本文主要介绍了Prompt设计、大语言模型SFT和LLM在手机天猫AI导购助理项目应用。

ChatGPT基本原理
“会说话的AI”,“智能体”
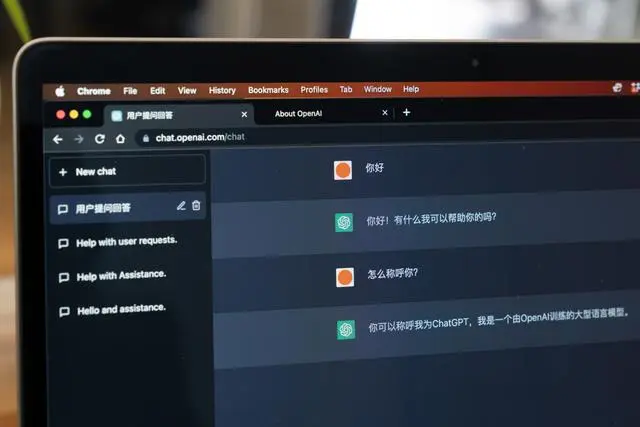
简单概括成以下几个步骤:
预处理文本:ChatGPT的输入文本需要进行预处理。
输入编码:ChatGPT将经过预处理的文本输入到神经网络中进行编码处理,使用的是多层transformer编码器结构。
预测输出:ChatGPT通过对输入进行逐个token预测,输出下一个最可能出现的token序列,使用的是softmax函数进行概率预测。
输出解码:ChatGPT将预测的token序列作为输入,经过多层transformer解码器结构进行解码处理,最终输出模型的回答。
重复步骤3和4:ChatGPT在处理输入时会持续输出预测的token序列,直到遇到停止符号或达到最大输出长度为止。
算法内核——Transformer
由 Encoder 和 Decoder 两个部分组成
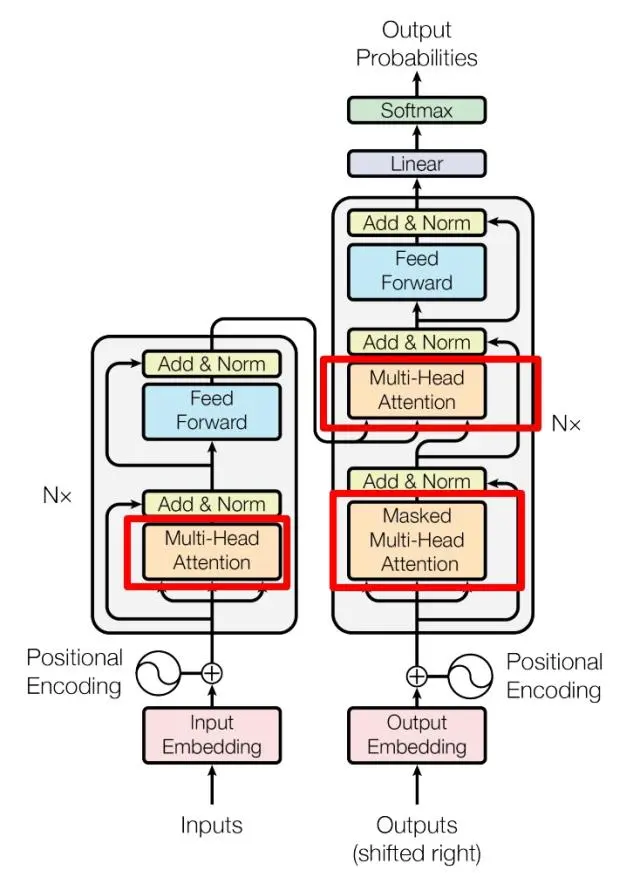
编解码动画

Prompt设计
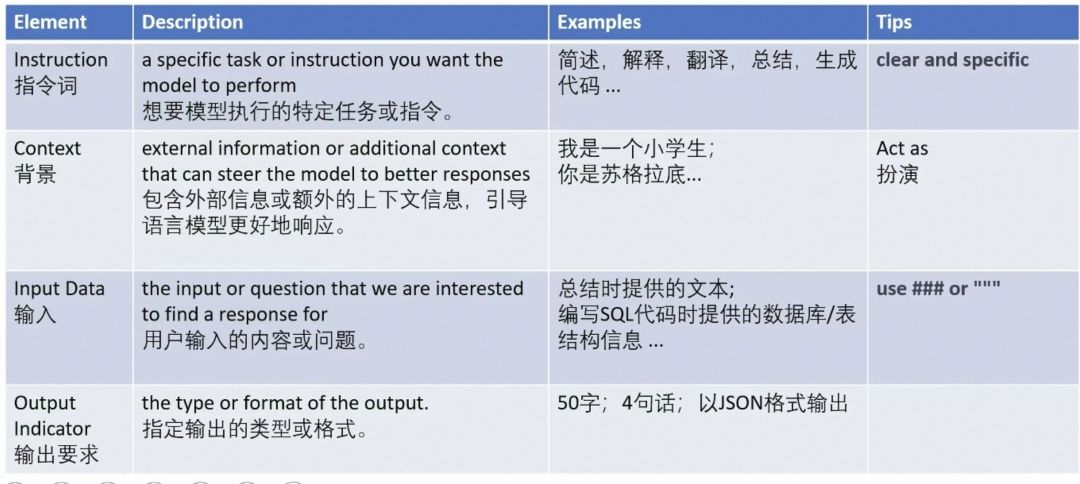
▐ 什么是prompt?
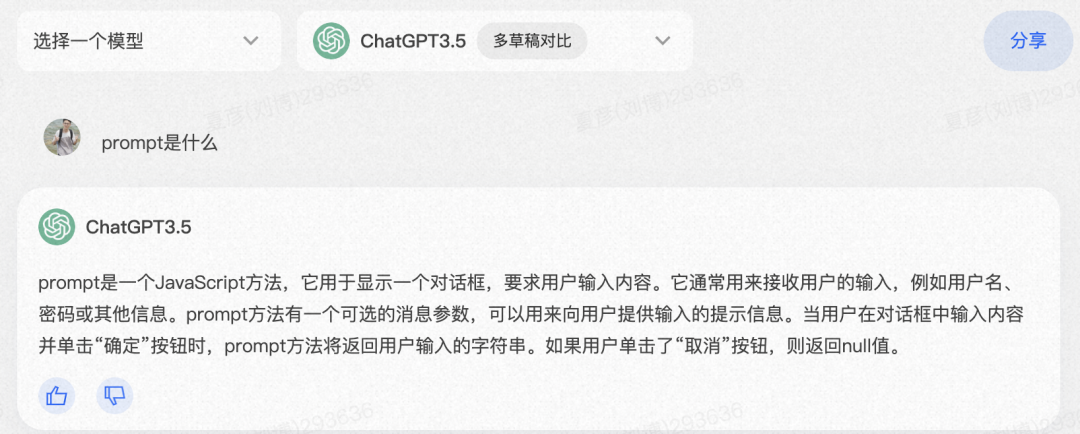
看来跟我今天想分享的不太一样,加个具体的限定条件,然后呢?

这下对了!
Prompt的不同能直接决定模型是否能按我们的预期输出
▐ prompt基本技巧
1.清晰,明确,避免模糊的词语
| bad case | good case |
| 产品描述不应该太短,用一些句子就行,也不用特别多 | 用3到5个短语描述这个产品 |
给手机天猫写首诗
| 给手机天猫写一首四句的古文诗,模仿李白的《早发白帝城》
|


2.用###或者"""或者<>或者'''将指令和待处理的内容分开
| bad case | good case |
| 将下面内容总结为一句话。你应该提供尽可能清晰和具体的指令来表达你想让模型做什么。这将引导模型朝着期望的输出方向发展,并减少收到无关或不正确响应的可能性。不要混淆写一个清晰的提示和写一个简短的提示。在许多情况下,更长的提示提供更多的清晰度和上下文,这可以导致更详细和相关的输出。 | 将下面用三个引号括起来的内容总结为一句话: 需要总结的文本是: ''' 你应该提供尽可能清晰和具体的指令来表达你想让模型做什么。这将引导模型朝着期望的输出方向发展,并减少收到无关或不正确响应的可能性。不要混淆写一个清晰的提示和写一个简短的提示。在许多情况下,更长的提示提供更多的清晰度和上下文,这可以导致更详细和相关的输出。 ''' |
3.指定输出格式
| bad case | good case |
生成三个虚构书名,包括它们的作者和类型。
| 生成三个虚构书名,包括它们的作者和类型。以JSON列表的格式提供,包括以下键:book_id、title、author、genre
|


4.角色扮演,用扮演、担任等这一类词汇告诉大模型在对话中特定的人格或角色
| bad case | good case |
给我推销一款男士洗面奶
| system:我想让你扮演一个专业的导购员。你可以充分利用你的电商知识、导购话术,生动活泼的帮顾客介绍推销商品。 user:给我推销一款男士洗面奶
|


▐ Few shot进阶
启用上下文in-context learning学习,在prompt中提供几个样例(这里只有一个例子one-shot)

▐ Chain of Thought(Cot)
思维链(CoT)是一种改进的提示策略,用于提高 LLM 在复杂推理任务中的性能,如算术推理、常识推理和符号推理。
| one-shot | Cot |
model input: Q:小明有5个球,他又买了2筐,每一筐有3个球。那么他现在总共有几个球? A:答案是11 Q:小花有23个苹果,他们午餐用去了20个,又买了6个。那么现在还有多少个苹果? model output:
| model input: Q:小明有5个球,他又买了2筐,每一筐有3个球。那么他现在总共有几个球? A:小明开始有5个球,又买了2筐球,每筐3个共6个球,合计11个球,答案是11 Q:小花有23个苹果,他们午餐用去了20个,又买了6个。那么现在还有多少个苹果? model output:
|


上面的例子很好的激发了大模型的潜能,是否有prompt技巧无能为力的问题?
答案是肯定的,一些偏实时,模型训练过程中缺乏的语料知识,它也无能为力。
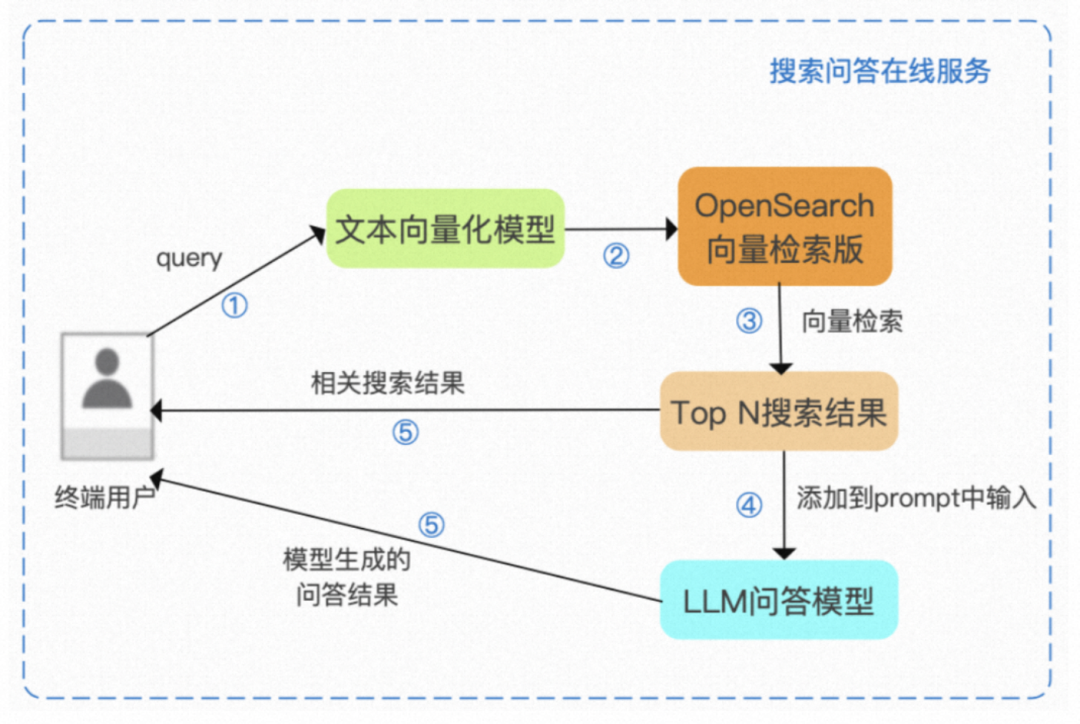
▐ Search API & GPT

"""
网页搜索结果:
{web_results}
当前日期:{current_date}
指令: 用给定的网络搜索结果,总结回复用户query
用户Query: {query}
回复语言: {reply_language}
"""私有化知识库(嵌入式向量检索+LLM)
▐ ReAct框架
大模型Agent功能,大模型会自己分析问题,选择合适的工具,最终解决问题。
ReAct方式的作用就是协调LLM模型和外部的信息获取,与其他功能交互。如果说LLM模型是大脑,那ReAct框架就是这个大脑的手脚和五官。
| 关键概念 | 描述 |
| Thought | 由LLM模型生成,是LLM产生行为和依据 |
| Act | Act是指LLM判断本次需要执行的具体行为 |
| Obs | LLM框架对于外界输入的获取。 |
尽可能回答以下问题,可以使用工具:
{工具名和描述}
使用以下格式回答:
问题:你必须回答的问题
思考:你应该一致保持思考,思考要怎么解决问题
动作:{工具名}。每次动作只选择一个工具,工具列表{工具名和描述}
输入:{调用工具时需要传入的参数}
观察:{第三方工具返回的结果}
【思考-动作-输入-观察】循环N次
思考:最后,输出最终结果
最终结果:针对原始问题,输出最终结果开始!
问题:上海最高楼是多少?它楼层高度的平方是多少?
思考:我需要知道上海最高楼,然后进行计算。
动作:搜索API
观察:632米
思考:我需要计算上海最高楼高度的平方,然后得到结果。
动作:计算器
输入:632^2
观察:399424
思考:
最终结果:上海最高楼632米,它的高度平方是399424
大模型SFT(supervised fine tuning)
▐ 预训练 VS 微调
预训练:模型以一种无监督的方式去训练,学习根据前文生成下一个单词。在海量数据下进行,让大模型具备语言理解和生成能力。
指令微调:有监督的方式进行学习,包括任务描述,输入等,去预测答案。目标是如何跟人类指令对齐,让模型更加适应专业化领域场景
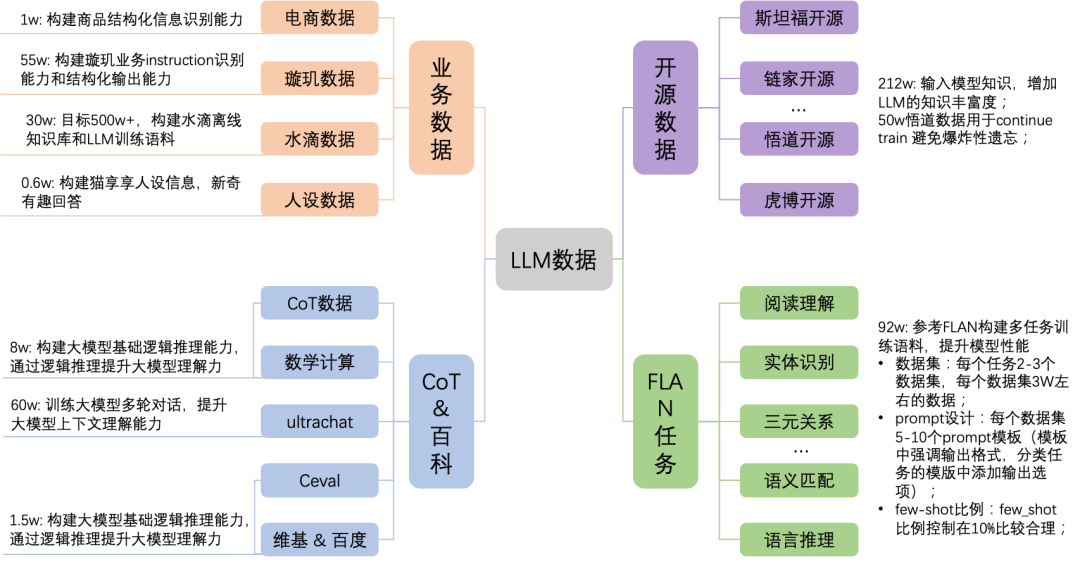
业务数据从哪来?
人工标注
种子数据 + self-instruct(gpt 3.5构造)

▐ P-tuning
动机:Fine-tuning需要微调整个预训练语言模型,且额外添加了新的参数,而Prompting则可以将整个预训练语言模型的参数保持固定,而只需要添加prompt来预测结果即可;
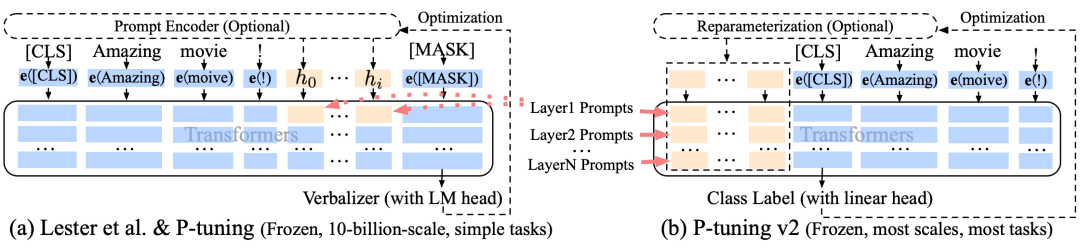
P-tuning:将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
P-tuning V2:每一层都加入可训练的prompts,只对Prompt部分的参数进行训练,而语言模型的参数固定不变。
▐ LoRA
Low-rank Adaption of LLM,利用低秩适配(low-rank adaptation)的方法,可以在使用大模型适配下游任务时只需要训练少量的参数即可达到一个很好的效果。在计算资源受限的情况下的弥补方案。
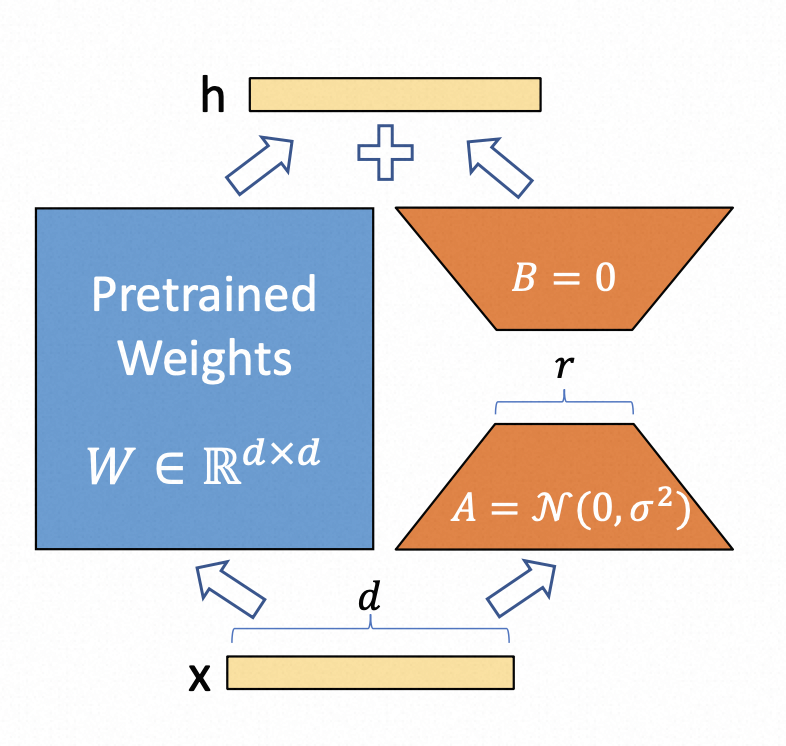

对于不同的下游任务,只需要在预训练模型基础上重新训练AB就可以了,这样也能加快大模型的训练节奏。
▐ LoRA VS 全参数微调
lora的优点在于轻量化,低资源。但缺点很明显,参与训练的模型参数量不多,在百万到千万级别的参数量,实验来看效果比全量微调差一些。
▐ C-Eval评估
C-Eval由上海交通大学,清华大学,爱丁堡大学共同完成,是构造了一个覆盖人文,社科,理工,其他专业四个大方向,52 个学科(微积分,线代 …),从中学到大学研究生以及职业考试,一共 13948 道题目的中文知识和推理型测试集。
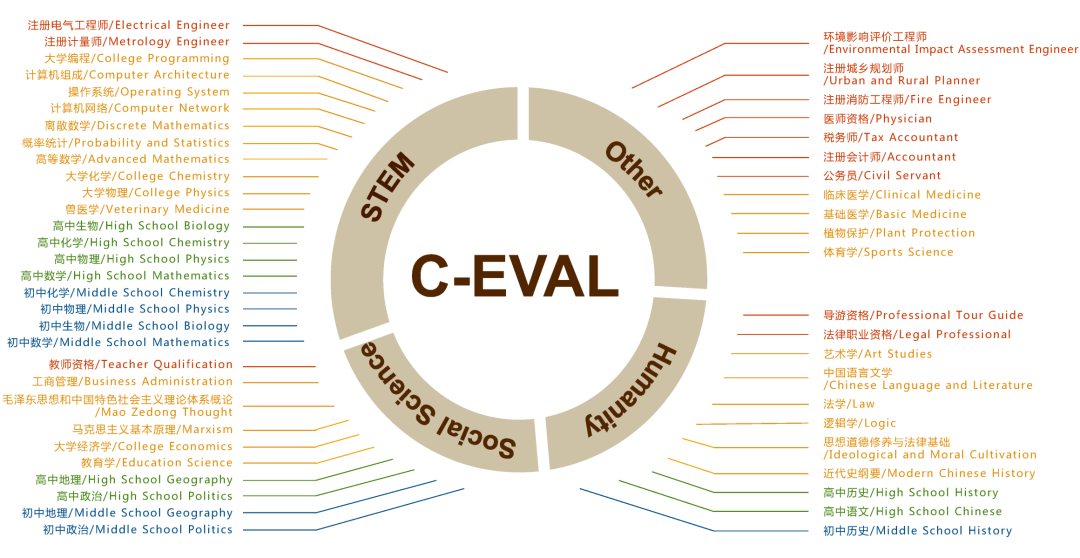
C-Eval认为:一个模型要强,首先需要广泛的知识,然后在知识的基础上做推理,这样才能代表一个模型可以做复杂且困难的事情。
此外,还有一些公开评测集,用于评估模型在学科综合、语言能力、推理能力等。


手机天猫AI导购助理项目落地应用
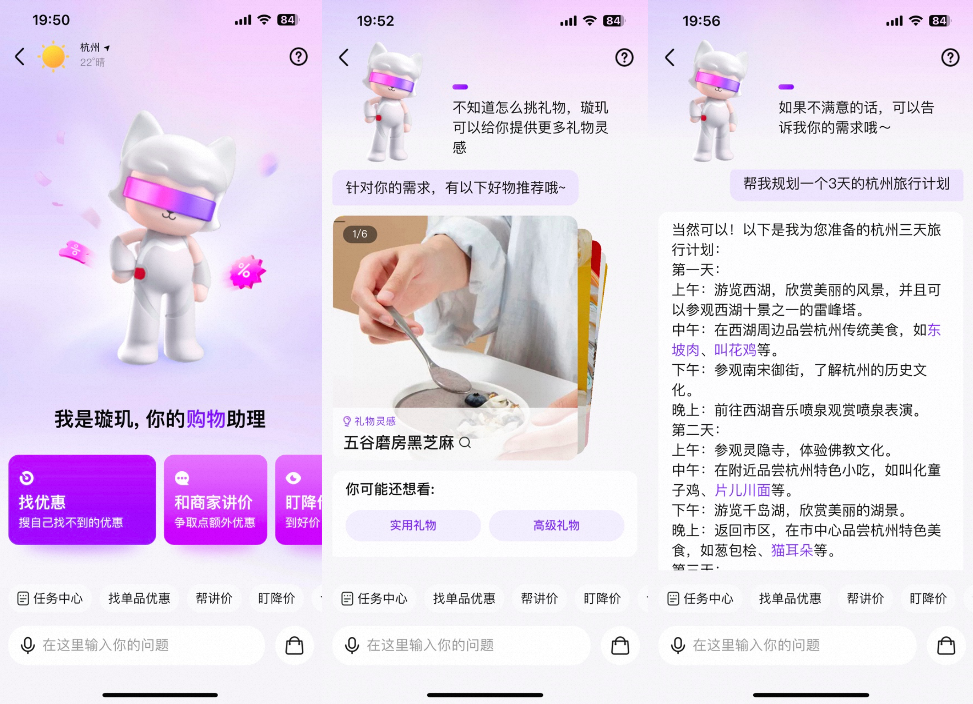
▐ 项目背景
“AI形象”璇玑作为个人专属导购员,在交互式对话中进行用户理解、导购商品。
定位:交互式搜索导购产品
▐ 算法框架
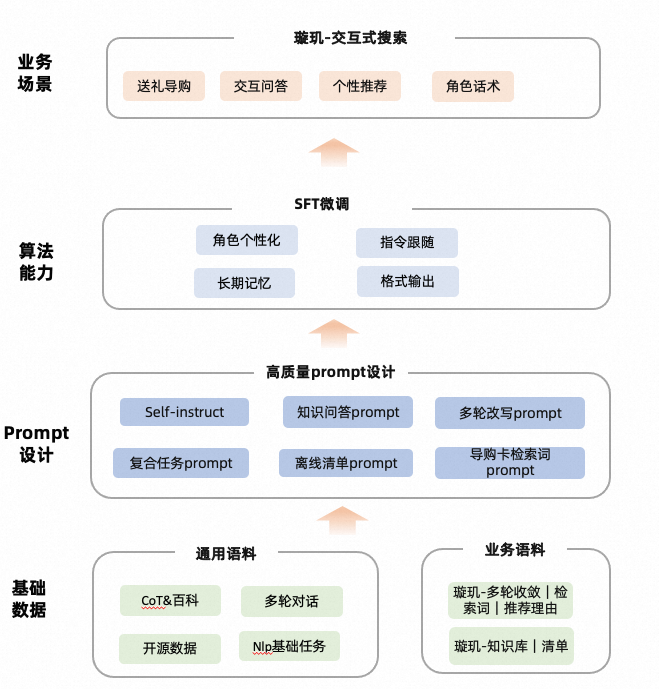
▐ 语料收集
电商种子问题收集:端内会话日志、小红书sug收集电商领域种子问题:
问题泛化:明确场景问题定义,通过手猫核心query、种子问题等,设计prompt,通过gpt补充收集问题;
人工标注: 标注高质量语料;
self-instruction:通过prompt(few-shot)方法根据已有人工标注扩充新的instruction。通过gpt获取更多训练语料,解决标注人效瓶颈。
▐ 模型训练
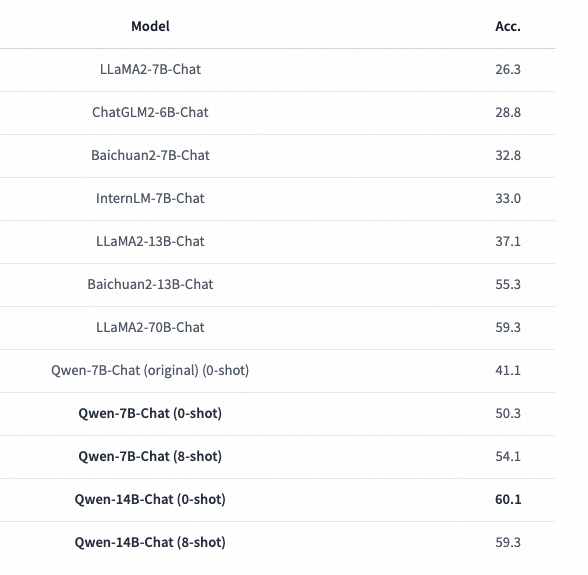
base模型选型
中文评测

数学评测
训练平台:AOP/星云/PAI
基于达摩院模型基座qwen-14B,针对璇玑产品,新增电商领域的训练数据,增强模型的电商领域知识、安全、导购等能力。
params="--stage sft \
--model_name_or_path /data/oss_bucket_0/Qwen_14B_Chat_ms_v100/ \
--do_train \
--dataset_dir data \
--dataset xuanji \
--template chatml \
--finetuning_type full \
--output_dir file_path \
--overwrite_cache \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 5 \
--save_strategy epoch \
--save_steps 10000 \
--learning_rate 2e-6 \
--num_train_epochs 3.0 \
--warmup_ratio 0.15 \
--warmup_steps 0 \
--weight_decay 0.1 \
--fp16 ${fp16} \
--bf16 ${bf16} \
--deepspeed ds_config.json \
--max_source_length 4096 \
--max_target_length 4096 \
--use_fast_tokenizer False \
--is_shuffle True \
--val_size 0.0 \
"pai -name pytorch112z
-project algo_platform_dev
-Dscript='${job_path}'
-DentryFile='-m torch.distributed.launch --nnodes=${workerCount} --nproc_per_node=${node} ${entry_file}'
-DuserDefinedParameters=\"${params}\"
-DworkerCount=${workerCount}
-Dcluster=${resource_param_config}
-Dbuckets=${oss_info}${end_point}训练中间过程

▐ 模型部署&调用
达摩院千问
模型基于allspark做量化加速,部署在dashscope平台,机器为双卡A10。
# For prerequisites running the following sample
import dashscope
from dashscope import Generation
from http import HTTPStatus
dashscope.api_key = 'your-dashscope-api-key'
response_generator = Generation.call(
model='model_name',
prompt=build_prompt([
{'role':'system','content':'content_info'},
{'role':'user', 'content':'query'}
]),
stream=True,
use_raw_prompt=True,
seed=random_num
)
for resp in response_generator:
# when stream, you need to get the result through iteration
if resp.status_code == HTTPStatus.OK:
print(resp.output)
else:
print('Failed request_id: %s, status_code: %s, \
code: %s, message:%s' %
(resp.request_id, resp.status_code, resp.code, resp.message))
# Result:
# {"text": "汝亦来", "finish_reason": "null"}
# {"text": "汝亦来哉,幸会。\n\n汝可", "finish_reason": "null"}
# {"text": "汝亦来哉,幸会。\n\n汝可唤我一声「百晓生", "finish_reason": "null"}
# {"text": "汝亦来哉,幸会。\n\n汝可唤我一声「百晓生」,不知可否?", "finish_reason": "null"}
# {"text": "汝亦来哉,幸会。\n\n汝可唤我一声「百晓生」,不知可否?", "finish_reason": "stop"}Whale私有化
部署发布:
模型管理:
from whale import TextGeneration
import json
# 设置apiKey
# 预发或线上请勿指定base_url
TextGeneration.set_api_key("api_key", base_url="api_url")
# 设置模型生成结果过程中的参数
config = {"pad_token_id": 0, "bos_token_id": 1, "eos_token_id": 2, "user_token_id": 0, "assistant_token_id": 0, "max_new_tokens": 2048, "temperature": 0.95, "top_k": 5, "top_p": 0.7, "repetition_penalty": 1.1, "do_sample": False, "transformers_version": "4.29.2"}
prompt = [
{
"role": "user",
"content": "content_info"
}
]
# 请求模型
response = TextGeneration.call(
model="model_name",
prompt=json.dumps(prompt),
timeout=120,
streaming=True,
generate_config=config)
# 处理流式结果
for event in response:
if event.status_code == 200:
print(event.finished)
if event.finished is False:
print(event.output['response'], end="")
else:
print('error_code: [%d], error_message: [%s]'
% (event.status_code, event.status_message))EAS
借助EAS,将代码和模型文件分离进行LLM服务部署,基于http协议提供流式输出。模型存储在oss上。
▐ 模型评测
基础能力评测:在公开评测集上评估模型中英文、推理、知识问答能力表现。
业务评测:以业务人工评测为主,每个大模型任务150个评测问题。
体验问题:埋点日志获取,定期review。

参考链接
1.https://www.semanticscholar.org/paper/Attention-is-All-you-Need-Vaswani-Shazeer/204e3073870fae3d05bcbc2f6a8e263d9b72e776
2.https://huggingface.co/Qwen/Qwen-14B-Chat
3.https://github.com/yuanzhoulvpi2017/zero_nlp
4.https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
5.https://www.bilibili.com/video/BV1jP411d7or/?spm_id_from=333.337.search-card.all.click
6.https://arxiv.org/pdf/2305.08322v1.pdf
7.https://zhuanlan.zhihu.com/p/630111535?utm_id=0
8.https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
9.https://github.com/tatsu-lab/stanford_alpaca

团队介绍
我们是淘天集团下FC技术部智能策略团队,主要负责手机天猫的推荐和广告算法的研发与优化工作,为用户提供更精准的推荐服务,提高用户体验和满意度。此外,团队还致力于AI技术的创新应用,如智能导购等领域,并积极探索创新性的业务实践。
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法