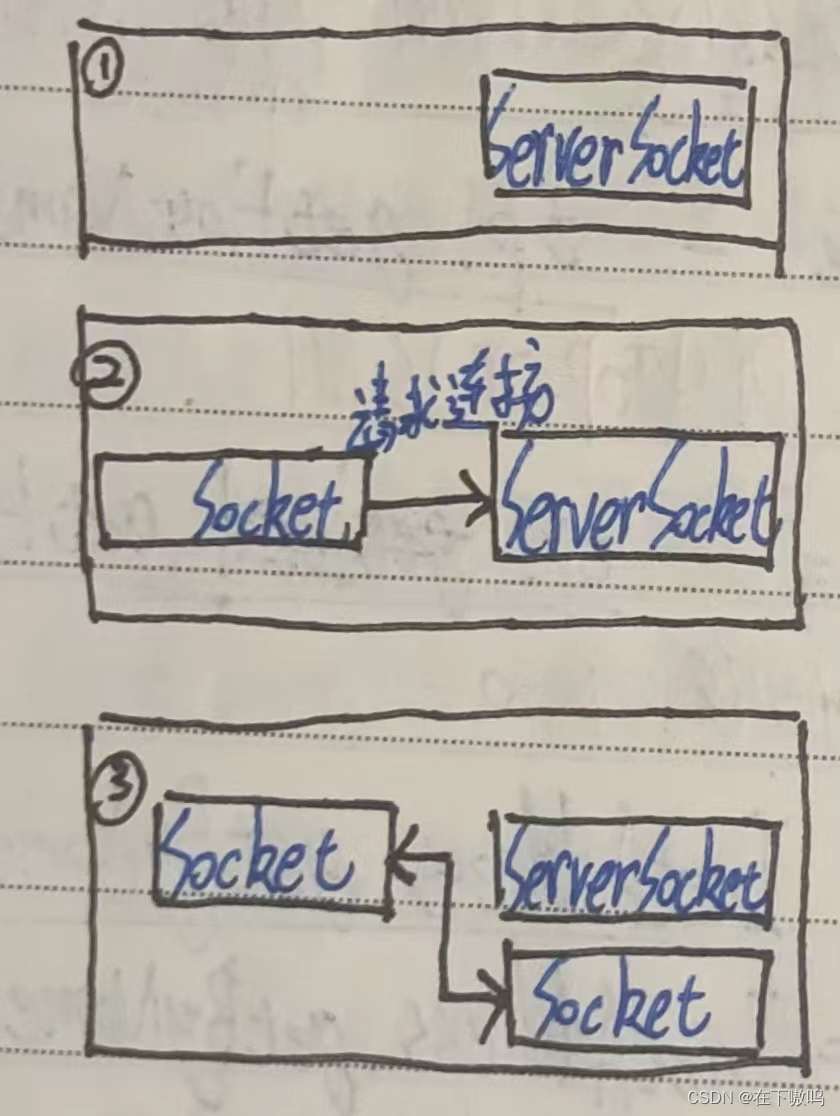
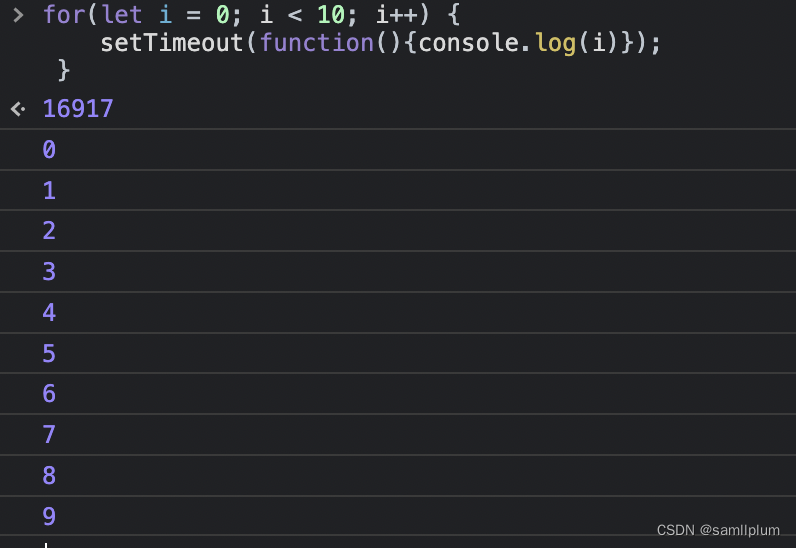
申请内存过程介绍
- 1.主函数执行
- 2.ThreadCache
- 3.CentralCache
- 4.PageCache
1.主函数执行
先从内存池申请内存
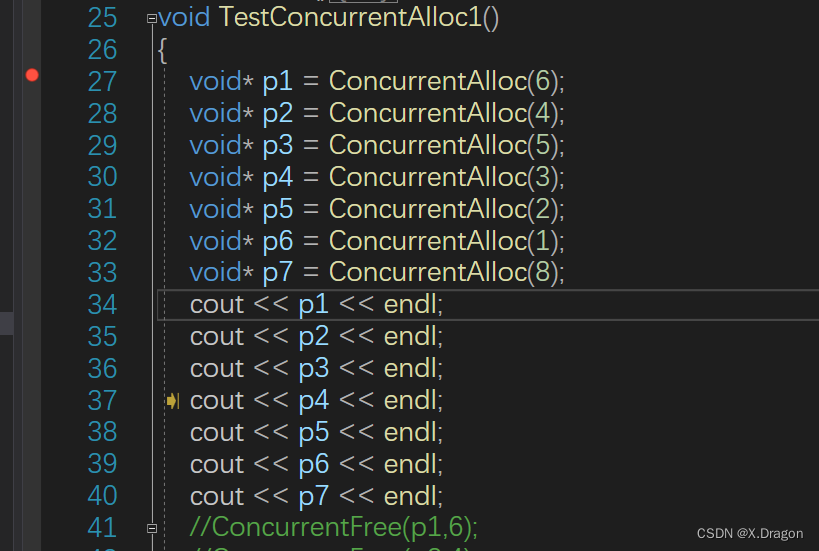
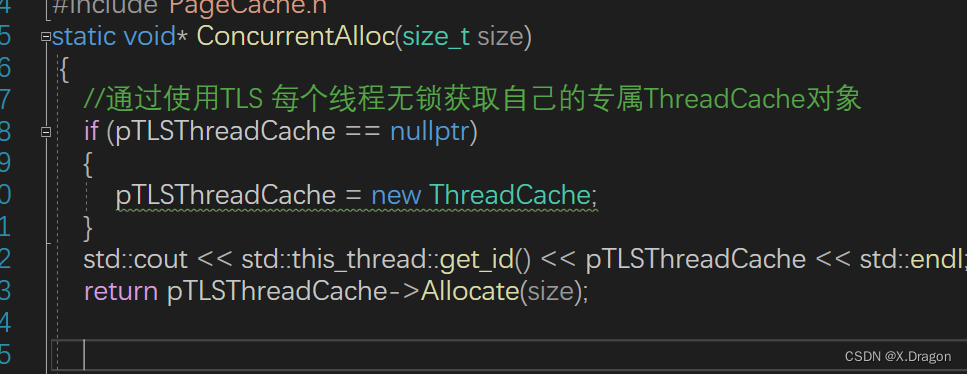
获取ThreadCache对象,然后去ThreadCache对象的Allocate申请!
2.ThreadCache
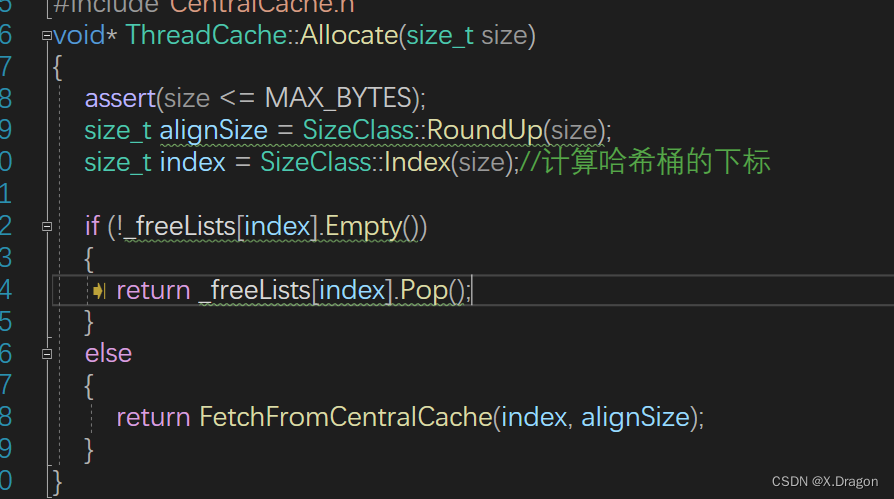
这里要计算对齐函数和相应的桶的下标,这个之前介绍ThreadCache的框架设计的时候有说明,这里不多赘述,计算完对齐数和桶下标之后,如果当前的桶下面有内存对象就直接返回给上级,如果没有,就去中中心调度器CentralCache中申请
- 申请函数 :FetchFromCentralCache(index, alignSize);。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
//慢开始反馈调节算法(batch:批量)
//1.最开始不会一次向central cache要太多,因为要多了可能用不完,浪费
//2.如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限
//3.size越大,一次向central cache要的batchNum就越小
//4.size越小,一次向central cache要的batchNum就越大
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
assert(actualNum >0);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);
return start;
}
}
这里采用满增长双重机制来规范分配规则(之前也有介绍过),计算出在该机制规则下,ThreadCache想向CentralCache中取多大的内存,batchNum,然后去CentralCache申请,但是CentralCache不一定会给你这么多的内存(有可能对应的桶下面没能满足 但是最少有一个单位的内存 不然CentralCache就会继续向上一级申请内存了) 基于这种策略,所以有一个实际分配回来的内存actualNum,如果返回的内存单位只有一个,就直接返回给上级调用对象,如果有多余的内存就插入对应的空闲列表中等待下次对象申请直接 分配
//头插一段范围的节点
void PushRange(void* start, void* end, size_t n)
{
assert(start && end);
NextObj(end) = _freeList;
_freeList = start;
_size += n;
}
3.CentralCache
size_t CentralCache::FetchRangeObj(void*& star, void*& end, size_t batchNum, size_t size)
{
size_t index = SizeClass::Index(size);//计算出桶的下标
_spanlists[index]._mtx.lock();//加锁
Span* span = GetOneSpance(_spanlists[index], size);
assert(span);
assert(span->_freeList);//断言成功 则证明至少有一个块
//从span中获取batchNum个对象
//如果实际的个数不够 那就有多少拿多少 这里就需要有一个实际变量actuall作为返回
star = span->_freeList;
end = star;
size_t i = 0;
size_t actualNum = 1;
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
//更新end的位置
end = NextObj(end);
++actualNum;
++i;
}
span->_freeList = NextObj(end);
NextObj(end) = nullptr;
_spanlists[index]._mtx.unlock();
return actualNum;
}
Span* GetOneSpance(SpanList& list, size_t size)
{
//查看一下当前spanlists是否span未分配的
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freeList!=nullptr)
{
return it;
}
else
{
it = it->_next;
}
}
//先把centralCache的桶解掉 ,这样如果其他的线程释放对象回来,不会阻塞
list._mtx.unlock();
//走到这里说明没有空闲的span了,再往下找PageCache要
PageCache::GetInstance()->_pageMtx.lock(); //加锁 这是一个大锁
Span* span = PageCache::Newspan(SizeClass::NumMovePage(size));
PageCache::GetInstance()->_pageMtx.unlock();//到这一步程序就已经申请到一个span了
//对span进行切分 此过程不需要加锁 因为其他的线程访问不到这个span
//(这时的span没切分好也没挂到相应位置)
//通过页号 计算出起始页的地址 add=_pageID<<PAGE_SHIFT
//计算span的大块内存的起始地址 和大块内存的大小(字节数)
char* start = (char*)(span->_page_id << PAGE_SHIFT);
size_t bytes = span->_n *8*1024;
char* end = start + bytes;
//把大块内存切成自由链表 链接起来
//这里使用尾插 因为尾插会保持内存空间的连续性 提高CPU的缓存利用率
span->_freeList = start;
start += size;
void* tail = span->_freeList;
int i = 1;
while (start < end)
{
++i;
NextObj(tail) = start;
tail = NextObj(tail);
start += size;
}
/*
if (tail == nullptr)
{
int x = 0;
}
NextObj(tail) = nullptr;
void* cur = span->_freeList;
int koko=0;
//条件断点
//类似死循环 可以让程序中断 程序会在运行的地方停下来
while (cur)
{
cur = NextObj(cur);
koko++;
}
if (koko != (bytes / 16))
{
int x = 0;
}*/
//这里切好span以后 需要把span挂到桶里面 同时加锁
list._mtx.lock();
list.PushFront(span);
//list._mtx.unlock();
return span;
}
-
FetchRangeObj函数用于从 CentralCache 中获取一定数量的对象,并且返回这些对象的实际数量。它的参数包括star(起始对象指针)、end(结束对象指针)、batchNum(要获取的对象数量),以及size(对象大小)。 -
首先,根据对象大小
size计算出对象应该存储在哪个 CentralCache 桶中,这通过SizeClass::Index函数实现。 -
然后,获取对应桶的互斥锁,因为这里涉及到多线程并发访问。
-
通过
GetOneSpance函数从当前桶中获取一个Span对象。如果找到一个非空的Span,则继续下一步;否则,会释放当前桶的互斥锁,并尝试从PageCache获取一个新的Span。 -
获取到的
Span可能包含多个对象,所以接下来需要从Span中获取batchNum个对象。这里维护了star和end两个指针来跟踪获取的对象的范围。一个while循环逐个获取对象并将star和end指针移动到下一个对象。 -
最后,释放当前桶的互斥锁,返回实际获取的对象数量。
-
GetOneSpance函数用于从当前桶中获取一个非空的Span对象。如果当前桶中没有非空的Span,它会释放当前桶的互斥锁,然后尝试从PageCache获取一个新的Span。 -
如果找到一个非空的
Span,接下来就需要将Span中的大块内存切分为小对象并链接成自由链表。这部分代码主要用来处理大块内存到小对象的切分,确保内存连续性,并将小对象挂到自由链表中。 -
最后,将切好的
Span加入当前桶的链表,并返回该Span。
总之,这段代码的目的是从 CentralCache 中获取一定数量的对象,如果当前桶没有足够的对象,则会先从 PageCache 获取一个 Span,然后将该 Span 切分成小对象,并挂到自由链表中。最后,返回获取的对象数量。这是内存分配的关键逻辑,确保了对象的高效分配
4.PageCache
//获取一个K页的span
Span* PageCache::Newspan(size_t k)
{
assert(k > 0);
//大于128页的就直接向堆中申请
if (k > NPAGES - 1)
{
//
void* ptr = SystemAlloc(k);
Span* span = pageCache->_spanPool.New();
span->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_n = k;
pageCache->_idSpanMap.set(span->_page_id, span);
return span;
}
//先检查第K个桶里面有没有span
if (! pageCache->_spanList[k].Empty())
{
/*Span* kSpan = pageCache->_spanList[k].PopFront();
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
pageCache->_idSpanMap.set(kSpan->_page_id + i, kSpan);
}
return kSpan;*/
return pageCache->_spanList->PopFront();
}
//第K个桶是空的 检查一下后面的桶里面有没有span
for (size_t i = k + 1; i < NPAGES; ++i)
{
if (!pageCache->_spanList[i].Empty())
{
Span* nspan = pageCache->_spanList[i].PopFront();
Span* kspan = new Span;
//Span* kspan= pageCache->_spanPool.New();
//在nspan头部切一个k页下来
//k页的span返给centralcache剩下的挂在对应的映射位置上
kspan->_page_id = nspan->_page_id;
kspan->_n = k;
nspan->_page_id += k;
nspan->_n -= k;
pageCache->_spanList[nspan->_n].PushFront(nspan);
/*
//存储nSpan的首位页号跟nspan映射
//存储nSapn的首位页号跟nspan映射
//方便page cache回收内存时,进行合并查找
//_idSpanMap[nSpan->_pageId] = nSpan;
pageCache->_idSpanMap.set(nspan->_page_id, nspan);
//_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
pageCache->_idSpanMap.set(nspan->_page_id + nspan->_n - 1, nspan);
//建立id和span的映射,方便central cache回收小块内存时,查找对应的span
for (PAGE_ID i = 0; i < kspan->_n; ++i)
{
//_idSpanMap[kSpan->_pageId + i] = kSpan;
pageCache->_idSpanMap.set(kspan->_page_id + i, kspan);
}*/
return kspan;
}
}
//走到这个位置,后面没有大页的span
//这时候就去找堆要一个128的span
Span* bigSpan = new Span;
//Span* bigSpan = pageCache->_spanPool.New();
void* ptr = SystemAlloc(NPAGES - 1);
bigSpan->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
pageCache->_spanList[bigSpan->_n].PushFront(bigSpan);
return Newspan(k);
}
Span* PageCache::MapObjectToSpan(void* obj)
{
PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);
//std::unique_lock<std::mutex> lock(_pageMtx);//出了作用域自动释放锁
//auto ret = _idSpanMap.find(id);
//if (ret != _idSpanMap.end())
//{
// return ret->second;
//}
//else
//{
// assert(false);
// return nullptr;
//}
auto ret = (Span*)pageCache->_idSpanMap.get(id);
assert(ret != nullptr);
return ret;
}
一样的道理,仔细分析代码不难推断其逻辑,核心功能就是:当CentralCache向它申请内存时,它要是有空闲的内存就分配给CentralCache,要是没有,就想系统申请,然后会多申请一些,挂到相应的桶(挂桶规则之前介绍框架设计的时候介绍过)方便下一次分配。
点赞支持一下,持续更新~