本文对LLM+推荐的结合范式进行了梳理和讨论,并尝试将LLM涌现的能力迁移应用在推荐系统之中,利用LLM的通用知识来辅助推荐,改善推荐效果和用户体验。
背景
电商推荐系统(Recommend System,RecSys)是一种基于用户历史行为和兴趣偏好的个性化系统,能够为用户提供精准、个性化的商品推荐,促进用户的购物体验和消费满意度。一个成熟的RecSys通常采用pipeline的级连结构,包括召回、粗排、精排、重排等各个模块,具有高度的专业领域特性。随着ChatGpt的爆火,大语言模型(LLM)开始在越来越多的领域崭露头角。LLM是一种基于深度学习的自然语言处理技术,能够从大规模的语料库中学习语言的规律和模式。当模型参数突破某个规模时,性能显著提升,LLM开始展现出涌现能力和泛化能力,庞大的参数中存储了大量通用的世界知识,同时具有语言理解和表达能力。
对比RecSys和LLM,前者是一个数据驱动的系统,依赖电商ID体系来建模用户或物品,缺乏语义和外部知识信息,存在信息茧房、冷启动、多样性不足、无法跨域推荐等问题;而后者缺乏推荐领域内的专有数据信息,不具备传统推荐模型的序列处理和记忆能力,同时计算复杂度高、训练和推理成本大。
一个自然的想法是:如何通过一种合适的范式,将LLM涌现的各种能力迁移应用在推荐系统之中,利用LLM大语言模型的通用知识来辅助推荐,改善推荐效果和用户体验。
技术交流群
建了技术交流群!想要进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

LLM与推荐的融合
目前业界有非常多关于LLM与推荐的探索,根据LLM与推荐系统的耦合强弱,概括起来有两种建模范式:
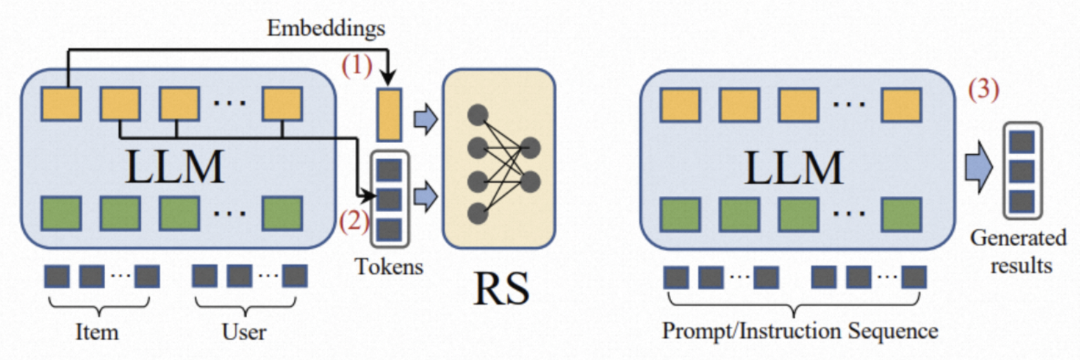
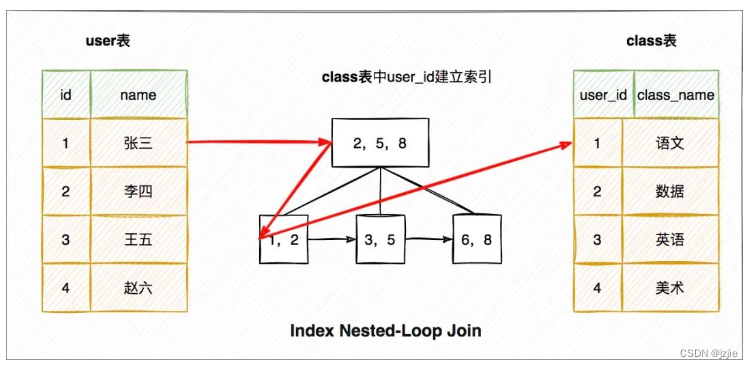
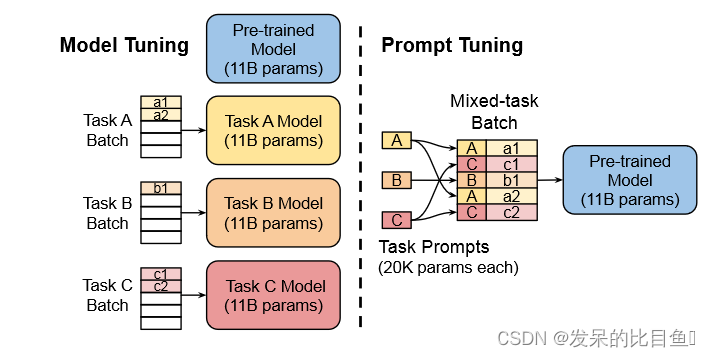
LLM和推荐的两种融合方式[1]:1. LLM+推荐(左) 2. LLM as 推荐(右)
▐ 方式1:LLM + 推荐
这种建模范式将语言模型视为特征提取器,将物品和用户的原始信息(比如商品的标题/属性/类目、用户的点击序列/上下文)设计成prompt,输入到LLM中并输出相应的embedding或者语义summary信息,后续作为特征或者通过语义挖掘用户潜在的兴趣偏好,最终被整合到推荐系统的决策过程中。
在传统推荐领域,往往使用不具有语义的数值ID来表征商品和文本信息,并采用稀疏one-hot来进行ID特征编码,而特征编码则被设计成一个简单的Embedding Look-up Table。即使是富含文本语义的特征(如商品的标题、属性)都被统一成了ID编码,产生了语义层面的信息损失。伴随着语言模型的兴起,一种直观的方式是采用语言模型作为编码器获取商品标题/属性等文本信息的嵌入表示,与推荐系统基于ID的one-hot编码模式结合起来。典型的工作包括:U-BERT[2]对用户评论内容进行编码来增强用户的个性化向量表征,最终得到稠密的embedding向量;UniSRec[3]通过对商品title/用户行为序列进行编码,来达成跨域序列推荐的目标。
此类工作使用LLM对商品/用户原始的语料信息进行概要总结,生成精简的语义表述,用于后续推荐模块使用,比如Liu[5]等人提出的一个基于LLM的生成式新闻推荐框架GENRE。通过将新闻标题、类别等数据构建成prompt提示,从而激发LLM基于其通用知识来生成如新闻摘要、个性化新闻等相关信息。这些生成信息,一方面用来迭代的优化LLM生成;另一方面用来训练新闻推荐模型,补充推荐模型的知识信息。

GENRE[5],一个基于LLM的生成式新闻推荐框架
GPT4Rec[6]将LLM模型用于用户意图理解,根据用户的行为历史,进行兴趣抽取并生成中间的语义query,用于后续的推荐召回。如下图所示,其主要分为两步:首先根据用户历史交互的商品和它们对应的标题,通过prompt格式化后,使用GPT2来生成可以表征用户多个兴趣的“search query”。然后将GPT2生成的query提供给搜索引擎,以检索要推荐的商品,从而提高推荐召回的相关性和多样性。
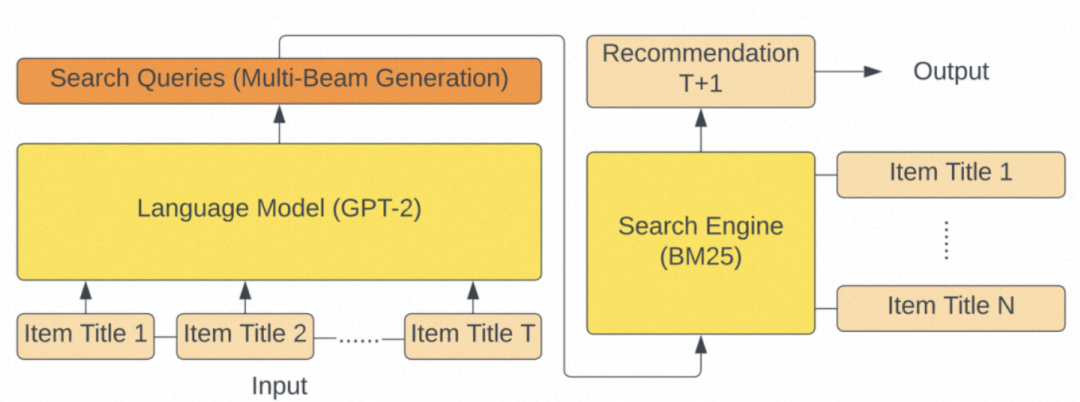
GPT4Rec:query生成+搜索引擎
▐ 方式2:LLM as 推荐
与融合方式1不同,这个范式的目标是直接将预训练的LLM转换为一个强大的推荐模型,用来替换推荐系统(召回->粗排->精排->重排)的一个或者全部模块。输入序列通常包括简介描述、行为提示和任务指示,输出就是最终的推荐结果。"LLM as 推荐"是一种非常理想的推荐范式,极其依赖于LLM模型强大的语言理解、逻辑推理和文本生成能力。
此类工作[7][8]将推荐问题形式化为给定条件的排序任务,其中用户的历史交互作为条件,推荐系统召回得到的商品作为候选。通过设计合适的prompt模版,结合条件、候选、排序指令,使得LLM为候选的商品进行打分或者排序。实验证明,LLM在Zero-Shot场景具有较好的零样本排序能力,但在排序时不可避免地有position bias和popularity bias问题。
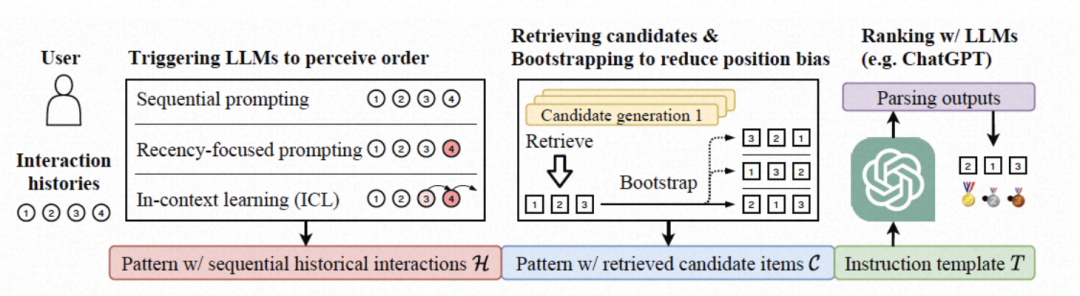
基于LLM的“零样本”排序方法[7]
以Chat-Rec[9]为例。Chat-Rec将LLM视作推荐系统的枢纽,通过prompt链接LLM和推荐各个模块,通过用户与LLM的多轮对话,不断缩小推荐候选范围,并最终给出精准的推荐结果和推荐理由。具体包括:将用户的行为足迹等转换为prompt,让LLM学习到用户偏好;然后进一步地将用户的推荐历史和推荐系统生成的候选集输入到LLM,让LLM执行过滤和排序,完成多轮推荐。
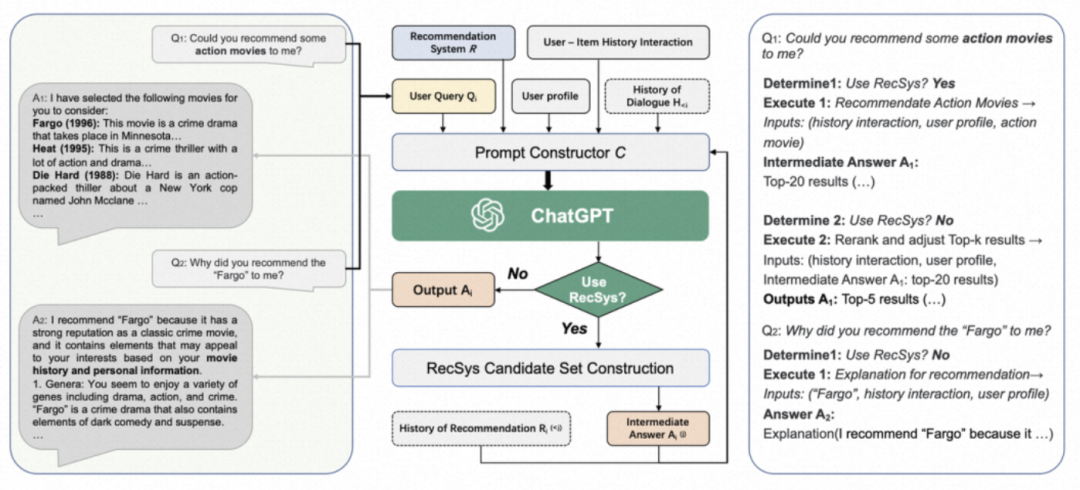
Chat-Rec:将LLM视作推荐系统的枢纽
算法方案
当前的LLM在精准性上和推荐模型相差甚远,同时受限于LLM模型极大的推理耗时,无法满足在线推荐系统毫秒级的时延限制,短期内不具备将LLM模型用于在线推理的条件。于是我们更多地采用"LLM + 推荐"的方式,去利用大模型的知识和推理能力,提高推荐模型对商品信息、上下文、用户行为序列的知识表达,包括:
-
借助LLM通用知识信息,构建类目搭配体系,引入推荐系统在推荐召回侧引入搭配I2I、排序侧进行类目兴趣扩展建模,提高推荐的多样性。
-
借助LLM文本推理能力,辅助商品/用户理解。我们使用LLM将电商Item冗余文本信息进行去噪提纯和改写;结合用户行为序列、上下文以及用户画像,进行用户行为sumarry总结。并通过预训练语言模型,将文本知识结果进行embedding向量化表征,与传统的推荐模型进行知识感知嵌入,提高模型的知识表达。
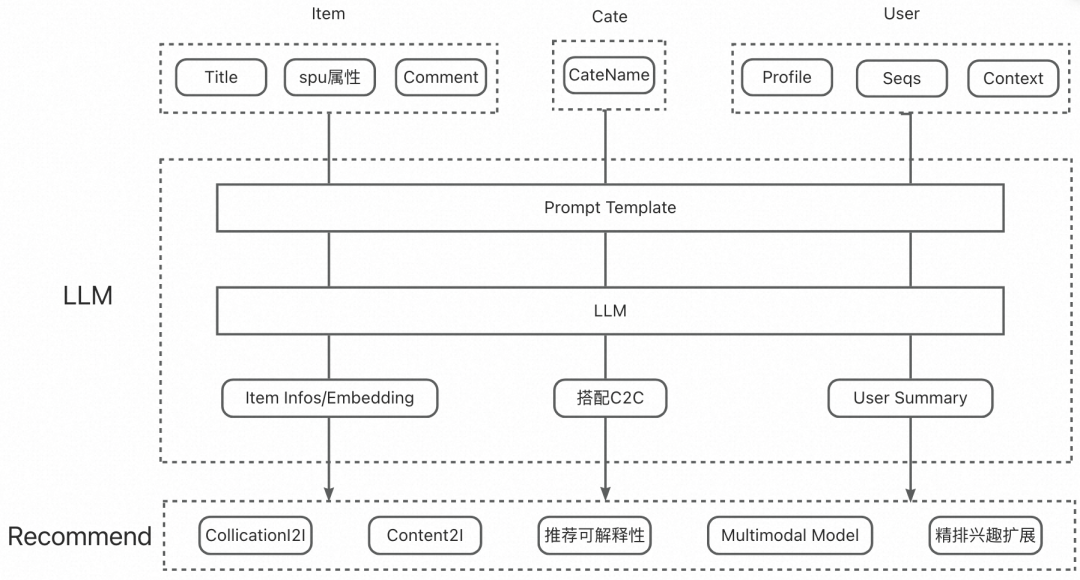
LLM在推荐的应用
▐ 基于LLM知识能力的类目搭配推荐
经过多年的沉淀,电商平台已经拥有了一套完整的类目体系。这套类目体系通常采用树状结构,通过层层拆解,最终将一个商品映射到一个末级类目,不同末级类目之间相对独立。现有的类目体系无法体现出这类目之间存在的搭配信息,缺乏跨类目的搭配关系表达。同时,相较于品牌和卖家,类目可以更加显式地与用户兴趣进行聚合和映射。在推荐场景之中,给用户准确地推荐相关商品的同时,如果能够挖掘不同兴趣之间的隐藏关系,基于搭配进行发散推荐,将给用户带来新的惊喜感、实现用户需求和兴趣的扩展。

类目体系:休闲裤和衬衫分别属于一级类目(男装)下面的不同二级类目,而男帆布鞋又挂载在另一个一级类目(流行男鞋)上。
传统的类目关系挖掘往往基于知识图谱,采用距离度量、聚类、行业规则、协同过滤等方法。这些工作大都需要繁杂的数据清洗、算法挖掘和行业专家知识。LLM大模型的出现,让快速、高效的电商知识构建变成了现实。
- LLM搭配类目
LLM搭配类目的整体生产链路如图所示,主要包括三个部分:1. 基于站内类目体系,设计prompt template;2. 批量调用LLM模型,请求LLM知识;3. 进行知识抽取和站内类目ID映射。
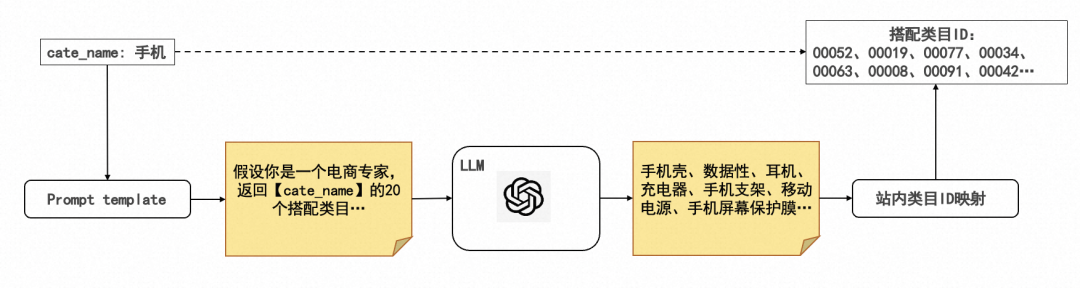
LLM搭配C2C的生产链路
prompt设计
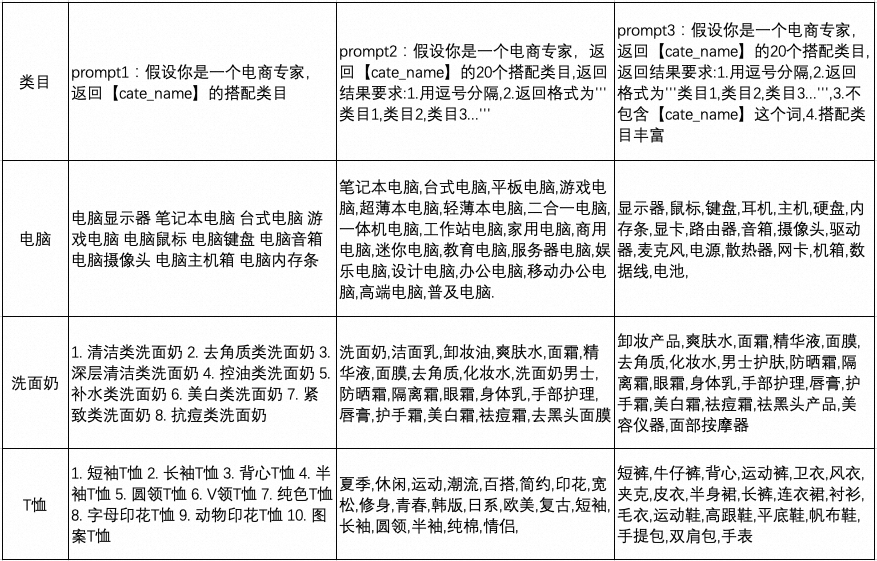
LLM的最终效果非常依赖prompt的设计,设计prompt技巧可以参考吴恩达的课程[10]。以下是我们针对“LLM返回搭配类目”这个问题尝试的几种prompt效果。可以看到,当添加:"1.用逗号分隔,2.返回格式为’‘‘类目1,类目2,类目3…’’',3.不包含【cate_name】这个词,4.搭配类目丰富"这些限制后,LLM返回结果具有不错的效果,搭配类目的多样性也基本上能够符合预期。
LLM模型选择
业界主流的开源LLM模型/服务如下。最终我们选择通义千问模型,进行搭配信息的获取。
-
LLaMA(Large Language Model Meta AI)[11]:由 Meta AI 发布的一个开放且高效的大型基础语言模型,其数据集来源都是公开数据集,无任何定制数据集。
-
ChatGlm6B[12]:一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM)架构,具有 62 亿参数。
-
通义千问:阿里云推出的一个中文LLM模型,功能包括多轮对话、文案创作、逻辑推理、多模态理解、多语言支持等。
-
百川13B:Baichuan-13B 是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。
-
chatgpt[13]:openAI基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的对话AI模型。
站内类目ID映射
由于LLM模型返回的是通用知识信息,存在与站内的类目体系无法完全对应的情况。为了便于后续推荐各个模块使用,兼容现有的电商推荐链路,我们进一步将LLM搭配类目映射成站内类目ID。站内类目ID映射可以采用以下两种方法:
-
基于文本相关性的向量召回。将LLM搭配类目和站内类目分别表征成文本embedding向量,然后通过向量召回的方式,选取与LLM搭配类目距离空间最近的top站内类目进行映射。
-
基于站内后验统计的query2cate映射。将搭配类目作为query,根据电商平台搜索query2cate的统计数据,使用该query下top的点击cate作为映射类目,实现LLM搭配到站内ID的映射。
我们尝试在排序中引入搭配信息,从序列建模的角度进行优化从而实现兴趣拓展。
序列扩展建模:推荐排序模型通常使用target-attention对用户行为序列进行建模,当序列商品与target商品相关性越大时,会被赋予更大的权重。为了更好的表达用户的类目兴趣,我们在CTR预估模型中新增了一个类目点击序列,同时通过近邻类目表征的方式,实现类目兴趣的扩展。具体地,我们在target和序列侧的sideInfo分别新加一个搭配类目emb来进行信息扩展,搭配类目emb计算规则为:
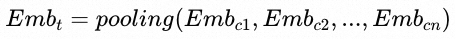
其中, 为target类目t的一个搭配类目。
为target类目t的一个搭配类目。
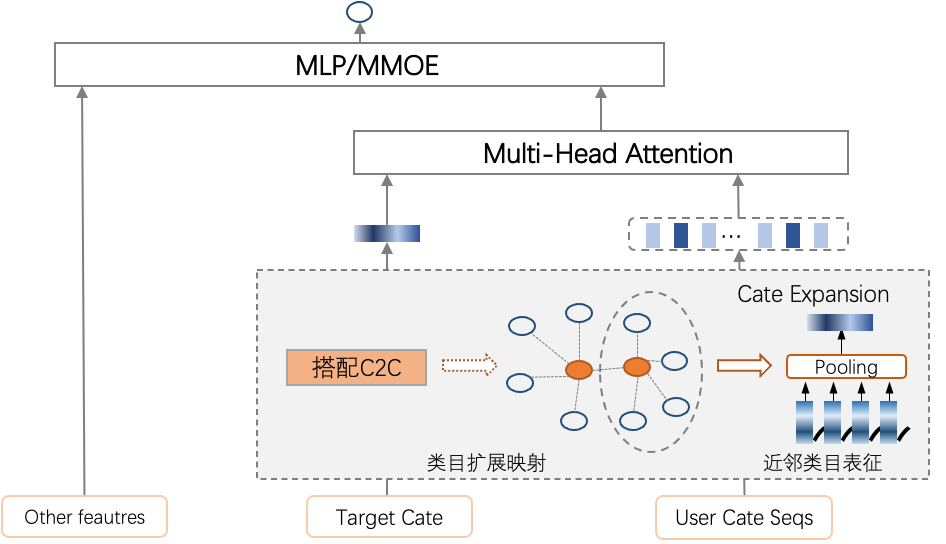
序列兴趣扩展
目前,基于LLM搭配类目的精排兴趣扩展模型已经在我们的推荐场景全量,ab效果:uctr+0.83%、人均ipv+2.58%、人均点击叶子类目数+2.06%。
▐ 基于LLM文本能力的商品语义表征
描述商品的文本信息主要包括title、类目以及CPV属性数据。对于商品类目以及属性信息,通常将其通过multi-hot的方式进行编码转化成特征向量。得益于成熟的规范化的商品类目体系,采用这种方式对商品类目信息进行编码是符合直觉的。但是由于商品种类复杂,不同商品的属性往往千差万别,采用mutli-hot形式对商品属性进行编码可拓展性不高,容易产生数据稀疏问题。
同时,商品标题是商品固有的内容类数据,其往往是对属性类特征的延伸。为了最大化商品搜索流量,商家在命名商品标题时通常会添加一些与商品本身无关的修饰词(比如“特价”、“爆款”等),同时也包含一些冗余的类目词。商品标题语义上并不连贯,信息凌乱,直接进行mutli-hot或者文本编码难以得到很好的嵌入表示。
一种可行的解决方案是将对商品零散的信息转换成语义连贯的文本,然后通过pre-train语言模型进行编码。对此,我们借助LLM蕴含的强大的语言表达能力和逻辑推理能力从商品标题中抽取出关键信息,从而实现对商品标题的正则化,得到语义连贯的文本描述,再对其进行编码,从而丰富商品的特征。
我们尝试使用LLM对商品标题进行正则化,并通过困惑度[14]衡量正则化后文本的语义连贯性。考虑到商品标题大多为相关词的组合,于是我们先将商品标题进行分词得到描述词列表,同时结合商品的属性列表,限制LLM选出关键词输出商品的简短描述。具体步骤如下图所示。
你现在是一个买家。给定商品的描述词【A】以及各种属性【B】,请根据关键词和关键属性描述出商品是什么。要求是只需要回答是什么,不要补充其他内容,尽量从A和B中选出词语进行描述,字数不超过40,回答模版为:这个商品是...。比如当A=['giyo', '公路', '山地车', '专用', '自行车', '单车', '专业', '骑行', '手套', '半指', '夏季', '男', '硅胶', '减震', '女'],B=['尺码': 'XXL', '类目': '自行车手套', '适用对象': '通用', '颜色分类': '弧光半指-黄色-双面透气+GEL硅胶+劲厚掌垫', '上市时间': '2016年夏季', '货号': '1183', '品牌': 'GIYO/集优', '款式': '半指手套'],输出:这个商品是GIYO牌的自行车半指手套。现在A=...,B=...
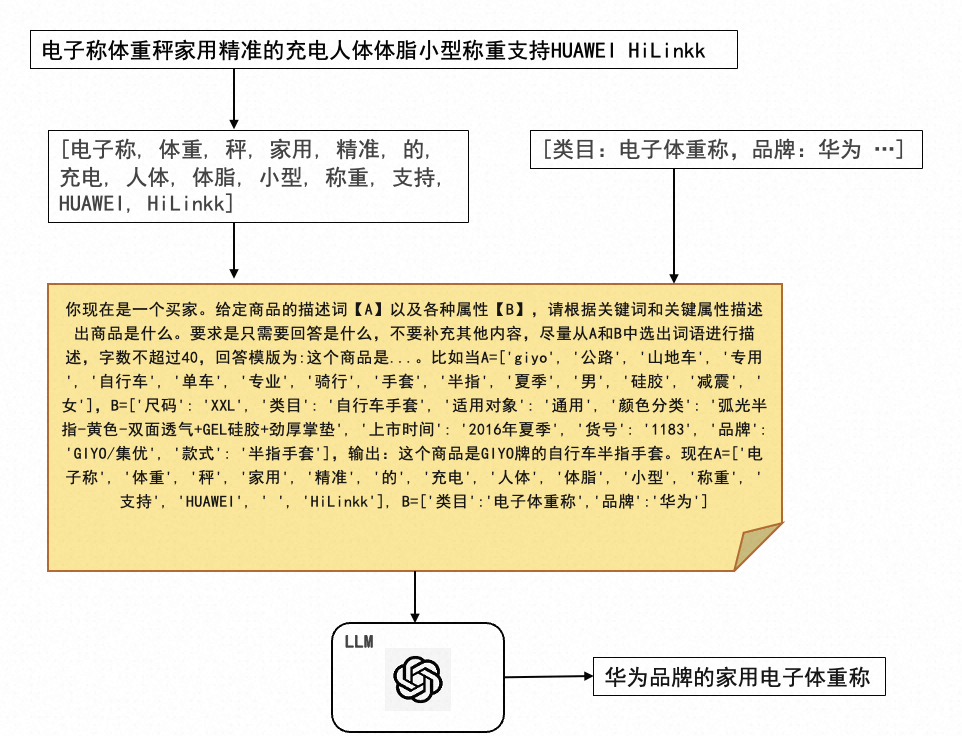
抽取部分样本结果如下表所示。
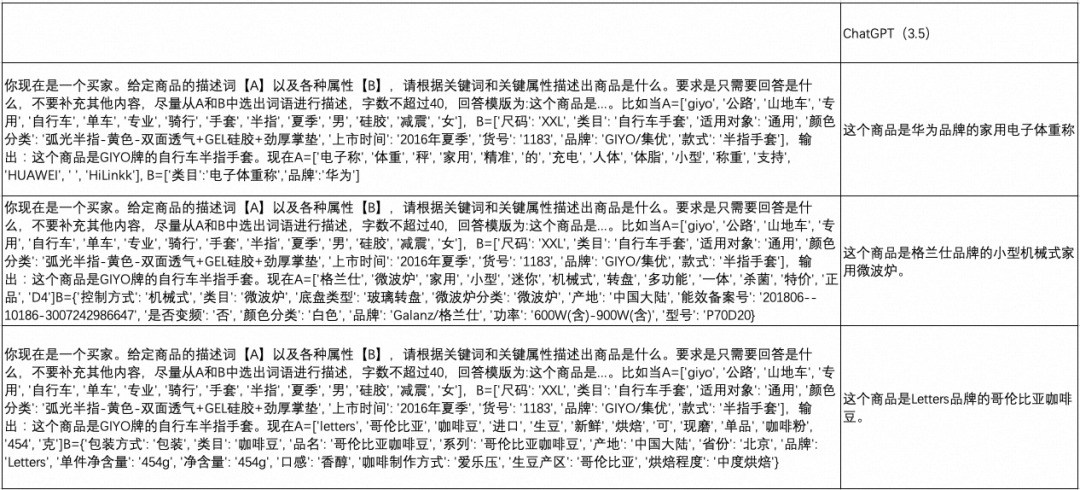
随机抽取100条样本统计平均困惑度,从下表可见,正则化后的商品描述文本困惑度显著下降,表明其语义程度比原始的商品标题更加连贯。

借助Modelscope的CoROM模型[15],我们对正则化后的商品标题文本进行了向量化抽取,并作为特征加入基于双塔结构的DSSM粗排模型中[16]。我们分别做了以下几个实验:
- 实验1:模型结构不变,用corom向量替换mind[17]向量对itemid做初始化(包含序列特征+item Tower特征),其他向量重新初始化。
- auc:0.73158 (-1pt)
- 实验2:模型结构不变,用corom向量替换mind向量对itemid做初始化(包含序列特征+item Tower特征),其他向量用base模型warmup。
- auc:0.73434 (-0.7pt)
- 实验3、模型结构不变,在item tower额外添加一个新特征corom向量,原所有向量用base模型warmup。
- auc:0.74233 (+0.064pt)
从实验结果中不难发现,用商品标题抽取的文本语义特征相比于用户行为学出来的ID类特征(mind向量)仍然处于劣势,但在mind基础上新增语义向量有着正向效果。因此,语义特征加入模型的较合理方式仍然是做为ID特征的补充而不是替换。此外,由于各种语言大模型中的embedding维度较高,加入模型需要占用大量的存储空间,因此embedding的降维也显得尤为重要,目前我们调研到的一种比较简单有效的降维方式是BERT-whitening[18],供大家参考。
总结展望
可以预见的是,随着LLM模型的发展和优化,LLM将从推荐系统的一种高效的辅助工具,逐渐成为推荐系统的一部分或作为推荐系统的骨干网络进行推荐内容的生成或排序。结合现阶段的LLM能力,我们将从以下几个方向继续探索:
-
多模态推荐:利用多模态LLM大模型的多模态信息抽取和表征能力,提取包括图片、文本、视频关键帧,视频语音文字等不同模态的语义化信息,并通过离线特征工程进行表征,使线上推荐模型能够真正完整地感知到各种电商模态信息,并实现对用户不同信息偏好和意图的理解。
-
LLM推理加速:现阶段LLM存在推理时延过高的问题,无法满足推荐系统数十ms级别的rt要求,我们的LLM探索也止步于离校特征编码阶段。后续考虑通过蒸馏、剪枝、量化等手段,用一个小模型蒸馏出LLM的部分能力,从而降低推理的复杂性,使其能线上serving。
-
LLM as 重排: 利用LLM丰富的知识领域扩展能力,在商品已有丰富的语义标签基础上,结合用户历史交互兴趣、选择偏好、序列生成规则 和 prompt template为用户从top排序集合中选取合适的商品或话题,生成推荐列表。
参考文献
[1] Hou, Yupeng, et al. “Large language models are zero-shot rankers for recommender systems.” arXiv preprint arXiv:2305.08845 (2023).
[2] Qiu, Z., Wu, X., Gao, J., & Fan, W. (2021). U-BERT: Pre-training User Representations for Improved Recommendation. Proceedings of the AAAI Conference on Artificial Intelligence, 35(5), 4320-4327. https://ojs.aaai.org/index.php/AAAI/article/view/16557
[3] Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards Universal Sequence Representation Learning for Recommender Systems. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '22). Association for Computing Machinery, New York, NY, USA, 585–593. https://doi.org/10.1145/3534678.3539381
[4]Dingkun Long, Qiong Gao, Kuan Zou, Guangwei Xu, Pengjun Xie, Ruijie Guo, Jian Xu, Guanjun Jiang, Luxi Xing, and Ping Yang. 2022. Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR '22). Association for Computing Machinery, New York, NY, USA, 3046–3056. https://doi.org/10.1145/3477495.3531736
[5] Liu, Q., Chen, N., Sakai, T., & Wu, X. (2023). A First Look at LLM-Powered Generative News Recommendation. ArXiv, abs/2305.06566.
[6] Li, J., Zhang, W., Wang, T., Xiong, G., Lu, A., & Medioni, G.G. (2023). GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation. ArXiv, abs/2304.03879.
[7] Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. Large Language Models are Zero-Shot Rankers for Recommender Systems. arXiv preprint arXiv:2305.08845, 2023.
[8] Dai, S., Shao, N., Zhao, H., Yu, W., Si, Z., Xu, C., Sun, Z., Zhang, X., & Xu, J. (2023). Uncovering ChatGPT’s Capabilities in Recommender Systems. ArXiv, abs/2305.02182.
[9] Gao, Y., Sheng, T., Xiang, Y., Xiong, Y., Wang, H., & Zhang, J. (2023). Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System. ArXiv, abs/2303.14524.
[10] https://github.com/datawhalechina/prompt-engineering-for-developers
[11] https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
[12] https://github.com/THUDM/ChatGLM-6B
[13] https://arxiv.org/pdf/2303.12712.pdf
[14] https://zhuanlan.zhihu.com/p/114432097
[15] https://www.modelscope.cn/models/damo/nlp_corom_sentence-embedding_chinese-base-ecom/summary
[16] https://www.microsoft.com/en-us/research/publication/learning-deep-structured-semantic-models-for-web-search-using-clickthrough-data/
[17] Li et al.(2019)]{2019arXiv190408030L} Li, C. and 9 colleagues 2019.\ Multi-Interest Network with Dynamic Routing for Recommendation at Tmall.\ arXiv e-prints. doi:10.48550/arXiv.1904.08030