2021-arXiv-The Power of Scale for Parameter-Efficient Prompt Tuning

Paper: https://arxiv.org/abs/2104.08691
Code: https://github.com/google-research/ text-to-text-transfer-transformer/ blob/main/released_checkpoints.md# lm-adapted-t511lm100k
在这项工作中,作者探索了“提示调整”,这是一种简单而有效的机制,用于学习“软提示”来调节冻结的语言模型以执行特定的下游任务。与 GPT-3 使用的离散文本提示不同,软提示是通过反向传播学习的,并且可以调整以合并来自任意数量的标记示例的信号。端到端学习方法大大优于 GPT-3 的小样本学习方法。更值得注意的是,通过使用 T5 对模型大小进行消融,表明Prompt Tuning在规模上变得更具竞争力:随着模型超过数十亿个参数,该的方法“缩小了差距”并匹配了模型调优的强大性能(其中所有模型权重都被进行了调整)。并且展示了使用软提示对冻结模型进行调节可以提高域迁移的鲁棒性,并实现高效的“提示集成”。
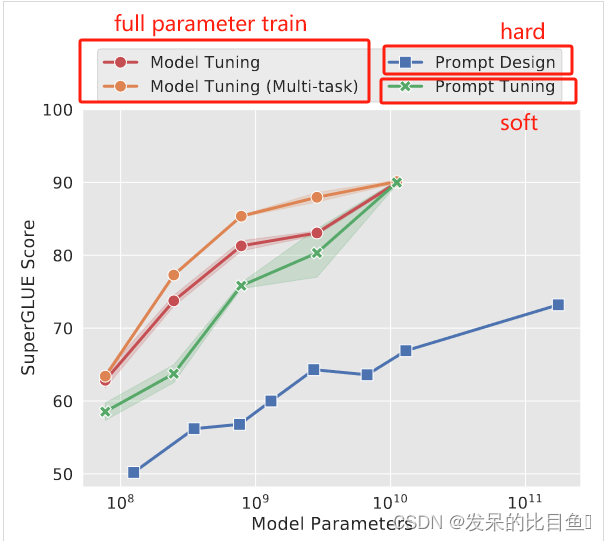
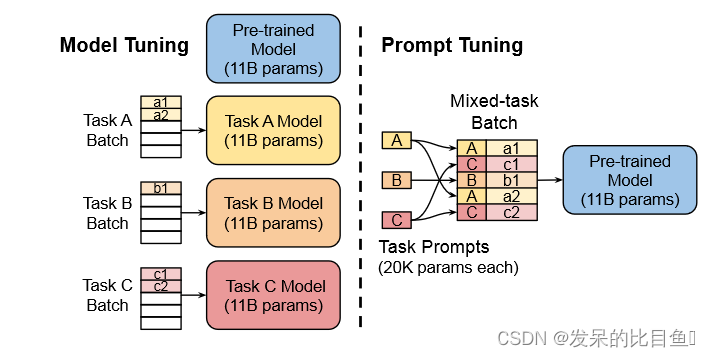
论文第一次证明仅提示调整(没有中间层前缀或特定于任务的输出层)足以与模型调整竞争的人。 通过实验证明语言模型能力是这些方法成功的关键因素。 如图 1 所示,**随着规模的扩大,即时调优变得更具竞争力。**如下图所示:T5 的标准模型调优实现了强大的性能,但需要为每个最终任务存储单独的模型副本。 随着大小的增加,T5 快速调整与模型调整的质量相匹配,同时能够为所有任务重用单个冻结模型。 该方法明显优于使用 GPT-3 的fewshot prompt 设计。
本文贡献:
1. 提出了快速调优,并在大型语言模型体系中展示了其与模型调优的竞争力。
2. 消融许多设计选择,显示质量和稳健性随着规模的增长而提高。
3. 在域转移问题上显示快速调优优于模型调优。
4. 提出“即兴合奏”并显示其有效性。
Prompt Tuning
Discrete prompt
Discrete prompt更多是通过先验知识来添加prompt,比如通过人类手工设计,将pretraining的只是和dowm stream的任务结合起来;另一种则是通过从trigger(触发) token的方法,这种方法假设所有的先验知识都存在于pretraining的模型之中,然后,设计某种trigger方法在下游任务中将prompt提取出来。
Soft/continuous prompts
Prompt Tuning 以 T5 为基础,将所有任务转化成文本生成任务,表示为 P r θ ( Y ∣ X ) Pr_{\theta}(Y|X) Prθ(Y∣X)。Prompt Tuning 在输入 X X X 前额外添加一系列特殊 tokens P P P,输入语言模型生成 Y Y Y,即 P r θ [ P ; X ] Pr_{\theta}[P;X] Prθ[P;X]。其中, θ \theta θ为预训练模型参数,在训练过程被固定, θ p \theta_p θp为 prompts 的专有参数,在训练过程被更新优化。通过将输入 X X X的 embedding 矩阵 X e X_e Xe与 prompts 的 embedding 矩阵进行拼接 [ P e , X e ] [P_e,X_e] [Pe,Xe]输入 T5 模型,最大化 Y Y Y的概率训练模型,但是只有 prompt 参数被更新。