目录
一、Spark On Hive原理
(1)为什么要让Spark On Hive?
二、MySQL安装配置(root用户)
(1)安装MySQL
(2)启动MySQL设置开机启动
(3)修改MySQL密码
三、Hive安装配置
(1)修改Hadoop的core-site.xml
(2)创建hive-site.xml
(3)修改配置文件hive-env.sh
(4)上传mysql连接驱动
(5)初始化元数据 (Hadoop集群启动后)
(6)创建logs目录,启动元数据服务
(7)启动Hive shell
四、Spark On Hive配置
(1)创建hive-site.xml(spark/conf目录)
(2)放置MySQL驱动包
(3)查看hive的hive-site.xml配置
(4)启动hive的MetaStore服务
(5)Spark On Hive测试
(6)Pycharm-spark代码连接测试
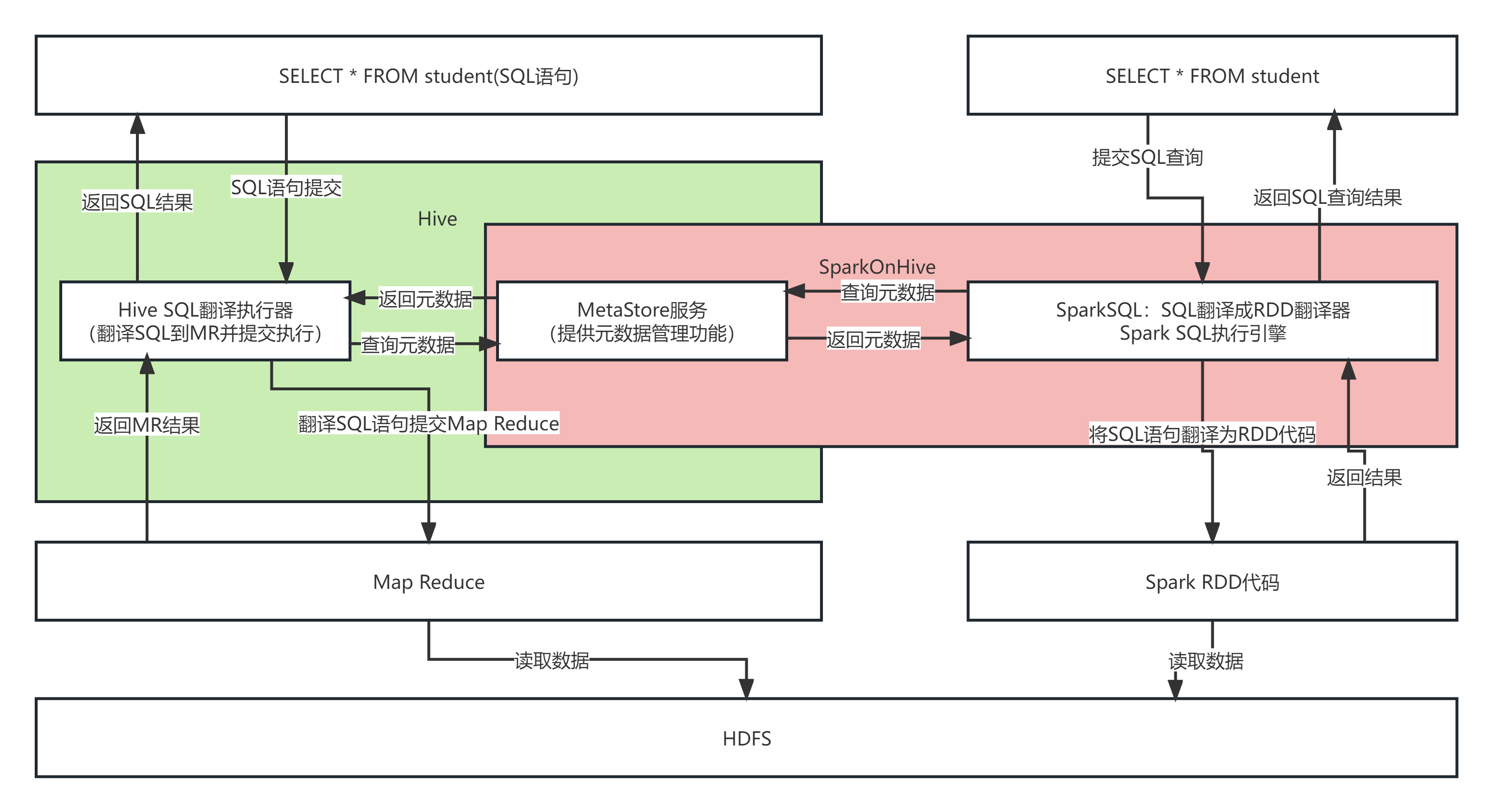
一、Spark On Hive原理
(1)为什么要让Spark On Hive?
对于Spark来说,自身是一个执行引擎。但是Spark自己没有元数据管理功能,当我们执行: SELECT * FROM person WHERE age > 10的时候, Spark完全有能力将SQL变成RDD提交。
但是问题是,Person的数据在哪? Person有哪些字段?字段啥类型? Spark完全不知道了。不知道这些东西,如何翻译RDD运行。在SparkSQL代码中可以写SQL那是因为,表是来自DataFrame注册的。 DataFrame中有数据,有字段,有类型,足够Spark用来翻译RDD用.。如果以不写代码的角度来看,SELECT * FROM person WHERE age > 10 spark无法翻译,因为没有元数据。
解决方案:
Spark提高执行引擎能力,Hive的MetaStore提供元数据管理功能。选择Hive的原因是使用Hive的用户数量多。
二、MySQL安装配置(root用户)
(1)安装MySQL
命令:
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
rpm -Uvh https://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
yum -y install mysql-community-server


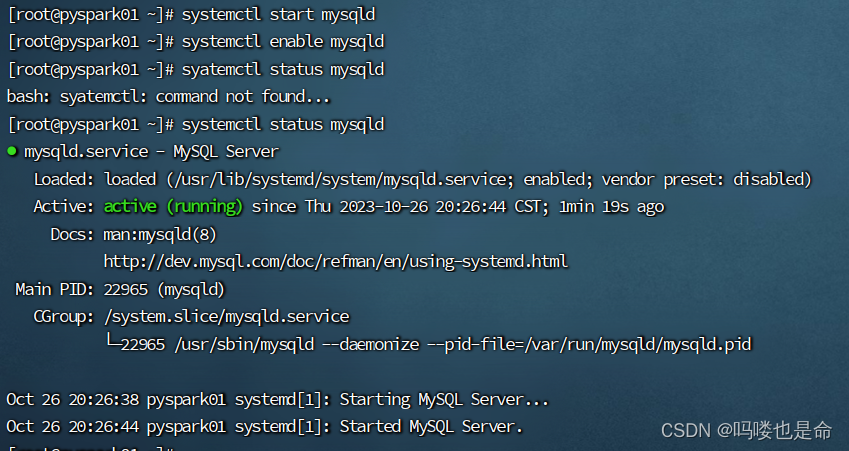
(2)启动MySQL设置开机启动
命令:
systemctl start mysqld
systemctl enable mysqld
(3)修改MySQL密码
命令:
查看密码:grep 'temporary password' /var/log/mysqld.log
修改密码:
mysql -uroot -p #登录MySQL,密码是刚刚查看的临时密码
set global validate_password_policy=LOW; #密码安全级别低
set global validate_password_length=4; #密码长度最低四位
ALTER USER 'root'@'localhost' IDENTIFIED BY '密码'; # 设置用户和密码
# 配置远程登陆用户以及密码
grant all privileges on *.* to root@"%" identified by 'root' with grant option;
flush privileges;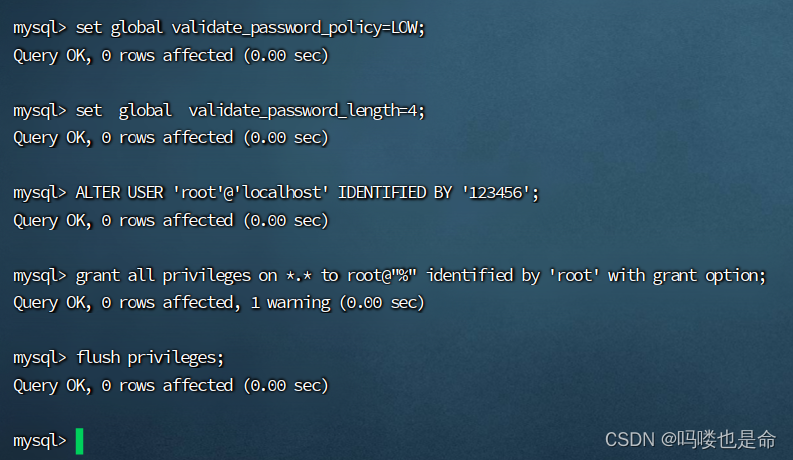
三、Hive安装配置
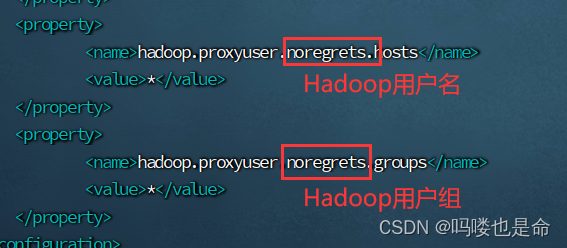
(1)修改Hadoop的core-site.xml
添加内容如下:
<property>
<name>hadoop.proxyuser.noregrets.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.noregrets.groups</name>
<value>*</value>
</property>
上传解压安装Hive压缩包并构建软连接
命令:
解压:tar -zvxf apache-hive-3.1.3-bin-tar-gz -C /export/servers
构建软连接:ln -s /export/servers/apache-hive-3.1.3-bin/ /export/servers/hive

(2)创建hive-site.xml
命令:
cd /export/servers/hive/conf
vim hive-site.xml
添加内容如下:
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://pyspark01:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>pyspark01</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://pyspark01:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
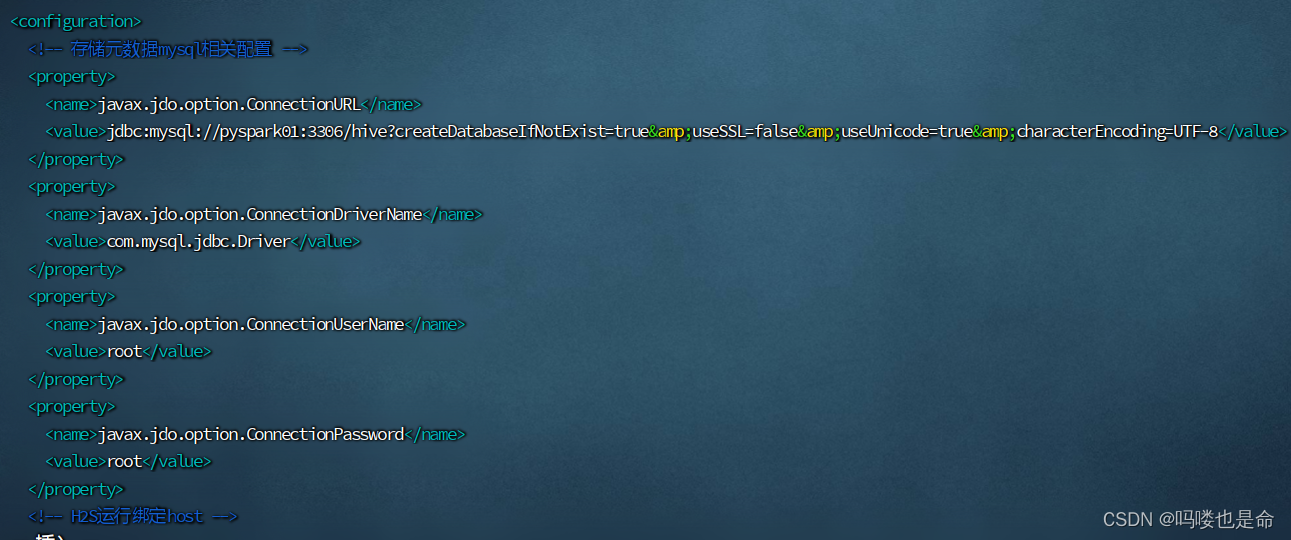
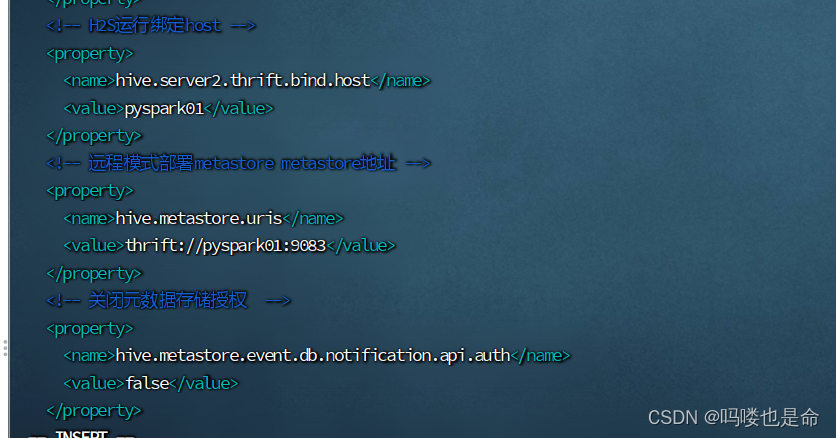
(3)修改配置文件hive-env.sh
命令:
cd /export/servers/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh(修改第48行内容)
内容如下:
export HADOOP_HOME=/export/servers/hadoop
export HIVE_CONF_DIR=/export/servers/hive/conf
export HIVE_AUX_JARS_PATH=/export/servers/hive/lib

(4)上传mysql连接驱动
链接:https://pan.baidu.com/s/1MJ9QBsE3h1FAxuB3a4iyVw?pwd=1111
提取码:1111
MySQL5使用5的连接版本,MySQL8使用8的连接版本。
(5)初始化元数据 (Hadoop集群启动后)
命令:
登录数据库:
mysql -uroot -p
CREATE DATABASE hive CHARSET UTF8; #建表
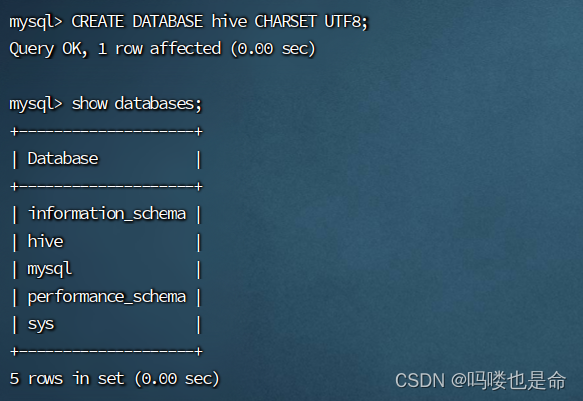

cd /export/server/hive/
bin/schematool -initSchema -dbType mysql -verbos
#初始化成功会在mysql中创建74张表

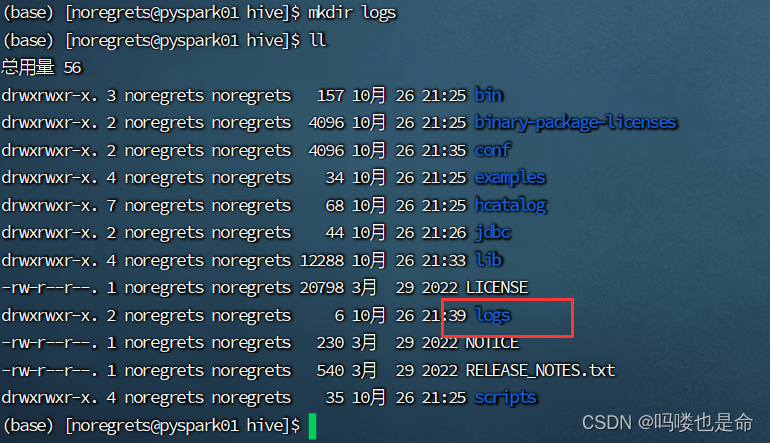
(6)创建logs目录,启动元数据服务
命令:
创建文件夹:mkdir logs
启动元数据服务:nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &

(7)启动Hive shell
命令:bin/hive(配置环境变量可直接使用hive)

四、Spark On Hive配置
(1)创建hive-site.xml(spark/conf目录)
添加内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--告知Spark创建表存到哪里-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<!--告知Spark Hive的MetaStore在哪-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://pyspark01:9083</value>
</property>
</configuration>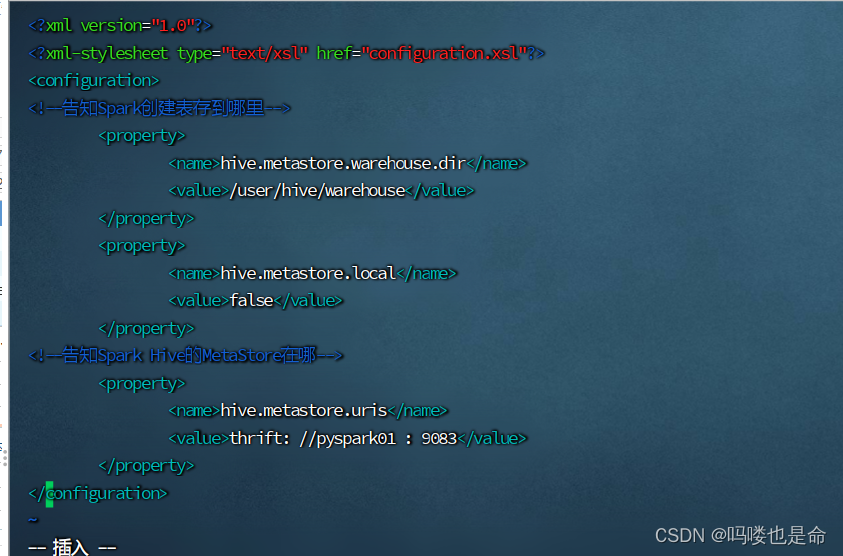
(2)放置MySQL驱动包

(3)查看hive的hive-site.xml配置
确保有如下配置:

(4)启动hive的MetaStore服务
命令:
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
(5)Spark On Hive测试
①创建表sparkonhive
命令:
在spark目录下:
bin/spark
spark.sql('create table sparkonhive(id int)' )

②进入查看查看
命令:
hive目录:
bin/hive(配置过环境变量可直接使用hive)

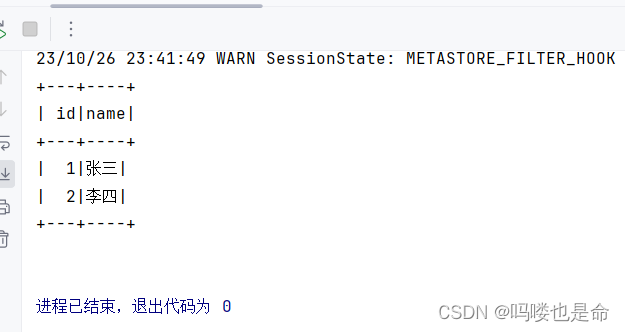
(6)Pycharm-spark代码连接测试
在Linux的sparkSQl终端或者hive终端创建学生表,然后使用spark代码查询。
命令:
create table student(id int, name string);
insert into student values(1,'张三'),(2, '李四');
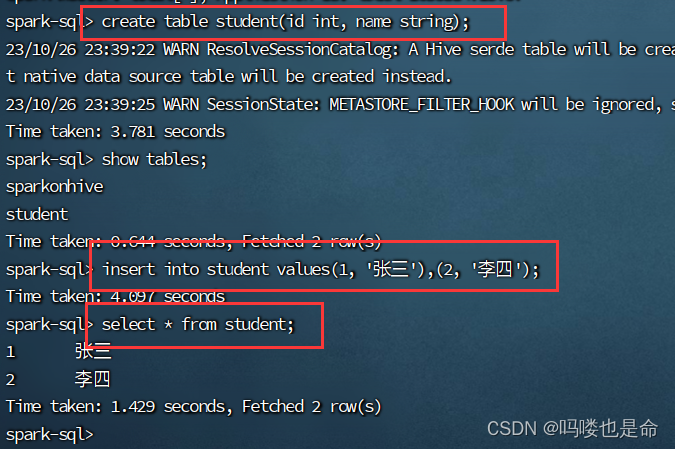
使用spark代码查询
在Spark代码中加上如下内容

# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':
spark = SparkSession.builder.\
appName('udf_define').\
master('local[*]').\
config('spark.sql.shuffle.partitions', 2).\
config('spark.sql.warehouse.dir', 'hdfs://pyspark01:8020/user/hive/warehouse').\
config('hive.metastore.uris', 'thrift://pyspark01:9083').\
enableHiveSupport().\
getOrCreate()
sc = spark.sparkContext
spark.sql('''
SELECT * FROM student
''').show()