目录
1. 字符指针
1.1. 一般使用
1.2. 另一种使用
2. 指针数组
3. 数组指针
3.1. 数组指针
3.2. 数组名和&数组名
3.3. 数组指针的用处
1. 传递一个数组
2. 传递数组首元素的地址
3. 数组指针处理一维数组
4. 数组指针处理二维数组
4. 数组传参和指针传参
4.1. 数组传参
4.1.1. 一维数组传参
4.1.2. 二维数组传参
4.2. 指针传参
4.2.1. 一级指针传参
4.2.2. 二级指针传参
5. 函数指针
5.1. 函数指针的定义及使用
5.2. 函数指针的类型及类型重命名
6. 函数指针数组
7. 指向函数指针数组的指针
8. 回调函数
9. 指针和数组面试题的解析
9.1. 测试一
9.2. 测试二
9.3. 测试三
9.4. 测试四
9.5. 测试五
9.6. 指针笔试题:
1. 第一题
2. 第二题
3. 第三题
4. 第四题
5. 第五题
6. 第六题
7. 第七题
8. 第八题
1. 字符指针
字符指针(Character Pointer)是指向字符数据的指针变量。它存储了一个字符(或字符序列)的内存地址。
1.1. 一般使用
void Test1(void)
{
char ch = 'x';
char* ptr = &ch;
*ptr = 'q';
}上面的使用,没什么好说的,我们要说的是下面的这种使用方式。
1.2. 另一种使用
void Test2(void)
{
const char* str = "cowsay hello";
std::cout << str << std::endl;
}这里有一个疑问,这个字符指针str指向的内容是什么呢?是一个字符串还是一个字符呢?
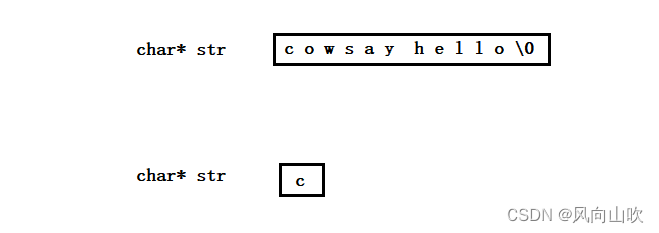
我们经过验证,发现其实str指向的内容是一个字符'c',而这个字符很特殊,它是这个字符串的第一个字符。换句话说,此时的str就是这个字符串第一个字符的地址即首字符的地址。相信有人发现我加了一个const,为什么呢?
void Test2(void)
{
const char* str = "cowsay hello";
*str = 'w'; // error
/* 我们说过const如果在
* '*' 的左边那么意味着 该指针指向的内容不可修改
* 反之,const如果在
* '*' 的右边那么意味着 该指针自身的值不可被修改
* 由于这是一个常量字符串,其本身具有常性,不可被修改
* 因此用const修饰,防止非法操作(去修改这个常量字符串)
*/
}
其实,编译器对常量字符串也有特殊处理,由于常量字符串具有常性,一般情况下,不会被修改。因此在内存中只会维护这一份常量字符串,通过地址空间,让指向该字符串的所有指针,共同访问这一份空间(且只支持读),我们也可以通过下面的测试验证:

有了上面的理解,我们延伸一下:
void Test4(void)
{
const char* str1 = "cowsay hello";
const char* str2 = "cowsay hello";
//str1 和 str2 是指向的统一块空间
char str3[] = "cowsay hello";
char str4[] = "cowsay hello";
//str3 和 str4 也是指向的统一块空间吗?
}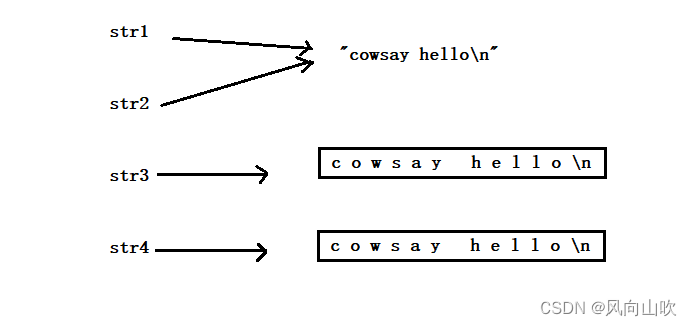
str1和str2指向的是同一个常量字符串;然而,对于str3和str4来说,它们俩各自是一个char数组,用相同的字符串进行初始化这两个char数组,因此,str3 != str4。它们指向的不是同一块空间。
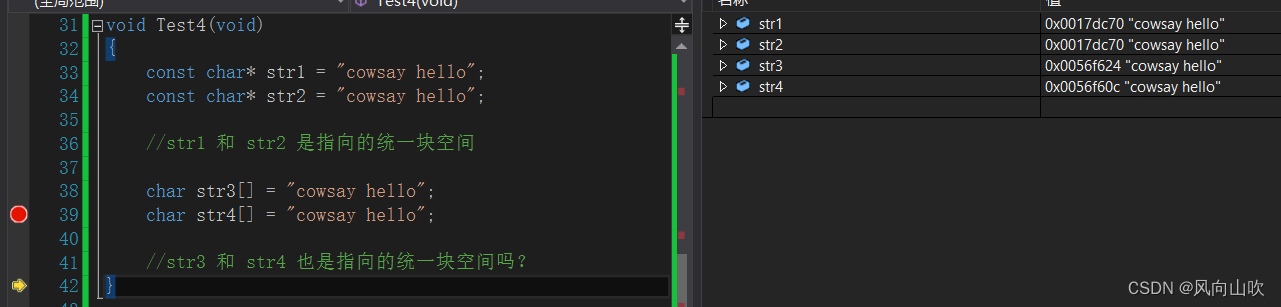
通过监视窗口,也可以观察到这个现象。
2. 指针数组
简单理解为,指针数组是一个数组,其每个元素是一个指针变量。
光这么说,可能不能很好地理解。我们可以通过类比,加深理解:
void Test5(void)
{
// 我们称之为整型数组,其每个元素是一个int
int i_arr[10] = { 0 };
// 我们称之为字符数组,其每个元素是一个char
char c_arr[10] = { 0 };
// 那么指针数组呢?
// 是不是就可以理解为:每个元素是一个指针变量的数组呢
// 当然可以
// p_arr是一个数组,又因为其每个数据元素是一个int*
// 因此它是一个整形指针数组,即指针数组
int* p_arr[10] = { NULL };
}有了对指针数组的简单理解,那么我们看看它是如何使用的呢?
void Test6(void)
{
// 我们说了,指针数组中的每一个元素是一个指针变量
// 那么我们可以如下操作:
int a = 10;
int b = 20;
int c = 30;
// int类型的地址就是int*
int* arr[] = { &a, &b, &c };
for (size_t i = 0; i < 3; ++i)
{
// arr[i] 是一个地址
// 通过解引用获得其指向的值
std::cout << *(arr[i]) << " ";
}
std::cout << "\n";
}但一般来说,上面的使用很少见,几乎不用,在这只是用于举例,以便我们理解指针数组。
为了加强理解,我们看看下面的这个例子:
void Test7(void)
{
int arr1[3] = { 1, 2, 3 };
int arr2[3] = { 2, 3, 4 };
int arr3[3] = { 3, 4, 5 };
/*
* 如果此时我想将arr1、arr2、arr3存进一个数组,该如何存储呢?
* 首先arr1这些都是数组的数组名,数组名是首元素的地址。
* 又由于其上面的每个数组的数据元素类型是int
* 那么int类型数据的地址(指针变量)的类型是不是int*呢? 当然是的。
* 因此,我就可以如下操作了:
*/
int* p_arr[3] = { arr1, arr2, arr3 }; // 将每个数组名存储与这个指针数组中
for (size_t i = 0; i < 3; ++i)
{
for (size_t j = 0; j < 3; ++j)
{
/*
* *(p_arr + i) 是不是等价于 p_arr[i]
* 即取到p_arr这个指针数组的每一个元素
* 而这每一个元素是不是都是一个数组的首地址呢? 是的
* 因此 *(*(p_arr + i) + j) 等价于 *(p_arr[i] + j) 也等价于 p_arr[i][j]
* 即取到p_arr[i]这个数组的每一个元素
*/
//std::cout << *(*(p_arr + i) + j) << " ";
//std::cout << *(p_arr[i] + j) << " ";
std::cout << p_arr[i][j] << " ";
}
std::cout << "\n";
}
}如果还不是很好的理解,请看下图:
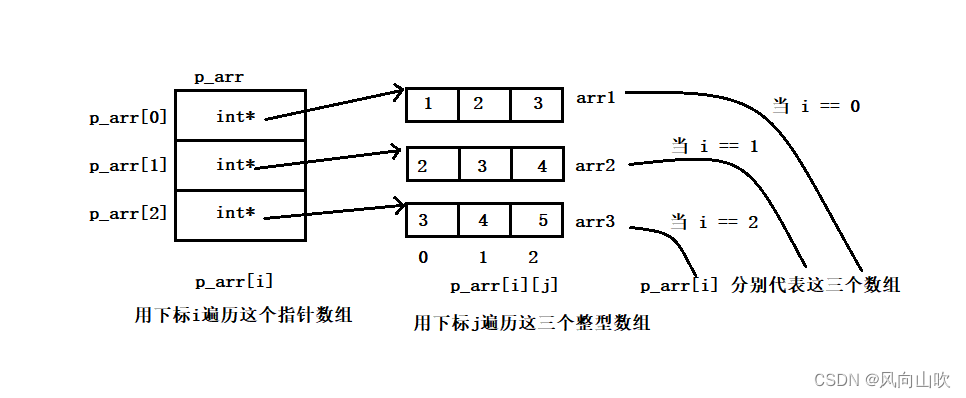
希望可以帮助理解。
3. 数组指针
3.1. 数组指针
数组指针是什么? 首先它是一个指针,是指向一个数组的指针,注意:不是指向数组的首地址,而是指向一个数组的指针。
首先,我们看看什么是指针数组,什么又是数组指针?
void Test8(void)
{
int *p_arr1[10]; // 指针数组
/*
* 指针数组是一个数组
* 其每个元素是一个指针变量
*/
int(*p_arr2)[10]; // 数组指针
/*
* 那么数组指针呢?
* 数组指针是一个指针
* 该指针指向一个数组
*/
}了解了上面之后,我们试着理解一下数组指针,但在之前,我们还需要知道一个知识:在以前,我们说过,一般情况下,一个数组的数组名是首元素的地址,但是有特殊情况,我们今天看看这种特殊情况:
void Test9(void)
{
int arr[10] = { 0 };
// 数组名:
printf("arr_name: %p\n", arr);
// 数组首元素的地址:
printf("&arr[0]: %p\n", &arr[0]);
// 数组的地址:
printf("&arr: %p\n", &arr);
}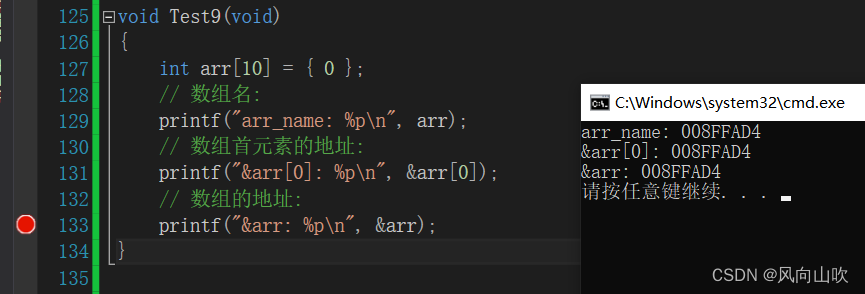
咦,它们的值都是一样的啊,貌似没有什么区别啊,别急,待我改进一番:
void Test10(void)
{
int arr[10] = { 0 };
// 数组名:
printf("arr_name: %p\n", arr);
// 数组名 + 1:
printf("arr_name + 1: %p\n", arr + 1);
std::cout << " --------------- " << std::endl;
// 数组首元素的地址:
printf("&arr[0]: %p\n", &arr[0]);
// 数组首元素的地址 + 1:
printf("&arr[0] + 1: %p\n", &arr[0] + 1);
std::cout << " --------------- " << std::endl;
// 数组的地址:
printf("&arr: %p\n", &arr);
// 数组的地址 + 1:
printf("&arr + 1: %p\n", &arr + 1);
}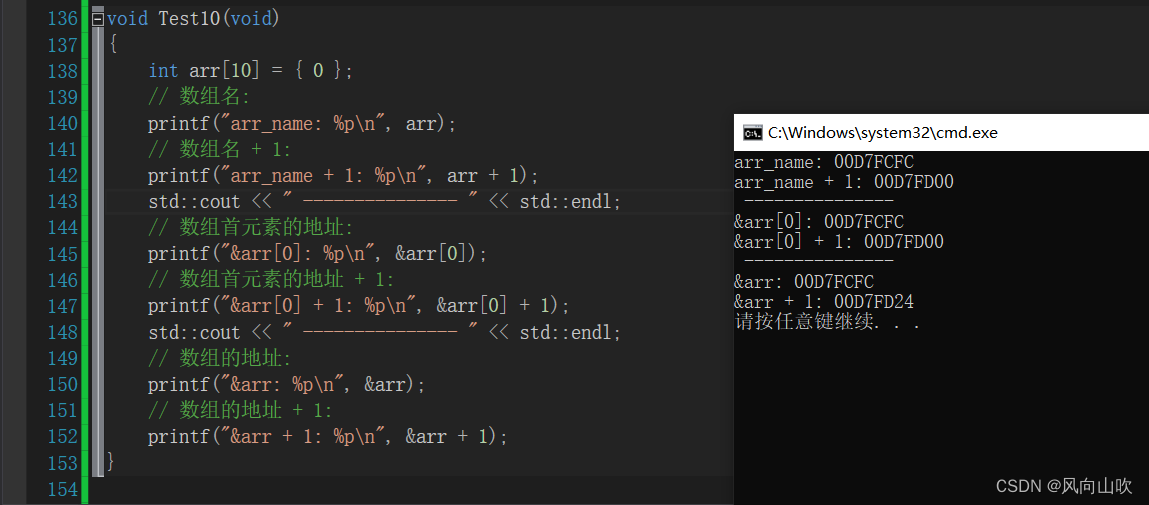
差异出来了,我们可以看到,对于数组名 + 1 和 数组首元素地址 + 1 它们都只跳过了4个字节(因为这个数组的每个元素是int,sizeof int 等于 4), 而 数组的地址 + 1 却跳过了整整0x28个字节,也就是40个字节,而我们这个数组的大小也正好是40个字节,也就是说,数组的地址 + 1会跳过整个数组的大小。然而数组的地址是不是也是一个地址啊,即我们需要用一个指针变量去接收它,那么问题来了,这个指针变量的类型是什么呢?
void Test11(void)
{
int i = 10;
// 对于整形的地址我们是不是用一个int*去接收
int *i_ptr = &i;
int arr[10] = { 0 };
/*
* 那么对于数组的地址呢?
* &arr 该用什么类型的指针变量去接收呢?
* 既然是要用指针变量接收
* 那么首先要有一个指针变量 *p
* 接下来讨论它的类型
* 因为这是一个数组
* 那么必然有[] ---> *p[]
* 但又由于 [] 的优先级比 * 高
* 因此我们要保证p是一个指针变量 (*p)[]
* 既然是数组,我们是不是应该把原始数组的大小标明清楚
* 因此 (*p)[10]
* 又因为这个指针变量指向的数组的每个元素类型为 int
* 因此 int (*p)[10] 而此时p就是一个数组指针 它的类型是 int (*)[10]
* 它就可以接收该数组arr的地址,即
*/
int(*p)[10] = &arr;
}有了上面的描述,相信大概可以很好的理解数组指针是什么,以及如何定义一个数组指针了,为了更好地理解这个问题,请解决下面的问题:
void Test12(void)
{
char* str[5] = { NULL };
/*
* 那么如何定义上面这个数组的数组指针呢?
* 即 &str 应该用什么类型来接收呢?
* 请自己实现,若没有实现出来,在看看下面的分析
*/
/*
* 分析:
* 它首先得是一个指针变量吧:
* *p_str
* 该指针指向一个数组,那么就会有[],既然有[]还要考虑数组的大小吧,且因为优先级的关系,即:
* (*p_str)[5]
* 又由于该数组的每一个元素的数据类型是char*,那么有:
* char* (*p_str)[5]
*/
char* (*p_str)[5] = &str;
}3.2. 数组名和&数组名
通常情况下,我们所说的数组名就是数组首元素的地址,但有两个特殊情况:
sizeof 数组名 : 计算的是整个数组的大小。
&数组名 : 取出的是整个数组的地址。
3.3. 数组指针的用处
首先说一下,对于数组指针而言,是很少对一维数组使用的。但我们在这里是举例,为了加深我们对数组指针的理解,在这里对一维数组也进行演示:
void Test13(void)
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
size_t sz = sizeof arr / sizeof arr[0];
// 如何遍历这个数组呢?即print()函数如何实现呢
} 在我们以前的学习中,我们可能会以如下的两种方式实现print():
1. 传递一个数组
// 传递一个数组,这没啥好说的
void print(int arr[], size_t sz)
{
for (size_t i = 0; i < sz; ++i)
{
std::cout << arr[i] << " ";
}
std::cout << "\n";
}
void Test13(void)
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
size_t sz = sizeof arr / sizeof arr[0];
print(arr, sz);
} 2. 传递数组首元素的地址
// 由于这是一个数组,因此我们只需要数组元素的首地址,即可打印整个数组
void print(int* arr, size_t sz)
{
for (size_t i = 0; i < sz; ++i)
{
std::cout << arr[i] << " ";
}
std::cout << "\n";
}
void Test13(void)
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
size_t sz = sizeof arr / sizeof arr[0];
print(arr, sz);
} 3. 数组指针处理一维数组
但假如说,我就是想用数组指针遍历这个数组呢?而我们知道,数组指针指向的是一个数组,那么该如何实现呢?
/*
* 因为传递过来的是一个数组的地址
* 因此需要用数组指针接收
*/
void print(int (*p_arr)[10], size_t sz)
{
for (size_t i = 0; i < sz; ++i)
{
/*
* p_arr是一个数组指针,指向一个数组
* (*p_arr) 对这个数组指针解引用是什么呢?
* 其实我们会得到这个数组,即(*p_arr)就是数组首元素的地址
* 也可以理解为 (*p_arr) 就是 数组名
* 注意: *运算符 和 []运算符的优先级关系
* 那么:
*/
//std::cout << (*p_arr)[i] << " ";
// 也等价于:
std::cout << *(*p_arr + i) << " ";
}
std::cout << "\n";
}
void Test13(void)
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
size_t sz = sizeof arr / sizeof arr[0];
print(&arr, sz);
} 我要说的是,我们对于一维数组的处理没有必要用数组指针处理,太麻烦了,感觉多此一举,但是,之所以在这里举例说明,是想加深我们对其的理解,在实际中,对于一维数组,尽量不要用数组指针。
4. 数组指针处理二维数组
但是对于二维数组的处理,用数组指针还是具有价值的。
void Test14(void)
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };
// 如何遍历这个二维数组呢? 此时的print()该如何实现?
}在我们以前的学习中,对于二维数组的处理可能是如下形式:
// 二维数组的行可以省略,但列数不可省略
//void print(int arr[][5], size_t row,size_t col)
void print(int arr[3][5], size_t row,size_t col)
{
for (size_t i = 0; i < row; ++i)
{
for (size_t j = 0; j < col; ++j)
{
std::cout << arr[i][j] << " ";
}
std::cout << "\n";
}
}
void Test14(void)
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };
// 如何遍历这个二维数组呢? 此时的print()该如何实现?
print(arr, 3, 5);
}那么用数组指针如何处理呢?首先,我们分析一下二维数组的结构:
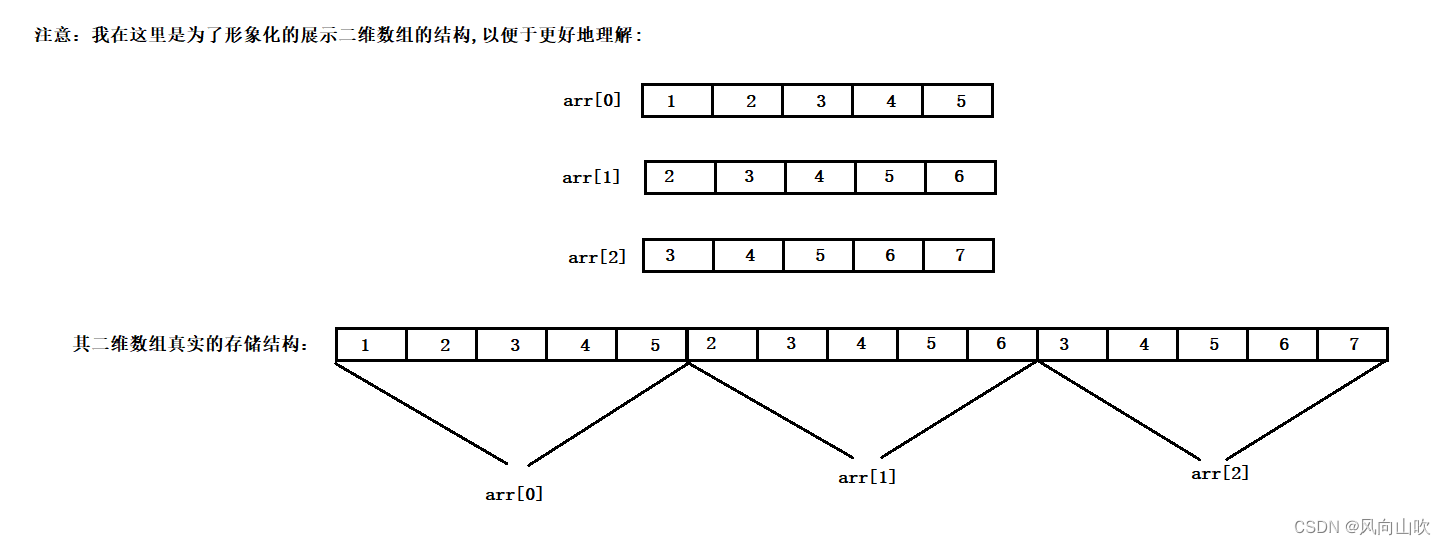
我们可以这样认为,二维数组是一个"一维数组",其每一个元素也是一个"一维数组";也就是说,对于二维数组而言,其数组名也代表首元素的地址,那么首元素是谁呢?就是&arr[0]。那么arr[0]是什么呢?是不是一个一维数组?&一维数组是什么呢? 不就是一个数组指针吗?这时候我们就串起来了,请看如下代码:
/*
* 因为传递过来的是arr,二维数组的数组名
* 即代表着首元素的地址,而二维数组的首元素是一个一维数组
* 对这个一维数组取地址,且这个一维数组的类型是int,那么有:
* arr --> &arr[0] ---> int (*p_arr)[5]
*/
void print(int (*p_arr)[5], size_t row, size_t col)
{
for (size_t i = 0; i < row; ++i)
{
for (size_t j = 0; j < col; ++j)
{
/*
* (*p_arr) 对它解引用得到的是什么呢?
* 是不是会得到这个二维数组arr
* 也可以理解: (*p_arr)是这个二维数组arr的数组名
* ((*p_arr) + i) 代表着 arr[i] 即代表这下标为i的"一维数组"
* 也就是说, ((*p_arr) + i) 就是每个 "一维数组"的首元素的地址
* (*((*p_arr) + i ) + j),就是第i个一维数组中的第j个元素
* 下面的三种方式互为等价关系
*/
//std::cout << p_arr[i][j] << " ";
//std::cout << ((*p_arr) + i)[j] << " ";
std::cout << (*((*p_arr) + i) + j) << " ";
}
std::cout << "\n";
}
}
void Test14(void)
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };
// 注意,我们在这里传递的是二维数组的数组名哦
print(arr, 3, 5);
}当然有人说,那我此时就想传递二维数组的地址呢?那么此时应当如何处理呢?
/*
* 由于此时我们传递过来的是一个二维数组的地址
* 但是, 只要是数组的地址,我们就可以用数组指针接收
* 但是这里的数组指针的类型如何写呢? 同样的思路:
* 你首先得是一个指针变量吧 (*p_arr)
* 其次,你是一个二维数组,如何表示你是一个二维数组呢? [][]
* 当然还要你的行数和列数,所以 (*p_arr)[3][5], 注意 这里行数和列数都不可以省略
* 最后,你的每一个数据的类型是一个int,那么:
* int (*p_arr)[3][5] = &arr;
*/
void print(int(*p_arr)[3][5], size_t row, size_t col)
{
for (size_t i = 0; i < row; ++i)
{
for (size_t j = 0; j < col; ++j)
{
/*
* 此时的p_arr是指向整个二维数组的
* (*p_arr)代表什么呢? 是不是代表着整个二维数组
* 也代表着二维数组的首元素的地址,即二维数组的数组名
* (*p_arr)[i][j] 就是第i个一维数组的第j个元素
*/
//std::cout << (*p_arr)[i][j] << " ";
// 它也等价于
/*
* (*p_arr) 代表着二维数组的数组名
* (*(*p_arr) + i) 代表着第i个一维数组,也就是 (*p_arr)[i]
* (*(*(*p_arr) + i) + j) 代表着第i个一维数组中的第j个元素
*/
//std::cout << (*(*p_arr) + i)[j] << " ";
// 它也等价于
std::cout << (*(*(*p_arr) + i) + j) << " ";
}
std::cout << "\n";
}
}
void Test14(void)
{
int arr[3][5] = { { 1, 2, 3, 4, 5 }, { 2, 3, 4, 5, 6 }, { 3, 4, 5, 6, 7 } };
// 注意: 此时传递的是二维数组的地址
print(&arr, 3, 5);
}如果上面感觉良好,那么在下面有一个小测试,看看能否区分清楚呢?
void Test1()
{
// 请尝试分析: arr、p_arr1、p_arr2、p_arr3分别是什么?
int arr[10];
int *p_arr1[10];
char* (*p_arr2)[10];
int (*p_arr3[10])[5];
}
// 分析如下:
void Test1(void)
{
// arr一个整型数组,有10个元素
int arr[10];
// p_arr1是一个指针数组,其每一个元素是一个int*
int *p_arr1[10];
// p_arr2是一个数组指针,指向一个大小为10的数组,数组的每个元素是一个char*
char* (*p_arr2)[10];
/*
* 首先p_arr3 先跟 []结合,那么它一定是一个数组,这个数组有10个元素
* 那么这个数组的每一个元素的类型是什么呢? 是 int (*)[5]
* 很显然,这是一个数组指针,这个数组指针指向一个数组,该数组有5个元素,每个元素的类型是int
* 因此 p_arr3是一个数组,其每个元素是一个数组指针。
* 也就是说p_arr3是一个指向数组指针的指针数组
*/
int (*p_arr3[10])[5];
}望以上的分析对你有所帮助。
4. 数组传参和指针传参
4.1. 数组传参
4.1.1. 一维数组传参
注意:数组名在传参的本质上是:传递的是数组首元素的地址。
void Test2(void)
{
int arr[5] = { 0 };
// 当传递这个一维数组时,函数形参如何接收呢
func1(arr); //
}//对于func1来说你是一个数组,我用对应数组接收这显然没有任何问题
void func1(int arr[5]) {}
/*
* 我们之前说过,数组名在传参的本质上是:数组首元素的地址.
* 数组在传参的时候,实际上不会将整个数组传递过去,形参也不会真正去创建一个数组,
* 而是只需要接收数组首元素的地址即可,那么既然不需要创建这个数组,
* 那么此时这个大小写或者是不写都没有任何影响,即便大小胡写也没事,因为这个大小对于这个形参没有意义。
* 其实编译器在实际处理中, 参数列表的 int arr[] 会被当作 int* arr 来处理
*/
void func1(int arr[]) {}
void func1(int arr[1000]) {}
/*
* 因为这个数组的数据类型是int,那么该数组首元素的地址的类型就是int*
* 那么我用一个int*的指针去接收这个首元素的地址,当然没有任何问题
*/
void func1(int *arr) {}void Test3(void)
{
char* c_arr[10] = { NULL };
// 那么当传递一个指针数组,我们在参数列表中又如何接收呢?
func2(c_arr);
}/*
* 与上面的分析过程大同小异
* 数组名在传参的本质是:传递的是数组首元素的地址
* 因此实际上不会传递整个数组,形参也不会去创建一个数组
* 此时只需要去接收数组首元素的地址即可,因此这个数组的大小可写可不写,甚至可以乱写(当然这是一种不好的方式)
* 因为这个大小对于形参来说毫无意义
*/
void func2(char* c_arr[10]) {}
void func2(char* c_arr[]) {}
void func2(char* c_arr[1000]) {}
/*
* 与前面一样,如果要写成指针变量,那么我们分析这个变量的类型是什么:
* 这个数组是一个指针数组,其每一个元素的数据类型是一个char*
* 那么我们前面说了,数组名传参本质上传递的是数组首元素的地址,数组首元素的类型是一个char*
* 那么数组首元素的地址显然就是一个 char**
* 很显然,此时我们当然可以用一个char** 去接受这个地址
*/
void func2(char** p_carr) {}4.1.2. 二维数组传参
对于数组名传参,我们一定要牢记,其本质传递的是数组首元素的地址。
/*
* 与上面的分析过程大同小异
* 数组名在传参的本质是:传递的是数组首元素的地址
* 因此实际上不会传递整个数组,形参也不会去创建一个数组
* 此时只需要去接收数组首元素的地址即可,但是由于这里是一个二维数组
* 对于二维数组而言,其行数可以省略,甚至胡写,但对于列数必须正确的写
* 为什么?因为对于二维数组而言,其编译器需要知道"每一行"有多少个元素
* 如果没有写列数,或者胡写列数,那么编译器无法确定"下一行"的正确起始位置
* 因此,行数可写可不写,但是列数必须正确定义
*/
void func3(int arr[3][5]) {}
void func3(int arr[][5]) {}
void func3(int arr[10][5]) {}
/*
* 我们需要知道数组名传参的本质:传递的是数组首元素的地址
* 这是一个二维数组,之前我说过,我们可以把一个二维数组认作是一个"一维数组"
* 但这个"一维数组"的每一个元素是一个int的一维数组,那么也就是说,对于二维数组来说:
* 其首元素是一个数组,那么二维数组首元素的地址,是不是就是:&一维数组
* 对数组取地址是什么呢?不就是一个数组指针吗?那我就要考虑这个指针变量的类型了
* 首先它得是一个指针变量吧
* (*p_arr)
* 其次,这个指针变量指向一个数组,该数组大小为5
* (*p_arr)[5]
* 再其次,每个元素是一个int,那么就有:
* int (*p_arr)[5],这就是对应的指针变量的类型,也就是这个二维数组的首元素的地址的类型,因此:
* 很多人有疑问,问这个5可不可以不写,甚至胡写
* 答案: 不可以, 这个5必须写正确,因为它决定了这个p_arr加1跳多少个字节
* 只有此时跳过 sizeof int * 5 即20个字节,才会正确的跳到"下一行"的起始位置
*/
void func3(int(*p_arr)[5]){}4.2. 指针传参
4.2.1. 一级指针传参
/*
* 一级指针传参,自然可以用一级指针接收
* 这里的ptr就是p_arr,也就是这个数组首元素的地址
*/
void func4(int* ptr)
{
for (size_t i = 0; i < 10; ++i)
{
std::cout << ptr[i] << " ";
}
std::cout << "\n";
}
void Test5(void)
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* p_arr = arr;
// 一级指针传参
func4(p_arr);
}但有时候,如果某个函数的参数是一个一级指针,那么此时什么对象可以传给这个函数呢?
void func4(int *ptr)
{
//...
}
void Test5(void)
{
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
// 可以传一个整形的地址
int a = 10;
func4(&a);
int* p_arr = arr;
// 可以传一个一级整形指针
func4(p_arr);
/*
* 也可以传一个一维数组的数组名
* 因为这个一维数组的数据元素类型是int,
* 且数组名是数组首元素的地址,类型为int*,因此可以传递
*/
func4(arr);
// 同上,既然数组名可以传递,那么数组的首元素的地址也同样可以
func4(&arr[0]);
}4.2.2. 二级指针传参
/*
* 因为传递过来的是一个字符的二级指针
* 自然,我们可以用一个二级指针接收
*/
void func5(char** pptr) {}
void Test6(void)
{
char ch = 'x';
char* c_ptr = &ch;
char** c_pptr = &c_ptr;
// 那么此时传递c_pptr这个二级指针,应该用什么类型接收呢?
func5(c_pptr);
}现在的问题是,如果一个函数的参数是一个二级指针,那么此时我可以传递什么对象呢?
void func5(char** pptr) {}
void Test7(void)
{
char ch = 'x';
char* c_ptr = &ch;
char** c_pptr = &c_ptr;
// 我可以传递一个二级指针
func5(c_pptr);
// 我也可以传递一个一级指针的地址
func5(&c_ptr);
// 我还可以传递一个指针数组,该数组的每个元素类型是char*
/*
* 为什么呢?我们传递该数组的数组名,实际上传递的是数组首元素的地址,
* 而该数组是一个指针数组,每一个元素的数据类型是char*,那么
* 首元素的地址的数据类型是 char**,那么自然可以传过去
*/
char* arr[5];
func5(arr);
}
5. 函数指针
5.1. 函数指针的定义及使用
函数指针简单理解,就是指向函数的指针。
void print(const char* str)
{
std::cout << str << std::endl;
}
void Test8(void)
{
/*
* 其实函数指针和数组指针很类似
* 数组指针是指向一个数组的
* 函数指针是指向一个函数的
*/
// 那我们是怎么定义数组指针的呢?
int arr[10] = { 0 };
// 具体细节请看之前的解释
int(*p_arr)[10] = &arr;
/*
* void print(const char* str)
* 那我们以同样的方式定义函数指针,以上面的print举例
* 首先函数指针是一个指针,那么有:
* (*p_func)
* 函数指针是指向一个函数的,你的告诉我它的参数吧,那么有:
* (*p_func)(const char*)
* 并且还有该函数的返回值,你也的告诉我,那么有:
* void (*p_func)(const char*) ,这就是一个函数指针
* 因此有 void(*p_func)(const char*) = print;
*/
void(*p_func)(const char*) = print;
}有人看到我上面在取函数的地址的时候,直接使用的是函数名,那么有人就问了,不需要带取地址吗? 接下来我们就看看它们是否有区别呢?
void Test9(void)
{
printf("print address: %p\n", print);
printf("&print address: %p\n", &print);
}
通过结果我们可以得知,不论是函数名或者是&函数名,它们都代表着函数的地址,是没有任何区别的。
void Test10(void)
{
void(*p_func1)(const char*) = print;
void(*p_func2)(const char*) = &print;
const char* str = "haha";
p_func1(str);
p_func2(str);
}
结果没有任何区别。 有人看到这里就又有疑问了,诶,我们怎么看到你直接用这个函数指针再进行操作啊,不需要进行解引用,找到这个函数,再进行操作吗?
void Test11(void)
{
void(*p_func)(const char*) = print;
const char* str = "haha";
/*
* 你不是说p_func是一个函数指针吗?
* 那么就是说它是指向这个函数的啊
* 即p_func应该是函数的地址啊
* 不应该先进行解引用,在调用这个函数吗?
*/
(*p_func)(str);
// 那这两种方式谁对谁错呢?
p_func(str);
}
通过结果我们可以得知,这两种调用方式都是对的。即对于函数指针来说,这个解引用操作不起任何作用,纯属一种形式,符合对于指针的形式上的操作。所以实际上我们可以不用写这个解引用操作。
5.2. 函数指针的类型及类型重命名
void Test13(void)
{
/*
* 要说函数指针的类型,我们可以通过数组指针进行类比
* 例如:
*/
int arr[10] = { 0 };
int(*p_arr)[10] = &arr;
/*
* 我们以前说过,数组指针的类型是什么呢?
* 去掉指针变量,剩下的东西就是数组指针的类型
* 即 int(*)[10] 就是这个数组指针的类型
*/
// 那么对于函数指针呢?
void(*p_func)(const char*) = print;
/*
* 同样的处理方式,去掉这个指针变量,剩下的就是函数指针的类型
* 即这里的函数指针的类型: void(*)(const char*)
* 各位不觉得这个类型很复杂吗?如果参数很多,那么这个类型是不是非常的复杂啊
* 有人就提出了对这个类型进行重命名
*/
// 对于一般类型的重命名,例如int
typedef int val_type;
// 但是对于函数指针,必须这样命名,这是规定
typedef void(*func_val_type)(const char*);
/*
* 注意,对于函数指针类型的重命名稍显特殊
* 此时的func_val_type 就是重命名后的函数指针类型
*/
func_val_type pf = print;
const char* str = "cowsay hello";
pf(str);
}最后,请看一下下面这两段有趣的代码:
(*(void (*)())0)();
/*
* 1. 首先是把0强制类型转换为一个函数指针类型,这就意味着0是一个指针
* 即将0地址处存放一个返回类型是void,无参的一个函数
* 2. 调用0地址处的这个函数
*/
void (*signal(int , void(*)(int)))(int);
/*
* 1. signal是一个函数的声明
* 2. signal函数的参数,第一个是int类型,第二个是void(*)(int)的函数指针类型
* 3. signal函数返回值类型也是: void(*)(int)
* 这样看起来太过于复杂,我们可以对 void(*)(int)这个函数指针类型进行取别名
* typedef void(*func_pf)(int); func_pf 就是void(*)(int)这个函数指针类型的别名
* 于是我们可以简化这段代码:
*/
typedef void(*func_pf)(int);
func_pf signal(int,func_pf);6. 函数指针数组
函数指针数组,本质上是一个数组,其每一个元素是一个函数地址。
int Add(int x,int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void Test14(void)
{
/*
* 函数指针数组 顾名思义 是一个数组
* 只不过与之前不同的是,其每个元素是一个函数指针
* 上面有四个函数 Add Sub Mul Div,以往的处理,就写四个函数指针
* 具体如下
*/
int(*pf_func1)(int, int) = Add;
int(*pf_func2)(int, int) = Sub;
int(*pf_func3)(int, int) = Mul;
int(*pf_func4)(int, int) = Div;
/*
* 但是上面的处理太单调了,我们可以借助函数指针数组处理:
* 那么函数指针数组如何定义呢?
* 首先它的是一个数组
* pf_func[]
* 其次它是一个函数指针的数组,如果没有显式定义,需要加上数组的大小
* (*pf_func[4])
* 其次还需要它的参数类型及返回值类型
* int(*pf_func[4])(int,int) 这就是一个函数指针数组
*/
int(*pf_func[4])(int, int) = { Add, Sub, Mul, Div };
std::cout << "请输入x,y>: " << std::endl;
int x, y;
std::cin >> x >> y;
for (size_t i = 0; i < 4; ++i)
{
std::cout << pf_func[i](x, y) << std::endl;
}
}函数指针数组的简单利用:
void meau(void)
{
std::cout << "********************************" << std::endl;
std::cout << "**** 1.Add 2.Sub ****" << std::endl;
std::cout << "**** 3.Mul 4.Div ****" << std::endl;
std::cout << "**** 0.Exit ****" << std::endl;
std::cout << "********************************" << std::endl;
}
void Test15(void)
{
/*
* 在我们以前通过switch语句实现过一个简单的计算器
* 但这太具有局限性,且代码的维护性有待商榷
* 我们完全可以利用函数指针数组解决这个问题
*/
int x = 0;
int y = 0;
int input = 0;
int(*pf_func[5])(int, int) = { 0,Add, Sub, Mul, Div };
do
{
meau();
std::cout << "please input options:> ";
std::cin >> input;
if (input >= 1 && input <= 4)
{
std::cout << "please input two operand:> ";
std::cin >> x >> y;
std::cout << "ret = " << pf_func[input](x, y) << std::endl;
}
else if (input < 0 || input > 4)
{
std::cout << "undefined option" << std::endl;
break;
}
} while (input);
}7. 指向函数指针数组的指针
什么叫 指向函数指针数组的指针呢? 简单理解:就是指向一个函数指针数组的指针。
int Add(int x, int y)
{
return x + y;
}
void Test1(void)
{
/*
* 什么叫函数指针呢?
* 什么叫函数指针数组呢?
* 什么叫函数指针数组指针呢?
*/
int(*pf1)(int, int) = Add; // 函数指针
int(*pf2[5])(int, int) = { Add }; // 这就是一个函数指针数组
/*
* 那函数指针数组指针如何定义呢?
* 顾名思义, 该指针指向一个函数指针数组
* 首先,你是一个指针,那么得先有一个指针变量吧
* (*pf3)
* 其次,该指针指向一个数组,那么必有[],及这个数组的大小
* (*pf3)[5]
* 最后,由于这个数组的每一个元素类型是一个函数指针,那么有:
* int (*(*pf3)[5]) (int,int) 这就是一个函数指针数组指针,指向一个函数指针数组
* 即有:
*/
int(*(*pf3)[5])(int, int) = &pf2;
/*
* pf3是一个函数指针数组指针,指向一个函数指针数组
* *pf3 即 得到这个数组,也就是说 (*pf3) 代表这数组的数组名
* 此时就可以通过解引用访问原数组的元素
*/
//std::cout << (*pf3)[0](3, 5) << std::endl;
std::cout << (*((*pf3) + 0))(3, 5) << std::endl;
// 如果我们觉得太复杂,也可以简化一下,对这个函数指针类型进行重命名
typedef int(*pf_func)(int, int);
pf_func(*pf4)[5] = &pf2; // pf4也是一个函数指针数组指针,指向一个函数指针数组
std::cout << (*((*pf4) + 0))(3, 5) << std::endl;
}8. 回调函数
回调函数就是一个通过函数指针调用的函数。
void print()
{
std::cout << "hehe" << std::endl;
}
void print_hehe(void(*pf_func)()) // 此时的print_hehe 就是一个回调函数
{
pf_func();
}
void Test2(void)
{
print_hehe(print);
}那么回调函数有什么运用呢?在C标准库里有一个函数qsort,其底层就是一个回调函数。qsort排序逻辑是一个快排,其特点可以排序任何数据类型。
/*
* qsort函数原型如下:
* base : 待排序数据的起始位置
* num : 数组元素个数
* width : 元素大小(以字节为单位)
* e1、e2 : 待比较的两个元素的起始地址
* cmp : 一个函数指针,指向的函数就是其排序所依靠的比较逻辑,一般需要我们自己实现
* cmp指向的函数 返回值为int
* 升序规则:
* < 0 : e1 less than e2
* 0 : e1 equivalent to e2
* > 0 : e1 greater than e2
* 降序规则:
* < 0 : e1 greater than e2
* 0 : e1 equivalent to e2
* > 0 : e1 less than e2
*/
void qsort(void *base, size_t num, size_t width, int(*cmp)(const void *e1, const void *e2));举例说明:
int cmp(const void* e1, const void* e2)
{
/*
* 注意: e1、e2 类型为const void*,可以接受任意的指针类型,但不可以解引用
* 因为它不知道它解引用后应该访问几个字节,因此,一般使用都需要强转
* 在这里以升序举例:
*/
if (*(static_cast<const int*>(e1)) > *(static_cast<const int*>(e2)))
return 1;
else if (*(static_cast<const int*>(e1)) < *(static_cast<const int*>(e2)))
return -1;
else
return 0;
// 上面的方式太繁琐 e1 - e2 > 0 就是升序
//return (*(static_cast<const int*>(e1)) - *(static_cast<const int*>(e2)));
// e2 - e1 > 0 就是降序
return (*(static_cast<const int*>(e2)) - *(static_cast<const int*>(e1)));
}
void Test3(void)
{
int arr[10] = { 4, 3, 6, 5, 1, 2, 9, 7, 8, 0 };
qsort(arr, 10, sizeof arr[0], cmp); // 此时的qsort就是一个回调函数
for (auto& e : arr)
std::cout << e << " ";
}9. 指针和数组面试题的解析
9.1. 测试一
void Test4(void)
{
int a[] = { 1, 2, 3, 4 };
// 16 sizeof 数组名 数组的大小
printf("%d\n", sizeof(a));
// 4/8 a+0就是数组第一个元素的地址,既然是地址,32位下4字节,64位下8字节
printf("%d\n", sizeof(a + 0));
// 4 a是数组名,表示数组首元素的地址,*a是数组的第一个元素,其类型是int,在这里就是4
printf("%d\n", sizeof(*a));
// 4/8 a+1是数组第二个元素的地址
printf("%d\n", sizeof(a + 1));
// 4 a[1] 就是一个int类型的数据
printf("%d\n", sizeof(a[1]));
// 4/8 &a代表数组的地址,但终归是地址,32位下4字节,64位下8字节
printf("%d\n", sizeof(&a));
// 16 &a即数组的地址, *&a 就是这个数组,也就是说,*&a就是原数组的数组名, sizeof 数组名 就是数组的大小
printf("%d\n", sizeof(*&a));
// 4/8 数组的地址 + 1还是一个地址,只不过&a + 1 跳过了整个数组,即跳过了16个字节
printf("%d\n", sizeof(&a + 1));
// 4/8 第一个元素的地址
printf("%d\n", sizeof(&a[0]));
// 4/8 第一个元素的地址 + 1还是地址 ,只不过 &a[0] + 1 跳过了一个数据,即跳过了4个字节
printf("%d\n", sizeof(&a[0] + 1));
}结果:
16
4
4
4
4
4
16
4
4
4
9.2. 测试二
void Test5(void)
{
/*
* 这是一个字符数组 只有 'a' 'b' 'c' 'd' 'e' 'f'这六个字符,没有 '\0'
*/
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f' }; //[a b c d e f]
// 6 数组的大小,就是6
printf("%d\n", sizeof(arr));
// 4/8 数组首元素的地址 + 0 还是数组首元素的地址
printf("%d\n", sizeof(arr + 0));
// 1 arr是数组首元素的地址,*arr就是数组首元素的大小
printf("%d\n", sizeof(*arr));
// 1 arr[1]是数组第二个元素的大小
printf("%d\n", sizeof(arr[1]));
// 4/8 数组的地址
printf("%d\n", sizeof(&arr));
// 4/8 数组的地址 + 1 还是地址, 只不过跳过一个数组的大小,在这里跳过6个字节
printf("%d\n", sizeof(&arr + 1));
// 4/8 数组首元素的地址 + 1还是地址,只不过跳过了一个元素的大小,跳过1个字节
printf("%d\n", sizeof(&arr[0] + 1));
// 随机值, strlen会一直读取到 '\0', 由于原数组没有'\0',会一直访问到'\0',stlren才会结束
printf("%d\n", strlen(arr));
// 随机值, 原因同上
printf("%d\n", strlen(arr + 0));
/*
* arr是数组首元素的地址, *arr就是数组的首元素, 'a'--- 97
* 而strlen需要一个地址, 编译器在处理的时候会认为 97是一个地址
* 因此strlen会从97这个地址处向后访问,直至遇到'\0',这其实就是一个非法访问的过程
* 本质上这一段空间是是用户无法访问的,如果访问,进程崩溃
*/
// printf("%d\n", strlen(*arr)); // error,进程崩溃
// arr[1] 是数组的第二个元素, 'b' --- 98, 原因同上,非法访问
// printf("%d\n", strlen(arr[1])); // error,进程崩溃
/*
* 随机值, &arr 是数组的地址 ,但是在strlen看来,它和数组的首地址没有任何区别,
* strlen会从数组的首元素开始,依次往后访问,直至遇到'\0' 结束,虽然这里也存在在非法访问
* 但是这段空间用户是可以申请的,用户可以访问,但也属于属于非法访问,而上面的那种情况
* 是因为那段空间用户是无论如何都无法访问的
*/
printf("%d\n", strlen(&arr));
/*
* 随机值, &arr 是数组的地址, &arr + 1 跳过整个数组,即跳过了6个字节,strlen会从
* 数组中最后一个元素的下一个位置开始访问,直至遇到'\0'结束
*/
printf("%d\n", strlen(&arr + 1));
/*
* 随机值,&arr[0]是数组首元素的地址, &arr[0] + 1 会跳过一个元素,即跳过1个字节,就是原数组
* 的第二个元素,因此strlen会从第二个元素开始访问,直至遇到'\0'结束
*/
printf("%d\n", strlen(&arr[0] + 1));
}运行结果:
6
4
1
1
4
4
4
19
19
19
13
18
9.3. 测试三
void Test6(void)
{
/*
* 这是用一个字符串初始化这个字符数组
* 因此这个字符数组的内容: 'a' 'b' 'c' 'd' 'e' 'f' '\0' 这七个字符
*/
char arr[] = "abcdef";
// 7 sizeof 数组名就是数组的大小,而数组有七个字符,那么自然是7个字节
printf("%d\n", sizeof(arr));
// 4/8 arr是数组名即是数组的首地址,首地址 + 0,还是首地址
printf("%d\n", sizeof(arr + 0));
// 1 *arr 就是 数组的首元素,即一个字符的大小
printf("%d\n", sizeof(*arr));
// 1 arr[1] 就是 第二个字符的大小
printf("%d\n", sizeof(arr[1]));
// 4/8 &arr 数组的地址,还是地址
printf("%d\n", sizeof(&arr));
// 4/8 &arr是数组的地址, &arr + 1 数组的地址 + 1 还是地址, 只不过会跳过整个数组的大小,即跳过7个字节
printf("%d\n", sizeof(&arr + 1));
// 4/8 &arr[0]是数组首元素的地址 &arr[0] + 1 还是地址,只不过会跳过一个元素,即跳过1个字节
printf("%d\n", sizeof(&arr[0] + 1));
// 6 arr是数组名,即数组首元素的地址,又因为arr有'\0' 那么这个字符串的长度就是6
printf("%d\n", strlen(arr));
// 6 同样arr + 0 还是数组首元素的地址,那么还是6
printf("%d\n", strlen(arr + 0));
/*
* arr是数组首元素的地址, *arr就是数组的首元素, 'a'--- 97
* 而strlen需要一个地址, 编译器在处理的时候会认为 97是一个地址
* 因此strlen会从97这个地址处向后访问,直至遇到'\0',这其实就是一个非法访问的过程
* 本质上这一段空间是是用户无法访问的,如果访问,进程崩溃
*/
//printf("%d\n", strlen(*arr)); //error
// 原因同上,进程崩溃
//printf("%d\n", strlen(arr[1])); // error
// 6 &arr 是数组的地址, 但对于strlen来说,没有区别,strlen还是会从数组首元素的地址开始,因此长度为6
printf("%d\n", strlen(&arr));
// 随机值 &arr + 1 跳过整个数组,即会从数组的最后一个元素的下一个位置开始,直至遇到'\0'结束,因此是一个随机值
printf("%d\n", strlen(&arr + 1));
// 5 &arr[0] 是数组首元素的地址, &arr[0] + 1 跳过一个元素,即从b开始,那么结果就是5
printf("%d\n", strlen(&arr[0] + 1));
}结果:
7
4
1
1
4
4
4
6
6
6
12
5
总结:
sizeof 是一个操作符
sizeof 计算的是对象所占内存的大小,单位是字节,返回值类型是 size_t。不在乎内存中存放的是什么,只在乎内存大小。
strlen 是一个C库函数
求字符串长度,从给定的地址向后访问字符,统计'\0'之前出现的字符个数
9.4. 测试四
void Test7(void)
{
/*
* 注意: 此时不是将这个常量字符串存入指针变量p里
* 而是将这个字符串首元素的地址赋值给p,也就是说p指向的是这个字符串的首元素
* 即p就是这个常量字符串的首元素的地址
*/
char *p = "abcdef";
// 4/8 p是一个指针变量
printf("%d\n", sizeof(p));
// 4/8 p是一个指针变量,其类型为char*,p+1还是一个指针变量,只不过跳过一个字节,此时就是'b'的地址
printf("%d\n", sizeof(p + 1));
// 1 p是常量字符串首元素的地址,*p就是'a',一个字符,自然就是一个字节
printf("%d\n", sizeof(*p));
// 1 p[0]相当于*(p + 0) 就是原串的第一个字符'a' 一个字节
printf("%d\n", sizeof(p[0]));
// 4/8 p是一个指针变量, &p 还是一个指针变量,其类型是char**
printf("%d\n", sizeof(&p));
/*
* 4/8
* &p 是一个指针变量,其类型是char**
* &p + 1 跳过了一个指针(char*)的大小,即跳过4/8个字节,但还是一个指针变量
*/
printf("%d\n", sizeof(&p + 1));
/*
* 4/8
* p[0] 就是第一个字符 'a' &p[0]就是第一个字符的地址,
* &p[0] + 1 就是第二个字符的地址
*/
printf("%d\n", sizeof(&p[0] + 1));
// 6 p是常量字符串首元素的地址,strlen从'a'开始,那么自然结果是6
printf("%d\n", strlen(p));
// 5 p+1 就是常量字符串首元素的地址 + 1,也就是 'b'的地址,那么结果就是5
printf("%d\n", strlen(p + 1));
// 非法操作,*p 是 'a' --- 97,strlen 会将97认为一个地址,这段空间不可以被访问,进程崩溃
//printf("%d\n", strlen(*p)); // error
// 同上,非法操作,进程崩溃
//printf("%d\n", strlen(p[0])); // error
// 随机值, &p是p的地址,strlen从&p开始找'\0' 结果未知
printf("%d\n", strlen(&p));
/*
* 随机值
* &p是p的地址,&p + 1 跳过了一个指针(char*)的大小
* 即跳过4/8个字节,此时strlen从&p开始,直至遇到'\0'结束
* 结果是一个随机值
*/
printf("%d\n", strlen(&p + 1));
/*
* 5
* p[0] 就是第一个字符 'a' &p[0]就是第一个字符的地址,
* &p[0] + 1 就是第二个字符的地址,strlen 从第二个字符的地址开始,那么结果就是5
*/
printf("%d\n", strlen(&p[0] + 1));
}结果:
4
4
1
1
4
4
4
6
5
3
11
5
9.5. 测试五
void Test8(void)
{
//二维数组
int a[3][4] = { 0 };
// 48 sizeof 数组名 数组的大小 4 * 3 * 4 即 48个字节
printf("%d\n", sizeof(a));
// 4 a[0][0] 就是第0行第0列的一个int元素,自然是4
printf("%d\n", sizeof(a[0][0]));
/*
* 16
* 因为a是一个二维数组,那么a[0]就是一个一维数组,有4个元素,其每个元素是int
* 那么a[0]就代表着该数组的数组名,那么sizeof 数组名 就是 16
*/
printf("%d\n", sizeof(a[0]));
// 4/8 a[0] 是数组名,即数组的首地址,a[0] + 1 跳过一个int, 就是第0行第1个元素的地址
printf("%d\n", sizeof(a[0] + 1));
// 4 如上所说,a[0]+1是第0行第1个元素的地址,那么解引用就是一个int类型的数据,那么自然是4
printf("%d\n", sizeof(*(a[0] + 1)));
/*
* 4/8
* a是一个二维数组的数组名,表示首元素a[0]的地址, a+1就是第一行即a[1]这个数组的地址
* 既然 a + 1是一个地址,那么自然是4/8
*/
printf("%d\n", sizeof(a + 1));
// 16 如上所说,a + 1是第一行a[1]的地址,对其解引用,就得到了a[1]这个数组,有4个元素,每个元素类型为int,那么自然是16
printf("%d\n", sizeof(*(a + 1)));
/*
* 4/8
* a[0]是第0行的地址,而a[0]是一个一维数组,那么&a[0]就是一个数组的地址,即数组指针
* 数组指针 + 1就会跳过一个数组的大小,此时就是第1行即a[1]的地址,但还是地址,那么结果就是4/8
*/
printf("%d\n", sizeof(&a[0] + 1));
// 16 如上所说, &a[0] + 1是第一行a[1]的地址,对其解引用,就是a[1]这个数组,sizeof 数组名 在这里就是16
printf("%d\n", sizeof(*(&a[0] + 1)));
// 16 a是数组首元素的地址,即a[0]的地址,对其解引用,就会得到a[0]这个数组,sizeof 数组名, 在这里就是16
printf("%d\n", sizeof(*a));
/*
* 16
* sizeof 是不会访问内存的,只需要知道数据类型即可,因此不存在越界访问的情况
* a[3] 在sizeof 看来依旧是一个一维数组的数组名,在这里还是16
*/
printf("%d\n", sizeof(a[3]));
}结果:
48
4
16
4
4
4
16
4
16
16
16
9.6. 指针笔试题:
1. 第一题
void Test1(void)
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf("%d,%d\n", *(a + 1), *(ptr - 1));
}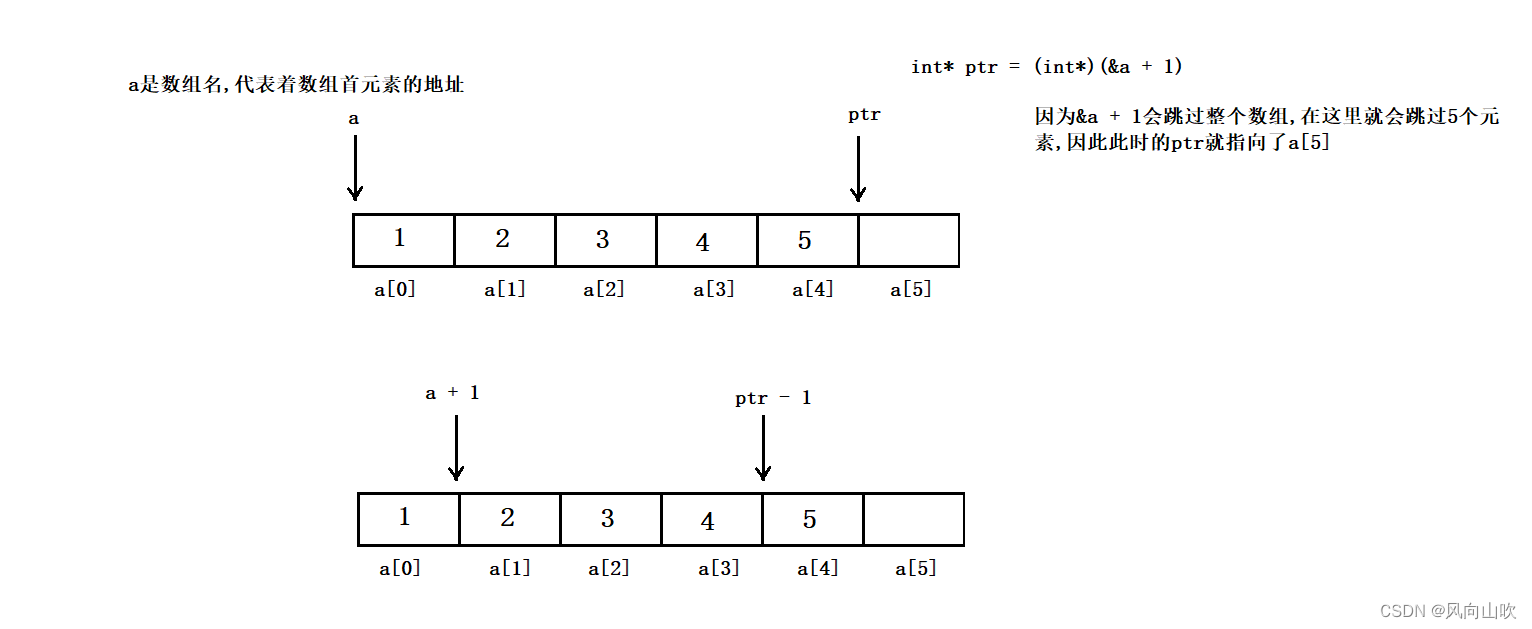
a本事是指向数组首元素的地址的,而a + 1就指向了a[1]这个元素的地址;ptr本身是指向a[5]这个元素的地址,ptr-1就指向了a[4]这个元素的地址。通过分别解引用,结果分别是2、5

2. 第二题
//这个结构体的大小是20个字节, 注意这里是32位的机器,其指针为4个字节
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
void Test2()
{
p = (struct Test*)0x100000;
/*
* p + 0x1 就是相等于 p + 1
* p的类型是一个struct test*
* p + 1会跳过一个struct test,而一个struct test的大小为20字节
* 因此这里会跳过20个字节,即 0x100000 + 20 即等于 0x100014
* 注意: 以%p打印会默认以十六进制打印
*/
printf("%p\n", p + 0x1); // 0x100014
/*
* 注意这里p强制转化为了一个unsigned long,即强转为了整形
* 整形 + 1, 那不就是 + 1吗? 就是相当于 0x100000 + 1 即等于 0x100001
*/
printf("%p\n", (unsigned long)p + 0x1); // 0x100001
/*
* 将p强制转化为了 unsigned int* ,那么此时 p + 0x1
* 就相当于p + 1, 跳过一个 整形的大小,即跳过4个字节
* 就相当于 0x100000 + 4 等于 0x100004
*/
printf("%p\n", (unsigned int*)p + 0x1); // 0x100004
}3. 第三题
void Test3(void)
{
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
int *ptr2 = (int *)((int)a + 1);
printf("%x,%x\n", ptr1[-1], *ptr2);
}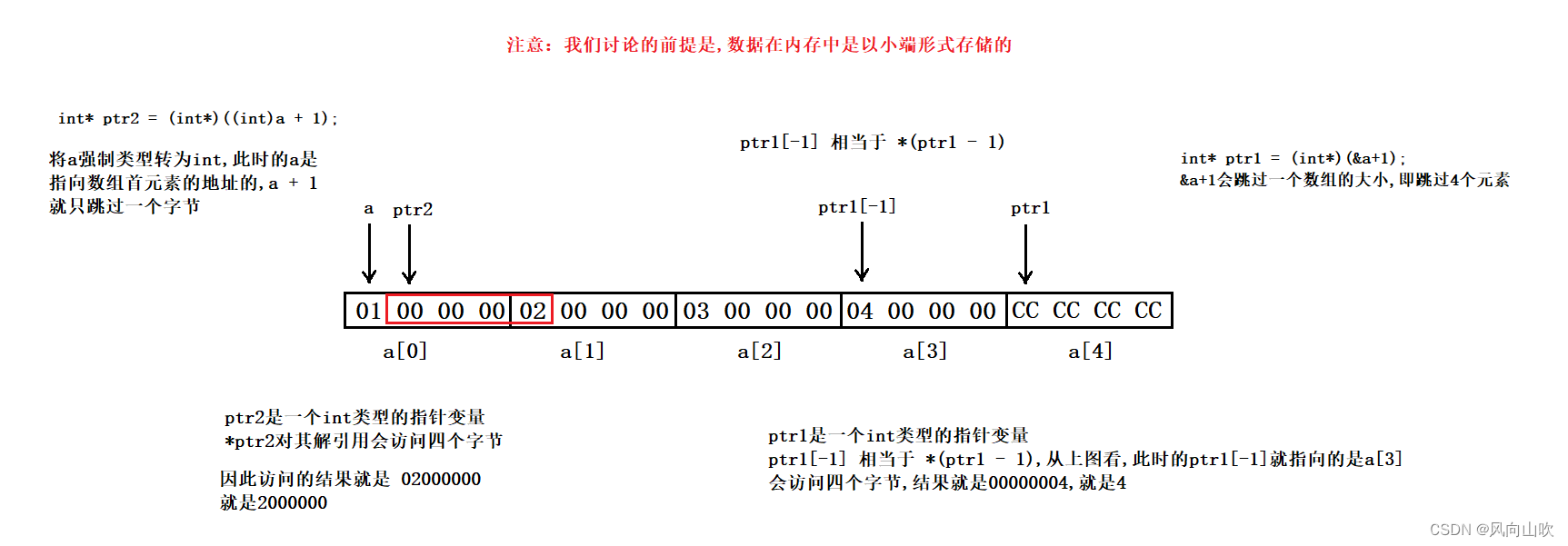
注意:%x 是以十六进制的形式打印的。而上面的存储结构就是以十六进制展示的。因此最后的结果就是4,和2000000。

4. 第四题
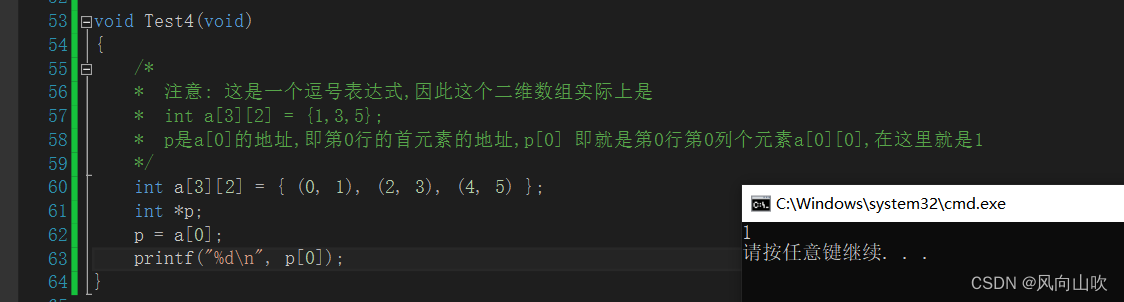
void Test4(void)
{
/*
* 注意: 这是一个逗号表达式,因此这个二维数组实际上是
* int a[3][2] = {1,3,5};
* p是a[0]的地址,即第0行的首元素的地址,p[0] 即就是第0行第0列个元素a[0][0],在这里就是1
*/
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf("%d\n", p[0]);
}
5. 第五题
void Test5(void)
{
int a[5][5];
int(*p)[4];
p = (int(*)[4])a;
/*
* 指针相减 代表两个指针之间元素的个数
* 答案分别是 -4的十六进制和十进制
* -8的原码形式: 10000000 00000000 00000000 00000100
* -8的反码形式: 11111111 11111111 11111111 11111011
* -8的补码形式: 11111111 11111111 11111111 11111100
* FF FF FF FC
* 因此最后的答案就是 FFFFFFFC,-4
*/
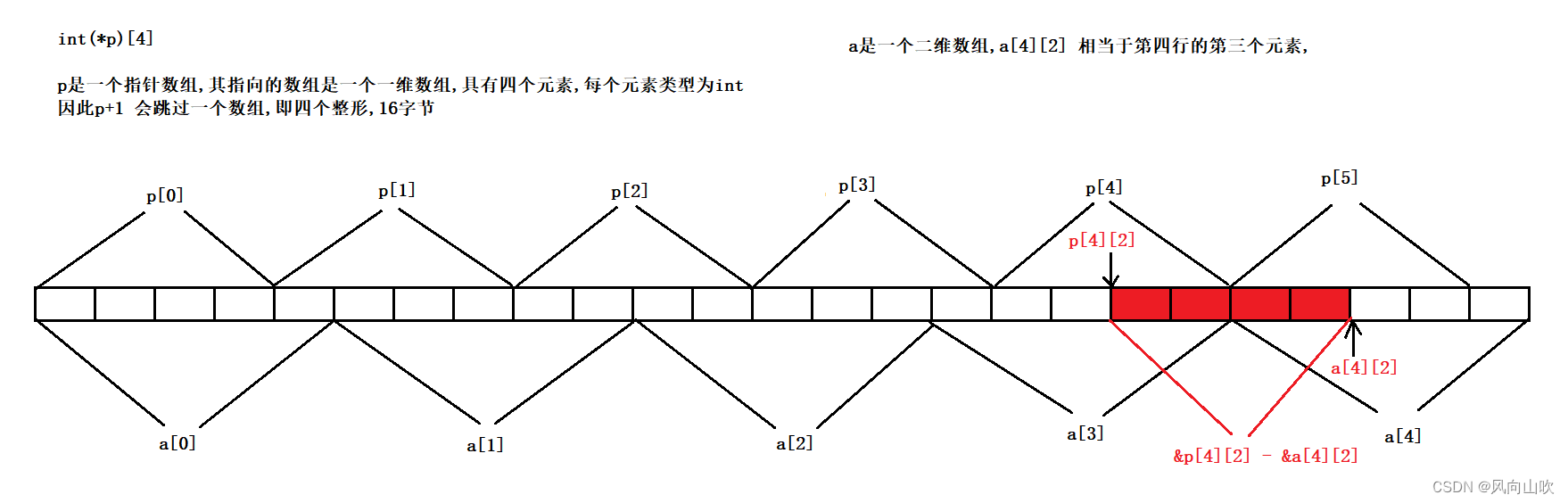
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
} 
6. 第六题
void Test6(void)
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int *ptr1 = (int *)(&aa + 1);
int *ptr2 = (int *)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1)); // 答案是10 5 ,分析请看下图
}

7. 第七题
void Test7(void)
{
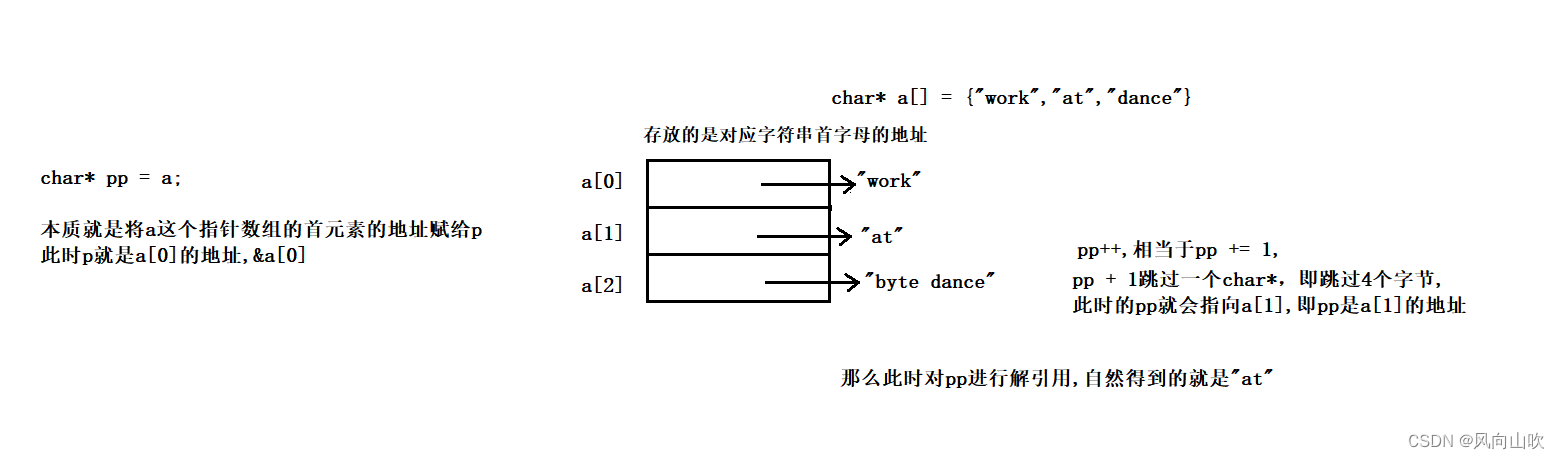
char *a[] = { "work", "at", "byte dance" };
char**pp = a; // 数组名相当于数组首元素的地址
pp++;
printf("%s\n", *pp); // 答案是"at",解析看下图
}
8. 第八题
void Test8(void)
{
char *c[] = { "ENTER", "NEW", "POINT", "FIRST" };
char**cp[] = { c + 3, c + 2, c + 1, c };
char***cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *--*++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
}要解决这个问题,我认为图是很重要的,如果图分析正确了,结果自然也就出来了
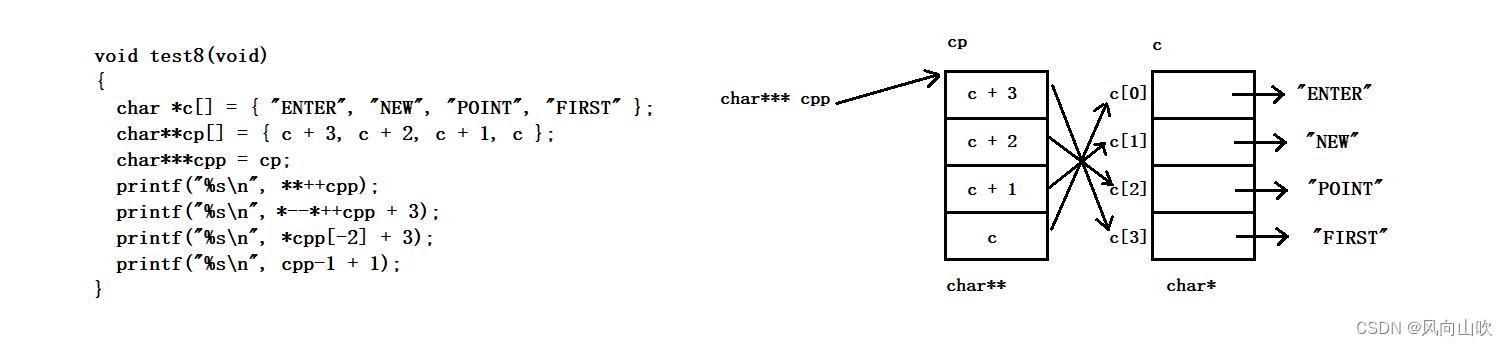
分析第一条打印: printf("%s\n", **++cpp);
注意: cpp 是 cp这个指针数组的首元素的地址,也就是说
cpp 等价于 &cp[0]
++cpp 等价于 (cp + 1),也就是 &cp[1]
那么**++cpp 等价于 **(cp + 1) 等价于 *(c + 2)
c + 2又是 "POINT"这个字符串的首字母的地址
*(c + 2) 就是 "POINT" 这个字符串
因此结果就是POINT
注意:当经过第一条打印后,此时的cpp就指向了cp + 1

此时,我们再分析第二条打印:printf("%s\n", *--*++cpp + 3);
分析如下,
此时的cpp 指向的是 cp + 1
++cpp 指向的是 cp + 2解引用++cpp,即*(++cpp)得到的就是 c + 1
也就是"NEW"这个字符串首元素字母的地址
--*++cpp 即得到的就是 c + 0 即"ENTER"这个字符串首字母的地址*--*++cpp 得到的就是这个字符串,"ENTER"
*--*++cpp + 3 即从'E' 这个字母开始打印,得到的结果就是ER
注意:当经过第二条打印后,此时的cpp就指向了cp + 2,如下:
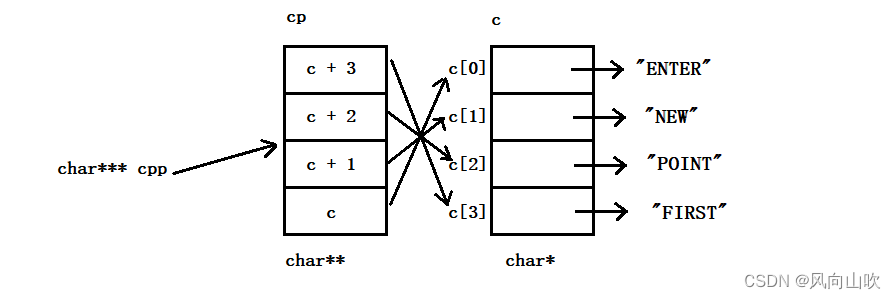
接下来,我们分析第三条打印:printf("%s\n", *cpp[-2] + 3);
cpp[-2] 相当于 *(cpp - 2)
*(cpp - 2) 就相当于 *(cp + 0) 即就是 c + 3
*cpp[-2] 就相当于 **(cpp - 2)
也相当于 *(c + 3)
而 c + 3 相当于 "FIRST"这个字符串的首地址
*(c + 3)得到的就是这个 "FIRST"这个字符串
*cpp[-2] + 3 就相当于 从'S'这个字符开始打印,结果就是ST
注意:当经过第三条打印后,此时的cpp依旧指向cp + 2,如下:
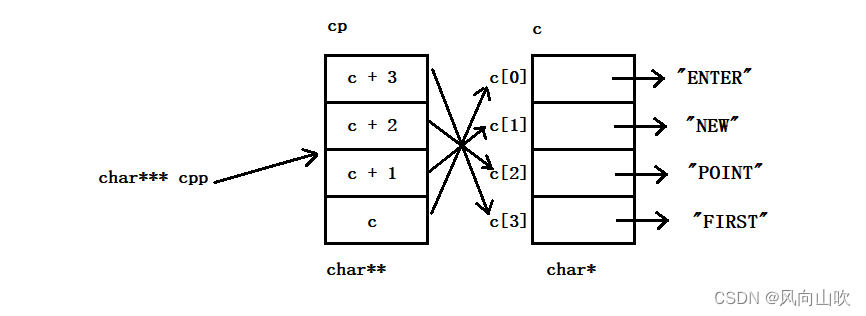
接下来,我们分析第四条打印:printf("%s\n", cpp[-1][-1] + 1);
分析如下:
cpp此时指向的是 cp + 2
cpp[-1]相当于 *(cpp - 1)
cpp[-1][-1] 相当于 *((*(cpp - 1)) - 1)
cpp - 1就是 cp + 1
(*(cpp -1)) 就是 *(cp + 1)即 cp[1],也就是 c + 2
c + 2也就是 "POINT"首字母的地址
((*(cpp - 1)) - 1) 就相当于 c + 2 - 1 即 c + 1
*(c + 1) 就是 "NEW"这个字符串
也就是说,cpp[-1][-1]就是 "NEW"这个字符串,
cpp[-1][-1] + 1 就相当于从'E'这个字符开始打印,最后的结果就是EW
至此,我们的练习题及指针的相关知识暂时结束,如若后期又有新收获,会再次补进来,学习是条漫长的道路,当真如逆水行舟,不进则退,只有及时总结,多多回顾,方能更上一层楼吧,期望你我之辈都有收获。