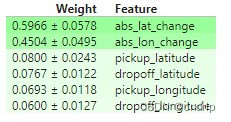
浏览因特网资源
- URI是一类更通用的资源标识符,URL与URN是它的子集
- URL通过描述资源的位置来标识资源
- HTTP规范将更通用的概念URI作为资源标识符,实际上,HTTP应用程序处理的知识URI的URL子集
- URL可以通过HTTP之外的其他协议来访问资源。
http链接一般由协议,服务器的位置(域名),资源路径组成,如下图
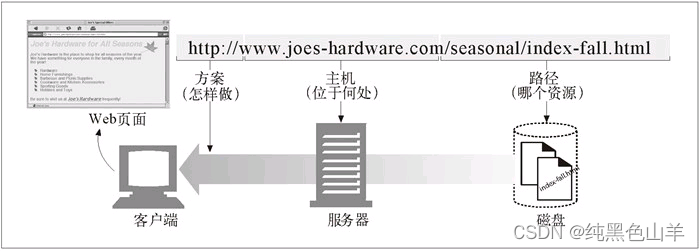
URL语法
URL通过不同方案进行不同资源的访问,不同方案URL语法会有些差异;但大多数URL方案的URL语法如下:
/**
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
*/
URL最重要的三个部分是方案(scheme),主机(host)和路径(path),具体说明如下表:
| 组件 | 描述 | 默认值 |
|---|---|---|
| 方案(scheme) | 访问服务器获取资源时要使用哪种协议 | 无 |
| 用户(user) | 某些方案访问资源时需要的用户名 | 匿名 |
| 密码(password) | 用户名后买你可能要包含的密码,中间由冒号(:)分隔 | <E-mail地址 |
| 主机或域名(host) | 资源宿主服务器的主机名或点分IP地址 | 无 |
| 端口(port) | 资源宿主服务器正在监听的端口号。很多方案都有默认的端口号(HTTP的默认端口号为80) | 每个方案特有 |
| 路径(path) | 服务器上资源的本地名,由一个斜杠(/)将其与前面URL组件分隔开来。路径组件的语法是与服务器和方案有关的 | 无 |
| 参数(params) | 某些方案会用这个组件来指定输入参数。参数为名/值对。URL中可以包含多个参数字段,它们相互之间以及与路径的其余部分用(;)分隔 | 无 |
| 查询(query) | 某些方案会用这个组件传递参数以激活应用程序。查询组件的内容没有通用格式。用字符”?"将其与其余部分分隔开来 | 无 |
| 片段(frag) | 一片或一部分资源的名字。引用对象时,不会将frag字段传送给服务器;这个字段是在客户端内部使用的。通过字符“#”将其与其余部分分隔开来 | 无 |
方案
- 规定如何访问指定资源的主要标识符,URL的应用程序会根据此进行解析
- 方案组件必须以一个字母符号开始,由第一个":"符号将其与URL其他部分分隔开来
- 方案名与大小写无关http:与HTTP:是等价的
主机与端口
* 主机组件标识了能够访问资源的宿主机器(域名或IP地址)
*端口组件标识了服务器正在监听的网络端口
用户名和密码
- 很多服务器都要求输入用户名和密码才允许用户访问数据
- 如果应用程序是用的URL方案要求输入用户名和密码,但用户没有提供,通常会插入一个默认的用户名和密码
路径
- 说明资源位于服务器的什么地方
- 路径通常像一个分级的文件系统路径
- 每段路径都有自己的参数(params)组件
参数
- 在URL中以字符;分隔URL其他部分
- 以名值对的形式存在
查询字符串
- 以?分隔URL其他部分
- 以名值对的形式存在,多个名值对用&分隔
片段
- 以#号分隔URL其他部分
- HTTP服务器通常只处理整个对象,而不是对象的片段,客户端不能将片段传送给服务器
- 浏览器会根据片段来显示对应的部分资源
URL快捷方式
指Web客户端可以理解并使用的几种快捷方式
相对URL
- 相对URL是不完整的URL,需要依靠另一个被称为基础(base)的URL进行解析
- 相对URL是URI的一种便捷缩略记法
- 为一组资源的可移植性提供了一种便捷方式(如HTML与其相应的资源)
基础URL
基础URL是作为相对URL参考点是用,可以来自以下几个不同的地方
- 在资源中显示提供
有些资源会显式地指定URL。如,HTML文档中可能会包含一个定义了基础URL的HTML标记,通过它来转换那个HTML文档中的所有相对URL - 封装资源的基础URL
没有显示指定的基础URL的资源中时,使用所属资源的URL作为基础 - 没有基础URL
某些情况下,没有基础URL,可能得到的是一个不完整或损坏的URL
解析相对引用
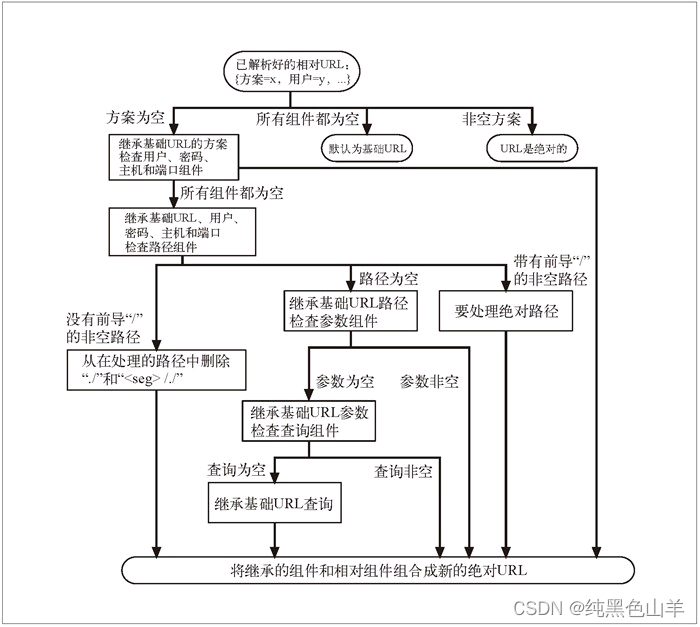
自动扩展URL
用户不需要输入完整的URL,浏览器会自动扩展。有以下两种方式
- 主机名扩展:只要有些小提示,浏览器通常就可以在没有帮助的情况下,将输入的主机名扩展为完整的主机名
- 历史扩展:将以前访问过的URL历史存储起来。当输入URL时,将输入URL与历史记录中的URL的前缀进行匹配,并提供一些完整的选项可以选择;
字符
URL是可移植的。它要统一第命名因特网上的所有资源,并且需要符合不同协议的传输规范,所以只能使用较小的,通用的安全字母表中的字符。但使用过程中,会遇到传递除安全字符外的其他字符,此时,就需要进行转义,再进行传输;
URL字符集
URL使用的字符集为US-ASCII字符集,有如下原因:
- 计算机系统字符集通常倾向于以英语为中心,很多计算机应用程序使用的都是US-ASCII字符集
- 历史悠久,可移植性好。通过转义序列,可以使用US-ASCII字符集的有限子集对任意字符值或数据进行编码,实现了可移植性与完整性
编码机制
使用转义来表示不安全字符,此转义表示法包含一个百分号(%),后面跟着两个字符ASCII码的十六进制数,常用的转义字符如:
| 字符 | ASCII码 | 示例 |
|---|---|---|
| ~ | 126(0x7E) | https://xxx/%07E |
| 空格 | 32(0x20) | https://xxx/%20xxx |
| % | 37(0x25) | https://xxx/100%25 |
字符限制
URL中,有几个字符被保留起来,有特殊含义,有些字符不在定义的US-ASCII可打印字符集中,有些则会与某些因特网网关和协议产生混淆。以下字符,除了用于保留用途之外的场合时,要在URL中进行编码
| 字符 | 保留/受限 |
|---|---|
| % | 保留作为编码字符的转义标志 |
| / | 保留作为路径组件中分隔路径段的界定符 |
| . | 保留在路径组件中使用 |
| … | 保留在路径组件中使用 |
| # | 保留作为分段定界符使用 |
| ? | 保留作为查询字符串定界符使用 |
| ; | 保留作为参数定界符使用 |
| : | 保留作为方案、用户/口令,以及主机/端口组件的定界符自用 |
| $ , + | 保留 |
| @ & = | 在某些方案的上下文中有特殊含义,保留 |
| { } | \ ^ ~ [ ] ‘ | 由于各种Agent代理,比如各种网关的不安全处理,使用受限 |
| < > " | 不安全;这些字符在URL范围之外通常是有意义的,比如在文档中对URL自身进行定界,所以应该对其进行编码 |
| 0x00-0x1F,0x7F | 受限,这些十六进制范围内的字符都在US-ASCII字符集的不可打印区间内 |
| >0x7F | 受限,十六进制值在此范围内的字符都不在US-ASCII字符集的7比特范围内 |