文章目录
- 前言
- 0x1 常见编码
- 0x01 编码
- 0x02 ASCII码
- 0x03 Base系列编码
- 0x04其他编码
- - URL编码
- -莫尔斯电码(Morse Code)
- -HTML实体编码
- -其他中的其他...
- 0x05编码与加密的关系
- 古典密码
- 凯撒密码
- 简单替换密码
- 维吉尼亚密码
- 栅栏密码
- 其他古典密码
- 替换加密
- 移位加密
前言
学习笔记撒;总结一下;
0x1 常见编码
0x01 编码
编码是信息按照预定的规则从一种形式或格式转换为另一种形式的过程;
例如:
- 文本文件通过ASCII编码的形式存储在计算机中
- HTTP协议通过Base64编码传输二进制数据
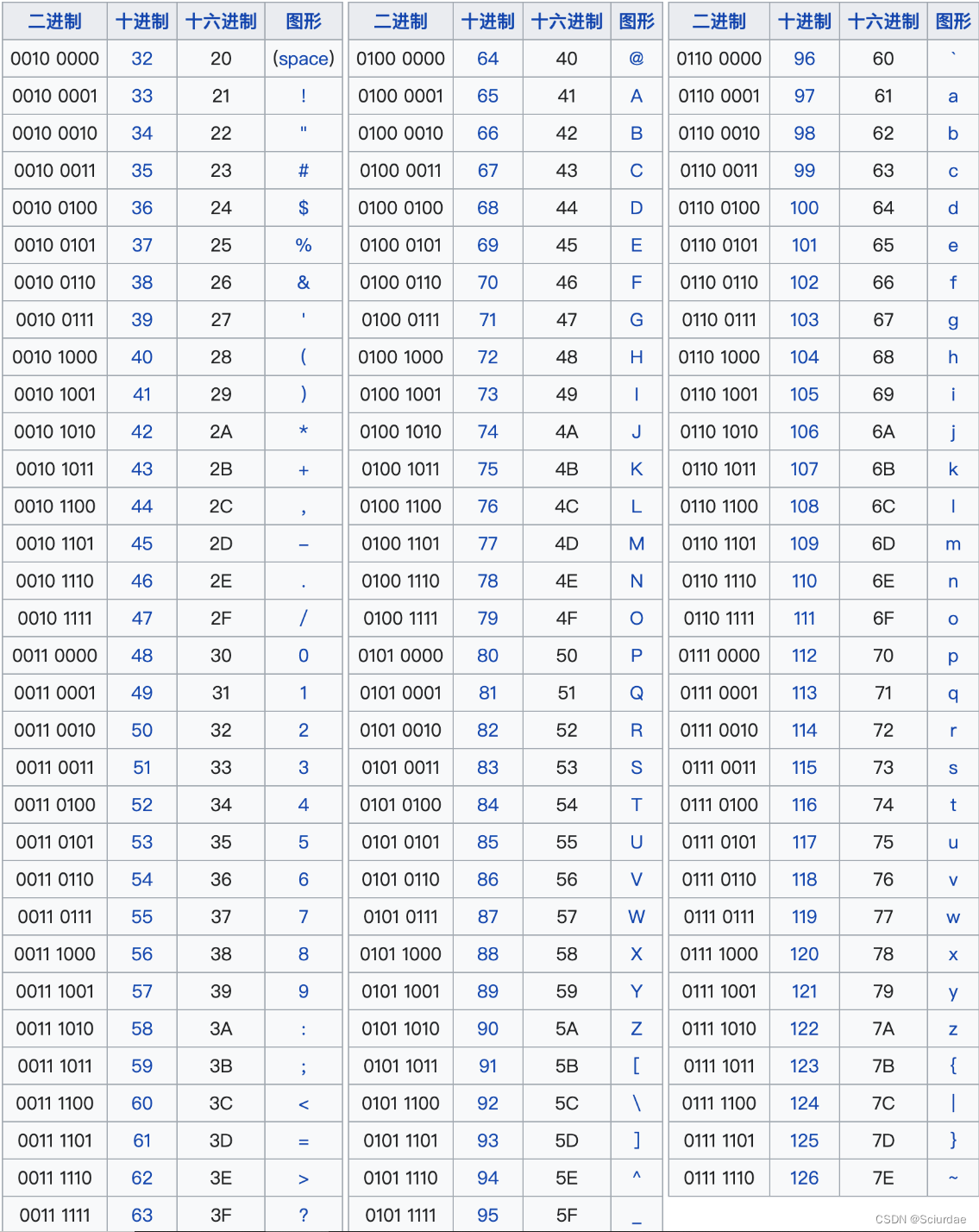
0x02 ASCII码
简述:
ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,是最通用的信息交换标准;
三个部分:
- 不可打印的控制字符(0 ~ 31)
- 可打印的字符(32 ~ 127)
- 扩展ASCII字符(128 ~ 255)
标准的ASCII码表:
0x03 Base系列编码
这个之前总结过了~
看一看呗 Base系列编码详解
0x04其他编码
- URL编码
简述:
url编码又叫百分号编码,是统一资源定位(URL)编码方式。URL地址(常说网址)规定了常用地数字,字母可以直接使用,另外一批作为特殊用户字符也可以直接用(/,:@等),剩下的其它所有字符必须通过%xx编码处理。
**特征:**编码前面都有%
例子:
(Hel10 Crypto!)
编码后’
%EF%BC%88Hel10%20Crypto%EF%BC%81%EF%BC%89
在线网站:
站长工具URL编码解码
-莫尔斯电码(Morse Code)
简述:
摩尔斯电码(英语:Morse code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。
摩尔斯电码主要由以下5种它的代码组成:
- 点(.)
- 划(-)
- 每个字符间短的停顿(通常用空格表示停顿)
- 每个词之间中等的停顿(通常用 / 划分)
- 以及句子之间长的停顿
基础拉丁字母表:

数字表:

其余还有标点符号希腊字母一系列编码表,查看
在线编码:莫斯电码
-HTML实体编码
字符实体是用一个编号写入HTML代码中来代替一个字符,在使用浏览器访问网页时会将这个编号解析还原为字符以供阅读。

在线网站:实体编码互转
-其他中的其他…
- Quoted-printable编码
- XXencode编码
- UUencode编码
- 敲击码
- ……
CTF中常见编码
0x05编码与加密的关系
在密码学中,经常提及编码和加密这个术语,大部分人会混用编码和加密,但是,编码不是加密!
通俗来说:编码的目的是转换格式,并不是为了让你读不懂,而加密是对数据进行隐藏和保护,让你识别不了明文。
所以,要说base编码而不是base加密。
古典密码
凯撒密码
简述:
凯撒密码是一种移位密码,通过把字母移动一定的位数来实现加密和解密。明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。
例如,当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推X将变成A,Y变成B,Z变成C。由此可见,位数就是凯撒密码加密和解密的密钥。
例如:
明文字母表:ABCDEFGHIJKLMNOPQRSTUVWXYZ
密文字母表:DEFGHIJKLMNOPQRSTUVWXYZABC
解密:
- 暴力破解法
因为凯撒密码位数的范围是0~25(偏移0和偏移26一样),最终的情况并不多,可以用python写个脚本将所有情况罗列出来,找到密文即可
def caesar_decrypt(ciphertext, shift):
decrypted_text = ""
for char in ciphertext:
if char.isalpha():
is_upper = char.isupper()
char = char.lower()
decrypted_char = chr(((ord(char) - ord('a') - shift) % 26) + ord('a'))
if is_upper:
decrypted_char = decrypted_char.upper()
decrypted_text += decrypted_char
else:
decrypted_text += char
return decrypted_text
def caesar_brute_force(ciphertext):
for shift in range(1, 26):
decrypted_text = caesar_decrypt(ciphertext, shift)
print(f"Shift {shift}: {decrypted_text}")
if __name__ == "__main__":
ciphertext = "Your encrypted text goes here" # 你的密文在这里替换
caesar_brute_force(ciphertext)
- 字频分析法
明文加密后得到密文,并不会改变每个字母的出现频率,因此可是通过计算出现在明文和密文中出现最多的俩个字母,计算其偏移,即是位数(密钥)。
在线网站:凯撒密码加密/解密
简单替换密码
简述:
简单替换密码(Simple Substitution Cipher)加密时,将每个明文字母替换为与之唯一对应且不同的字母。它与恺撒密码之间的区别是其密码字母表的字母不是简单的移位,而是完全是混乱的,这也使得其破解难度要高于凯撒密码。
例如:
明文字母 : abcdefghijklmnopqrstuvwxyz
密钥字母 : phqgiumeaylnofdxjkrcvstzwb
a 对应 p,d 对应 h,以此类推;
明文:the quick brown fox jumps over the lazy dog
密文:cei jvaql hkdtf udz yvoxr dsik cei npbw gdm
解密:
因为加密的密钥个数是 26!26!个,所以基本不可能用暴力破解,一般采用字频分析法。
- 字频分析法:
- 第一步要先统计字母频率:对密文进行字母频率分析。计算每个字母在密文中出现的次数。
- 确定常用字母:找出在所使用的语言中最常见的字母。英语中,E是最常用的字母
- 根据字母频率猜测有可能的替代关系,例如字频最高的字母可能对应最常见的字母E
- 初步解密,根据猜想初步解出一部分密文
- 根据语言特性或者单词,进一步猜测替代关系
- 慢慢修正猜想,直到整个密文都被解密,验证一下猜想;
在线网站: 字频分析
维吉尼亚密码
简述:
维吉尼亚密码(又译维热纳尔密码)是使用一系列凯撒密码组成密码字母表的加密算法,属于多表密码的一种简单形式。
维吉尼亚密码以其简单易用而著称,同时初学者通常难以破解,因而又被称为“不可破译的密码”(法语:le chiffre indéchiffrable)。这也让很多人使用维吉尼亚密码来加密的目的就是为了将其破解。
“第一次遇到维吉尼亚密码题目就叫做le chiffre indéchiffrable,hhhh”
加密过程:
在一个凯撒密码中,字母表中的每一字母都会作一定的偏移,例如偏移量为3时,A就转换为了D、B转换为了E……而维吉尼亚密码则是由一些偏移量不同的凯撒密码组成。
为了生成密码,需要使用表格法。这一表格包括了26行字母表,每一行都由前一行向左偏移一位得到。具体使用哪一行字母表进行编译是基于密钥进行的,在过程中会不断地变换。
例如,假设明文为:
ATTACKATDAWN
如果关键词为LEMON,先将其填充到明文同等长度,得到密钥
LEMONLEMONLE
对于明文的第一个字母A,对应密钥的第一个字母L,于是使用表格中L行字母表进行加密,得到密文第一个字母L。类似地,明文第二个字母为T,在表格中使用对应的E行进行加密,得到密文第二个字母X。以此类推,可以得到:
明文:ATTACKATDAWN
密钥:LEMONLEMONLE
密文:LXFOPVEFRNHR
解密的过程则与加密相反。例如:根据密钥第一个字母L所对应的L行字母表,发现密文第一个字母L位于A列,因而明文第一个字母为A。密钥第二个字母E对应E行字母表,而密文第二个字母X位于此行T列,因而明文第二个字母为T。以此类推便可得到明文。

用数字0-25代替字母A-Z,维吉尼亚密码的加密文法可以写成同余的形式:
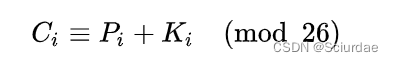
解密方法则能写成:

解密:
关于维吉尼亚的密码解密,一般都是以字母频率为基础的,但不是直接的字频分析;有三个著名的试验可以破译维吉尼亚密码;
- 卡西斯基试验
- 弗里德曼试验
- 柯克霍夫方法
感兴趣的可以自行查阅;(其实是博主也还学,就学了点爆破;以后学了有空再总结)
这里介绍一下,如果维吉尼亚密码的key较短,可以采用爆破的方式得到明文。
因为英文字母一共26个,如果key长度为1,那就只有26种情况;key长度为2,有325种;到长度5有六万多种;再长一些就很难爆破了,可以用来解密一些简单的题目;
爆破脚本:
def vigenere_decrypt(ciphertext, key):
decrypted_text = ""
key_length = len(key)
key_index = 0
for char in ciphertext:
if char.isalpha():
is_upper = char.isupper()
char = char.lower()
key_char = key[key_index % key_length].lower()
shift = (ord(char) - ord(key_char)) % 26
decrypted_char = chr((ord(char) - shift) % 26 + ord('a'))
if is_upper:
decrypted_char = decrypted_char.upper()
decrypted_text += decrypted_char
key_index += 1
else:
decrypted_text += char
return decrypted_text
def vigenere_brute_force(ciphertext, max_key_length):
for key_length in range(1, max_key_length + 1):
for key in itertools.product("abcdefghijklmnopqrstuvwxyz", repeat=key_length):
key = "".join(key)
decrypted_text = vigenere_decrypt(ciphertext, key)
print(f"Key: {key}\nDecrypted Text: {decrypted_text}\n")
if __name__ == "__main__":
import itertools
ciphertext = "Your encrypted text goes here" # 你的密文在这里替换
max_key_length = 5 # 设置密钥的最大长度
vigenere_brute_force(ciphertext, max_key_length)
栅栏密码
简述:
所谓栅栏密码,就是把要加密的明文分成N个一组,然后把每组的第1个字连起来,形成一段无规律的话。 不过栅栏密码本身有一个潜规则,就是组成栅栏的字母一般不会太多。(一般不超过30个,也就是一、两句话)。
-
传统栅栏密码
传统栅栏密码的密钥是密文长度的因数。
如密文长度为n,加密密钥为x,则有n%x==0。且解密密钥即为n/x。
'''
遍历所有可能的栏数,并得到加/解密结果
'''
s = 'KYsd3js2E{a2jda}'
factors = [fac for fac in range(2, len(s)) if len(s)%fac == 0] #取得密文长度的所有因数
for fac in factors:
flag = ''
for i in range(fac): #按一定的步长取几组字符,并连接起来,这里组数就等于步长数
flag += s[i::fac]
print(str(fac)+'栏:'+flag)

-
W型栅栏密码
W型栅栏密码是栅栏密码的变种,
将明文按w型排列,然后将每一行的字母依次连起来组成密文,行数就是密钥。
解密则同样画出这个w型图案,将每一列的字母依次连接起来组成明文。
W型栅栏密码的密钥不只是密文长度的因数,任何小于密文长度大于1的整数都有可能。
'''
若知道栏数,则使用decode解密,若不知道,则使用crack_cipher遍历所有可能性
'''
def generate_w(string, n):
'''将字符排列成w型'''
array = [['.']*len(string) for i in range(n)] #生成初始矩阵
row = 0
upflag = False
for col in range(len(string)): #在矩阵上按w型画出string
array[row][col] = string[col]
if row == n-1:
upflag = True
if row == 0:
upflag = False
if upflag:
row -= 1
else:
row += 1
return array
def encode(string, n):
'''加密'''
array = generate_w(string, n)
msg = []
for row in range(n): #将每行的字符连起来
for col in range(len(string)):
if array[row][col] != '.':
msg.append(array[row][col])
return array, msg
def decode(string, n):
'''解密'''
array = generate_w(string, n)
sub = 0
for row in range(n): #将w型字符按行的顺序依次替换为string
for col in range(len(string)):
if array[row][col] != '.':
array[row][col] = string[sub]
sub += 1
msg = []
for col in range(len(string)): #以列的顺序依次连接各字符
for row in range(n):
if array[row][col] != '.':
msg.append(array[row][col])
return array, msg
def crack_cipher(string):
'''破解密码'''
for n in range(2,len(string)): #遍历所有可能的栏数
print(str(n)+'栏:'+''.join(decode(string, n)[1]))
if __name__ == "__main__":
string = "ccehgyaefnpeoobe{lcirg}epriec_ora_g"
n = 5 #栏数
#若不知道栏数,则遍历所有可能
# crack_cipher(string)
#若知道栏数
array,msg = decode(string, n)
# array,msg = encode(string, n)
for i in array: print(i)
print(''.join(msg))


其他古典密码
替换加密
1.ROT5/13/18/47
2.埃特巴什码(Atbash Cipher)
3.希尔密码(Hill Cipher)
…
移位加密
1.曲路密码(Curve Cipher)
2.列移位密码
…
在线网站:
http://www.atoolbox.net/Category.php?Id=27
http://www.hiencode.com/
文献来源:
https://zh.wikipedia.org/wiki/%E5%8F%A4%E5%85%B8%E5%AF%86%E7%A2%BC
https://www.cnblogs.com/lnjoy/p/railfence.html
https://ruoli-s.github.io/posts/a36c.html#toc-heading-3
https://zh.wikipedia.org