一面:20min
1 自我介绍
2 微服务架构
1 nacos作为配置中心,如果nacos服务失效了,各个服务之间的调用如何保持高可用呢?
答:nacos注册中心本地有缓存,所以请求来了还是能够正常提供一段时间的服务,这段时间足够让nacos恢复服务了
2 nacos除了本地缓存,还有没有其他机制保证nacos中心失效的情况下,服务调用的可用性?
答:一般各个服务本身使用到的rpc框架会有一个本地注册中心,内容是nacos注册中心的副本
3 业务有没有用过nacos作为配置中心,有哪些参数
答:https://chat.openai.com/share/7aa5938e-b03a-43e2-9283-9229382c64c3
4 nacos新增了一个参数,如何影响它的实例?
答:我其实对nacos的机制并不了解,但是无非就推或者拉,如果使用“推”的机制,则可以采用redis的发布订阅机制,各个服务先在nacos上注册通道,当后面nacos一旦更新了服务就主动推送消息给各个服务,另一种“拉”比较笨,各个实例定期轮询nacos服务是否准备好,但是不推荐,比较占用cpu时间。
3 实习
3.1 我提个建议啊,实习有主次之分的对吧,快手两个字不明显,可以加粗,加大号。
3.2 快手这一块儿做的是什么业务?
答:运维开发,主要是数据中心的接线配置和管理。基础平台开发的…
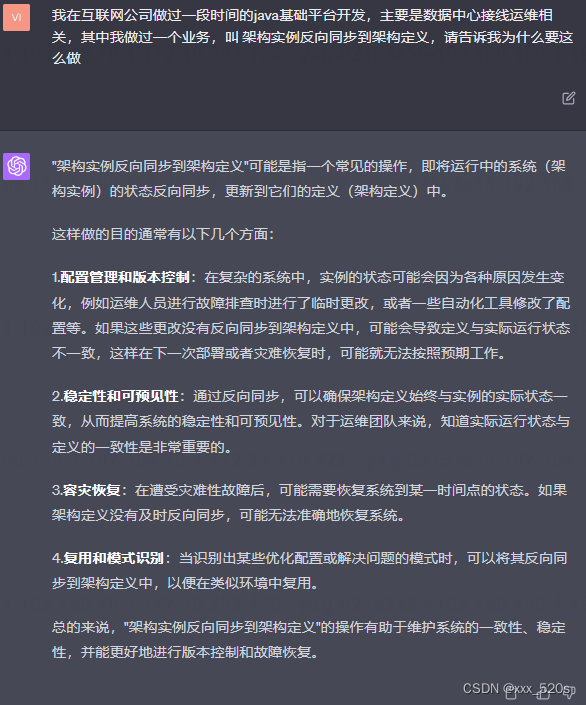
3.3 架构实例反向同步到架构定义这个业务看着还挺有意思的,讲一讲呗?业务需求,业务实现是怎么样的?
答:不得不说,gpt4考虑的比我周全
3.3.1 为什么要反向同步
3.3.2 涉及到哪几张表
archMain:架构表,表的字段包括
区块定义表(archBlock):树形结构表,数据中心组成的基本块,存在pod级别,leaf叶节点级别,
3.3.3 开发过程中难点
有两个难点,第一个是这种同步表有六个,每一个表要么是树形结构,要么是正常表结构,要么存在主子表结构,而且只同步表的部分字段,同时还有一部分特殊字段涉及到第三方的表,存在依赖关系,所以为了方便实现这个点,我首先分别为两张表对应的树形结构和主子表结构写了两个定制化的程序,然后再通过类型擦除和反射机制进行泛化,这样我们只需要在前端使用统一的访问格式就能实现针对所有表的通用的反向同步操作,这个格式定义了操作类型、表名、表结构、只需要比较的公共字段、涉及到第三方表的特殊字段以及待更新的子表字段。同时为了更加细粒度的增删改,还增加了一个id对儿字段,用于待比较或者待同步的树或者id记录。
另外一个是这个需求最难的地方:同步过程中涉及到树形表结构的同步,一般需要同一个架构下的所有记录是按照树形结构组织的,当实例架构同步到定义架构时,不仅仅是记录内容的复制,而且同一个架构下记录之间的父子关系也需要体现,尤其是涉及到第三方表字段的父子关系,这更加麻烦,为了处理父子关系,需要先将实例数据和定义数据提取出来然后按照架构名称建树,再根据实例树的路径匹配到定义树的对应路径,定义树中多余的路径需要删除,缺失的路径需要从实例树中同步,父子关系正确但是内容不一样的结点需要修改。
3.3.4
4 分布式键值对数据库
4.1 选举机制怎么设计的?正常选举的情况下以及异常时又怎么选举的
4.1.1 正常选举的情况下
Raft协议定义了三种角色:领导者(Leader)、跟随者(Follower)和候选人(Candidate)。在正常情况下,所有节点开始时都是跟随者。如果跟随者长时间(被设置为一个随机的时间,避免选举冲突)未收到领导者的心跳,它就会成为候选人并开始一次选举。
候选人会增加它的当前任期并投票给自己,然后向其他所有服务器发送请求投票的RPC。如果其他节点在这个任期内还没有投票,并且候选人的日志至少和它们一样新,那么它们就会给这个候选人投票。
如果候选人在选举的过程中收到了大多数节点(包括自己)的投票,那么它就会成为领导者。
4.1.2 异常选举的情况下
1 发生网络分区情况下重连
2 从节点宕机的情况下
3 多数节点宕机
4 leader节点宕机呢?
在异常情况下,比如领导者宕机或者网络分区,可能会触发新的选举。跟随者如果在超过选举超时时间的情况下还未收到领导者的心跳,就会变成候选人并开始新一轮的选举,这和正常选举的情况相同。
在网络分区的情况下,如果一个分区中没有领导者,那么这个分区中的节点会尝试选举新的领导者。然而,由于分区中的节点数可能少于集群节点的半数,因此它们无法获得足够的票数来选举出新的领导者。这就阻止了在分区期间系统状态的变更,保证了系统的强一致性。
另外,如果一个领导者在短暂的网络延迟或者宕机后恢复,但在此期间已经有新的领导者被选举出来,那么原先的领导者会在试图附加日志时收到更高任期号的拒绝响应,这时它会立即变回跟随者状态。
4.2 服务宕机的时候持久化非常关键, 是怎么做的?
4.2.1 raft集群的持久化
需要持久化哪些字段以及原因。
1 为什么要持久化VotedFor字段?
在Raft协议中,VotedFor字段记录了一个节点在当前任期内投票给了哪个候选者。这个字段需要持久化的原因主要是为了在单个任期内保持一致性,并防止一个节点在同一任期内为多个候选者投票。
当一个节点变为候选者并开始新的任期,它会给自己投票,并请求其他节点的选票。如果一个节点已经为这个任期内的其他候选者投过票(VotedFor字段非空),或者它的日志不够新,那么它就会拒绝这个请求。一旦节点投票给了某个候选者,它就会将VotedFor更新为那个候选者,并将其持久化。
假设VotedFor字段没有被持久化,那么如果一个节点在给某个候选者投票后崩溃,并在同一任期内重启,那么它就可能忘记它已经投过票,并可能再次为其他候选者投票,这违背了Raft协议的设计。因此,我们需要持久化VotedFor字段,以防止一个节点在同一任期内为多个候选者投票,保证了选举的正确性。
2 为什么需要持久化节点的任期号?
例子:假设我们有一个三节点的Raft集群,节点A、B和C,它们的任期号都是5,节点A是当前的领导者。现在发生了一次网络分区,节点A被隔离开来。
在A被隔离的情况下,节点B和C没有收到A的心跳,于是它们增加了任期号到6,并进行了选举。在这个选举中,节点B被选为新的领导者。
然后,节点B开始接受新的客户端请求,修改了系统的状态,这些新的日志条目的任期号是6。
接下来,假设节点A因为某种原因(例如,操作系统崩溃)重启了,但它没有持久化任期号,所以在重启后,它的任期号被重置为0。然后,A尝试发起新的选举,将自己的任期号增加到1,并将选举请求发送给B和C。
在这个情况下,如果B和C只是简单地比较自己的任期号和接收到的请求中的任期号,那么它们会发现自己的任期号更大,所以它们会拒绝A的选举请求。
然而,如果B和C没有正确地持久化任期号,它们可能会在接收到A的选举请求后错误地更新自己的任期号为1,并投票给A,这将导致A成为新的领导者,然后A可能会尝试复制一些过时的或者错误的日志条目给B和C,导致系统状态的不一致。
这就是为什么我们需要持久化任期号的一个例子。通过持久化任期号,我们可以保证在节点重启后,任期号不会被错误地重置,避免了上述问题的发生。
3 为什么要持久化日志?
答:方便根据日志恢复到崩溃前的状态
4.2.2 上层状态机的持久化
一般而言,如果raft系统没有实现快照机制则不需要持久化,但是如果有快照,则快照的数据也需要持久化,一般快照包含kv数据库以及确保接口幂等性的序列map,以上也只是单机部署的情况下持久化的参数,如果在分片的kv数据库中,持久化的数据还包括来配置中心的配置
5 反问
1 并发量怎么样?
用户有三五十万吧
2 怎么处理这些高并发呢?
有好几级缓存,本地缓存什么的,不是所有的项目都会使用redis的吗
3 评价
你的能力和你的简历基本上是匹配的,大多都能讲出来,你做的麻省的项目还是不错的,如果有时间我还是想深入问的。
4 闲谈:
劝进我搞网安(我原来的专业就是网安),大谈特谈网安就业的前景,认为是一个风口
5 redis和824键值对数据库的异同。
二面
6 手写的mini-spring框架
6.1 你是怎么实现注解的,比如注解怎么被spring解析的
1.类路径扫描
:Spring首先会扫描所有的类路径,寻找有特定注解的类。
2.解析注解
:当Spring发现一个类有@Component等注解时,它会解析这个类并创建一个相应的BeanDefinition。
这个BeanDefinition对象存储一个bean的原始信息,包括类型类,@Scope,@Lazy注解标注的单例,懒加载等信息
6.2 这个spring是基于spring实现的吗?
答:自己写的
6.3 比如我现在用你这个框架,引用你的架包,这个架包里的类可以做到自动注册到容器吗?怎么做
答:先自己先建一个@Component注解和@Bean注解类,然后新建一个叫做X的类,使用@Component标记它,内部再建立一返回对象为引用架包的某一个类对象的方法并且用@Bean标记它,这样我在扫描到@Bean的时候就知道这个方法的返回对也是一个需要托管的Bean对象,然后就会去库中搜索相应的类再加载到bean容器中。
6.4 或者我换一种问法,架包中的类你怎么扫描?
对于如何扫描架包中的类,这跟扫描你自己应用中的类是一样的。当Spring启动时,它会根据你在配置中指定的base-package,扫描所有的类路径,包括你的应用和所有的引用的架包。Spring不区分这个类是在哪里定义的,只要这个类在类路径中,就会被Spring扫描。
这就是为什么你可以在你的应用中使用Spring Boot Starter或其他第三方库中的类,只要这个类有@Component等注解,Spring就会自动处理这个类,并将其添加到ApplicationContext中。
demo:
假设你有一个名为 external-lib 的外部架包,这个架包里有一个带有@Component注解的类叫 ExternalClass,如下:
// 在external-lib架包中
package com.example.external;
import org.springframework.stereotype.Component;
@Component
public class ExternalClass {
public void sayHello() {
System.out.println("Hello from ExternalClass");
}
}
然后,你想在你的应用中使用 ExternalClass。首先,你需要在你的 pom.xml 或 build.gradle 中引入这个架包。
接下来,你需要在你的Spring Boot应用的主类或者一个配置类上添加 @ComponentScan 注解来指定要扫描的包路径。你应该包含你自己的应用和 external-lib 包的路径,如下所示:
package com.example.myapp;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@ComponentScan(basePackages = {"com.example.myapp", "com.example.external"})
public class MyApp {
public static void main(String[] args) {
SpringApplication.run(MyApp.class, args);
}
}
在这个例子中,Spring会在启动时扫描com.example.myapp和com.example.external包路径,这样就会发现并处理 ExternalClass 类。
然后,你可以在你的应用中使用 ExternalClass,如下:
package com.example.myapp;
import com.example.external.ExternalClass;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class MyClass {
private final ExternalClass externalClass;
@Autowired
public MyClass(ExternalClass externalClass) {
this.externalClass = externalClass;
}
public void doSomething() {
externalClass.sayHello();
}
}
在这个例子中,MyClass 类通过构造函数注入的方式使用了 ExternalClass。当你调用 doSomething 方法时,就会打印出 “Hello from ExternalClass”。
6.5 为什么使用三级缓存?
首先我解释一下,三级缓存肯定能解决循环依赖问题的,其实一级缓存也能解决这个问题,即使这个是带AOP的循环依赖例子…
6.6 一级和三级的区别在哪儿?
使用三级缓存主要是为了解耦合spring创建bean的生命周期的三个阶段,刚刚创建完但还没有属性填充和初始化的实例放入三级缓存,属性填充完但没有初始化完成的bean放入二级缓存,初始化的bean放入对应一级缓存,第三级缓存的目的是为了方便创建代理类,二级缓存主要是为了保证单例吧。
6.7 如果是一级的话你是怎么实现的?
大概就是代理类提前创建,在刚刚new一个实例的时候判断是否需要创建代理类,然后就把它放入到一级缓存中,到后面初始化的时候再从一级缓存中取出这个实例或者代理对象就行。
以对象A和B形成的带AOP循环依赖为例:大概讲解了一下一级缓存的创建流程。大概就是这个一级缓存存储了多种状态的对象,有可能是代理对象,也有可能是原始对象。
6.8 jdk和cglib的代理区别是什么?
从应用场景,原理以及具体的实现上讲了一下,可以参考下面这个文章:
6.9 为什么jdk只能为有接口的实现类做代理?
因为jdk本身就是一个被代理对象的接口的实现类,如果没有实现类,就无法形成代理:https://www.cnblogs.com/tuyang1129/p/12878549.html
7 线程池
7.1 java的线程池有没有用过?比如现在有一个任务等待线程池处理,线程池会怎么处理这个任务呢?
答:线程池相关建议看这篇面经,https://www.zhihu.com/question/295692815/answer/2247491537
7.2 在异步任务的情况下,怎么获取异步任务的返回值?
在Java中,你可以使用java.util.concurrent.Future接口来表示一个异步计算的结果。当你启动一个异步任务时,你会得到一个Future对象,你可以用这个Future对象来获取异步任务的结果。
如果你使用Spring框架来执行异步任务,你可以使用@Async注解来标记一个方法为异步方法。当这个方法被调用时,Spring会在一个新的线程中执行这个方法。如果这个方法有返回值,Spring会自动将这个返回值包装成Future对象。
以下是一个简单的例子:
@Service
public class AsyncService {
@Async
public Future<String> asyncMethodWithReturnType() {
System.out.println("Execute method asynchronously - "
+ Thread.currentThread().getName());
try {
Thread.sleep(5000);
return new AsyncResult<String>("hello world !!!!");
} catch (InterruptedException e) {
//
}
return null;
}
}
在这个例子中,asyncMethodWithReturnType方法是一个异步方法,它会在一个新的线程中执行,并在5秒后返回一个字符串。由于这个方法是异步的,所以它的返回值被自动包装成Future对象。
然后,你可以在其他地方调用这个方法并获取它的返回值:
@Service
public class AnotherService {
@Autowired
private AsyncService asyncService;
public void doSomething() {
Future<String> future = asyncService.asyncMethodWithReturnType();
try {
String result = future.get(); // this will block until the async task completes
System.out.println(result);
} catch (InterruptedException | ExecutionException e) {
// handle exception
}
}
}
在这个例子中,doSomething方法调用了异步方法并得到一个Future对象,然后它调用Future.get方法来获取异步任务的结果。需要注意的是,Future.get方法是阻塞的,如果异步任务还没有完成,它会阻塞等待直到异步任务完成。
如果你不想阻塞等待,你也可以调用Future.isDone方法来检查异步任务是否已经完成。
7.3 一个分布式系统中,向一个服务器获取订单服务,另一个服务器获取商品服务,两个请求多线程的方式发出(异步),如何获得这两个异步任务的返回值,然后需要合并结果再返回给前端。
7.3.1 我自己的解决方案:
是的,你可以使用一个共享的数据结构来存储多个异步任务的结果。这种方法通常适用于任务数量未知或者任务结果需要被多个线程共享的情况。
例如,你可以使用一个线程安全的集合,如ConcurrentHashMap,来存储异步任务的结果。你可以在每个异步任务完成时,将其结果添加到集合中。然后,其他线程可以从这个集合中获取所有任务的结果。
这是一个简单的例子:
@Service
public class MyService {
@Autowired
private OrderService orderService;
@Autowired
private ProductService productService;
private final ConcurrentHashMap<String, Object> resultMap = new ConcurrentHashMap<>();
public void doSomething() {
// 启动异步任务获取订单数据
CompletableFuture<Void> orderFuture = orderService.getOrderAsync().thenAcceptAsync(order -> {
resultMap.put("order", order);
});
// 启动异步任务获取商品数据
CompletableFuture<Void> productFuture = productService.getProductAsync().thenAcceptAsync(product -> {
resultMap.put("product", product);
});
// 使用allOf方法等待所有异步任务完成
CompletableFuture<Void> allFutures = CompletableFuture.allOf(orderFuture, productFuture);
// 当所有异步任务完成时,获取结果
allFutures.thenAcceptAsync(v -> {
Order order = (Order) resultMap.get("order");
Product product = (Product) resultMap.get("product");
// 在这里使用订单数据和商品数据
System.out.println("Order: " + order);
System.out.println("Product: " + product);
});
}
}
在这个例子中,我们使用了一个ConcurrentHashMap来存储订单和商品数据。每当一个异步任务完成,我们就将它的结果添加到这个集合中。然后,当所有的异步任务都完成后,我们就可以从这个集合中获取所有的结果。
这种方法的优点是简单且灵活,你可以在任何地方访问这个集合并获取异步任务的结果。但是,这种方法也有一些缺点,例如,你需要手动管理这个集合,而且你需要确保在获取结果之前所有的异步任务都已经完成,否则你可能会得到不完整的结果。另外,使用ConcurrentHashMap可能会导致内存浪费,特别是当任务数量非常大时。
所以,尽管使用共享数据结构可以在一些情况下获取异步任务的结果,但是在大多数情况下,使用Future或CompletableFuture可能是更好的选择,因为它们提供了更强大和灵活的功能来处理异步任务和它们的结果。
7.3.2 gpt4给的标准答案
在一个分布式系统中,对于异步任务的处理,可以采用CompletableFuture,它是Future的增强版本,提供了更加强大的功能,包括链式操作,合并多个Future结果等。
假设你有两个服务,一个是OrderService,一个是ProductService,它们都提供了异步方法来获取数据,你可以使用CompletableFuture来同时调用这两个服务并获取结果。
这是一个简单的例子:
@Service
public class MyService {
@Autowired
private OrderService orderService;
@Autowired
private ProductService productService;
public void doSomething() {
// 启动异步任务获取订单数据
CompletableFuture<Order> orderFuture = orderService.getOrderAsync();
// 启动异步任务获取商品数据
CompletableFuture<Product> productFuture = productService.getProductAsync();
// 使用allOf方法等待所有异步任务完成
CompletableFuture<Void> allFutures = CompletableFuture.allOf(orderFuture, productFuture);
// 当所有异步任务完成时,获取结果
allFutures.thenAcceptAsync(v -> {
try {
Order order = orderFuture.get();
Product product = productFuture.get();
// 你可以在这里使用订单数据和商品数据
// ...
} catch (InterruptedException | ExecutionException e) {
// handle exception
}
});
}
}
在这个例子中,getOrderAsync和getProductAsync方法是异步的,它们返回CompletableFuture对象。我们使用CompletableFuture.allOf方法来等待所有的异步任务完成,然后在所有的异步任务完成后,我们获取并使用订单数据和商品数据。
这个例子中使用的thenAcceptAsync方法是非阻塞的,它会在一个新的线程中执行。这意味着doSomething方法不会等待异步任务完成,它会立即返回。当所有的异步任务完成时,thenAcceptAsync中的代码会被执行。
请注意,你需要在你的服务中实现getOrderAsync和getProductAsync方法,并让它们返回CompletableFuture对象。你可以使用CompletableFuture.supplyAsync方法来启动一个新的异步任务并返回CompletableFuture对象。
8 设计模式
8.1 java怎么实现单例?
我先讲了spring的单例吧,
8.2 这其实是一种应用层上的单例应用,讲讲语言层面上的实现(双检锁没答上来…)
双检锁机制的单例实现,推荐看这篇文章:https://www.runoob.com/design-pattern/singleton-pattern.html
8.3 假设通过反射的方式能不能创建这个对象
能
8.4 如果现在不想让别人通过反射机制去恶意创建这个对象,因为我要保证他是单例的,办?
8.4.1 首先我们需要知道:
不论是使用new关键字,还是newInstance()方法,以及Class.getDeclaredConstructor().newInstance(),他们都是最终通过构造方法来创建类的实例的。
- 使用
new关键字直接调用类的构造器,这是最常见的创建实例的方式。 - newInstance()
方法属于Java的反射机制。当你有一个类的Class对象,你可以使用newInstance()方法来创建这个类的实例。这种方式主要用于在运行时动态创建对象,而且你不需要知道具体的类名。但在Java 9中,Class.newInstance方法已被废弃,建议使用Class.getDeclaredConstructor().newInstance()替代。 - Class.getDeclaredConstructor().newInstance()
也属于反射机制,与newInstance()相比,这种方式更加强大,它可以创建私有构造方法的类的实例,也可以传递参数到构造器中。
但要注意的是,这三种方法都会调用类的构造器来创建新的对象。因此,如果类的构造器是私有的,那么只能在类的内部创建新的对象。但是,通过反射,我们可以突破这一限制,调用私有构造器来创建对象,这就是为什么在实现单例模式时,我们需要对反射创建对象的情况做额外的处理。
8.4.2 所以我们可以通过构造方法来预防别人通过反射恶意创建多例对象
使用反射可以绕过单例模式的私有构造函数,创建多个单例类的实例。但是,我们可以在单例类的构造函数中添加一些检查逻辑,以防止通过反射创建多个实例。
以下是一个例子:
public class Singleton {
private static volatile Singleton singleton;
private static boolean initialized = false;
private Singleton() {
synchronized (Singleton.class) {
if (!initialized) {
initialized = !initialized;
} else {
throw new RuntimeException("Singleton already initialized, cannot create another instance");
}
}
}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
在这个例子中,我们添加了一个静态布尔型变量 initialized,用于记录 Singleton 是否已经被初始化。在 Singleton 的构造函数中,我们检查 initialized 的值。如果 Singleton 已经被初始化,那么我们就抛出一个异常,防止创建新的 Singleton 实例。如果 Singleton 还没有被初始化,那么我们就设置 initialized 为 true。
这样,即使通过反射调用 Singleton 的构造函数,也无法创建多个 Singleton 实例。但是,这种方法有一个缺点,那就是只有在尝试创建第二个 Singleton 实例时,才会抛出异常。也就是说,这种方法无法防止创建第一个 Singleton 实例,但是可以防止创建多个实例。
9 快排
9.1 怎么快排
首先会找到一个枢轴,然后将小于枢轴的元素往左挪,大于的往右移,然后再将这个枢轴元素放入最终的空位中,到下一轮可以在枢轴的两侧递归刚才这个移动行为。
9.2 就第一轮而言,左右两边分别给一个指针,你会怎么移?
首先将第一个元素存起来,然后开始移动右边的指针,当发现一个元素比tmp小,则和左边的指针交换,同时左边指针会加1,然后再遍历一下左边的指针,当发现元素比tmp大,则和右边的指针对应元素交换。
10 kv分片数据库
10.1 什么维度做的分片?
我大概介绍一下了整个分片数据库的架构,整个kv数据库有一个配置中心,所有的重新分片的命令都是它来下发给各个分片复制组的,
各个复制组收到配置后要做的第一件事情就是对比新旧配置,然后给准备迁移分片或者接收分片数据,无论是收到分片还是接收分片,接收到后写入数据库的过程是要通过日志的方式下发到raft集群来保证一致性的。在迁移期间,整个复制组的leader节点还是能够正常接收用户请求,只不过这个时候每次接收一个请求,就会查看一次最新取到的配置,当发现用户请求的数据所在分片在新配置中不归自己管时,就会返回一个ErrorWrongGroup的指令给客户端,客户端收到后就会去配置中心加载配置,并且重定位到新的复制组,如果分片还没迁移过来,那么返回客户端一个ErrorNotArrived的指令,客户端会重试直到拿到数据,
10.2 有没有持久化策略,比如重启之后?
答:我们是采用延迟持久化,有两个维度的持久化,
第一个维度是下层的raft节点本身的持久化,即每次碰到关键字段比如任期号,投票号以及日志变更时就立即进行一次持久化,
第二个维度涉及到快照机制,如果没有快照机制,则状态机的数据不需要持久化,但是如果有快照机制,则快照制作完之后也会下发给raft集群,raft集群本身会对快照进行持久化。快照的内容一般是键值对数据库,还有它的用于保证请求幂等性的序列map。
11 反问
11.1 你们公司主要是提供金融信息数据的对吗
答:给券商提供一个终端,这个终端展示的是券商所需要的各种信息
11.2 安全性和性能哪个更重要一些呢?
答:早期cpp,但是后来发展的一部分业务不涉及到强安全性,比如说新闻展示之类,采用的就是java最方便。