一、UDF函数定义
(1)函数定义
(2)Spark支持定义函数
(3)定义UDF函数
(4)定义返回Array类型的UDF
(5)定义返回字典类型的UDF
二、窗口函数
(1)开窗函数简述
(2)窗口函数的语法
一、UDF函数定义
(1)函数定义
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
Hive中自定义函数有三种类型:
第一种:UDF(User-Defined_-function)函数
· 一对一的关系,输入一个值经过函数以后输出一个值;
· 在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF(User-Defined Aggregation Function)聚合函数
· 多对一的关系,输入多个值输出一个值,通常于groupBy联合使用;
第三种:UDTF(User-Defined Table-Generating Functions)函数
· 一对多的关系,输入一个值输出多个值(一行变多为行);
· 用户自定义生成函数,有点像flatMap;
(2)Spark支持定义函数
目前来说Spark框架各个版本及各种语言对自定义函数的支持:在SparkSQL中,目前仅仅支持UDF函数和UDAF函数,目前Python仅支持UDF。
| Apache Spark Version | Spark SQL UDF(Python,Java,Scala) | Spark SQL UDAF(Java,Scala) | Spark SQL UDF(R) | Hive UDF,UDAF,UDTF |
| 1.1-1.4 | √ | √ | ||
| 1.5 | √ | experimental | √ | |
| 1.6 | √ | √ | √ | |
| 2.0 | √ | √ | √ | √ |
(3)定义UDF函数
①sparksession.udf.register()
注册的UDF可以用于DSL和SQL,返回值用于DSL风格,传参内给的名字用于SQL风格。

②pyspark.sql.functions.udf
仅能用于DSL风格。

其中F是:from pyspark.sql import functions as F。其中,被注册为UDF的方法名是指具体的计算方法,如:def add(x, y): x + y 。 add就是将要被注册成UDF的方法名
# cording:utf8
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType
if __name__ == '__main__':
spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7]).map(lambda x:[x])
df = rdd.toDF(['num'])
# TODO 1:方式1 sparksession.udf.register(),DSL和SQL风格均可使用
# UDF的处理函数
def num_ride_10(num):
return num * 10
# 参数1:注册的UDF的名称,这个UDF名称,仅可以用于SQL风格
# 参数2:UDF的处理逻辑,是一个单独定义的方法
# 参数3:声明UDF的返回值类型,注意:UDF注册时候,必要声明返回值类型,并且UDF的真实返回值一定要和声明的返回值一致
# 当前这种方式定义的UDF,可以通过参数1的名称用于SQL风格,通过返回值对象用户的DSL风格
udf2 = spark.udf.register('udf1', num_ride_10, IntegerType())
# SQL风格中使用
# selectExpr 以SELECT的表达式执行,表达式SQL风格的表达式(字符串)
# select方法,接受普通的字符串字段名,或者返回值时Column对象的计算
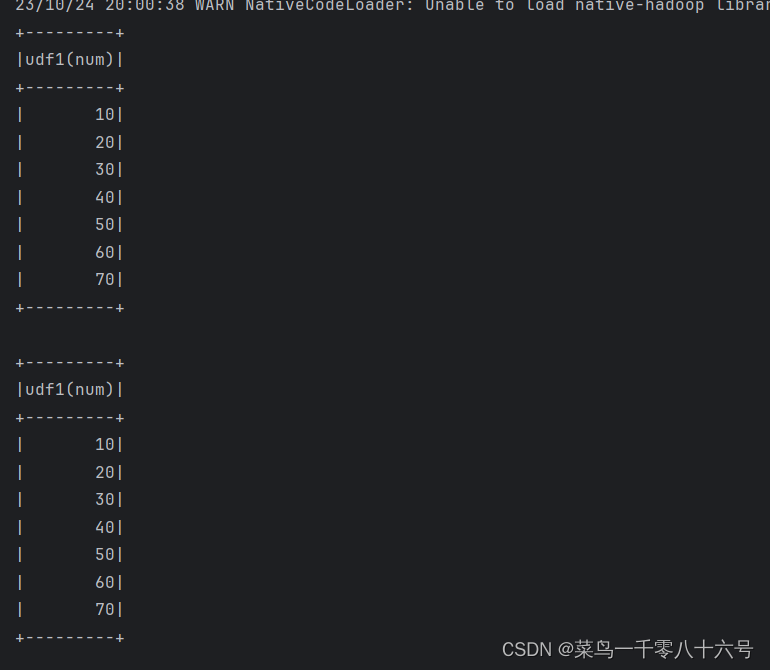
df.selectExpr('udf1(num)').show()
# DSL 风格使用
# 返回值UDF对象,如果作为方法使用,传入的参数一定是Column对象
df.select(udf2(df['num'])).show()
# TODO 2:方式2注册,仅能用于DSL风格
udf3 = F.udf(num_ride_10, IntegerType())
df.select(udf3(df['num'])).show()方式1结果:
方式2结果:
(4)定义返回Array类型的UDF
注意:数组或者list类型,可以使用spark的ArrayType来描述即可。
注意:声明ArrayType要类似这样::ArrayType(StringType()),在ArrayType中传入数组内的数据类型。
# cording:utf8
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':
spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 构建一个RDD
rdd = sc.parallelize([['hadoop spark flink'], ['hadoop flink java']])
df = rdd.toDF(['line'])
# 注册UDF,UDF的执行函数定义
def split_line(data):
return data.split(' ')
# TODO 1:方式1 后见UDF
udf2 = spark.udf.register('udf1', split_line, ArrayType(StringType()))
# DLS 风格
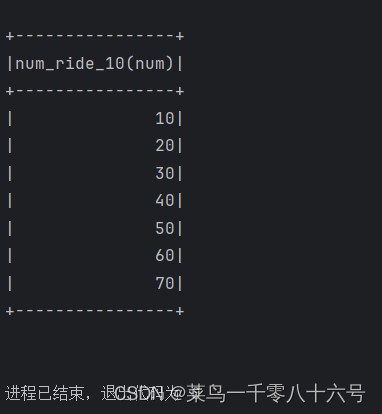
df.select(udf2(df['line'])).show()
# SQL风格
df.createTempView('lines')
spark.sql('SELECT udf1(line) FROM lines').show(truncate=False)
# TODO 2:方式的形式构建UDF
udf3 = F.udf(split_line, ArrayType(StringType()))
df.select(udf3(df['line'])).show(truncate=False)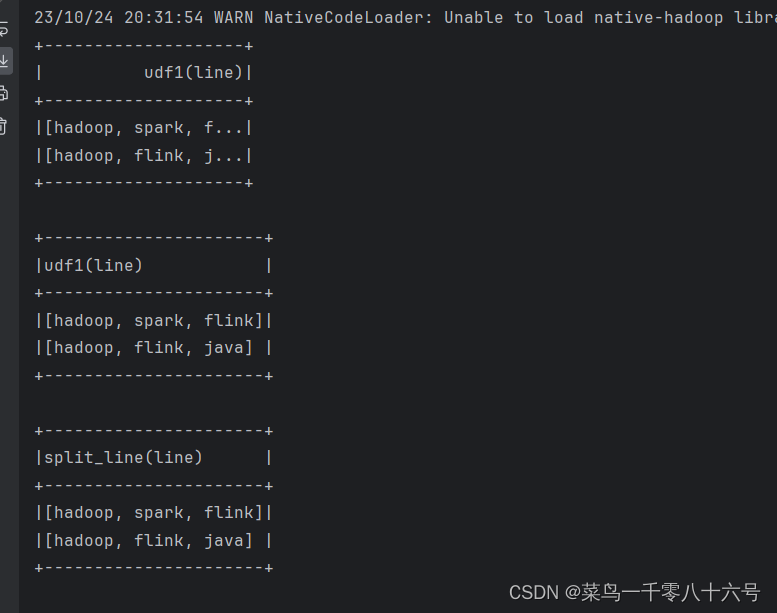
(5)定义返回字典类型的UDF
注意:字典类型返回值,可以用StructType来进行描述,StructType是—个普通的Spark支持的结构化类型.
只是可以用在:
· DF中用于描述Schema
· UDF中用于描述返回值是字典的数据
# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':
spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 假设 有三个数字: 1 2 3 在传入数字,返回数字所在序号对应的 字母 然后和数字结合组成dict返回
# 例:传入1 返回{'num':1, 'letters': 'a'}
rdd = sc.parallelize([[1], [2], [3]])
df = rdd.toDF(['num'])
# 注册UDF
def process(data):
return {'num': data, 'letters': string.ascii_letters[data]}
'''
UDF返回值是字典的话,需要用StructType来接收
'''
udf1 = spark.udf.register('udf1', process, StructType().add('num', IntegerType(), nullable=True).\
add('letters', StringType(), nullable=True))
# SQL风格
df.selectExpr('udf1(num)').show(truncate=False)
# DSL风格
df.select(udf1(df['num'])).show(truncate=False)
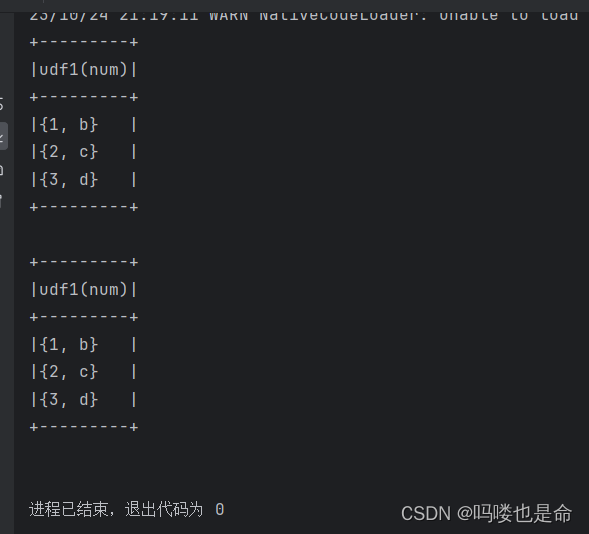
(6)通过RDD构建UDAF函数
# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':
spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([1, 2, 3, 4, 5], 3)
df = rdd.map(lambda x: [x]).toDF(['num'])
# 方法:使用RDD的mapPartitions 算子来完成聚合操作
# 如果用mapPartitions API 完成UDAF聚合,一定要单分区
single_partition_rdd = df.rdd.repartition(1)
def process(iter):
sum = 0
for row in iter:
sum += row['num']
return [sum] # 一定要嵌套list,因为mapPartitions方法要求返回值是list对象
print(single_partition_rdd.mapPartitions(process).collect())
二、窗口函数
(1)开窗函数简述
●介绍
开窗函数的引入是为了既显示聚集前的数据又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。 开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
●聚合函数和开窗函数
聚合函数是将多行变成一行,count,avg...
开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中,开窗函数可以不使用group by,直接将所有信息显示出来。
●开窗函数分类
1.聚合开窗函数 聚合函数(列)OVER(选项),这里的选项可以是PARTITION BY子句,但不可以是ORDER BY子句。
2.排序开窗函数 排序函数(列)OVER(选项),这里的选项可以是ORDER BY子句,也可以是OVER(PARTITION BY子句ORDER BY子句),但不可以是PARTITION BY子句。
3.分区类型NTILE的窗口函数
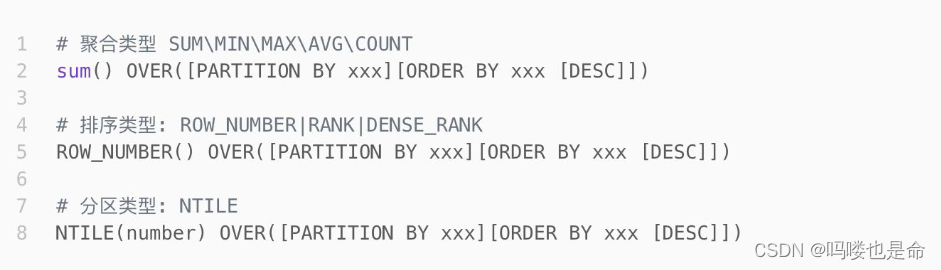
(2)窗口函数的语法
窗口函数的语法:
# cording:utf8
import string
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, StringType, StructType, ArrayType
if __name__ == '__main__':
spark = SparkSession.builder.appName('udf_define').master('local[*]').getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([
('张三', 'class_1', 99),
('王五', 'class_2', 35),
('王三', 'class_3', 57),
('王久', 'class_4', 12),
('王丽', 'class_5', 99),
('王娟', 'class_1', 90),
('王军', 'class_2', 91),
('王俊', 'class_3', 33),
('王君', 'class_4', 55),
('王珺', 'class_5', 66),
('郑颖', 'class_1', 11),
('郑辉', 'class_2', 33),
('张丽', 'class_3', 36),
('张张', 'class_4', 79),
('黄凯', 'class_5', 90),
('黄开', 'class_1', 90),
('黄恺', 'class_2', 90),
('王凯', 'class_3', 11),
('王凯杰', 'class_1', 11),
('王开杰', 'class_2', 3),
('王景亮', 'class_3', 99)])
schema = StructType().add('name', StringType()).\
add('class', StringType()).\
add('score', IntegerType())
df = rdd.toDF(schema)
# 创建表
df.createTempView('stu')
# TODO 1:聚合窗口函数的演示
spark.sql('''
SELECT *, AVG(score) over() AS avg_socre FROM stu
''').show()
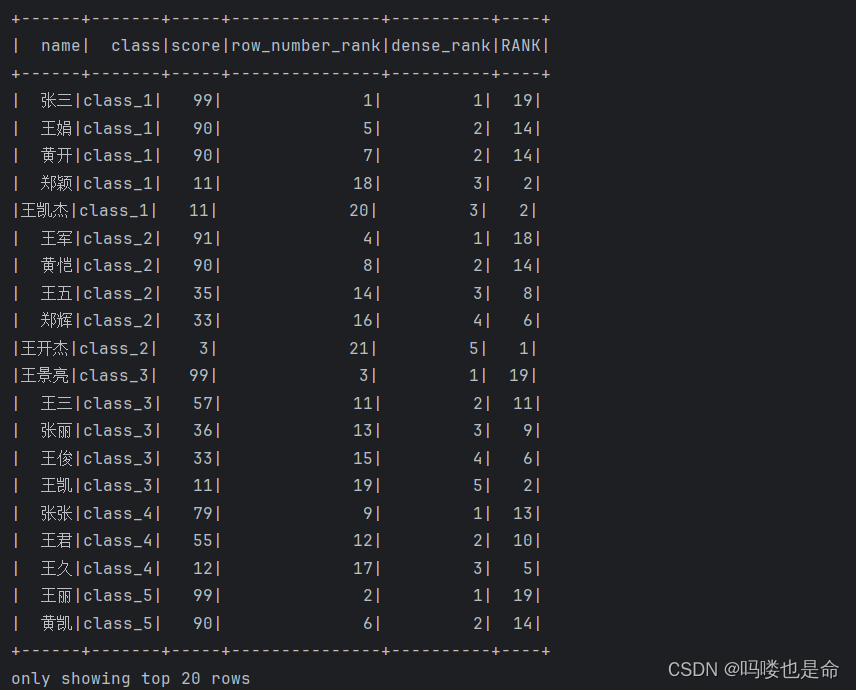
# TODO 2: 排序相关的窗口函数计算
# RANK over, DENSE_RANK over, ROW_NUMBER over
spark.sql('''
SELECT *, ROW_NUMBER() OVER(ORDER BY score DESC) AS row_number_rank,
DENSE_RANK() OVER(PARTITION BY class ORDER BY score DESC) AS dense_rank,
RANK() OVER(ORDER BY score) AS RANK
FROM stu
''').show()
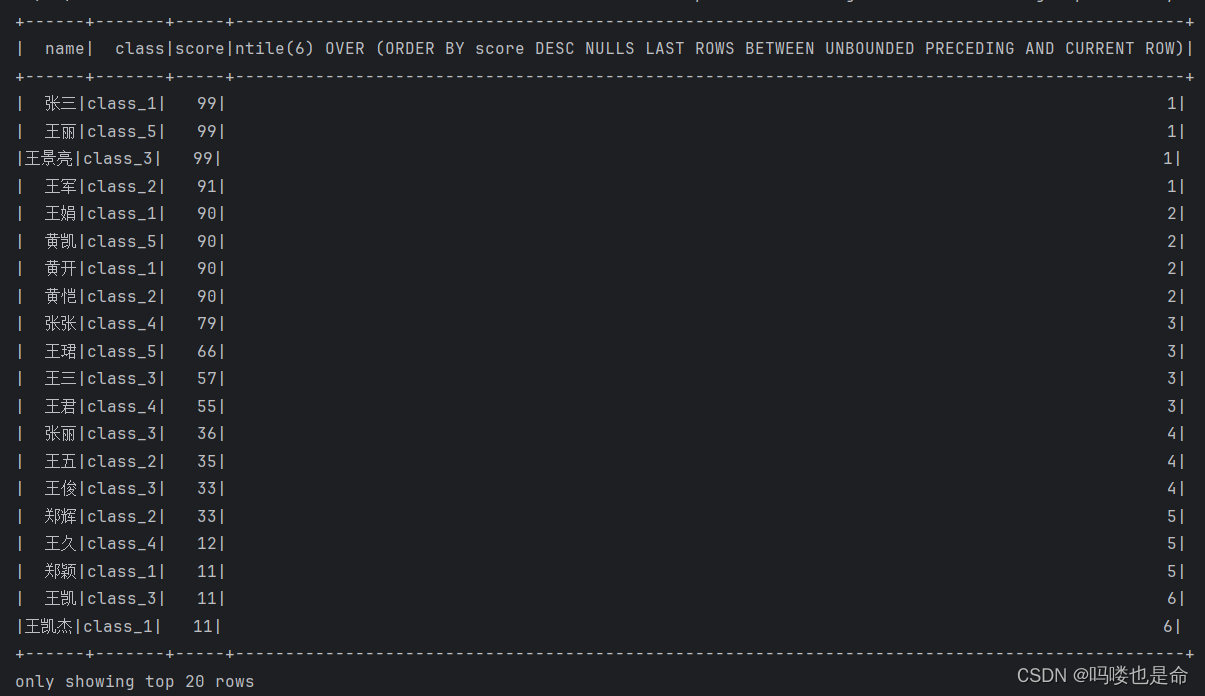
# TODO NTILE
spark.sql('''
SELECT *, NTILE(6) OVER(ORDER BY score DESC) FROM stu
''').show()
TODO1结果:

TODO2结果展示:
TODO3结果展示:











![[量化投资-学习笔记003]Python+TDengine从零开始搭建量化分析平台-Grafana画K线图](https://img-blog.csdnimg.cn/c316ad5384fd497b9afa6b3c06f0fd06.png#pic_center)