FLUSHALL:清空所有键值对操作(最好别搞,删库要被绳之以法的)
1.string类型
1.介绍
1.redis的字符串,直接按照二进制进行存储,所以可以存储任何数据,取出时不需要转码
2.redis的string类型,限制大小最大为512M,因为为单线程模型为了操作短平快
2.操作
1.set与get
set key value [ex seconds | px iseconds] [NX | XX]:添加string类型的键值对
1.一个语句可追加多条操作,而且合并的操作是原子性的
2.NX:如果key存在,则不设置,不存在则设置 ; XX:key存在更新设置,不存在不设置
3.如果key存在,则覆盖value,并且ttl也会失效
get key:获取key,只支持string类型的操作,如果不是会报错
2.mset与mget
操作多组键值对,减少了网络传输次数,增加效率
mset key value [key value...]:多次添加,但不是不要加太多,会使得redis阻塞
mget key [key]:一次性查找多次
3.setnx/setex/psetex
setnx: set同时设置nx选项,如果key存在,则不设置,不存在则设置
setex: 添加键值对并且设置超时时间
psetex:添加键值对并且设置毫秒级超时时间
4.incr/incrby/decr/decrby/incrbyfloat
value类型为int类型才能操作,并且数不能超过范围.操作的时间复杂度都是O(1),多客户端一起发送也不会出现线程安全问题
incr key: value+1 (64位),如果key不存在,当作当作value为0的键值对
incrby key n: value+n,n为正负数都可以
decr key: value-1
decrby key n: value-n,n为正负数都可以
incrbyfloat key n: value +/- 小数
5.append/getrange/setrange/strlen
append key value: 追加字符串,如果key没有则功能等于set.返回值的长度是字节
编码字节大小由shell设置,utf-8的汉字字节为3字节.get汉字不会返回汉字,会返回编码.需要在启动客户端时加上 --raw 的选项,客户端就会尝试翻译
getrange key start end: 获取字符串的一部分,区间范围为[start,end].负数表示倒数第几个.切分汉字可能会出现问题
setrange key offset value: 将offset位置的数据开始替换成value.替换结束返回新字符串的长度.如果当前替换的是汉字,那么可能会出现问题
strlen key:获取到字符串的长度,单位为字节
3.string编码方式
int: 8字节的长整型
embstr: 小于等于39字节的字符串
raw: 大于39字节的字符串
小数存储为一个字符串,而不是int类型.所以进行加减运行会进行转换
4.应用场景
1.作为缓存
应用服务器访问数据时,先查redis中是否存在,如果有直接返回给服务器;如果没有则在MySQL中寻找,并且将数据存一份到redis中.其功能就是把缓存用于存储热点数据,不过热点数据选择的策略是人为定义的.随时间推移key会越来越多,那么我们需要可以设置超时时间.当然redis在内存不足时,提供了淘汰机制.
2.计数
例如统计视频的观看次数.如果统计TopK的数据不太可以,使用MySQL更好
3.共享会话(session)
每一个服务器都在redis中维护同一份session,只要每个请求过来,每一个服务器都能对该请求进行处理与响应
2.hash类型
key field value形式,key对应一整个hash表
1.命令
1.hset/hget/hexists
hset key field value [field value...]:针对key跟上若干field与value的键值对.返回值为键值对的个数,value的类型为字符串
hget key field: key找到hash表,通过field找到value
hexists key field: 判断hash表中是否存在field
2.hdel
hdel key field[key field...]: 删除的是field,而不是key.返回删除的字段个数
3.hkeys/hvals
hkeys key: 查看所有field字段.找到hash,遍历hash的所有field.该操作有一定风险,与keys *差不多的错误
hvals key: 获取key中的所有value
4.hgetall/hmget
hgetall key: 查看所有field和对应的value,不推荐使用
hmget key field [field...]: 查看指定多个field的value
hscan key:渐进式遍历.敲一次遍历一部分
5.hlen/hsetnx/hincrby/hincrbyfloat
hlen key: hash的filed-value键值对个数,时间复杂度为O(1)
hsetnx key field value: 不存在则设置,存在则失败
hincrby key field n: hash的value也可当成整数,加减正负都行
hincrbyfloat key field n: hash的value也可当成浮点数,加减正负都行
2.hash编码方式
ziplist:压缩链表,适用于元素个数少,每个value的长度比较短
hashtable:hash表
3.应用
作为缓存:存储结构化的数据,类似于数据库的表结构.
1.hash类型是稀疏的,而关系型数据库是完全结构化的
2.关系型数据库可做复杂性查询,而redis不可以
3.list类型
类似于双端队列(deque),链表中的元素允许重复,下标从0开始
1.命令
1.lpush/lrange/lpushx/rpush
lpush key value [value...] :头插,返回值为list的长度
lrange key start end :查看[start,end]的区间,越界会返回能得到的所有数据
lpushx key value [value...] :key存在才头插
rpush key value [value...] :尾插,返回值为list的长度
2.lpop/rpop
lpop key :头删,返回删除元素值,或者返回空
rpop key :尾删,返回删除元素值,或者返回空
3.lindex/linsert/llen
lindex key index:给定下标,返回对应元素,时间复杂度为O(N)
linsert key <befor | after> pivot value :按顺序找pivot基准值,在其前面或者后面插入value元素,返回元素个数,时间复杂度为O(N)
llen key :获取list的元素个数
4.lrem
lrem key count element :count>0,删除element开始从左往右删除count次 ; count<0,删除element开始从右往左删除count次 ; count=0,删除所有的element
5.ltrim/lset
ltrim key start stop: 保留[start,stop]间元素
lset key index element: 修改任何位置的元素
6.阻塞式命令
阻塞:一旦list数据为空就会阻塞
blpop和brpop如果在list数据为空就会产生阻塞,直到list中有数据为止,当然可以设置阻塞时间,一旦超时就不再等待.返回一个二元组,哪个key取出哪个数据
blpop key [key...] timeout :一旦多个key存在一个数据,那么就会执行
brpop key [key...] timeout
2.list编码方式
ziplist: 压缩链表,节省空间,适用于元素个数少
linkedlist: 真实链表,适用于元素个数多
quicklist: redis5之后使用现在的结构,结合了ziplist和linkedlist,整体是链表,但是每一个元素是压缩链表
3.应用场景
1.list作为数组,存储多个元素
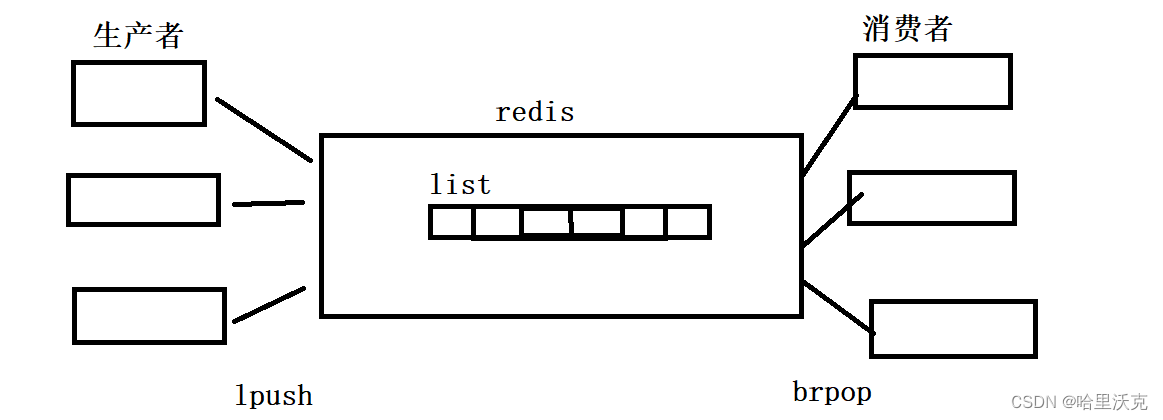
2.消息队列(生产者消费者模型),轮询模型
4.set类型
1.命令
1.sadd/smembers
sadd key member [member...]: 添加set的元素,返回添加成功的元素
smembers key :key中所有的元素
sismember key member :测试某一个member是否存在
2.spop/srandmember
spop key count: 随机删除count个元素
srandmember key count:随机获得count个元素
在源码中,针对spop与srandmember就采取了生成随机数的操作
3.smove/srem
smove key1 key2 member:从key1中删除member再加到key2中
srem key member [member...]: 删除指定元素,返回删除的个数
4.集合间操作
1.交集:
sinter key [key..]: 获取交集,时间复杂度为O(n*m)
sinterstore des key [key..]: 算好交集存到des中
2.并集:
sunion: 求并集,时间复杂度为O(n)
sunionstore des key [key..]: 求并集存到des中
3.差集:
sdiff key [key...]: 第一个key为参考,时间复杂度为O(n)
sdiffstore des key [key..]: 求差集存到des中
2.set编码方式
intset:整数集合,节省空间的特定优化,元素均为整数,元素个数不多的情况下使用
hashtable:哈希表
3.应用场景
1.保存特征形成标签,并且方便计算交集,找到两个集合的公共标签
2.使用set计算用户之间的共同好友
3.使用set统计UV,去重.(pv:page view用户每次访问都会产生一个pv;uv:user view一个用户产生一个uv)
5.zset
1.命令
1.zadd
zadd key [NX | XX] [GT | LT] [CH] [INCR] score member [score member...]: key中添加一个含score的member,返回值为新增的元素个数(不显示修改).时间复杂度为O(logN),主要因为跳表.修改后顺序会自动变换
不加[NX | XX]:不存在member就添加新的member,存在就更新member
NX:存在时不设置,没有member更新member
XC:更新存在的member
LT:只更新存在的元素,更新元素比要被更新的小才更新
GT:只更新存在的元素,更新元素比要被更新的大才更新
CH:返回值进行描述,原本返回添加的元素个数,加入CH则也会返回被修改的元素个数
INCR:对现有member能加减操作
特别的:score可以为浮点数,zset的排序默认为升序方式排列
2.zcard/zcount
zcard key:获取元素个数(member数量).时间复杂度为O(1)
zcount key min max: score在max和min之间的member个数,(max (min这样写不包含两端.时间复杂度为O(logN).max和min可以是浮点数,可以使用inf正无穷大和-inf负无穷大
3.zrange/zrevrange/zrangebyscore
zrange key start end [withscores]:查看[start,end]下标之间的元素,withscores现实members的score.时间复杂度为O(log(N)+M),升序查询
zrevrange key start end [withscores]:降序查询
zrangebyscore key min max [withscores] :查询分数范围内的元素
4.zpopmax
zpopmax key [count] :删掉count个最大的score对应的元素.如果元素的score相同,那么此时删除按照member的大小顺序进行一个一个删除.
删除的是最大的数据,那么其实等于是尾删.其时间复杂度为O(logN)
5.bzpopmax/bzpopmin
bzpopmax key [key...] timeout :删除最大的数一次,zset为空时阻塞,阻塞超时时间为timeout,并且单位为秒,支持小数
bzpopmin key [key...] timeout:删除最小的数一次,zset为空时阻塞,阻塞超时时间为timeout,并且单位为秒,支持小数
时间复杂度都是O(logN),key有很多也是一次
6.zrank/zrevrank/zscore
zrank key member: 查看member对应的下标,member不存在返回空.以升序的顺序算的
zrevrank key member:以逆序的顺序算的
zscore key member:查询指定member的score,时间复杂度为O(1) - 查询优化了
7.zrem/zremrangebyrank/zremrangebyscore
zrem key member [member...]: 删除member元素,返回删除元素个数.时间复杂度为O(logN*M)
zremrangebyrank key start end:下标描述范围进行删除元素.时间复杂度为O(logN+M)
zremrangebyscore key start end:分数描述区间进行删除元素.时间复杂度为O(logN+M)
8.zincrby
zincrby key increment member:对member的score增加increment
9.有序集合间关系操作
zinter交集,zunion并集,zdiff差集 -- redis6.2之后支持的
zinterstore des numkeys key [key...] [WEIGHT weight [weight...]] [AGGREGATE <SUM | MIN | MAX>]:交集,存在指定key中
zunionstore des numkeys key [key...] [WEIGHT weight [weight...]] [AGGREGATE <SUM | MIN | MAX>]:并集,存在指定key中
numkeys:多少个key进行交集运算.之所以需要显示,是因为若干个keys之后还有可有可无的操作,需要进行区分
WEIGHT:乘以权重,操作的优先级标准.即对member求交集同时要计算score权重的占比.要算权重那WEIGHT必须写
AGGREGATE:总数合计.SUM为score的总和,MIN为score最小值,MAX为score的最大值
zinterstore的时间复杂度为O(N*K)+O(M*logM),N为最小zset个数,K为numkey,M最终个数.约等于O(M*logM)
zunionstor的时间复杂度为O(N)+O(M*logM),N为所有zset个数
2.zset的编码方式
1.ziplist:适用于元素个数少,单个元素体积小.节省内存空间
2.skiplist:适用于元素个数多,单个元素体积大.查询的时间复杂度为O(logN)
3.应用场景
关键场景:实时的排行榜,可以高效更新
游戏排行看分数,单一的
其他综合热度,需要进行权重计算