侯捷——2.C++标准库 体系结构与内核分析
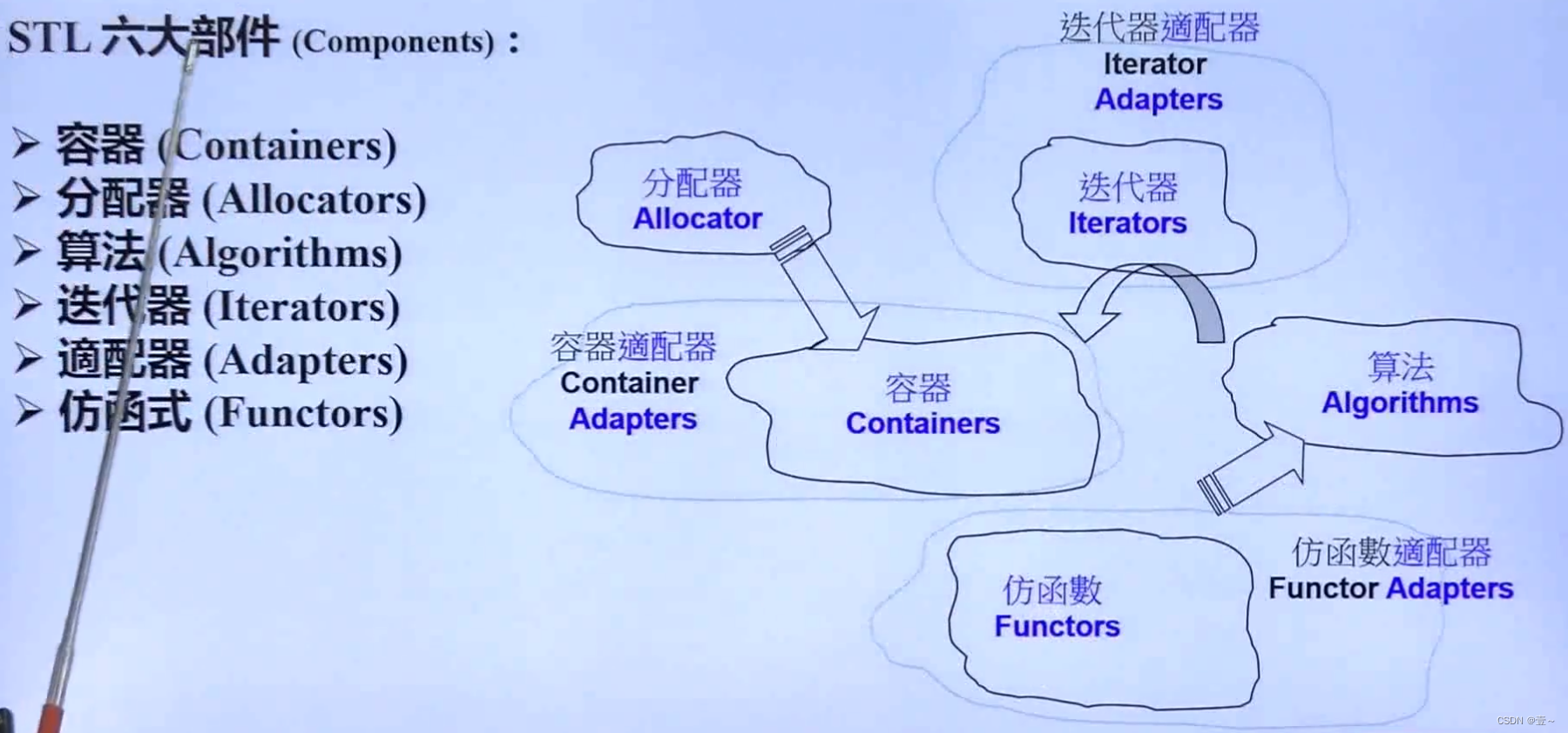
1. C++标准库 vs STL


C++标准库包含STL。标准库都用 std 这个命名空间包装起来。
2. STL体系结构基础介绍
allocators(分配器)是给containers(容器)分配内存的。当要创建容器时,必须先有分配器分配内存。在创建容器时,可以指定分配器,也可以不指定,编译器会默认指定分配器。
2.1 复杂度

2.2 迭代器采用前闭后开区间

begin()指向第一个元素,而end()指向最后一个元素的下一个元素。
2.3 range-based for statement(since C++11)
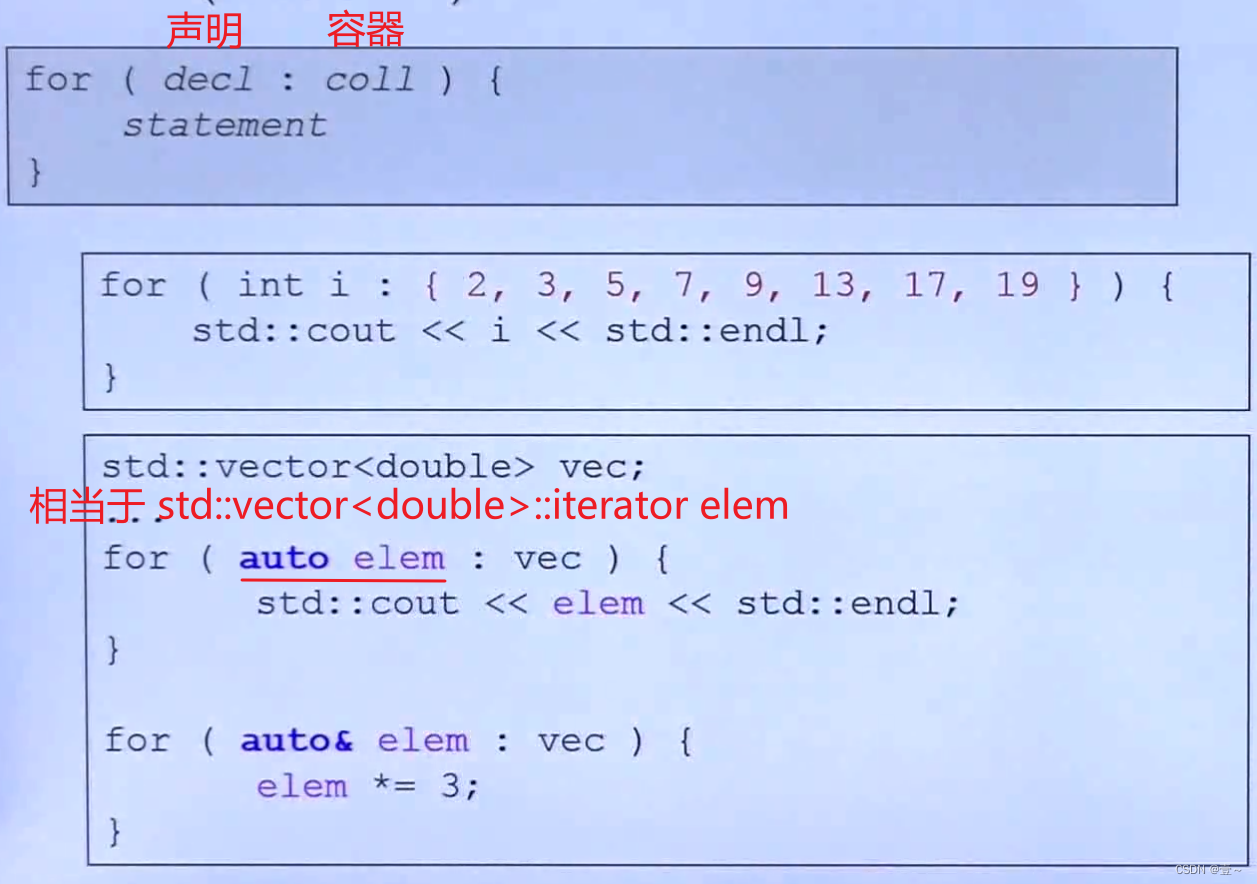
2.4 auto关键字

3. 容器——结构与分类(1)

循序式容器,是根据你放进去的顺序来决定顺序的。
Array、Vector和Deque的底部都是在内存中占用的空间都是连续的。
List和Forward-List都是空间可以不连续的。
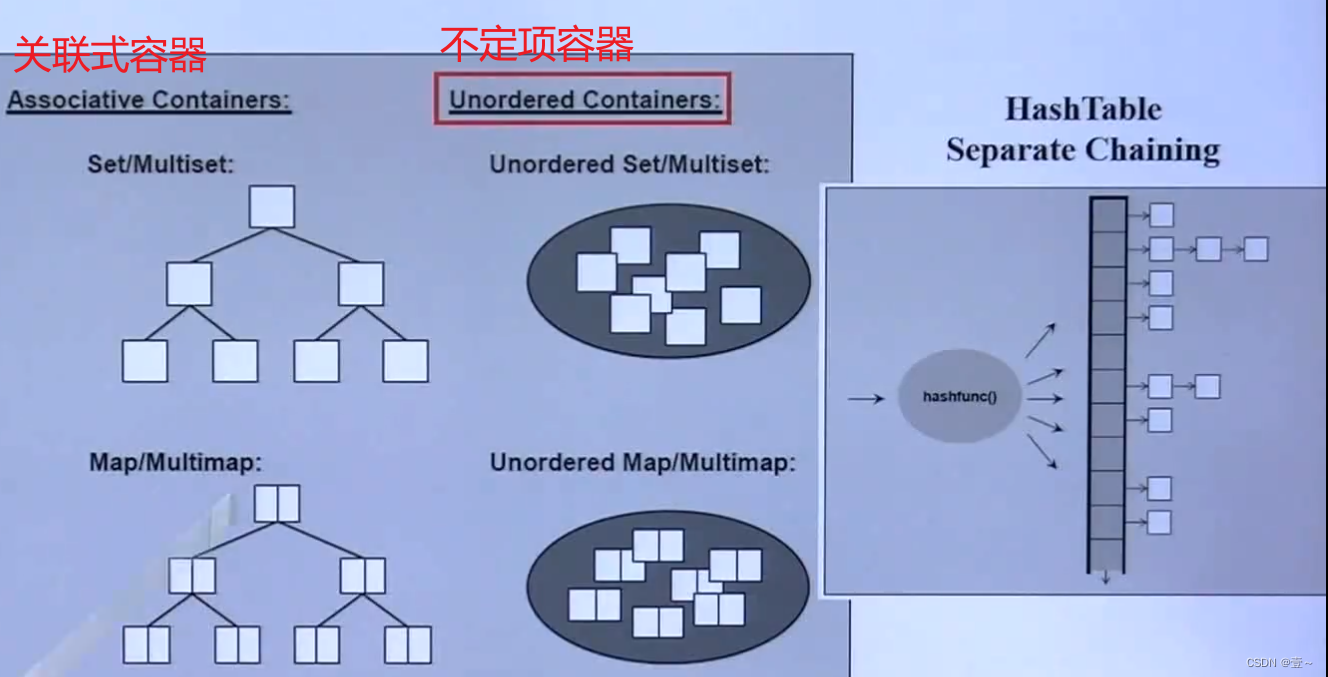
关联式容器,就是Set/MultiSet和Map/Mulimap,底部实现都是红黑树。
关联式容器都是内部有序的,而Set和Map是内部元素不可重复的,MultiSet和MultiMap是内部元素可以重复的。
Unordered Containers(无序容器),内部元素都是无序的,底部实现是哈希表。
3.1 Deque
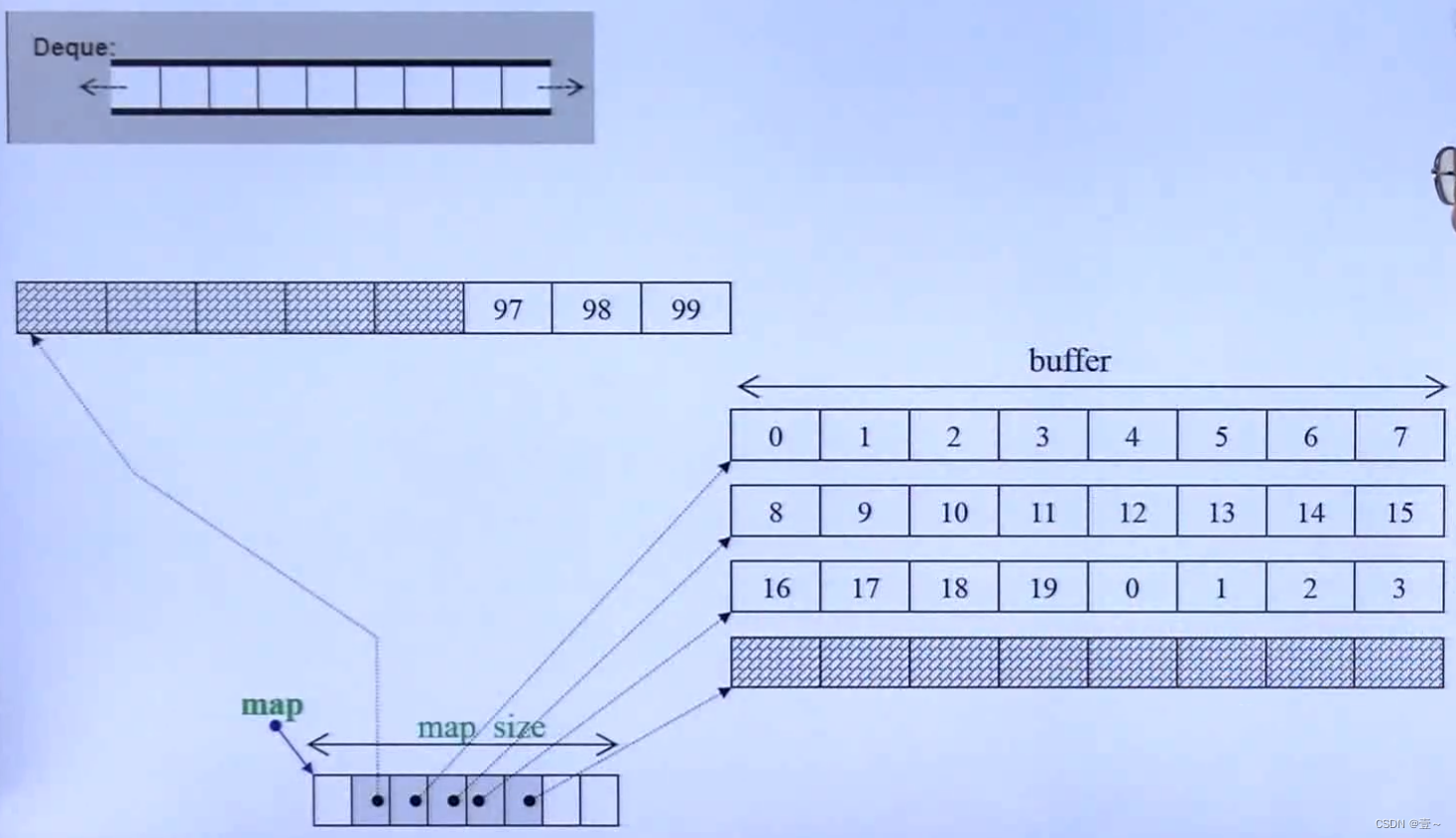
Deque(双向队列),其实它内部是有可能不连续的,但为了让它看起来是连续的,则每当读到一个buffer最后一个元素时,要自动跳到邻近buffer的第一个元素。
stack(栈)和queue(队列)底部都是deque实现的,只是限制了deque的进出元素的方式。


stack和queue是没有iterator的,因为stack是先进后出,queue是先进先出,如果有iterator的话,就有可能会通过iterator修改它们中间的值,从而破坏规则。
3.2 无序容器(unordered)
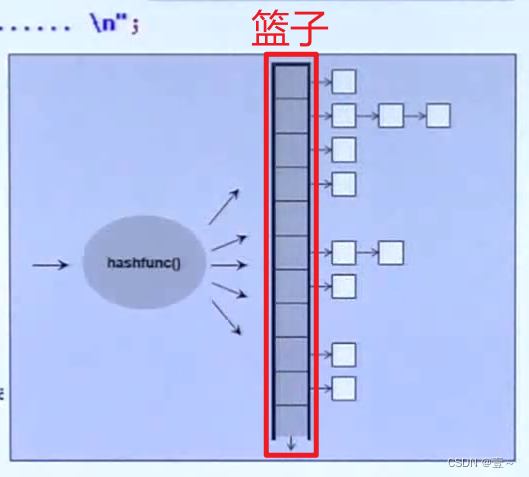
无序容器包括unordered_set、unordered_multiset、unordered_map和unordered_multimap。它们底部实现是哈希表,如上图,哈希表的位置称之为篮子。篮子的个数会随着元素的增加而扩充。
例如当篮子只有10个的话,当元素达到10个,篮子数量就会扩充到20个,然后把原来的元素打散,按照新的表达式计算出各个元素的新位置。
所以一般篮子的个数都会比元素的个数多。
4. 分配器(allocator)
容器的背后需要一个东西来支持它内存的使用,这个东西就是分配器。

容器的模板都有第二参数,就是分配器。但可以不指定,会自动使用默认的分配器。
4.1 用法

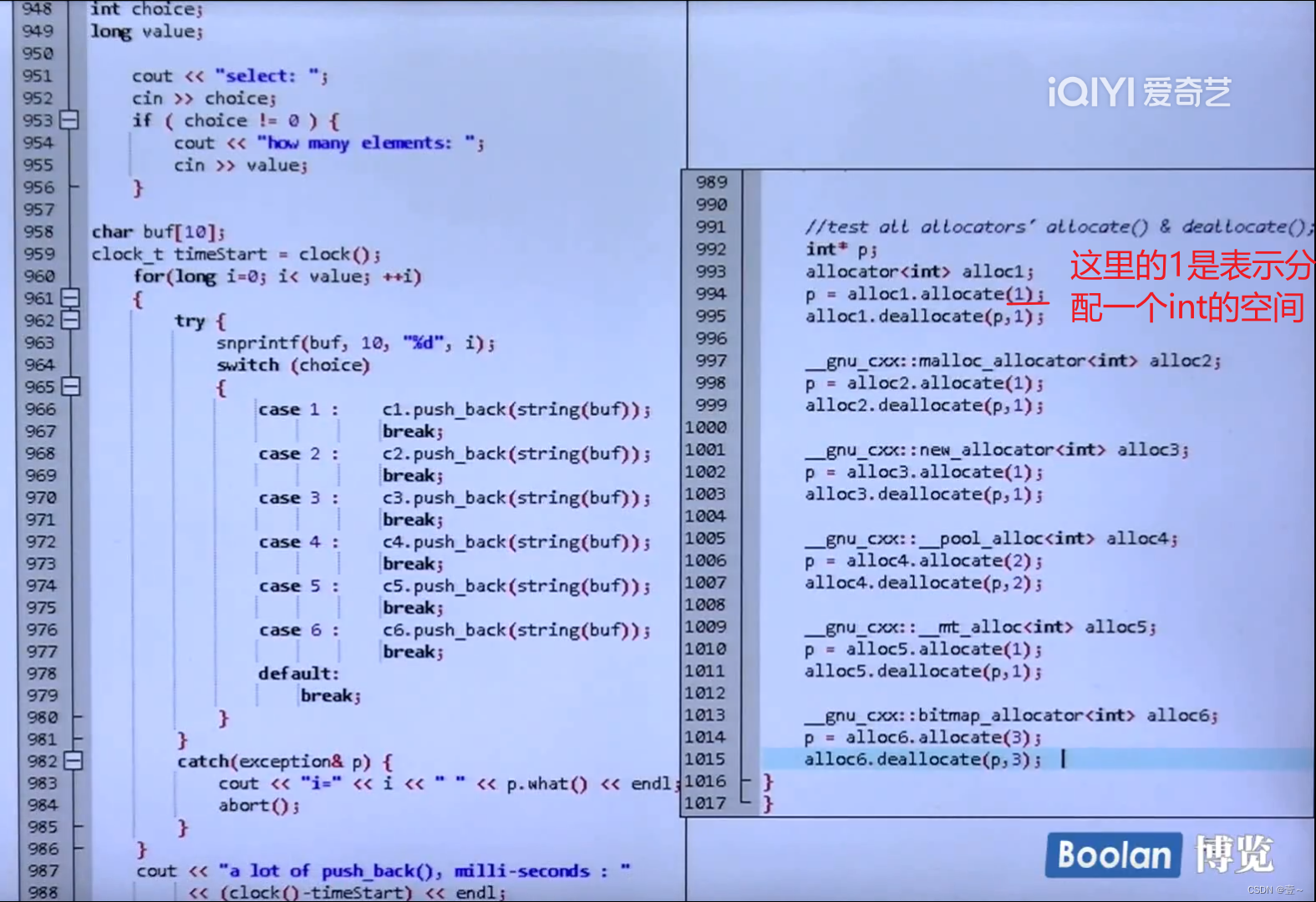
不推荐单独使用分配器。
5. OOP(Object-Oriented programming) vs GP(Generic programming)
5.1 OOP
OOP(面向对象编程)一般是将 datas(数据) 和 methods(方法)合并在一起的。

list无法使用全局的sort()。需要自己实现。

5.2 GP
GP是将数据和方法分开来的。
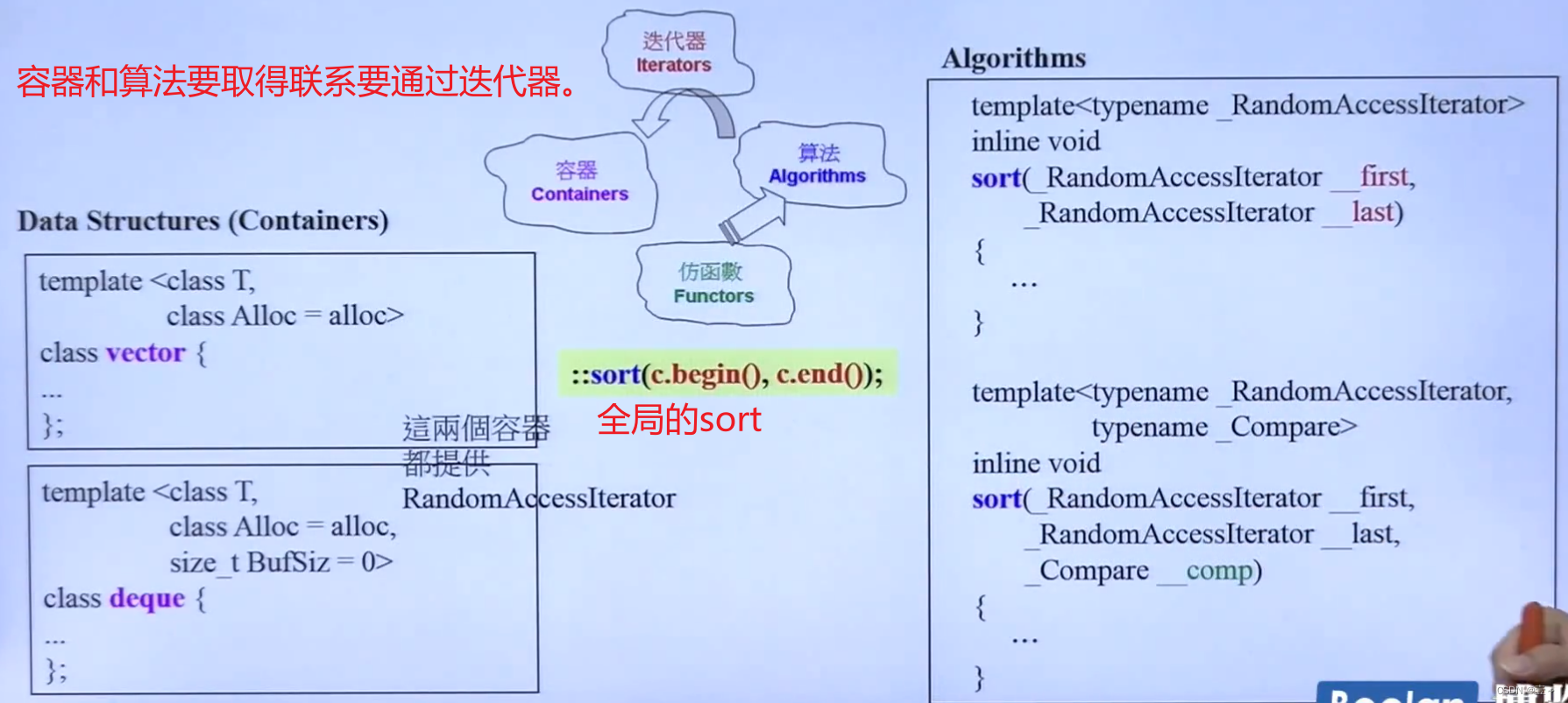
容器和算法要取得联系得通过迭代器。
vector和deque就可以使用全局的sort()。

采用GP的好处:
- 容器和算法可各自工作,互不影响,用迭代器沟通即可。
- 算法通过迭代器确定操作范围,并通过迭代器取得容器中的元素。
如果类中有实现sort(),则使用自己类中的。如果没有,则使用全局的。
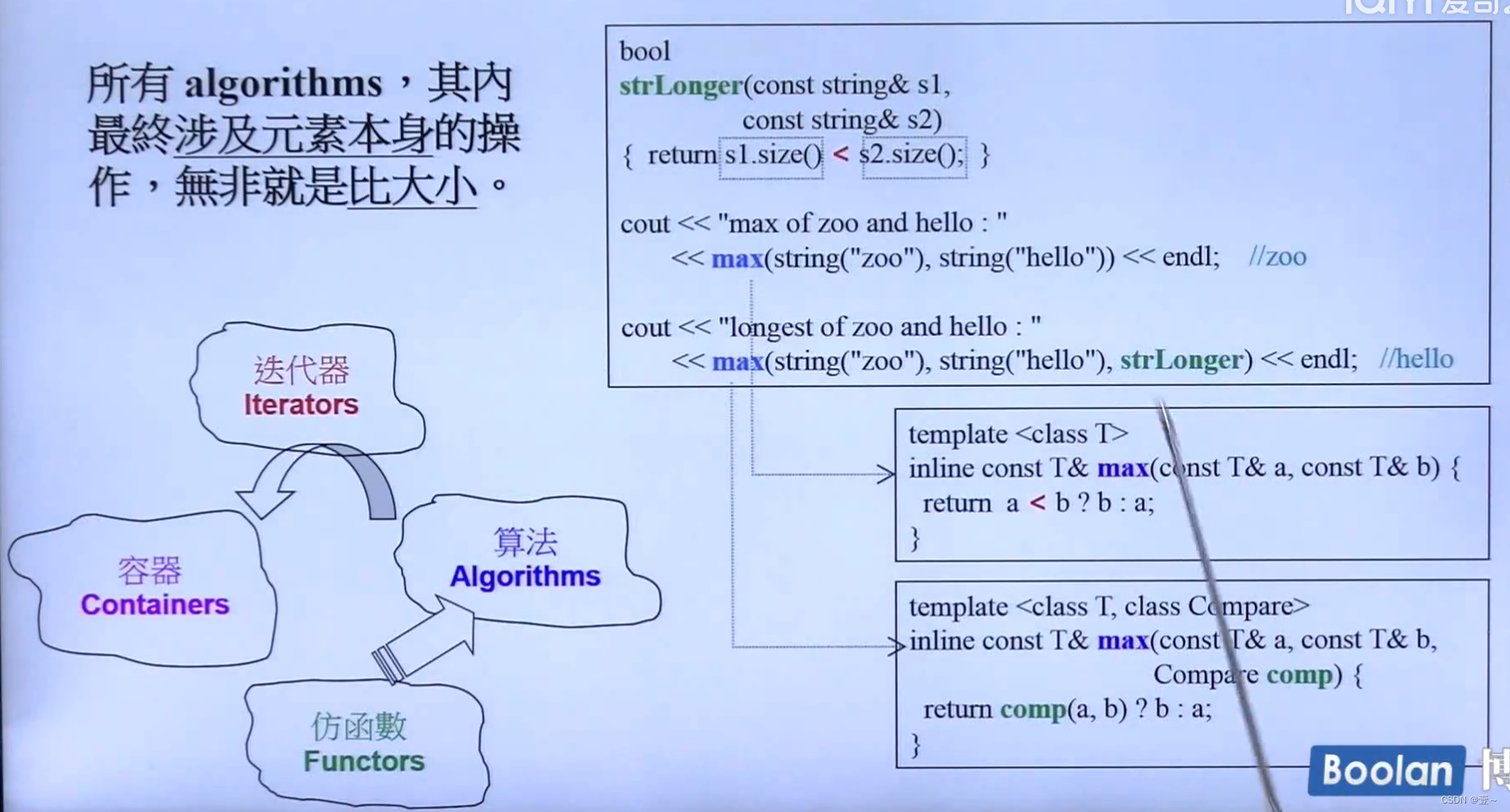
6. 操作符重载和模板(泛化、全特化、偏特化)
6.1 全特化
当某个类型有更好的处理方法时,可以使用特化。就是指定某种类型时,调用对应的方法。要注意特化的语法表示,如下图所示。
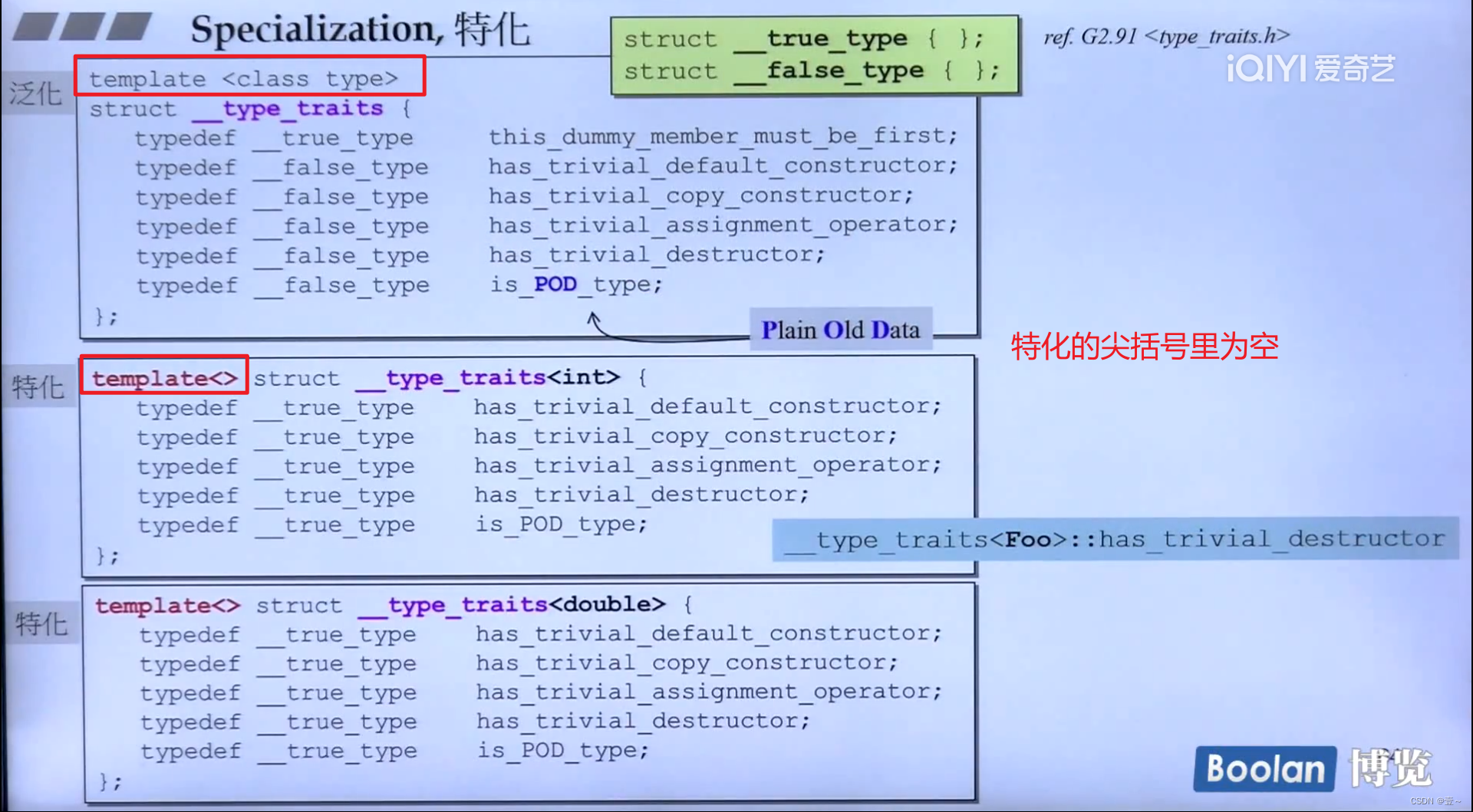
6.2 偏特化

7. 分配器(allocators)
分配器的好坏会影响容器的效率。因为分配器是为容器分配内存的,而容器中元素的进出都会关系到内存的分配。
7.1 先谈operator new()和malloc()
所有的内存分配动作最终都会跑到malloc()下去。

operator new()也不例外。malloc在分配内存时,会多分配出 32+4 字节的灰色部分,会两块红色的cookie部分,还有根据情况而定的绿色填充部分。所以当你想要分配的内存比较小的时候,灰色和红色这些内存是会固定分配的,所以会导致,实际上使用的内存占比比较小,而当你要申请的内存比较大的时候,则实际使用的内存占比就会比较大。
7.1 分配器的源码
以下是VC6低下的allocator的源码:

allocator两个比较重要的函数就是allocate()和deallocate()。allocate()底部会调用operator new(),而operator new()会调用malloc(),所以归根结底就是allocate()会调用malloc()。而deallocate()也同理,底部会调用operator delete(),而operator delete()底部会调用free()。
分配器在申请和释放内存时都需要指定大小,这是很不方便的,释放时很难去记住当初申请的大小。所以一般不推荐直接使用分配器。
VC下的 allocator 没有特殊的设计,背后只是调用 malloc 和 free 来实现内存的分配和释放。
VC下、BC下和GNU下的allocator的实现都差不多。但GNU下实现的allocator不怎么会去使用它,而是使用alloc。
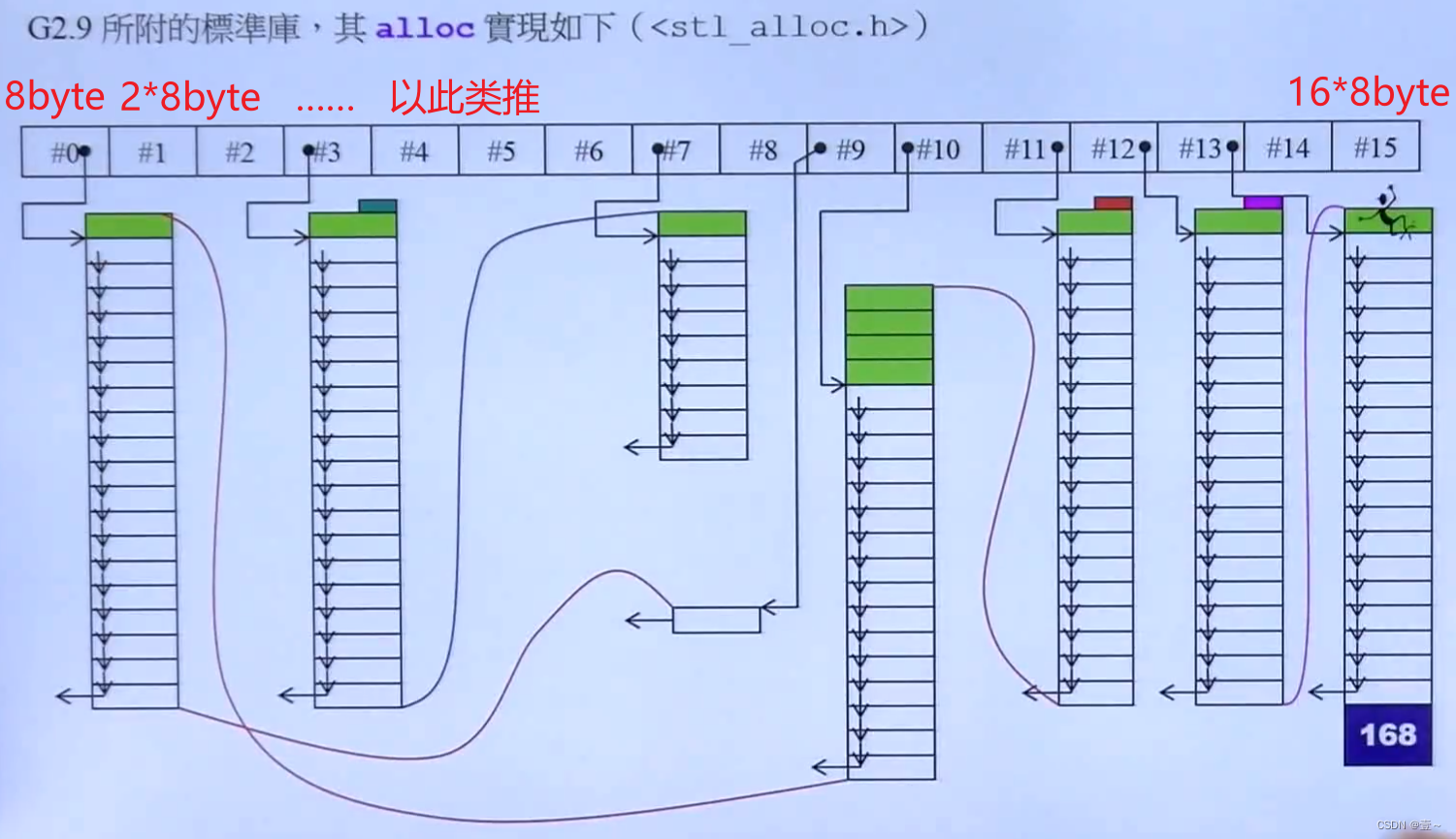
alloc 的主要改变是为了避免每分配一个元素需要在该元素上下消耗的8byte的cookie(记录大小),因为每次malloc都带来额外的内存开销。每个元素根据是 8 的几倍挂到上图对应的区域。当对应倍数下的链表没有内存时,系统还是会使用 malloc 向系统申请一大片内存。当然一使用malloc就会有额外开销。
8. 容器之间的实现关系与分类

本图以缩排形式表达“基层与衍生层”的关系。这里所谓的衍生,并非继承而是复合。
例如set、map、multiset和multimap与rb_tree(红黑树)的关系就是复合关系,也就是set、map、multiset和multimap里有rb_tree,它们底部需要红黑树作为支撑。
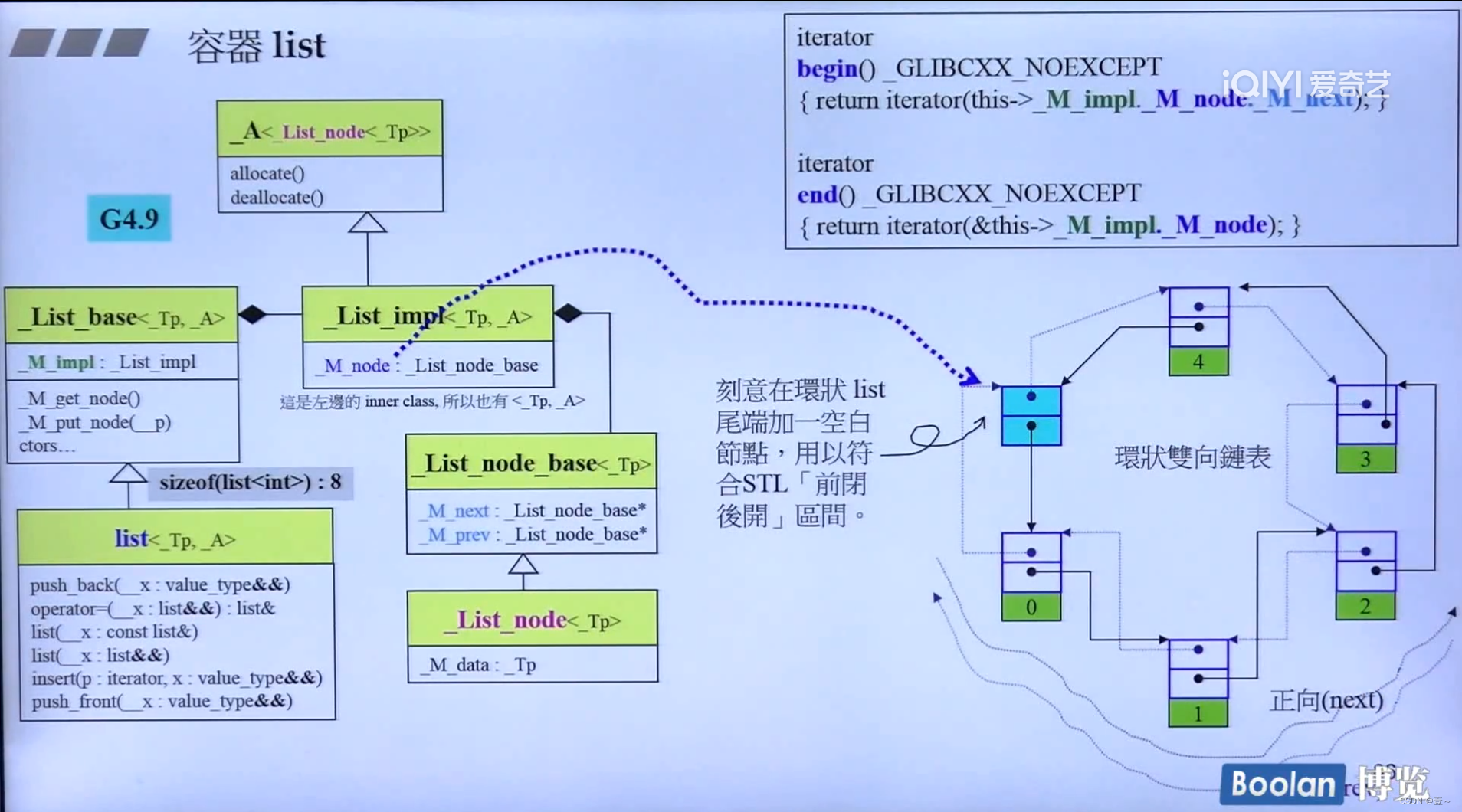
9. 深度探索list
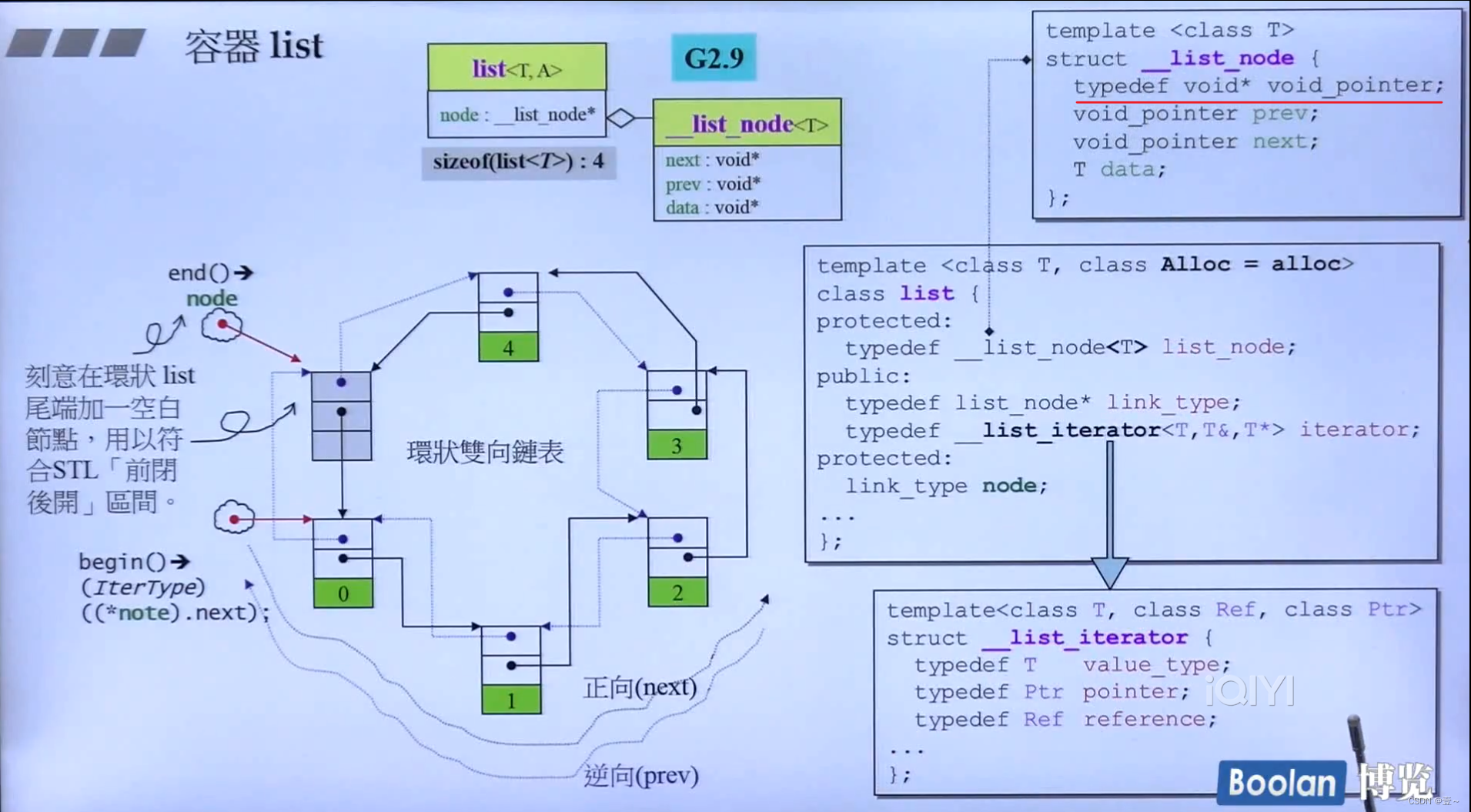
这里的 __list_node 节点设计中有一些小缺陷,该结构体左右节点指向的是 void* ,也就是在使用时还得注意转型。一般来说,节点两端指向的都是自己本身这种类型。
除了array和vector,其它容器的 iterator 都要自己通过写出 iterator 类来实现,才能使 iterator 变聪明,可以通过 ++ 而指向下一个。
9.1 list的iterator

iterator少不了操作符重载,因为要使它像指针。
operator++()是前置的++,相当于是i++;而为了区分前置跟后置,所以后置的加了一个参数,作为区分,这个参数是没有用到的,operator(int)。
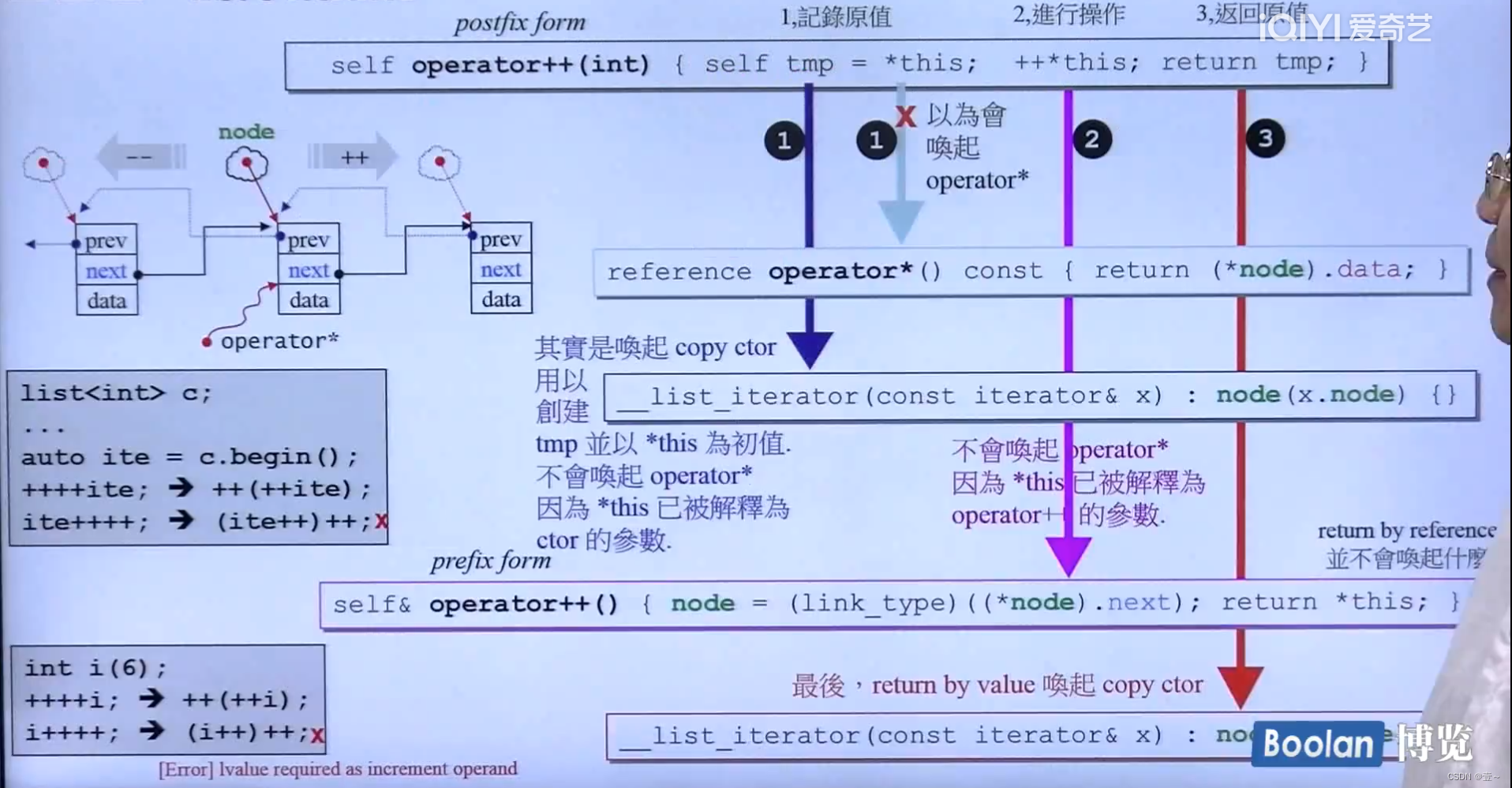
C++不允许连续两次后置++。
为了前置++可以两次,所以它的返回类型是引用。为了使后置++不可以两次,所以它的返回类型不是引用。

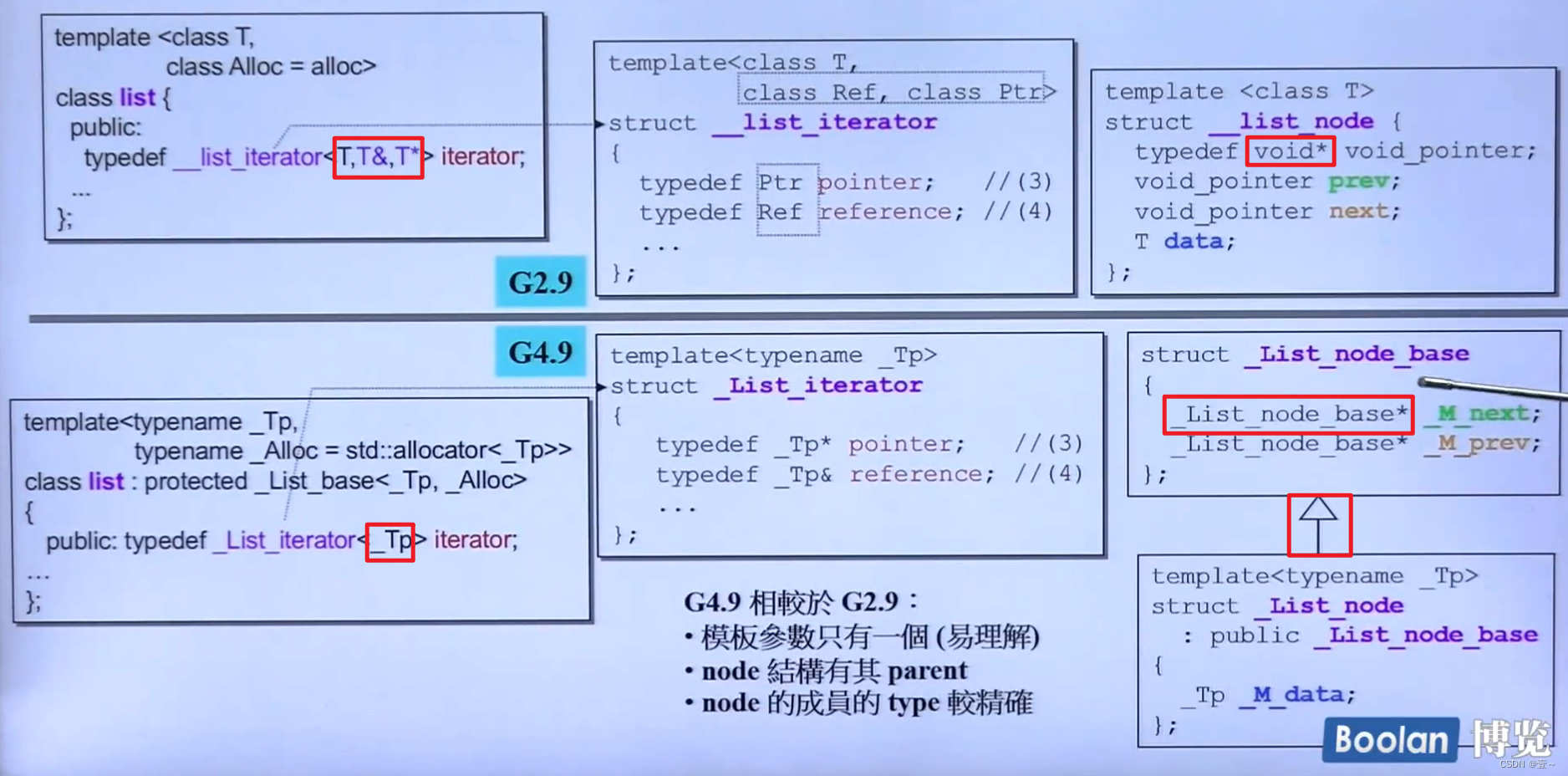
9.2 list不同版本的比较
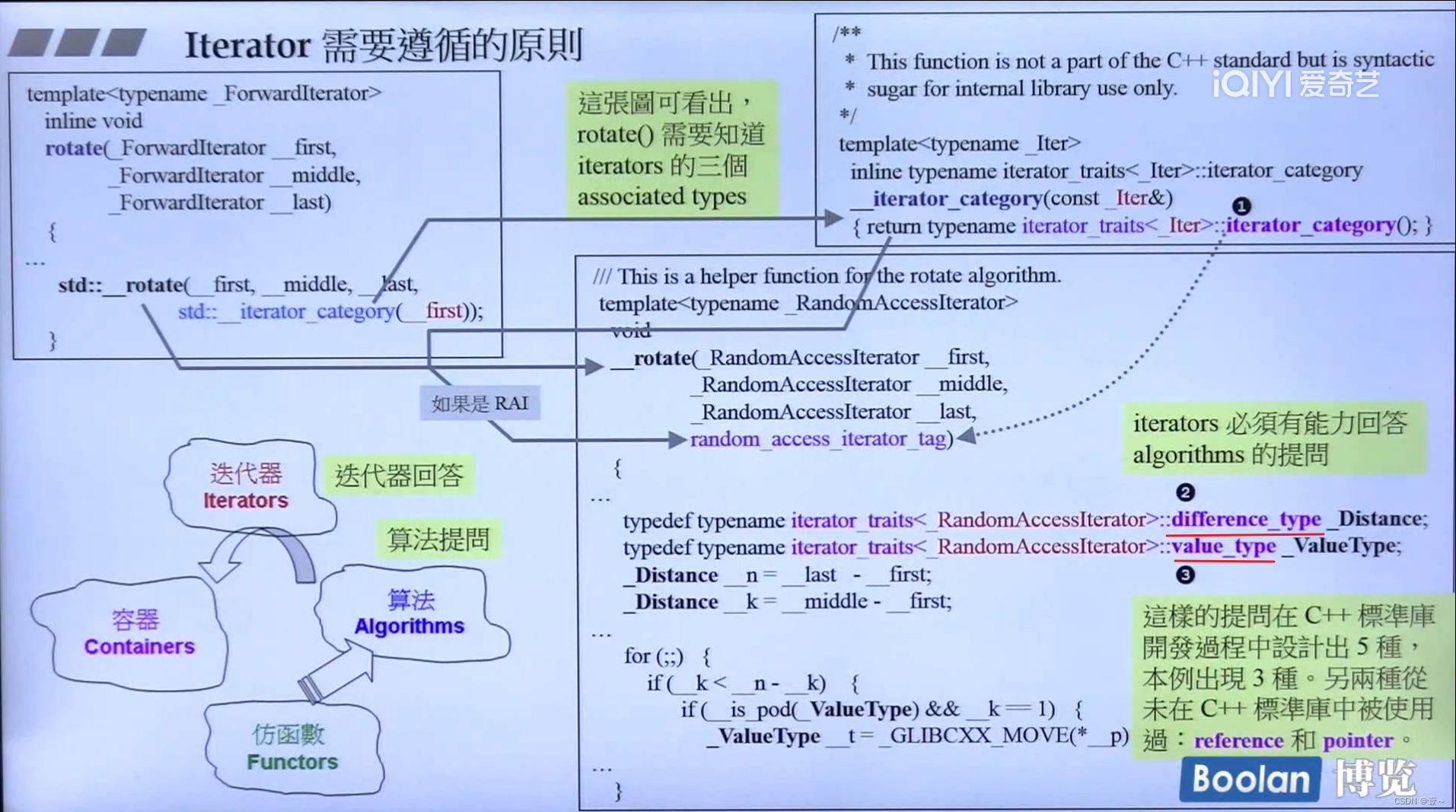
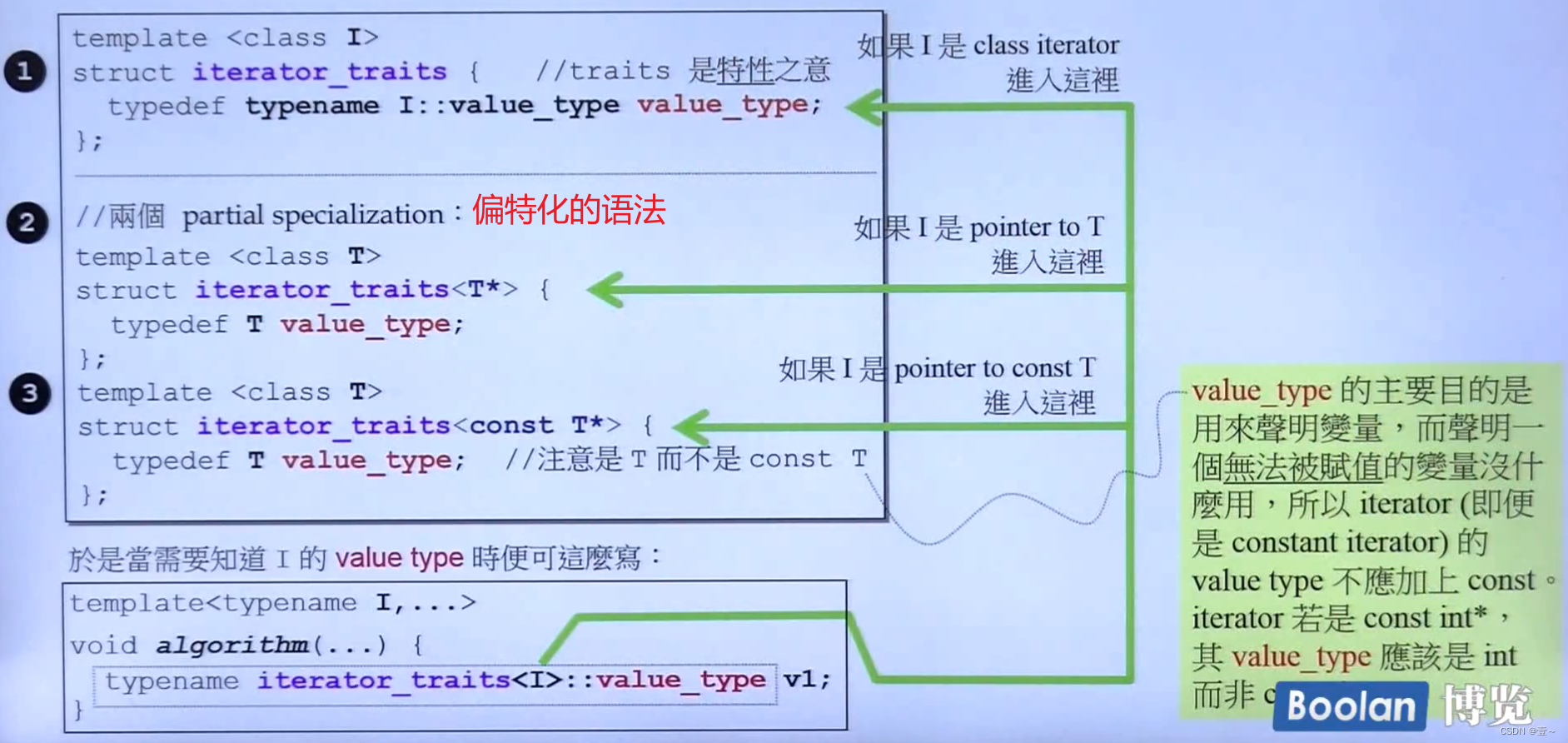
10. 迭代器的设计原则和Iterator Traits的作用与设计
10.1 Iterator 需要遵循的原则
value_type 指的是容器的类型,如果容器的类型是int,则 value_type 为 int。
difference_type指的是两个iterator之间的距离,应该用什么类型来表现,如 unsigned_int。
迭代器需要回答算法的五个问题:
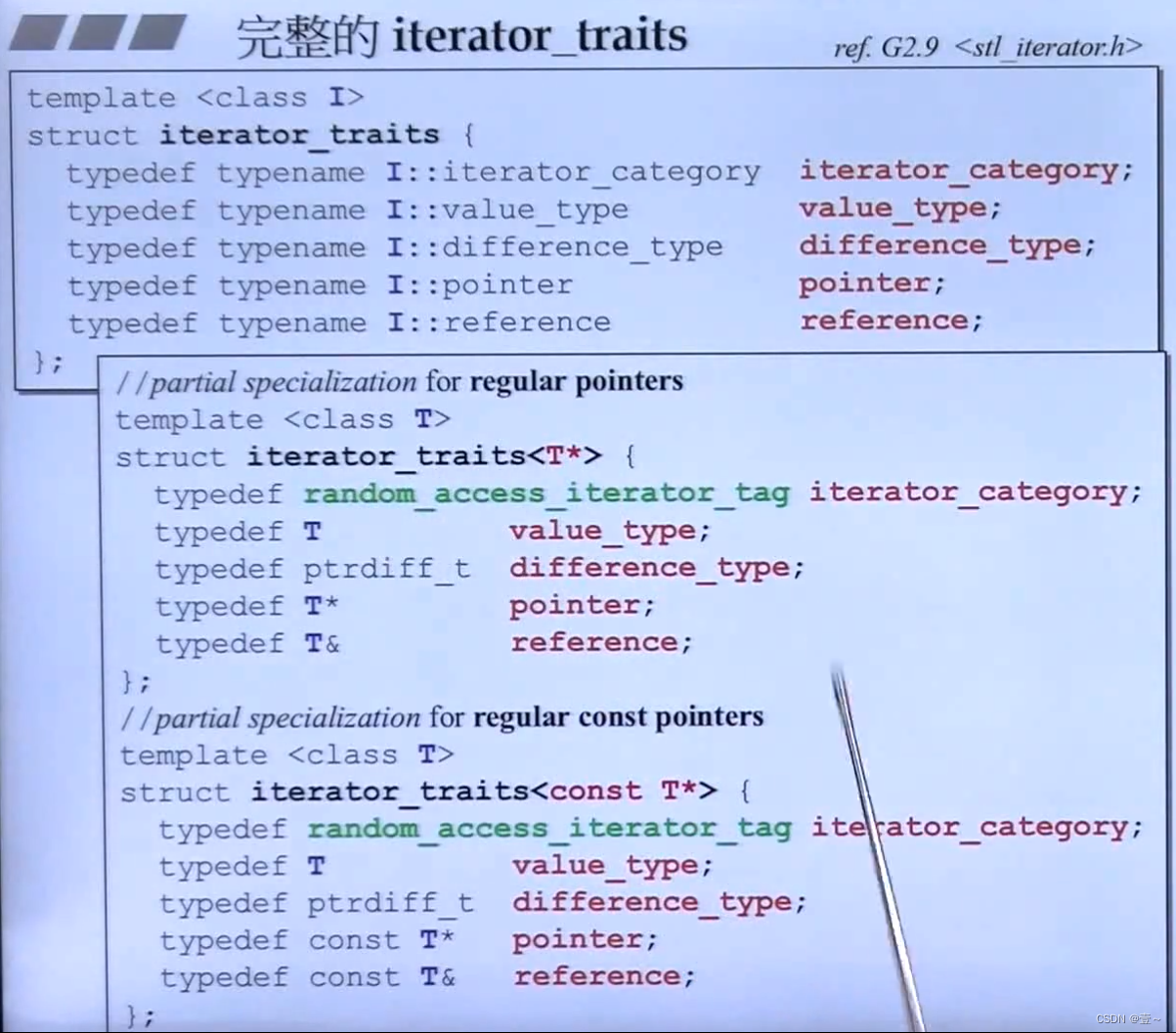
iterator 必须定义的五种类型,iterator_category(),difference_type,value_type,reference和pointer。以此来回答算法提出的问题。虽然reference和pointer从来没有被使用到。
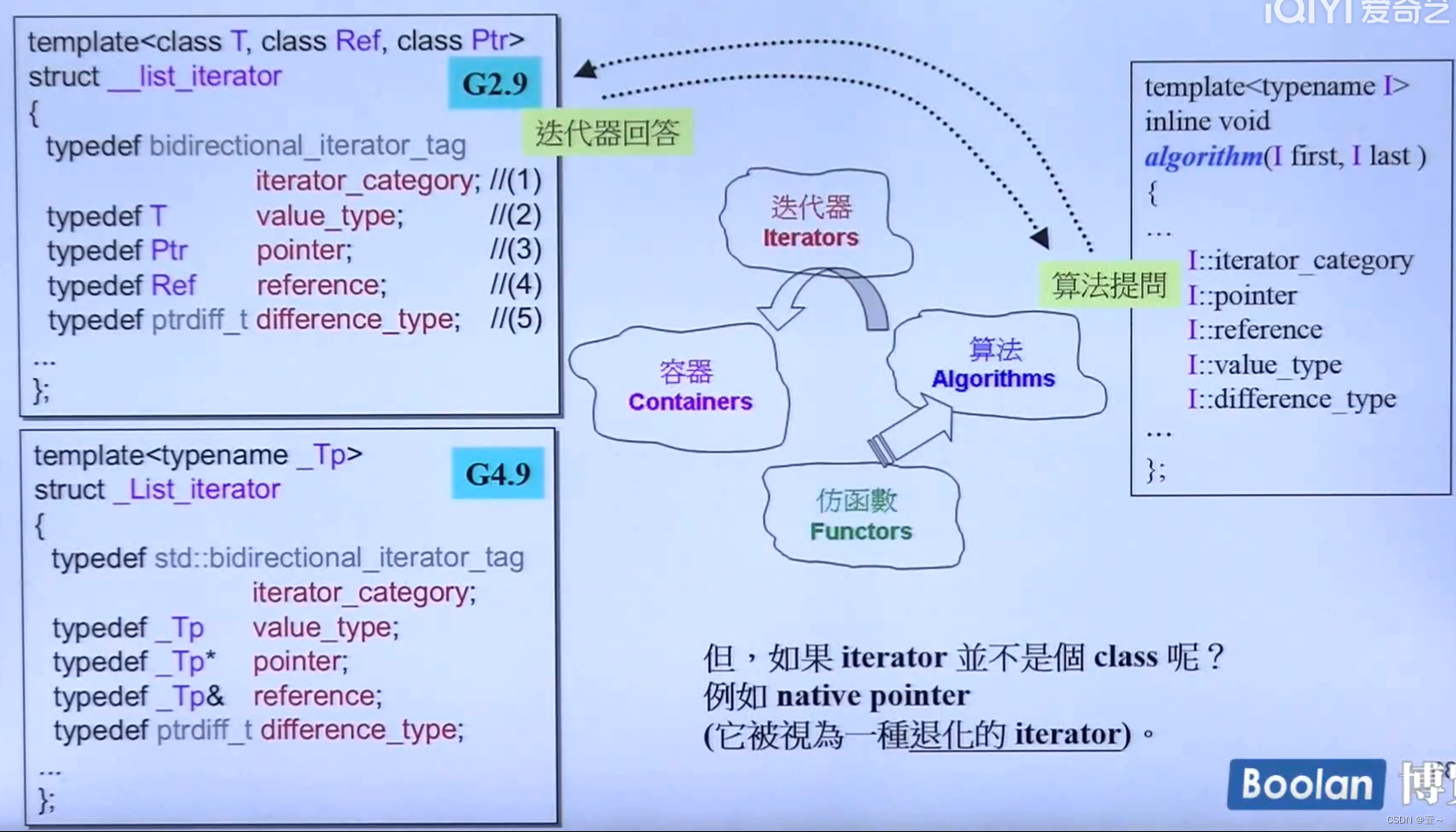
ptrdiff_t是比编译器已经定义好了的,好像是unsigned_long。
当iterator不是一个class时,而是一个自然指针(相当于一种退化的iterator),这个时候算法想要问它问题,就问不出什么,为了解决这个问题,引入了trait。
10.2 Iterator Traits的作用与设计
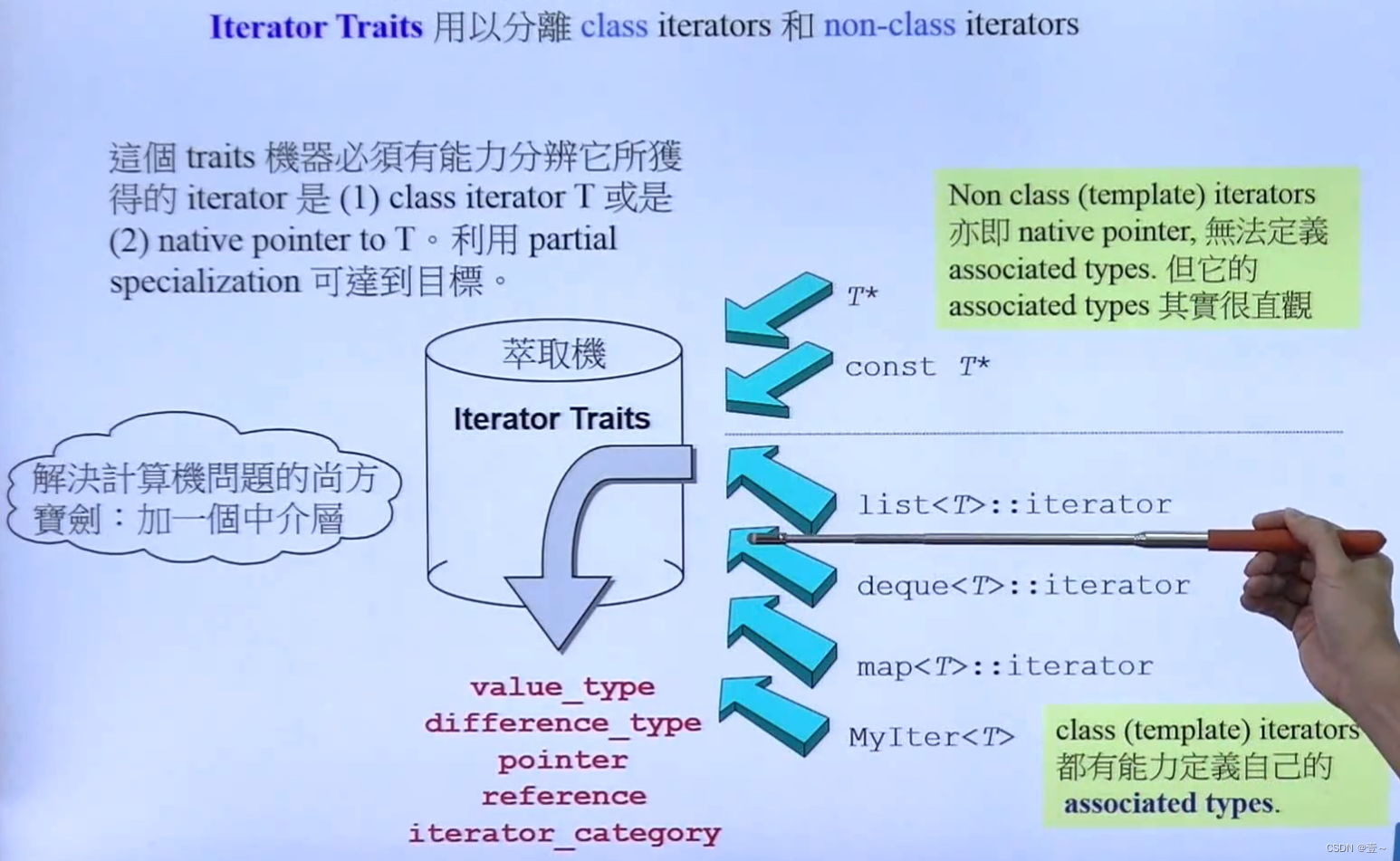
Iterator Traits(萃取机)必须要能区分iterator到底是class类型的,还是不是class类型的。可以把迭代器放进萃取机,问它一些事情,比如问迭代器是哪种类型等。
traits相当于中介。
11. vector深度探索
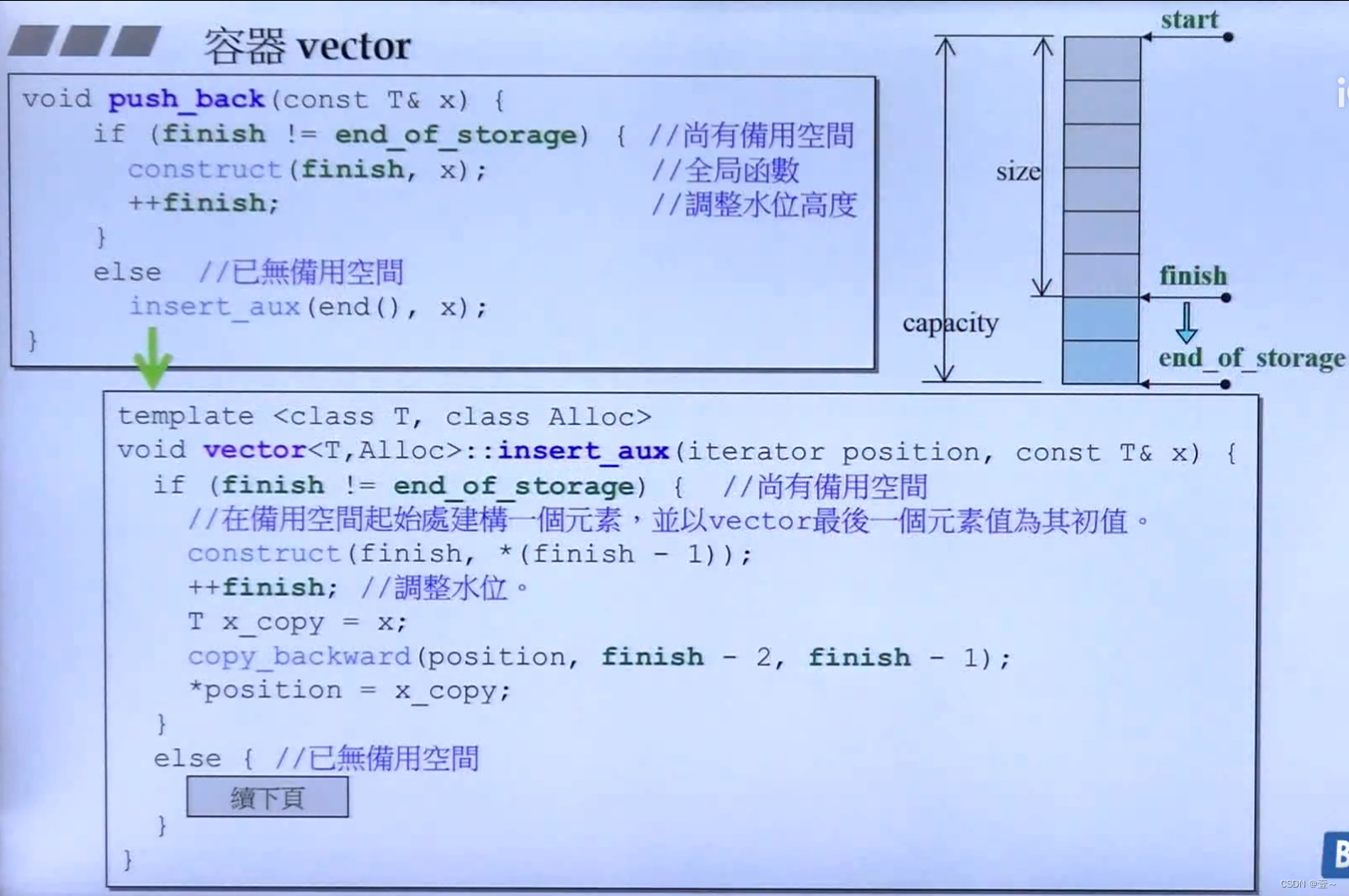
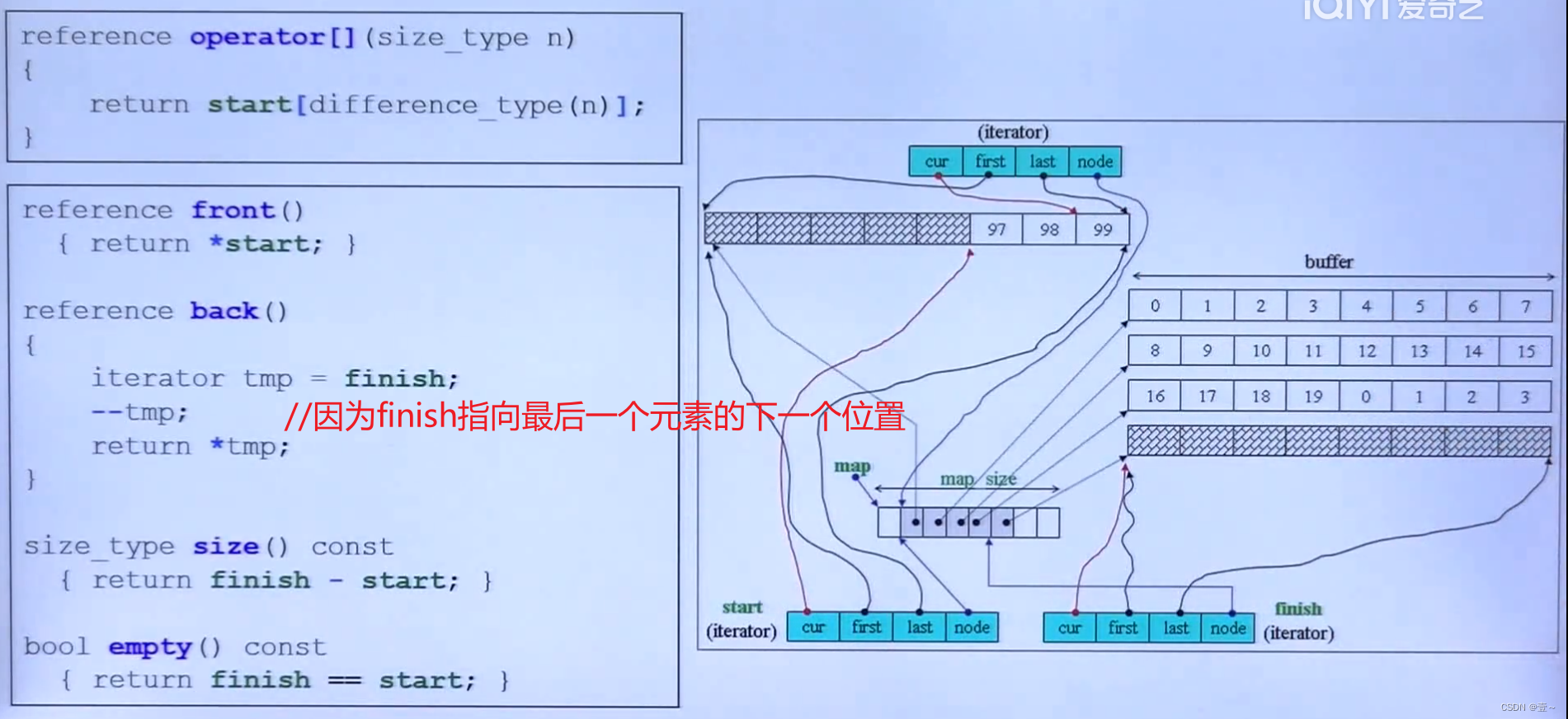
容器是一个前闭后开的区间。finish和end_of_storage都指向下一个。
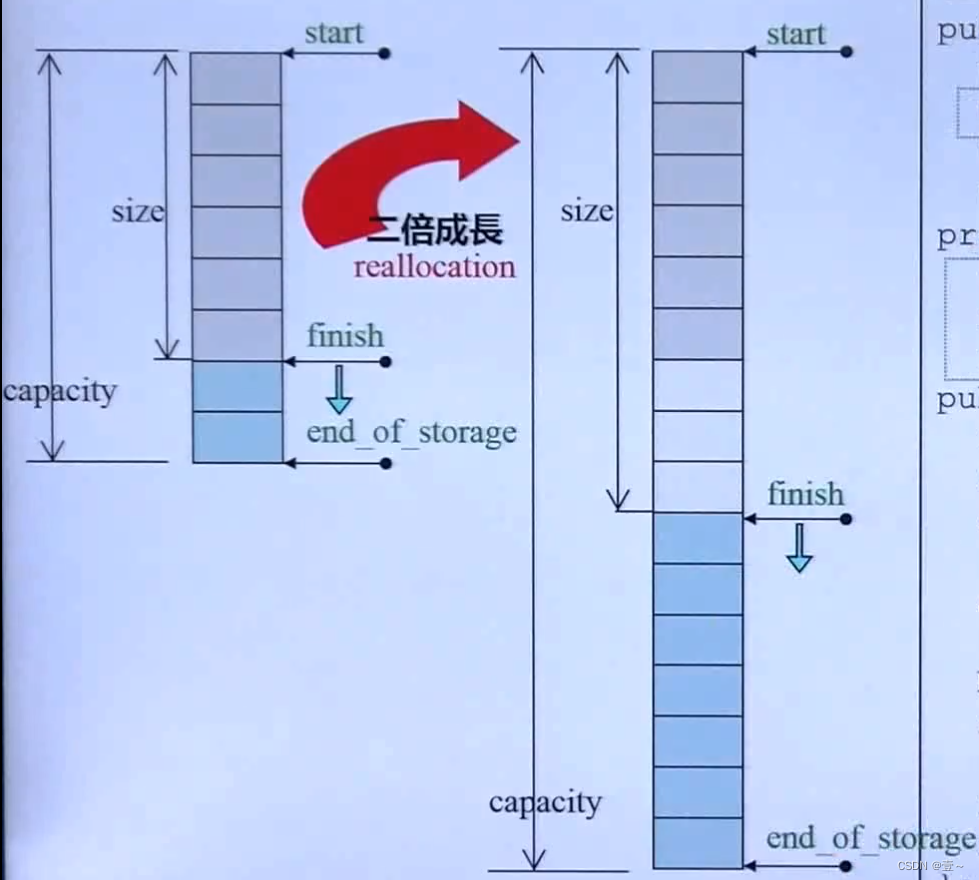
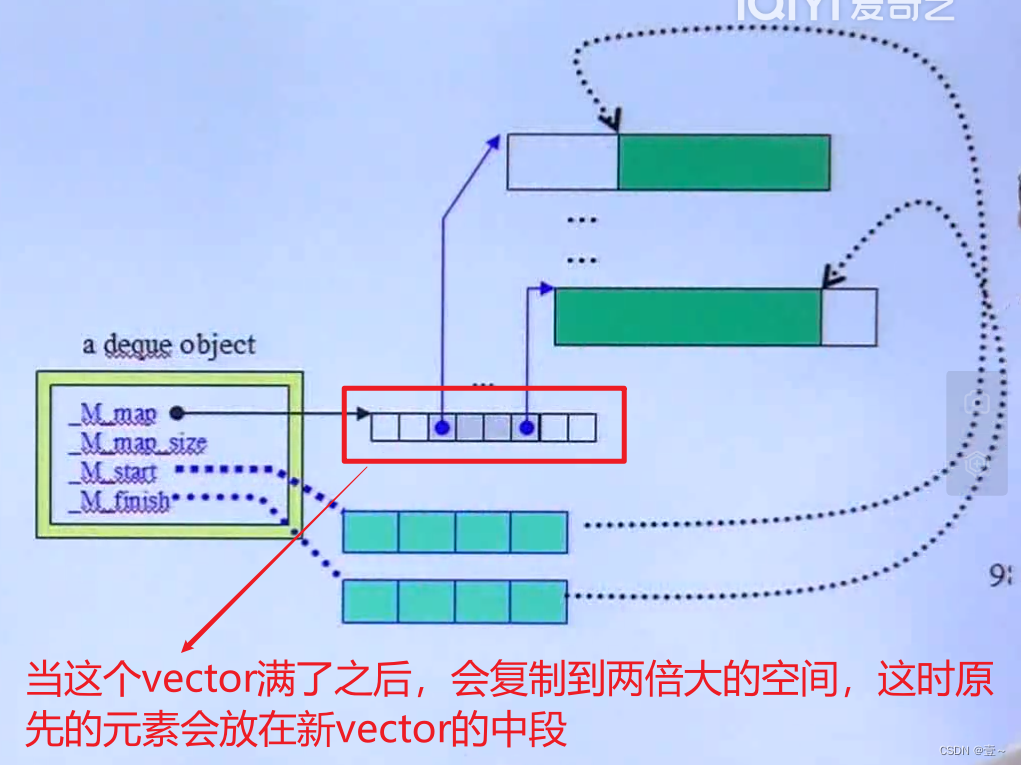
vector有三个iterator变量,分别是start(指向容器的开始)、finish(指向容器中最后一个元素的下一个)和end_of_storage(指向容器的末端的下一个)。当finish与end_of_storage相等时,如果还继续放入元素,则空间会以两倍原先的空间进行扩展,而这种扩展不会在原来的地方进行扩展,而是在别处寻找两倍的空间进行扩展。
11.1 源码(G2.9)
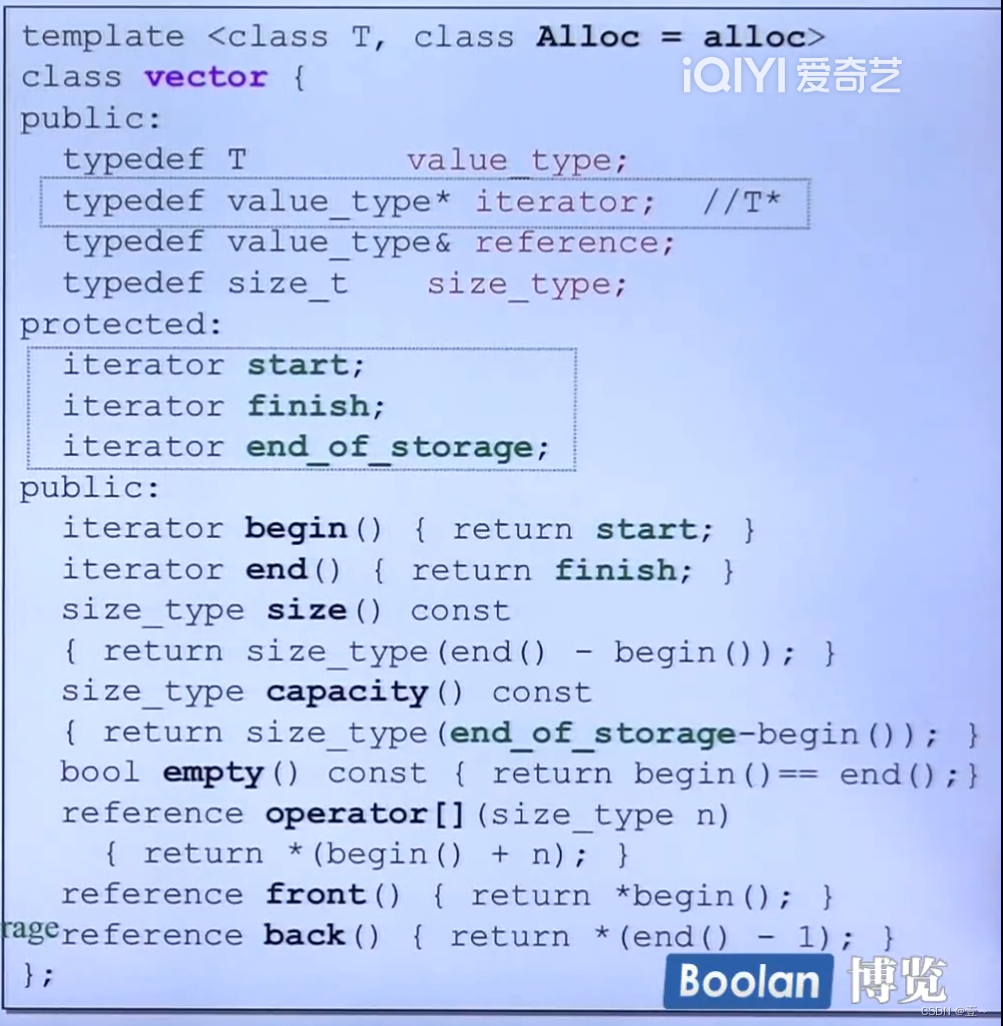
容器只要是存储在连续空间的就会提供operator[]。
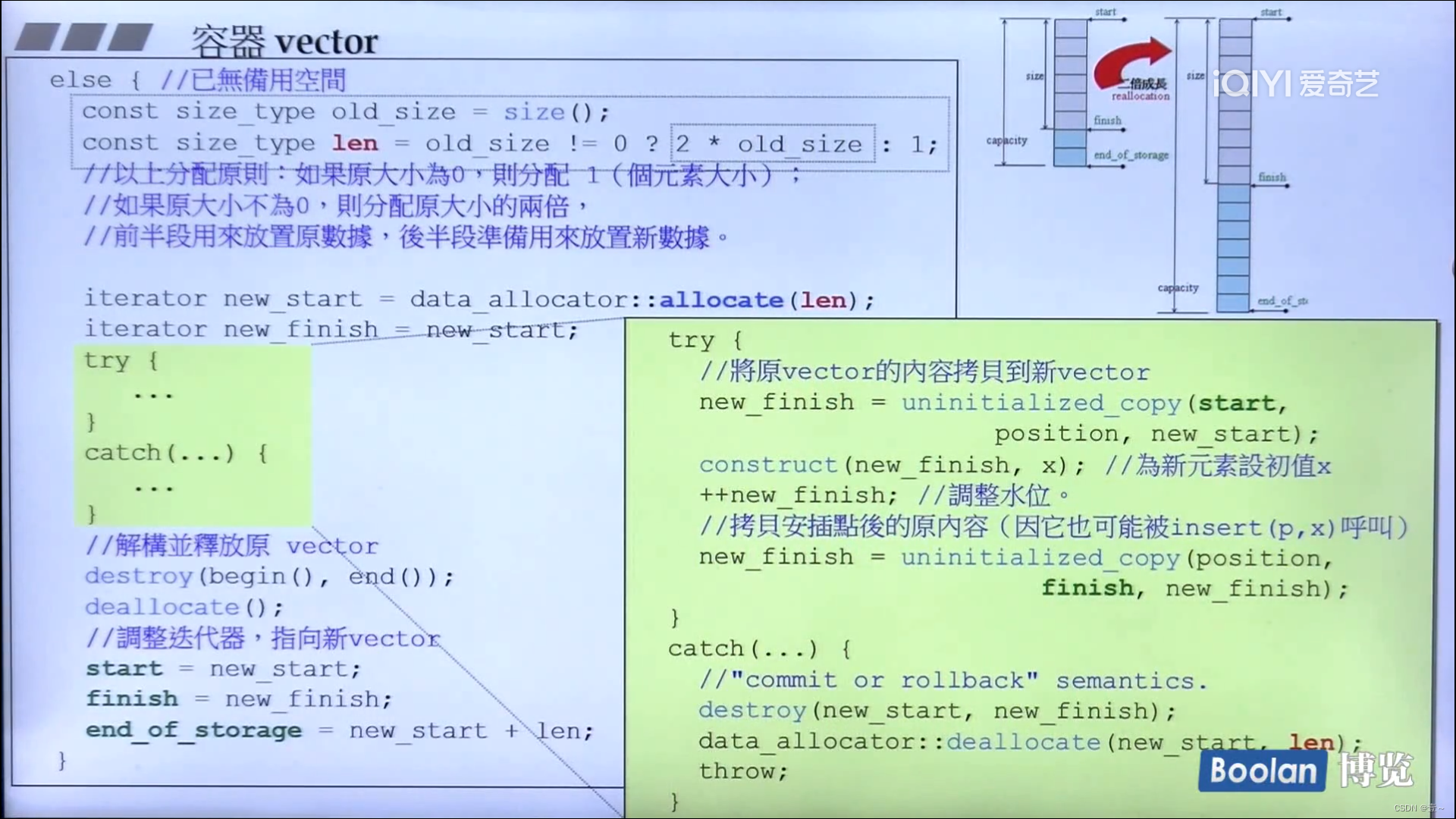
每次的扩展就会引发大量的拷贝动作,而拷贝就会调用拷贝构造函数。而原来的空间也要释放,所以会调用析构函数。所以每次的扩展会调用大量的拷贝构造函数和析构函数,这是一个大的成本,在使用vector时要注意。
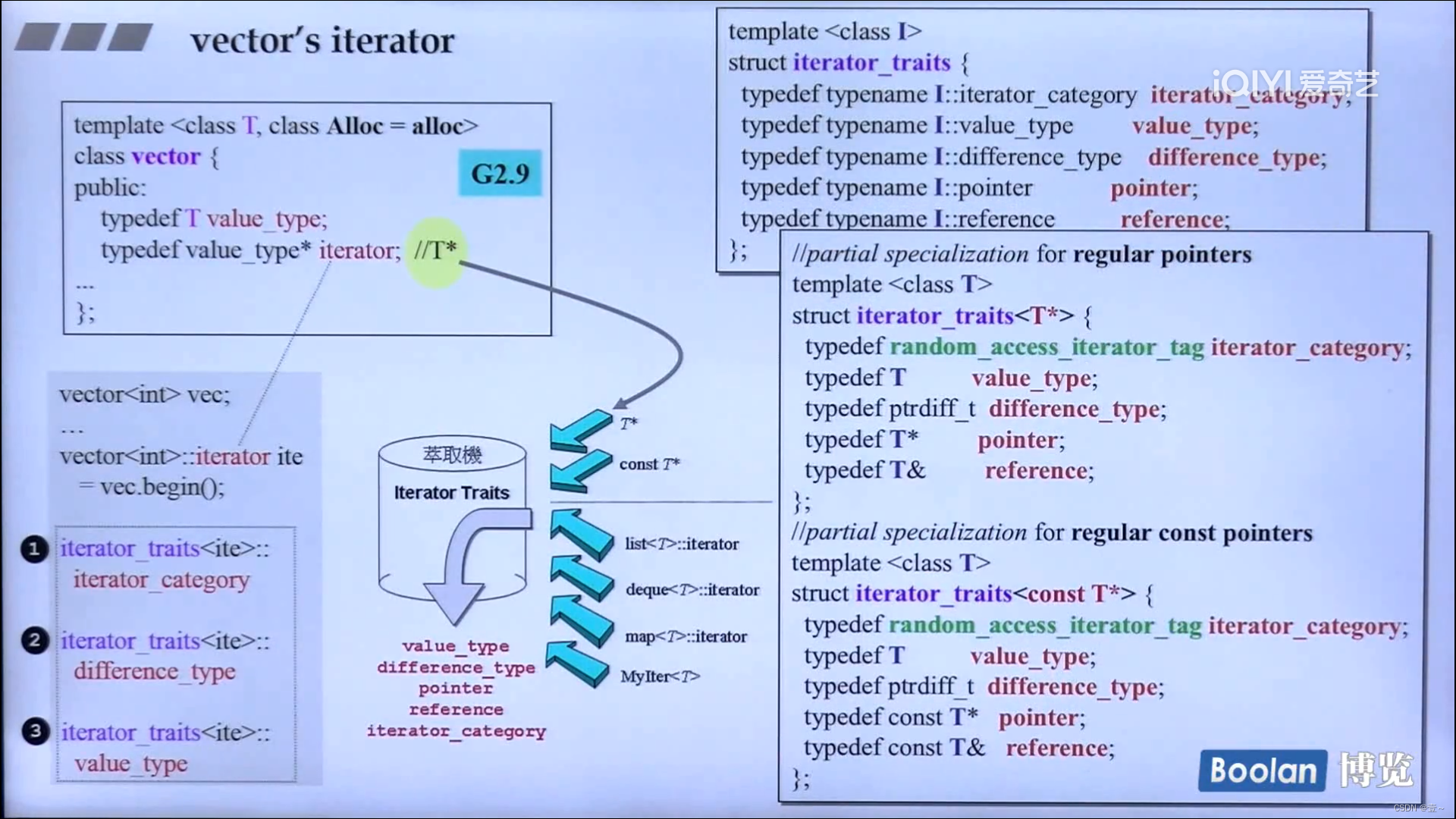
11.2 vector的迭代器
vector的迭代器不用设计得太复杂,因为vector内存是连续的,不用像list一样,把iterator单独设计成一个class,原因是list是内存不连续的。而vector的iterator只需要设计成指针就行了。
11.3 G4.9版本
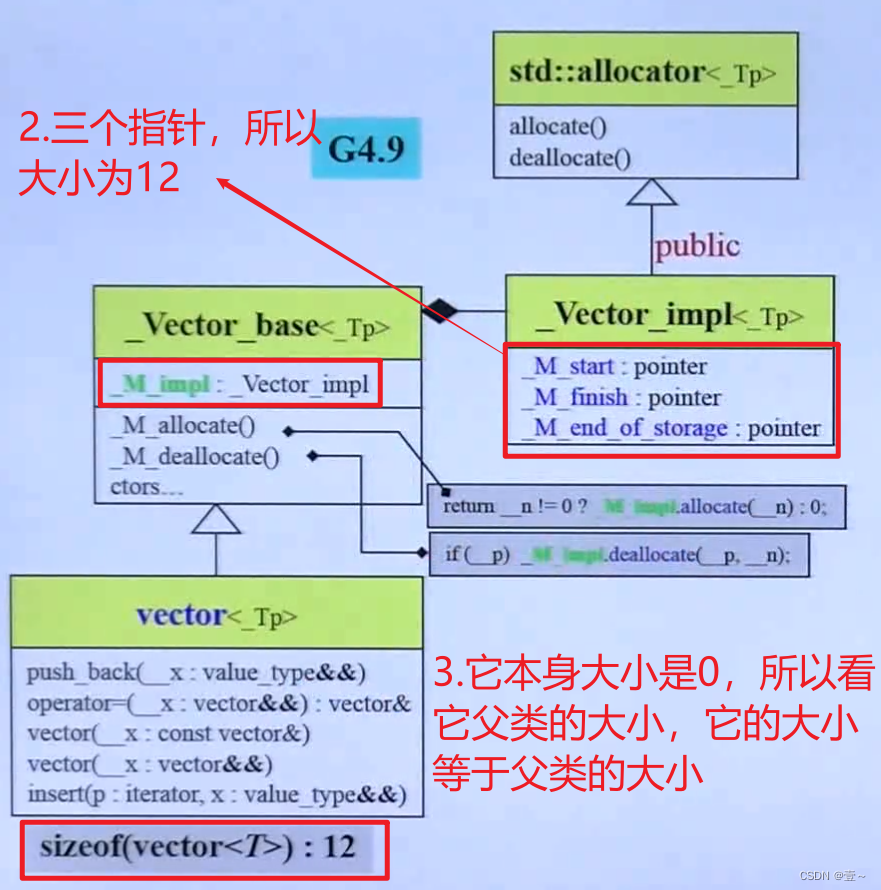

G4.9的iterator是一个class,不是一个单纯的指针。
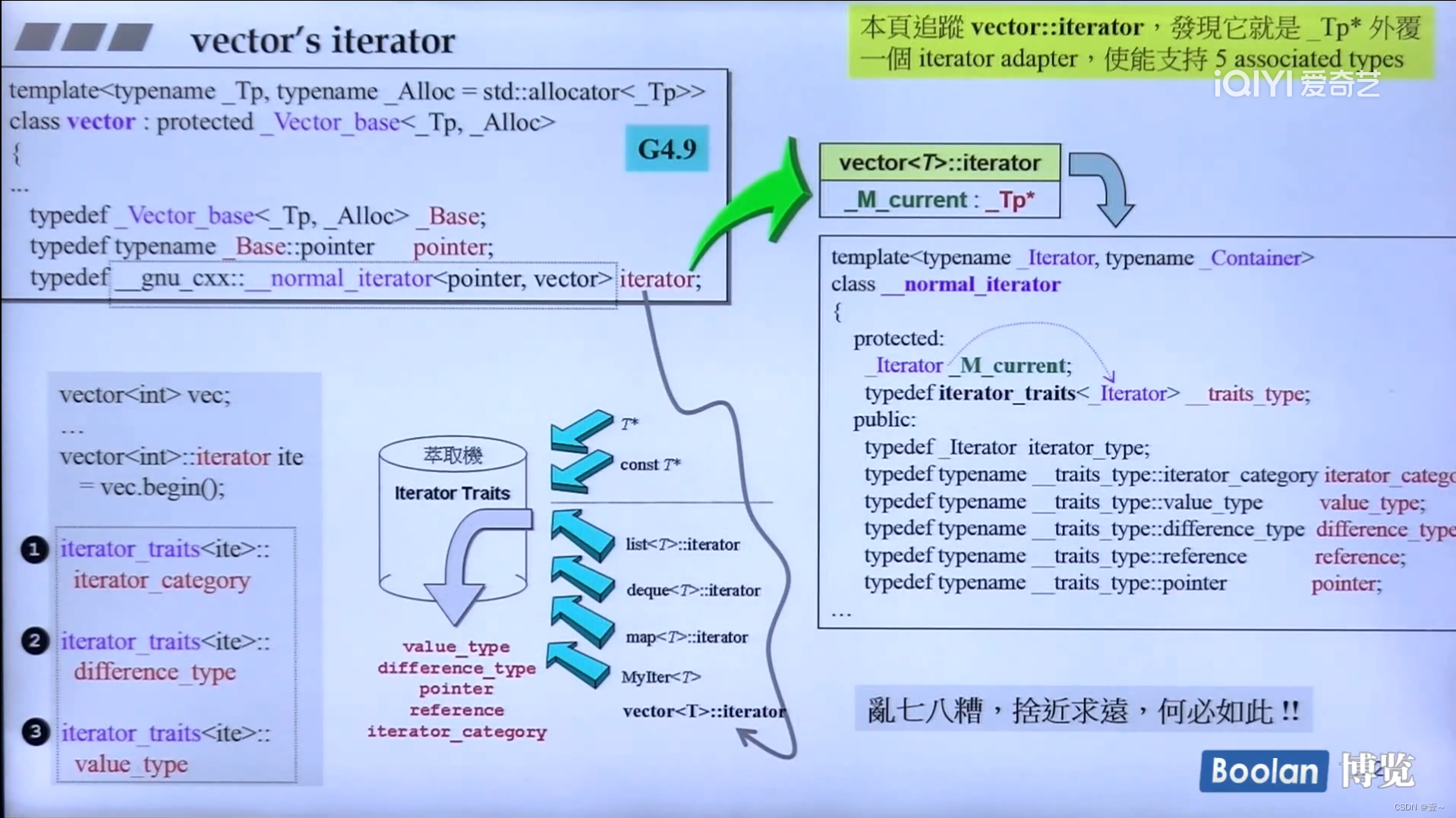
12. array、forward_list(单向链表)深度探索
12.1 array

G4.9 版本

12.2 forward_list(单向链表)
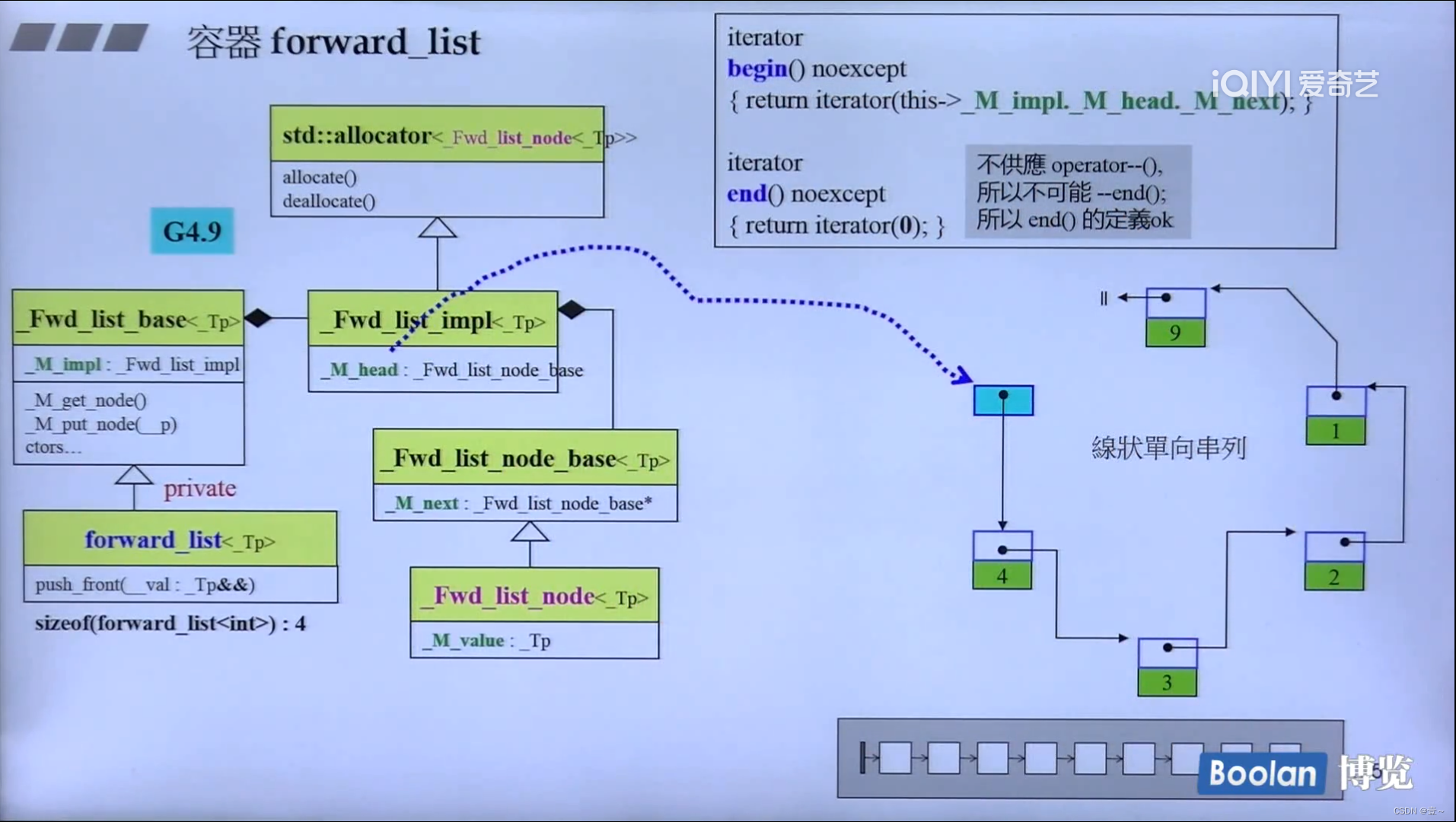
13. deque(双向队列)、stack和queue的深度探索
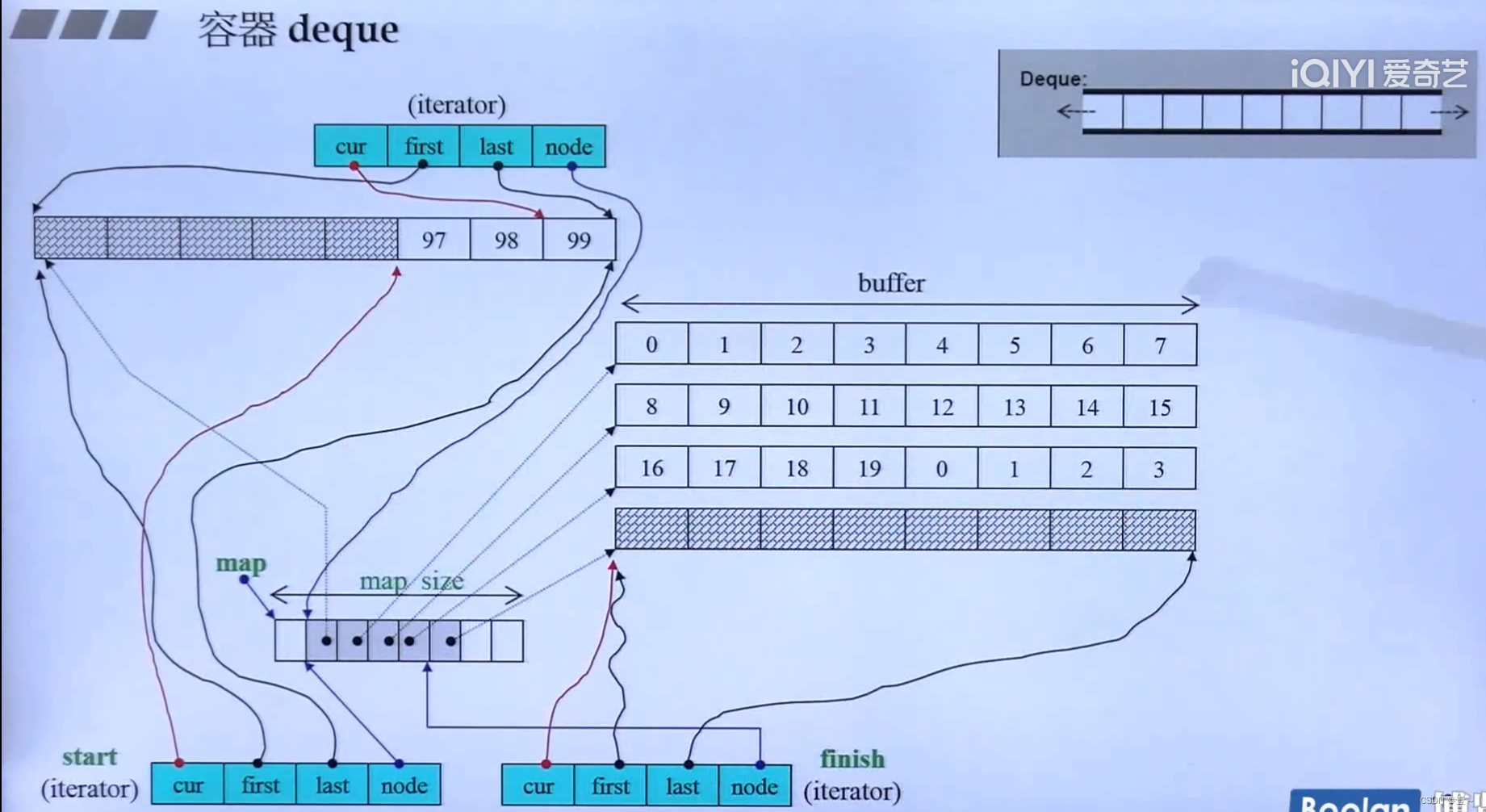
deque的底层,有一个vector(也就是图中的map)用来装指针,指针指向buffer(缓冲区),当deque想往前扩充时,只需要创建一个buffer,然后在vector前面的空地方用一个指针指向它就好。往后扩充也是同理。
deque是一个分段连续的容器,连续是假象,分段是事实。
13.1 源码
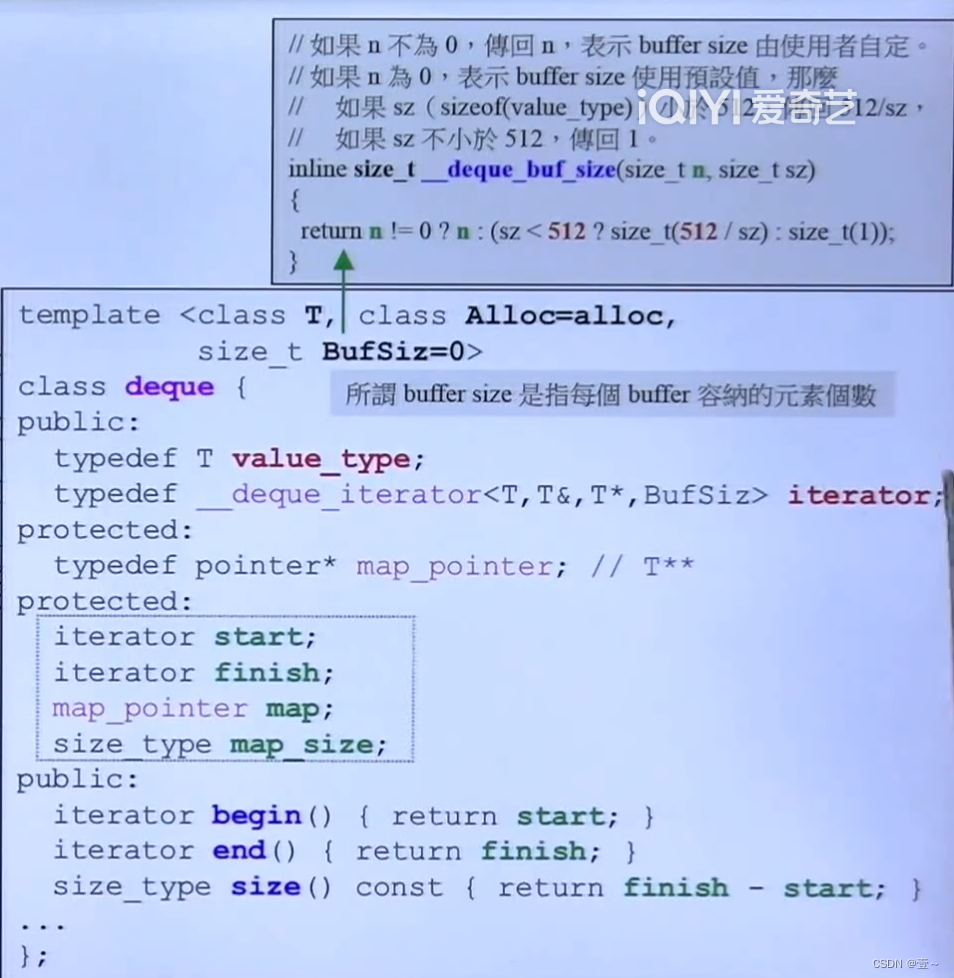
size_type类型的元素大小为4。
一个deque对象本身占40字节(两个iterator,2*16,加上4+4)。
13.2 deque的iterator

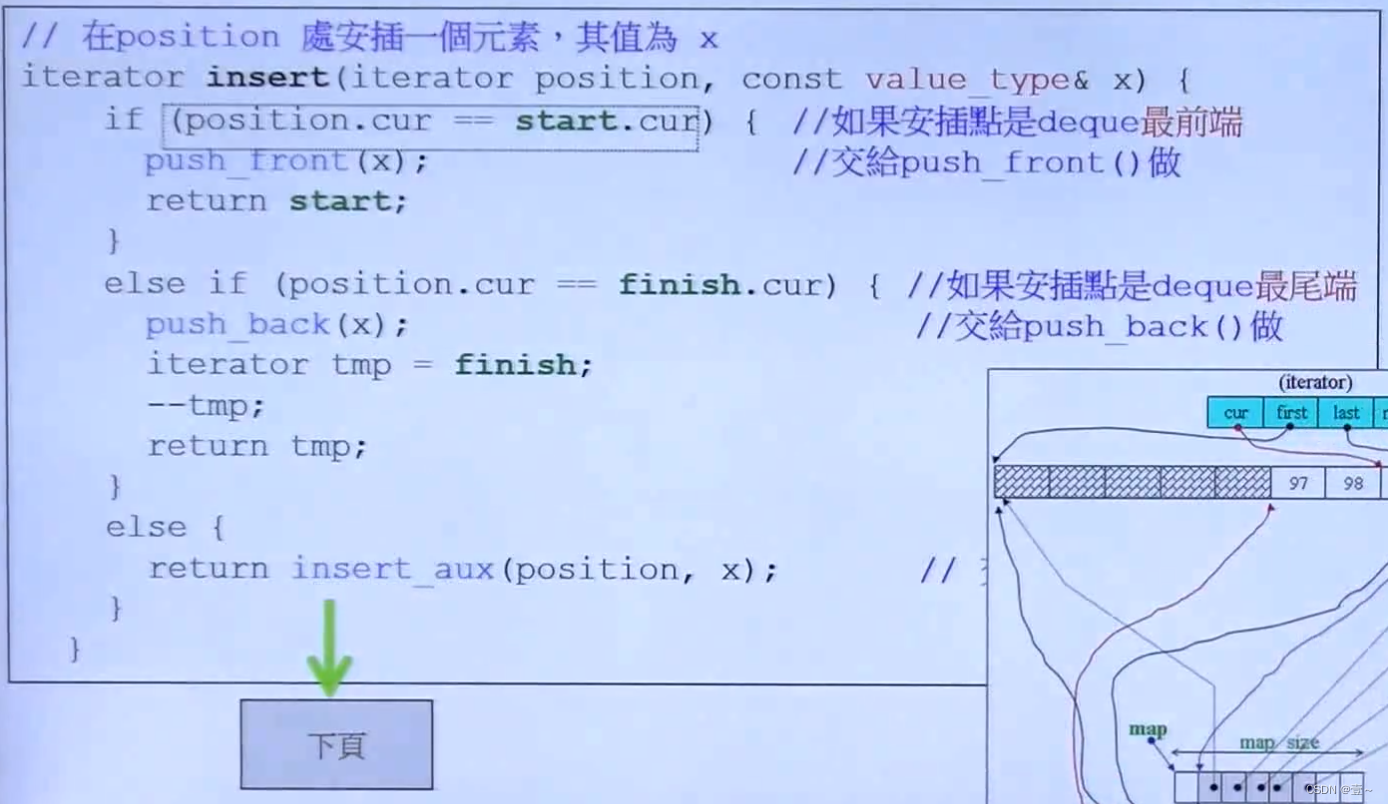
13.3 deque< T >::insert()
因为deque可以两端插入,所以在进行元素插入时可以比较聪明。当插入的位置处于deque所有元素的偏前面时,移动的是将插入位置前面的所有元素,而不是去移动后面的,这样做的目的是提高效率,因为每次的移动都需要调用构造函数和析构函数。

13.4 deque如何模拟连续空间
全是deque iterators的功劳。
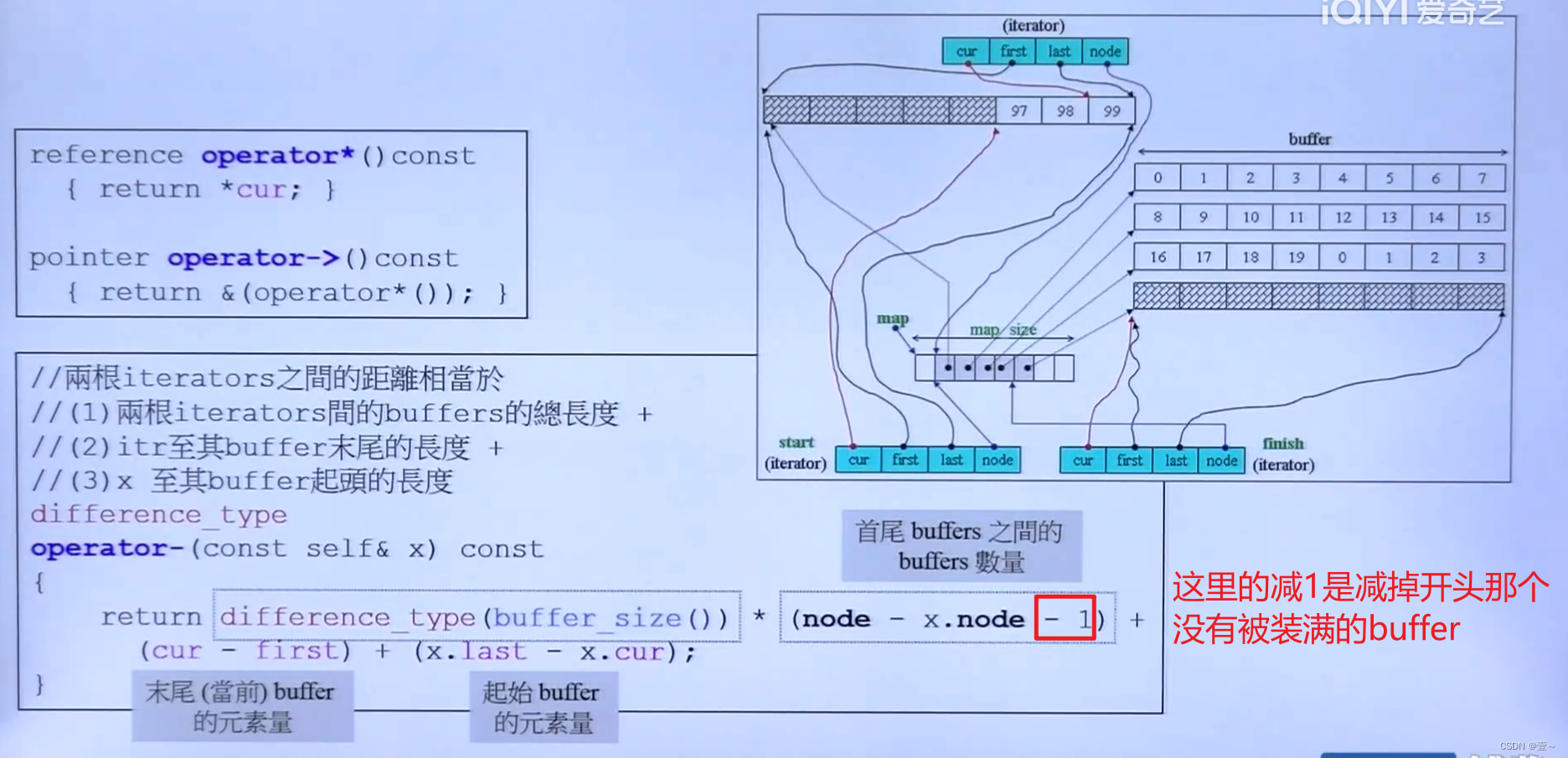

set_node()也可以用来往前跳。
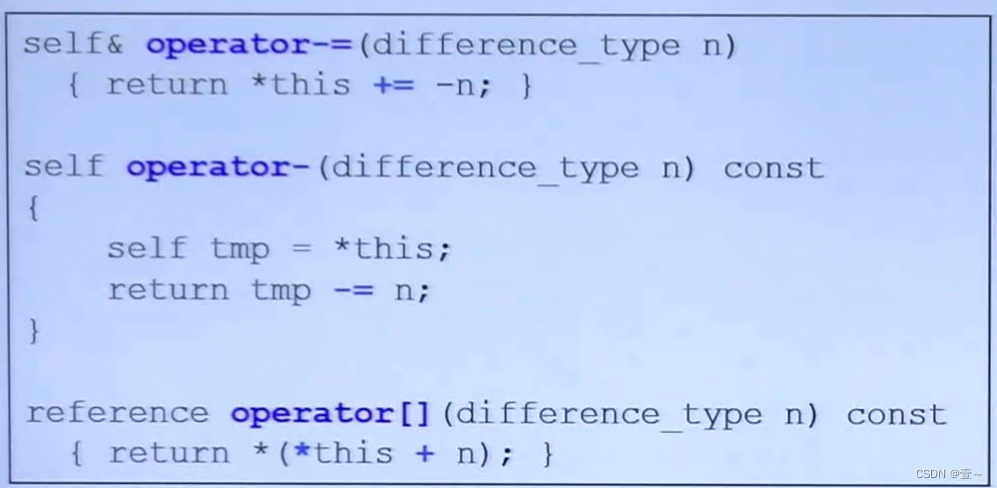
+=和+是实现iterator进行多个元素的跳转。

进行多个元素的跳转有两种情况,第一种是要跳的距离还是在同一个缓冲区内,这种情况就比较简单;第二种情况是跳的距离要跨越缓冲区,这时就得继续需要跨越多少个缓冲区,如何在存储缓冲区指针的vector种,先移动对应的几个,到达对应的缓冲区,然后再移动到对应的位置。
G4.9版本

13.5 queue的源码

stack和queue底部容器都是deque,只是封住某些端口。
13.6 stack的源码

13.7 queue和stack,关于其iterator和底层结构

queue和stack的底层结构默认是deque,但也可以选择list。速度的话,是deque比较快。
还有一个需要注意的点就是,stack和queue都不允许遍历,所有也不提供iterator。 因为一个是先进后出,一个是先进先出,如果允许在指定位置进行插入的话,就会干扰到原来的模式。

注意: stack还可以选择vector作为底层结构,而queue不能。

还有就是stack和queue不可以选择set或map作为底层结构。因为只要一些函数无法调用,就没办法实现原本的模式。
14. 容器rb_tree(红黑树)

我们不应该使用 rb_tree 的 iterators 改变元素值(因为元素尤其独特的排列规则),例如图中 6 改成 60 是不被允许的。但编程层面并未杜绝此事。不过这样设计是正确的,因为 rb_tree 是为 set 和 map 服务(作为其底部支撑),而 map 允许元素的 data 部分被改变,只有元素的 key 才是不可被改变的。
rb_tree 提供两种插入操作:insert_unique() 和 insert_equal()。前者表示插入的 key 在整个 tree 中是独一无二的,否则插入失败;后者表示插入的 key 是可以重复的。
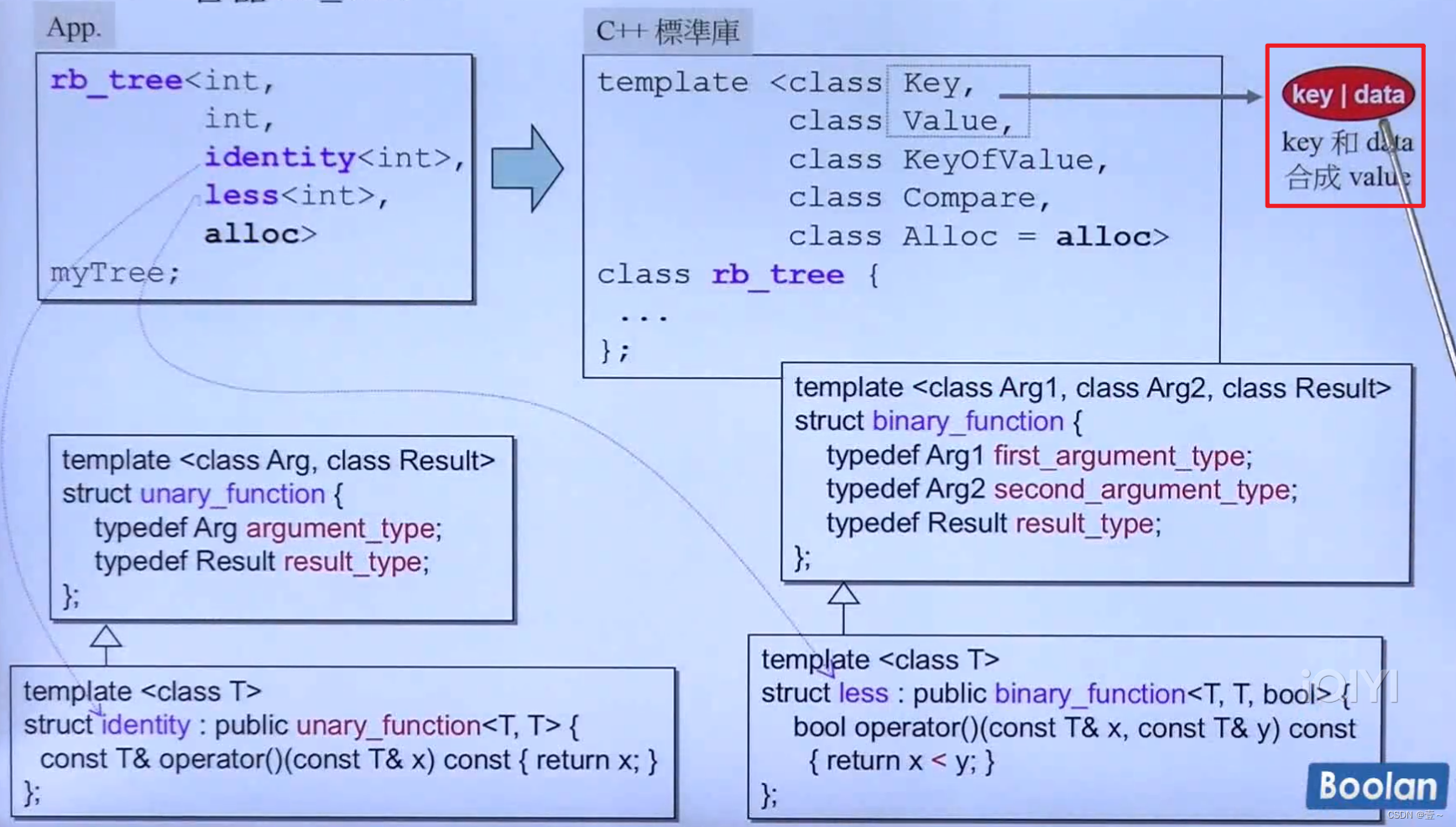
第三个模板参数KeyOfValue表示从value中取出key的方式。
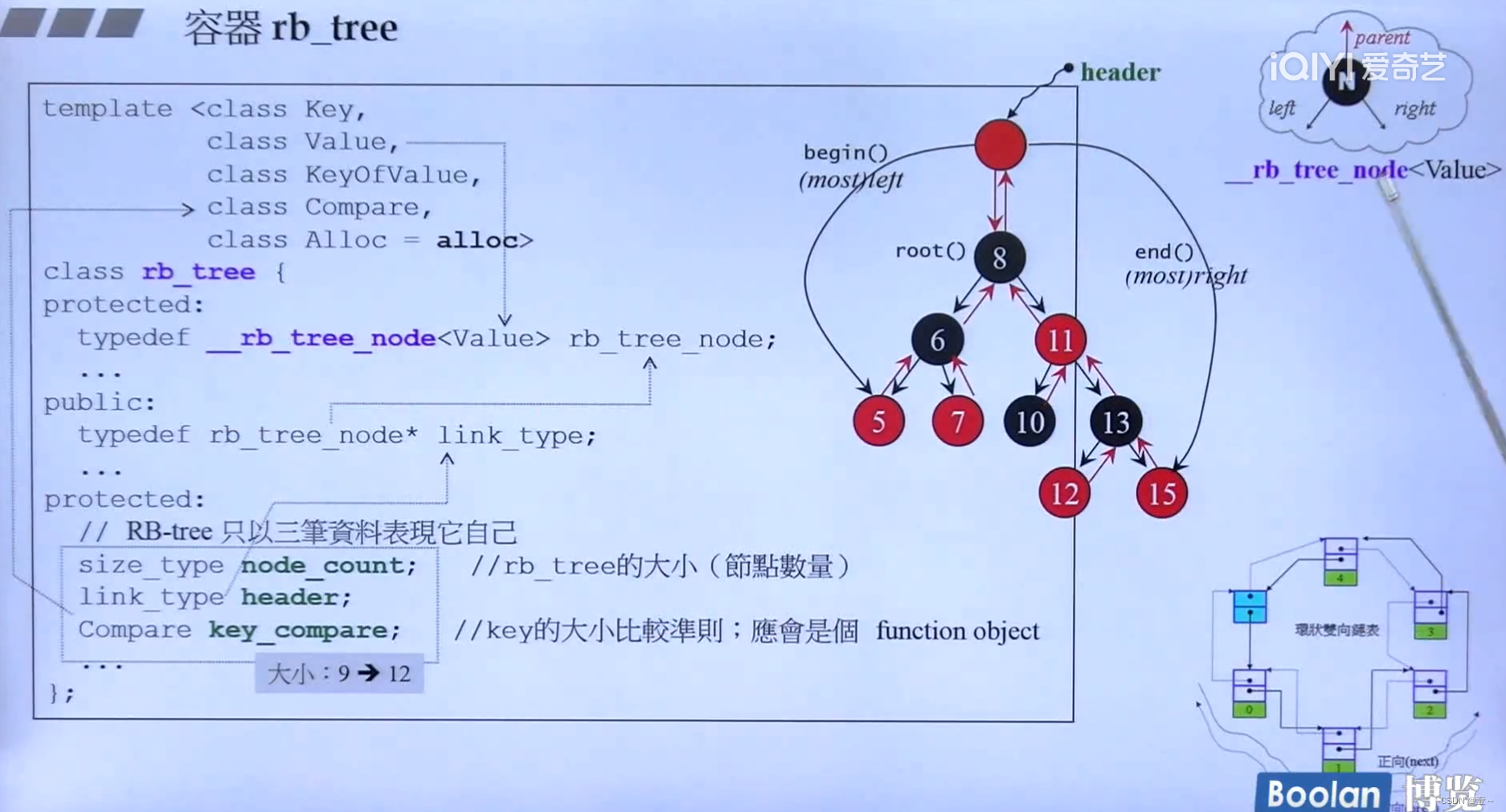
size_type是unsigned_int,所以大小为4字节;link_type是指针,所以大小也为4字节;key_compare是一种仿函数,仿函数是一个大小为0的class,但会给它分配1字节的大小。所以rb_tree整个类的大小为9,编译器的默认对齐方式为4字节,所以它的大小为12字节。
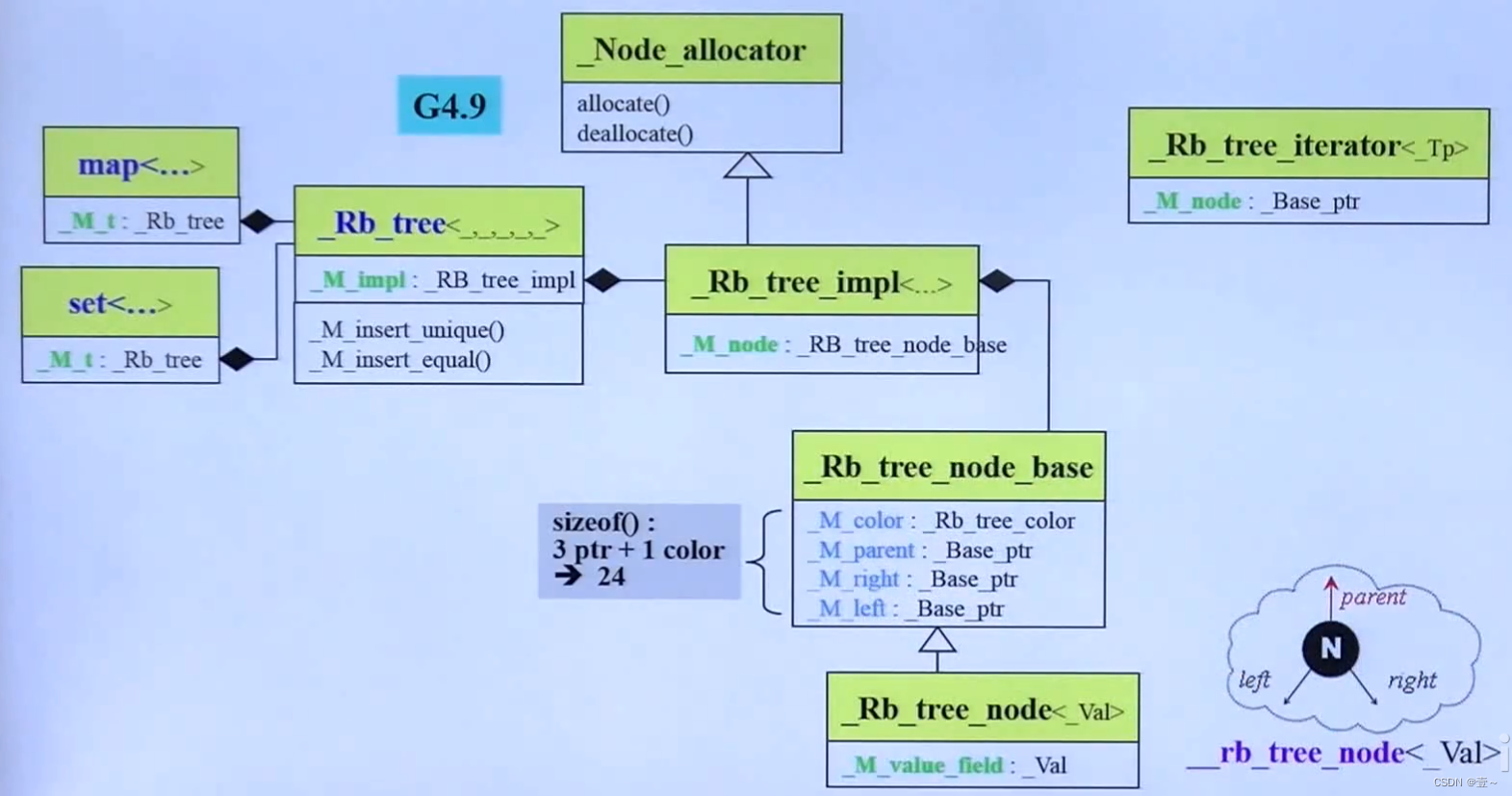
G4.9的红黑树
15. 容器set和multiset
value包含key和data。
set/multiset 元素的 value 和 key 合一:value就是key,相当于就是没有data。

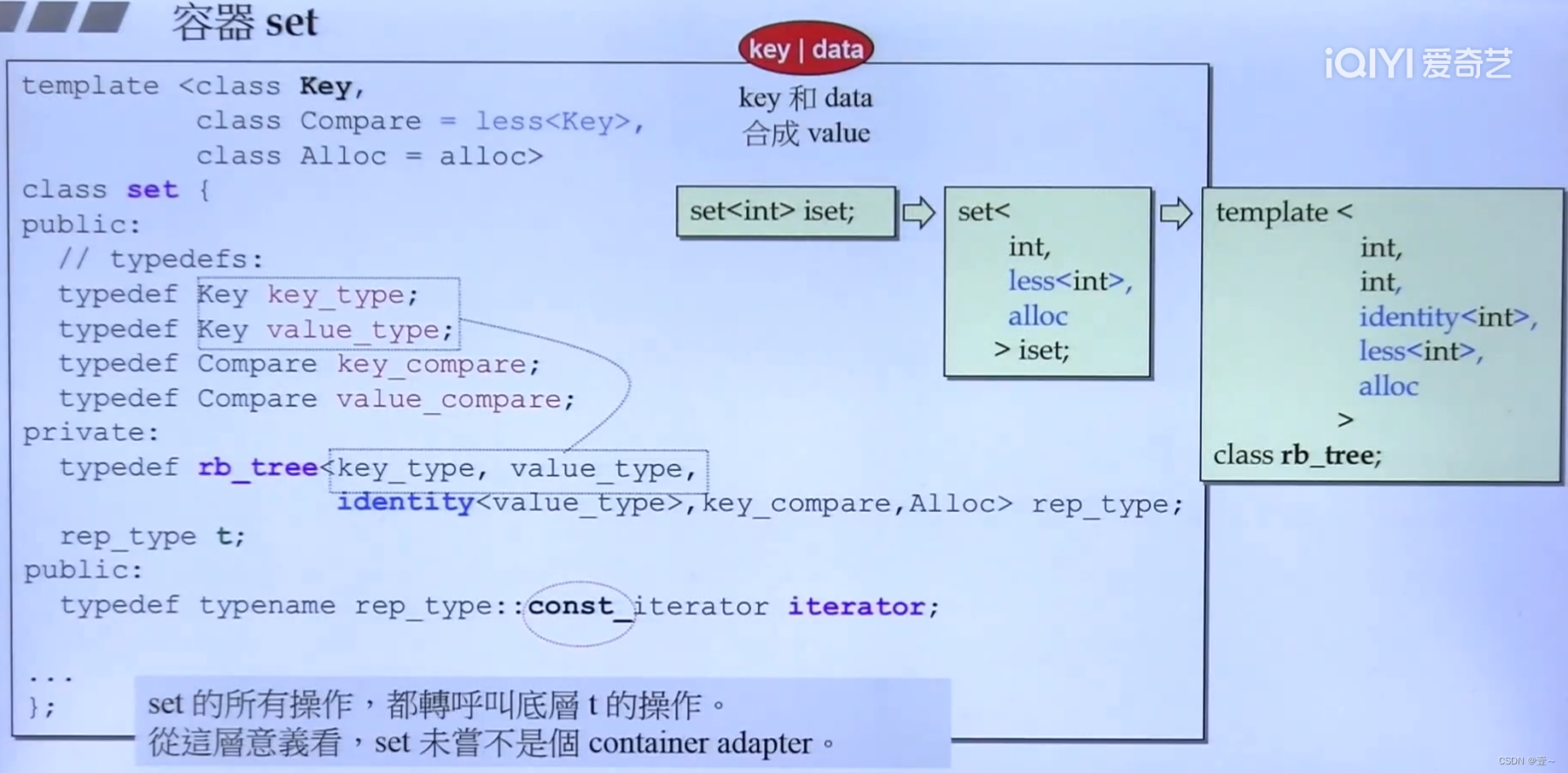
identity 就是将key看成value,取value时,返回key。
15.1 set in VC6

VC6里的_Kfn等同于identity()。
16. 容器map和multimap

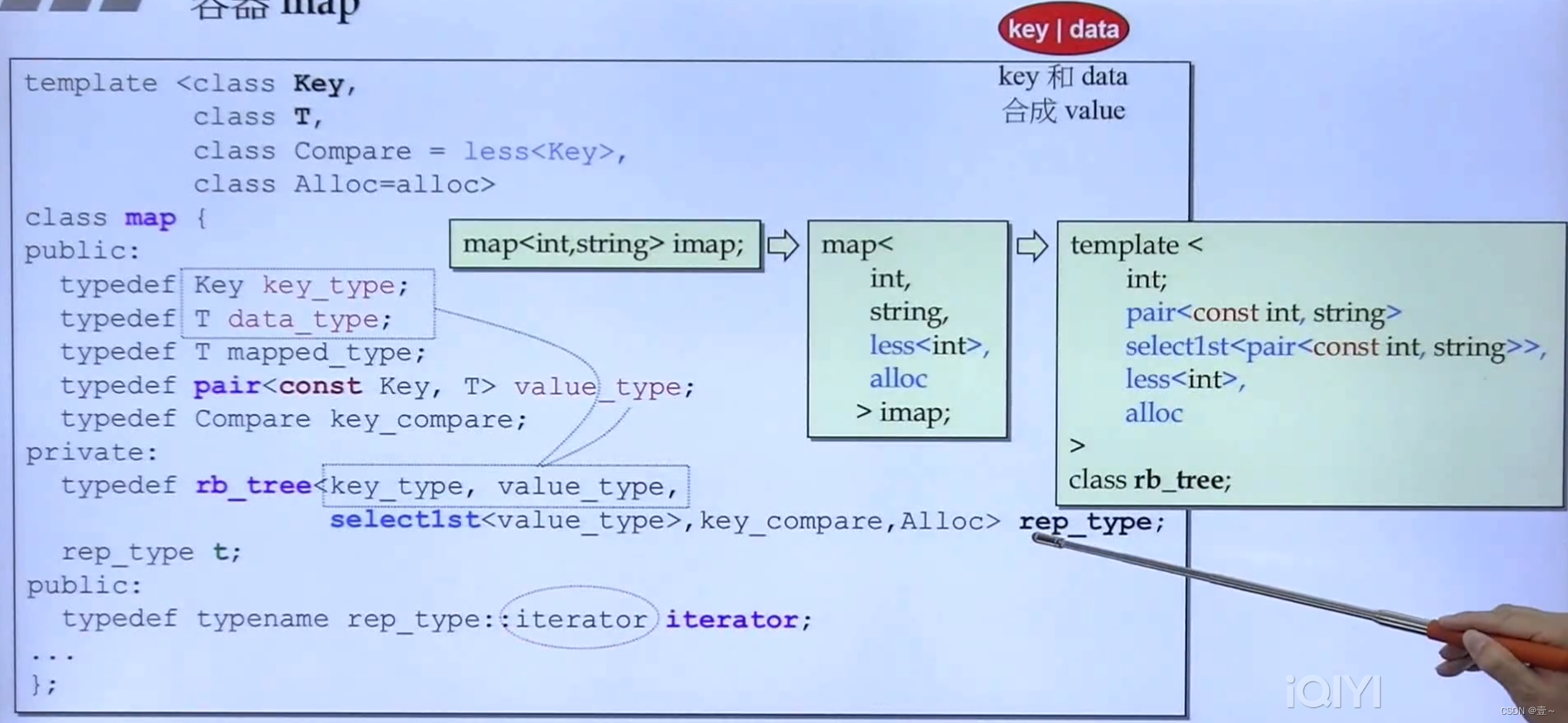
map不允许通过迭代器来修改key,它是通过在pair中,直接让key为const。
16.1 map in VC6

VC6里没有select1st(),这个函数的作用是查找容器中的对应的key。
16.2 multimap
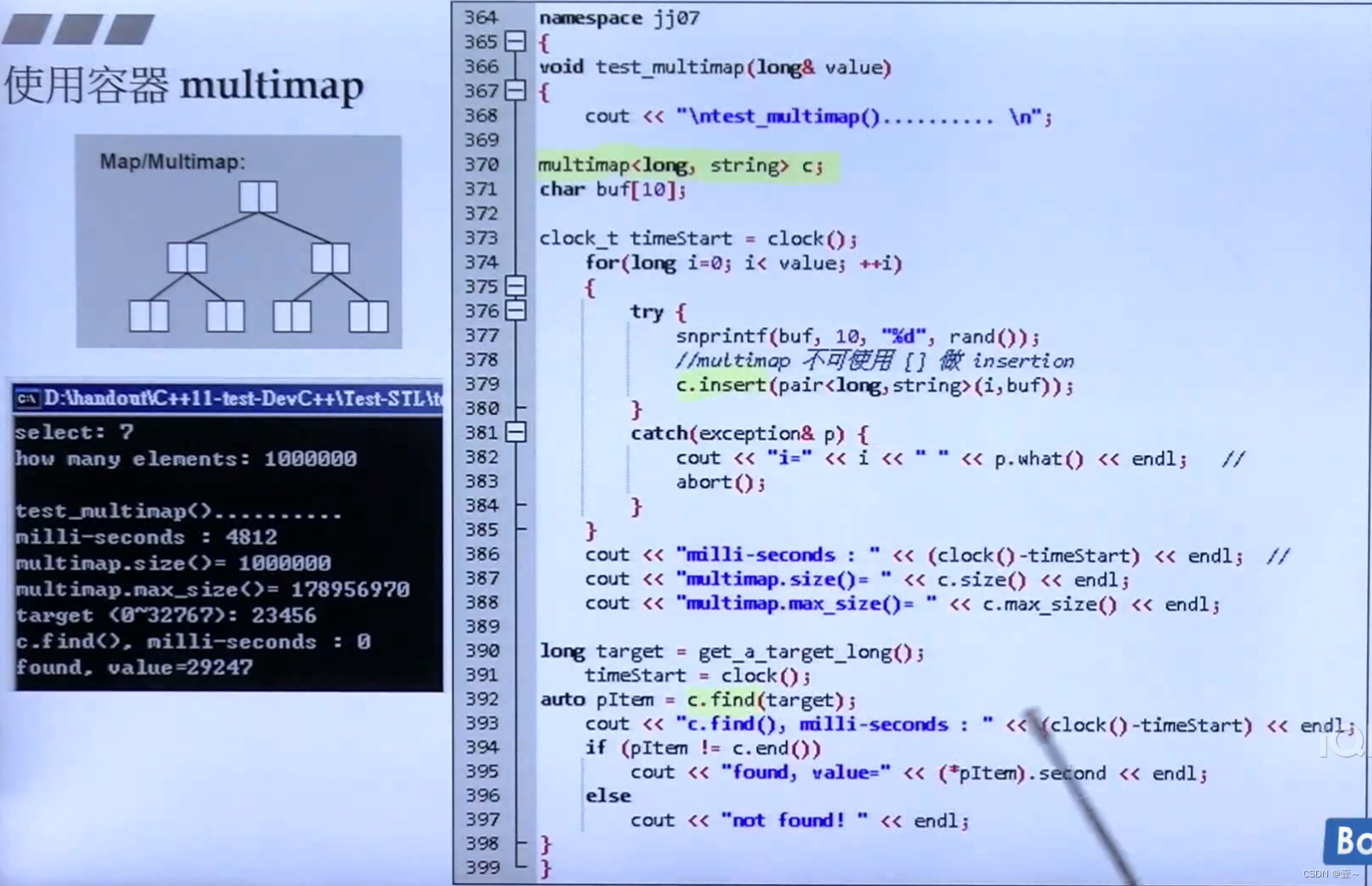
multimap不可使用 [] 做插入操作。

当用[]想map插入元素时,首先会先检查map里有没有该value,如果有,则用 iterator 指向其中第一个value(如果是multimap的话,有多个value相等的);如果没有,则 iterator 会找到最适合插入该value的位置。
17. 容器hashtable(哈希表)
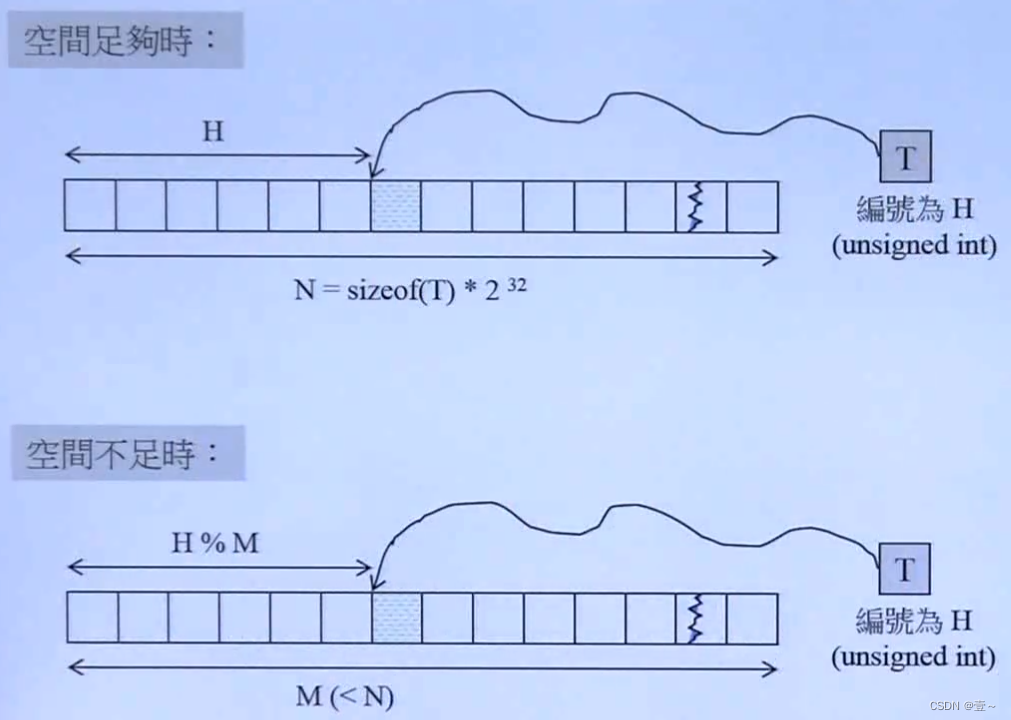
18. 迭代器的分类

算法看不见容器,对其一无所知。所以,它所需要的一切信息都必须从迭代器(iterators)取得,而 iterarors (有containers提供)必须能完成 algorithm 的要求,才能搭配该 algorithm 的所有操作。
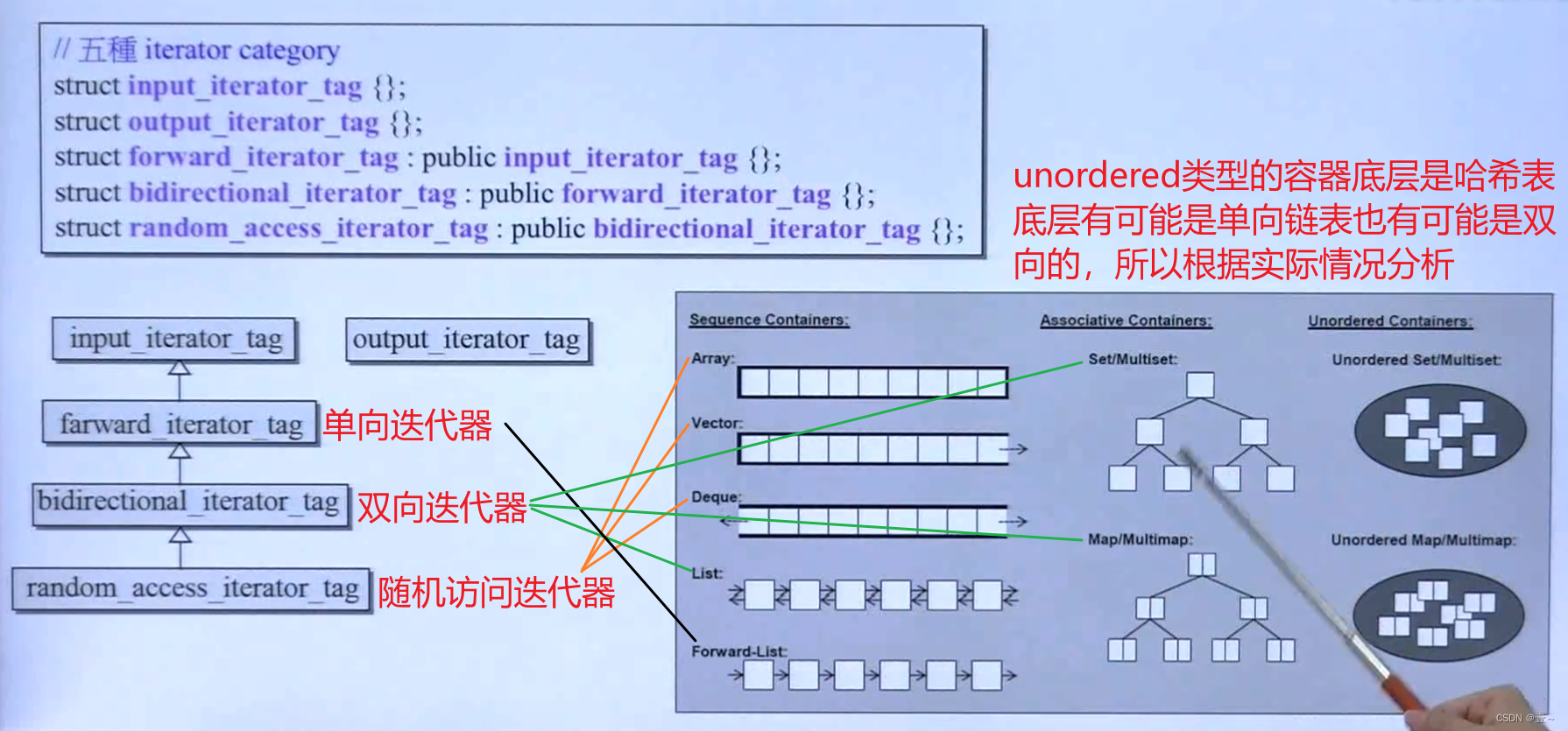
迭代器的分类如上图所示,使用结构体来表现,而且有的还是继承关系。
注意上面的连线,Forward-List(单向链表)用的迭代器是forward_iterator_tag(单向迭代器);Array、Vector、Deque(虽然它底层不是完全连续) 用的迭代器是random_access_iterator_tag(随机访问迭代器);List(双向链表)、Set/Multiset、Map/Multimap 用的迭代器是 bidirectional_iterator_tag(双向迭代器)。
unordered_set/multiset 和 unordered_map/multimap 视情况而定。
18.1 自己编写能够得到容器迭代器类型的代码
当我们想要用代码来识别当前容器的迭代器是什么类型时,可以使用下图这种方法,使用萃取机(iterator_traits< I >::iterator_category)来获得当前容器的迭代器的类型。根据编写函数重载的函数,就可以输出对应容器迭代器的类型。
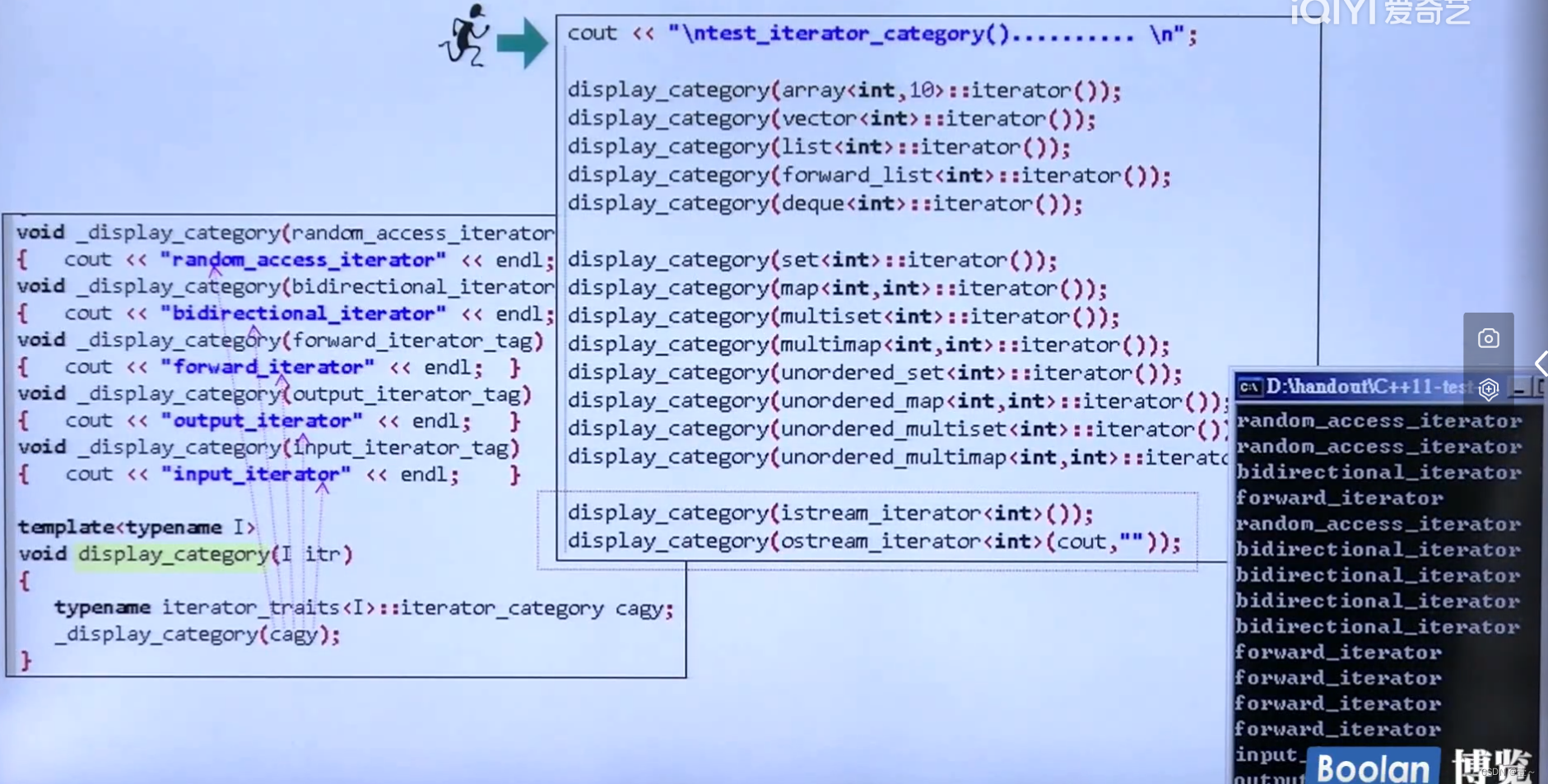
注意: istream_iterator 的类型就是input_iterator;ostream_iterator 的类型就是 output_iterator。
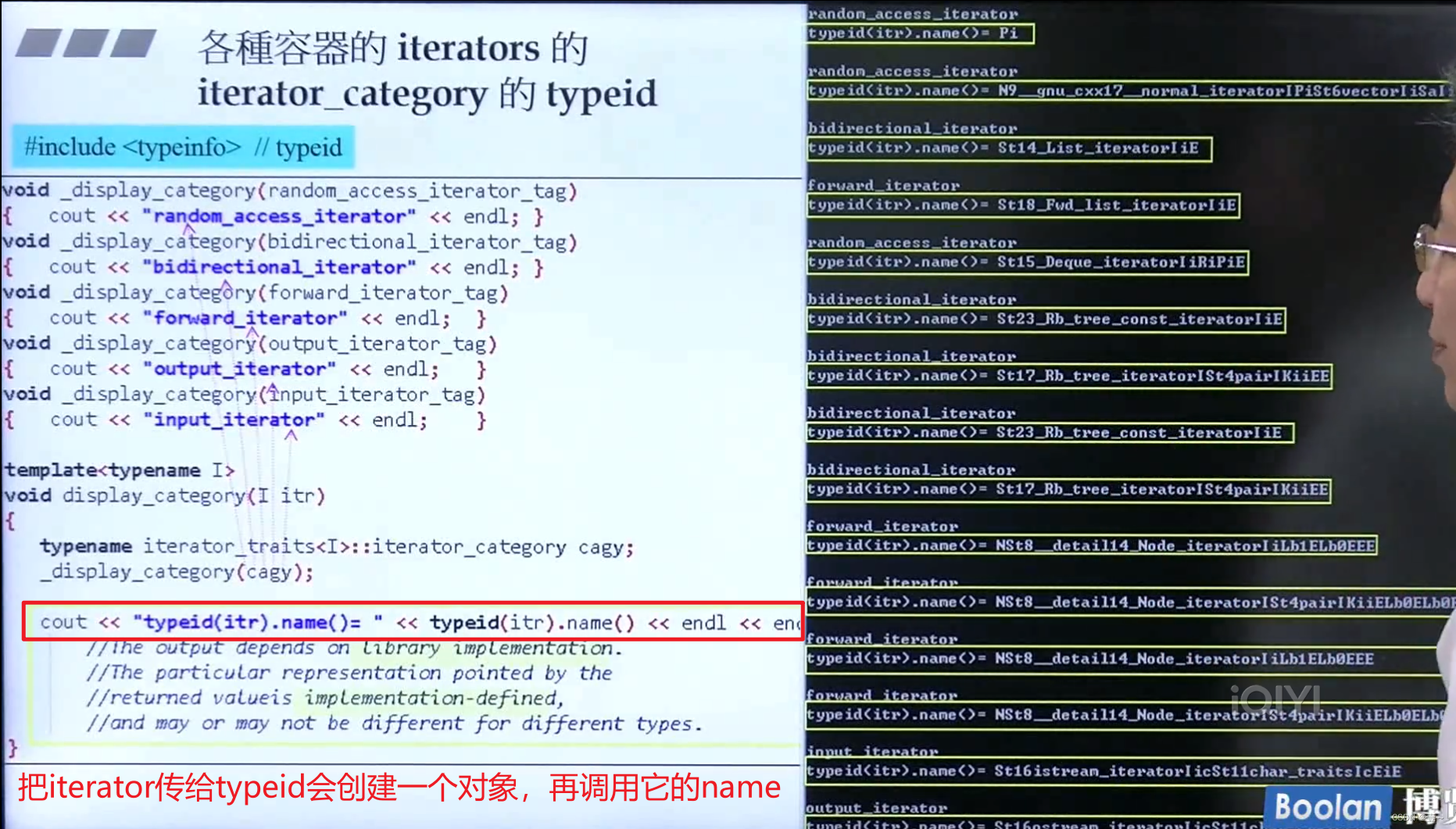
18.2 利用标准库自身的标识(各种容器的迭代器的iterator_category 的typeid)
要记得包含同文件 #include< typeinfo > 。
18.3 迭代器分类对算法的影响
18.3.1 一个例子(求两个迭代器之间的距离)

distance()是一个算法,用于计算两个迭代器之间的距离。但它的距离的类型不是 int,迭代器中有一种数据类型是用来代表两个迭代器之间的距离的(difference_type)。所以要把我们的迭代器类型传给萃取机,让萃取机帮我们找到对应的 difference_type,所以这个函数的返回类型是 iterator_traits< InputIterator >::difference_type。
它有一个对外开放的版本,底部调用就有两个版本,根据迭代器的类型来选择对应的函数。注意上面代码中的 category() ,这种语法的使用,就是一个临时对象,type name加上括号可以代表一个临时对象。
在数据很多的情况下,使用第二个 distance 会比第一个快很多。
这这里就可以看出,为什么迭代器类型要用结构体来表示而不是用枚举类型?
使用结构体来表示迭代器类型可以方便地封装相关数据和行为,并实现多态性,从而提高代码的灵活性和可复用性。例如上面的例子,五种迭代器类型,而只有两种迭代器类型的函数,这时,如果是 forward_iterator_tag 或者是 bidirectional_iterator_tag 类型就会直接调用第一种函数。
18.3.2 一个例子(让迭代器移动对应的距离)
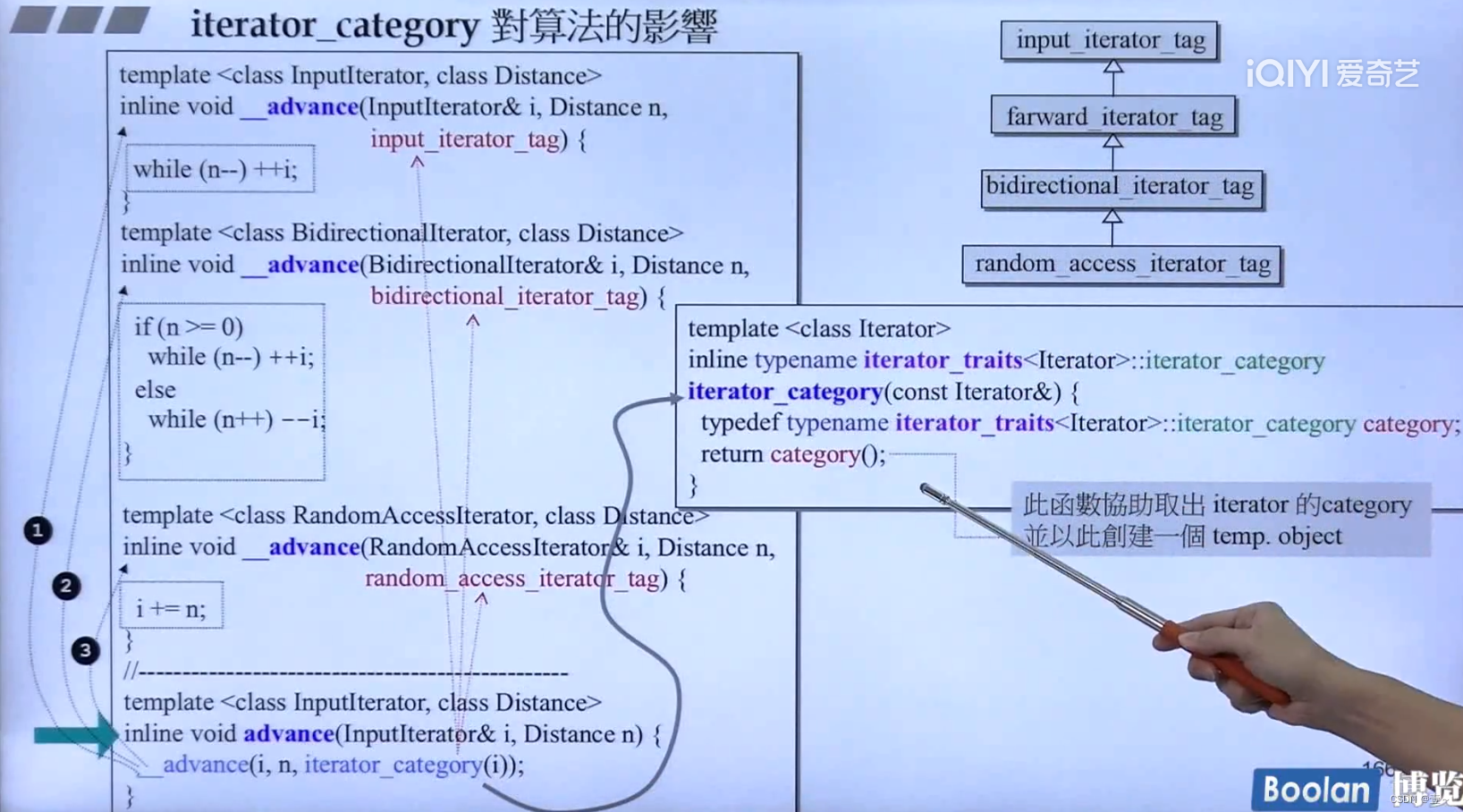
跟上面是一样的道理。
18.3.3 另一个例子(拷贝函数)
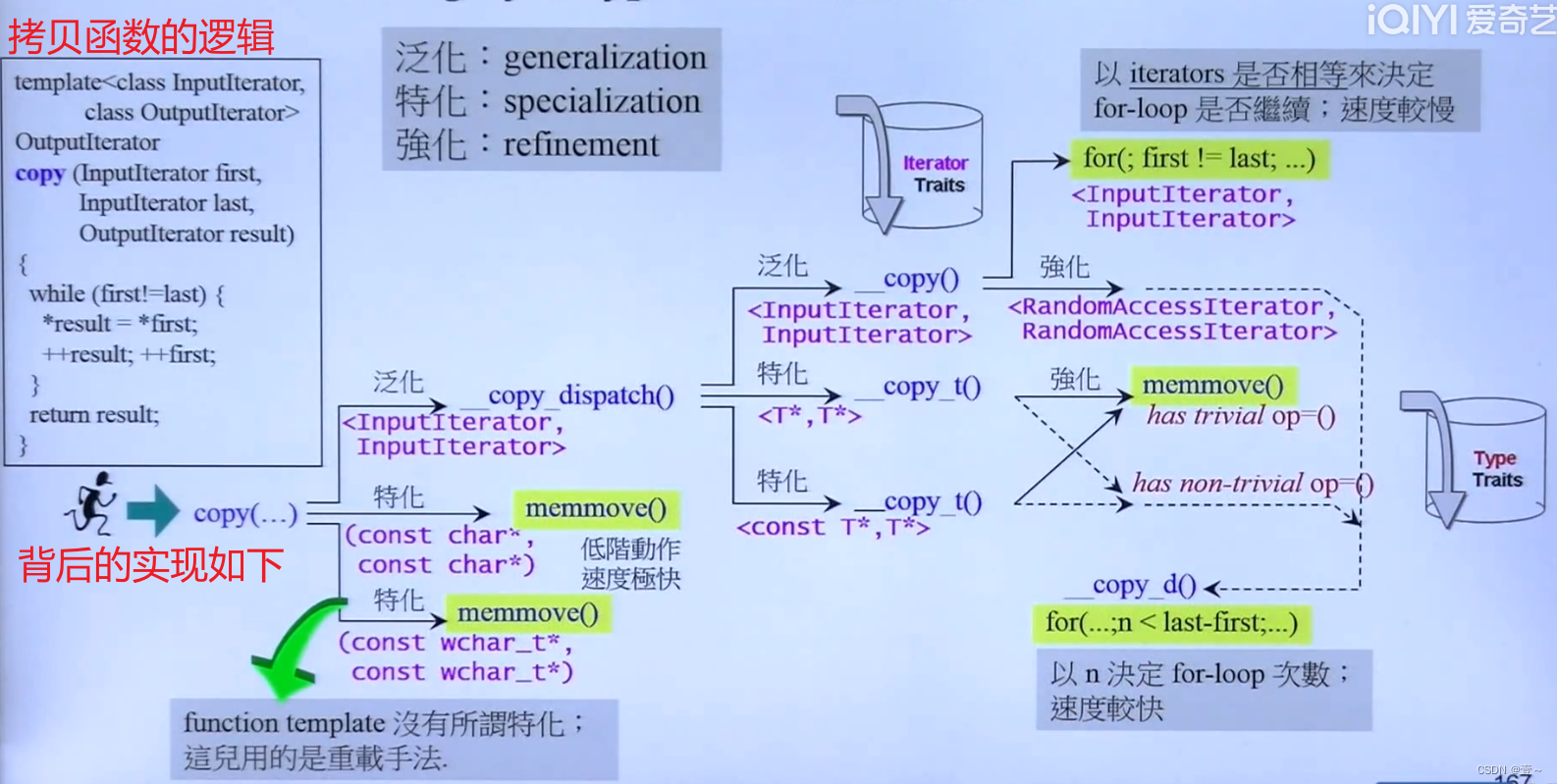
上面memmove()是C语言的一个拷贝字节的函数,属于低阶动作,速度较块;当最后判断是< T*,T* >或< const T*,T* >的话,就会经过 Type Traits 的判断,如果是不重要的(has trivial op=())话,就调用 mommove()处理,如果是重要的就用__copy_d()处理。
总之就是根据参数的类型去调用最快的函数。
18.3.4 另一个例子(destroy)
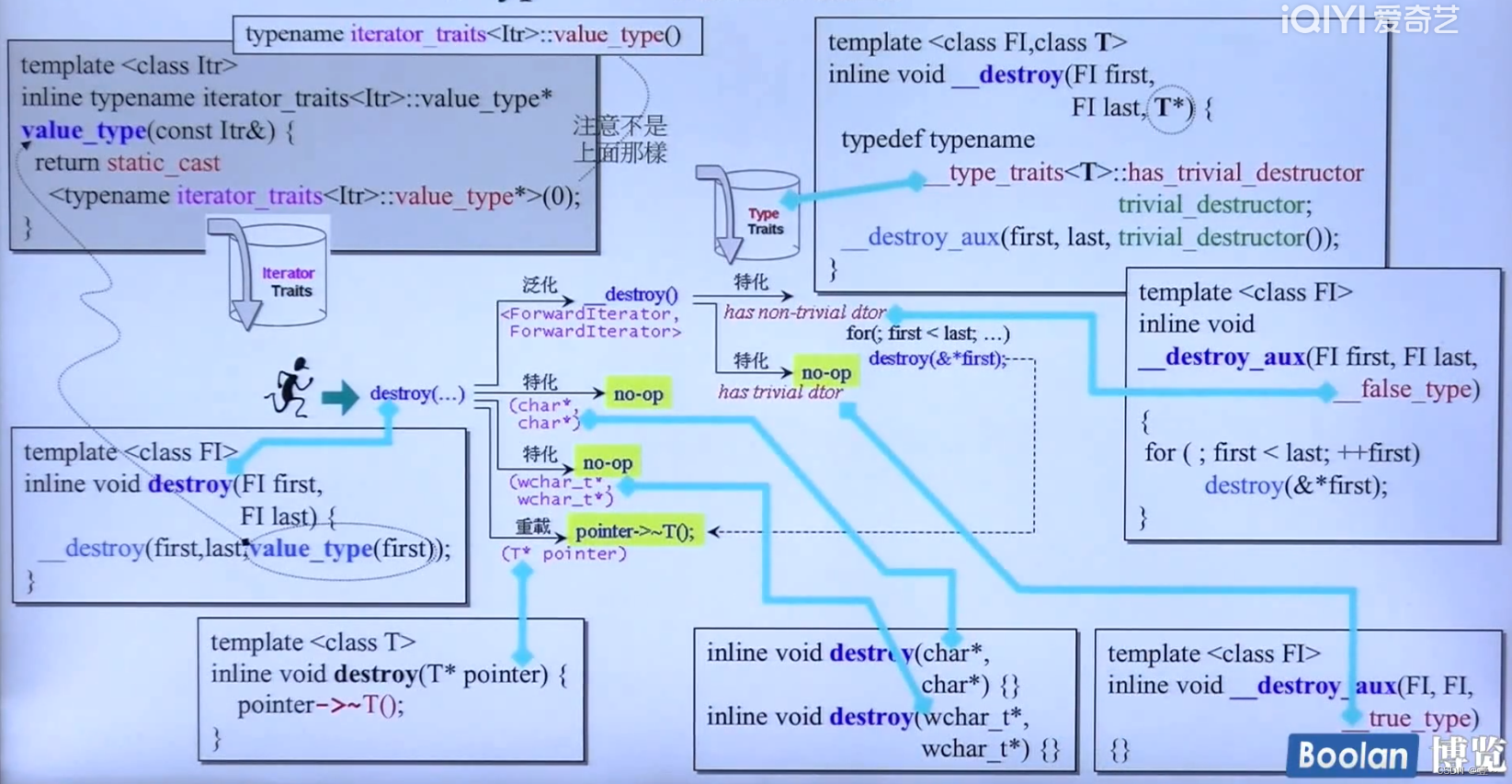
19. 算法源码剖析(11个例子)
20. 仿函数(Functors)
functors 是六大部件中大多时候比较会自己编写的一种,就是写一些能融入到STL(标准库)里的东西就是这种东西。 仿函数又称函数对象,专门为算法服务,当算法需要一些指定的规则(操作)时,就可以使用functors;例如,sort算法中我们可以自己指定排序的顺序,就可以创建一个functors,然后把functors传进去。
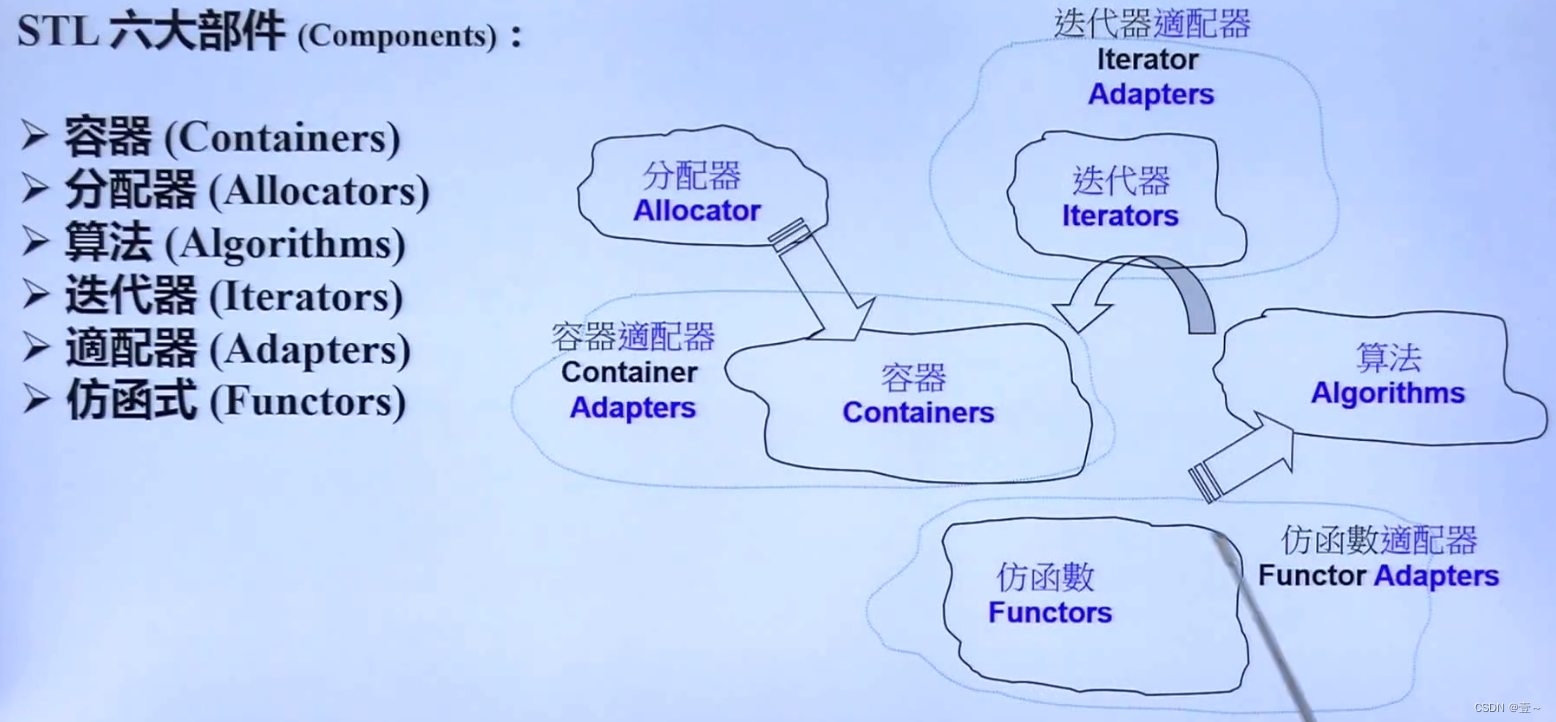
functors有三大类:算术类、逻辑运算类和相对关系类(比大小)。仿函数的特点就是重载小括号运算符。

20.1 举个例子

当我们自己实现的仿函数不继承STL里的类时就没有融入到STL里去,其实标准库中的 functors 都会有继承关系,虽然上面 myobj 和 less< int >() 实现的效果是一样,但 myobj 没有继承 STL 中的 binary_function或unary_function,就没有融入到STL中去,虽然上面执行没问题,但如果再执行某些操作,就会出现问题。因为它没有达到STL的全部要求。
20.2 为什么要继承(functors的可适配条件)

STL规定每个可适配的函数都应挑选上面两个其中的一个来继承,因为函数的适配器(Adapter)会向仿函数提问题。可适配的意思就是可以被修改以达成某种操作。
unary_function适合单操作数的情况,binary_function适合双操作数的情况。这两个类都没有成员变量和成员函数,所以理论上大小为0,但编译器会让它为1。当它们作为父类被继承时,给子类增加的大小就为0。

所以 less 继承 binary_function 后没有任何坏处,所增加的大小为0,而且有了 binary_function 里的三种数据类型,这三个数据类型可以回答适配器的问题。
所以当我们想要我们写的 functors 可以被修改,被适配就需要选择上面两种中合适的一种去继承。
总结: 仿函数就是一个类或结构体里面重载小括号,这样的类或结构体创建出来的对象就叫做函数对象或仿函数。在大大小小的算法中,我们为了搭配算法就会写出相应的仿函数出来。但如果我们没有去继承上面两种类的话,在未来就没有被改造的机会。如果我们想要我们写的 functors 能融入到STL的体系中去,就必须选择其中合适的一种去继承。