一 怎么理解平均负载
① 如何查看平均复杂
查看'系统负载'的命令: top、'uptime'、w、'cat /proc/loadavg'、tload/proc/loadavg
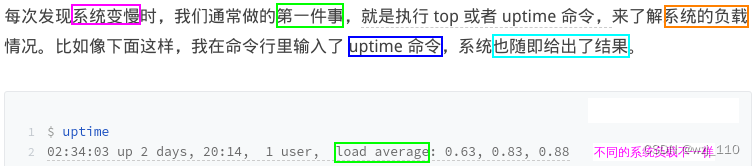

思考: uptime'每列'输出的'含义'?
重点: '当前时间'、'系统运行时间'、'正在登录用户数'、'平均负载'
②
![]()
思考:如何'观测'和'理解'这个最'常见'、也是'最重要'的'平均负载'系统指标?
思考: 'man uptime' 理解平均负载![]()
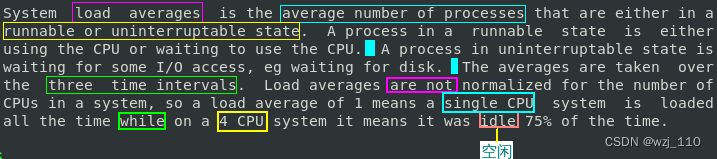
知识点: '可运行'状态和'不可中断'状态进程的理解![]()

linux 进程的六种状态
引入: '不可中断案例'讲解
备注: 不可中断状态实际上是'系统'对'进程和硬件设备'的一种'保护'机制
思考: 如何'更通俗'的理解'负载均衡'?
1、平均负载其实就是'平均活跃进程数'
2、直观上的理解就是'单位时间内的活跃进程数'
3、但它实际上是'活跃进程数'的'指数衰减'平均值
思考: '平均负载'和'cpu个数'关系?
绑核: 对于'特定进程或线程'需要绑定到'指定的核'上运行
③ 平均负载多少合理
有了'CPU 个数'.我们就可以判断出: 当平均负载比 CPU 个数还'大'的时候,系统已经出现了'过载'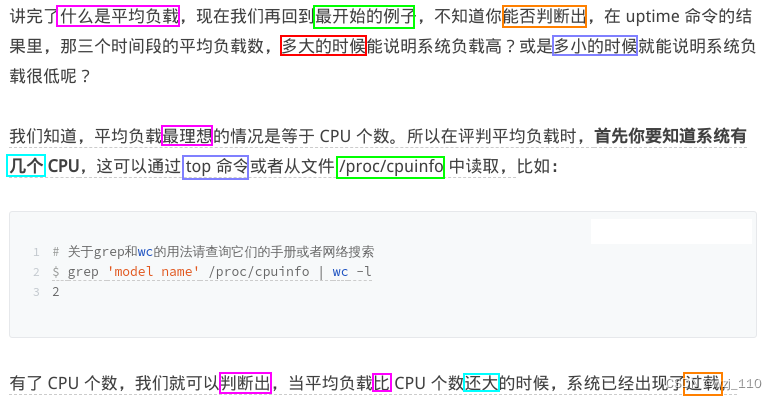
思考: 平均负载有'三'个数值,到底该参考'哪一个'呢?
核心: 分析系统负载的'趋势'


思考: 在'实际生产环境'中,平均负载'多高'时,需要我们'重点关注'呢?
④ 平均负载和CPU使用率关系

CPU密集型和I/O密集型区别
说明:云服务器涉及这'两种机型',CPU、内存、硬盘性能和容量不同.
⑤ 案例背景
1、我们以'三个示例'分别来看这'三种'情况
2、并用 'iostat、mpstat、pidstat' 等'工具',找出平均负载升高的'根源'
遗留: 后续会'开一个专题'讲解iostat、mpstat、pidstat的'综合'使用,这里暂时'局限'某一特性
测试'环境': 16 CPU、32GB 内存
运行'用户': 以 'root' 用户运行
stress stress各种测试
强调: 一定要'深入'了解 stress的各种参数含义,这样'压侧'的时候才能结合现象'判断'是否符合预期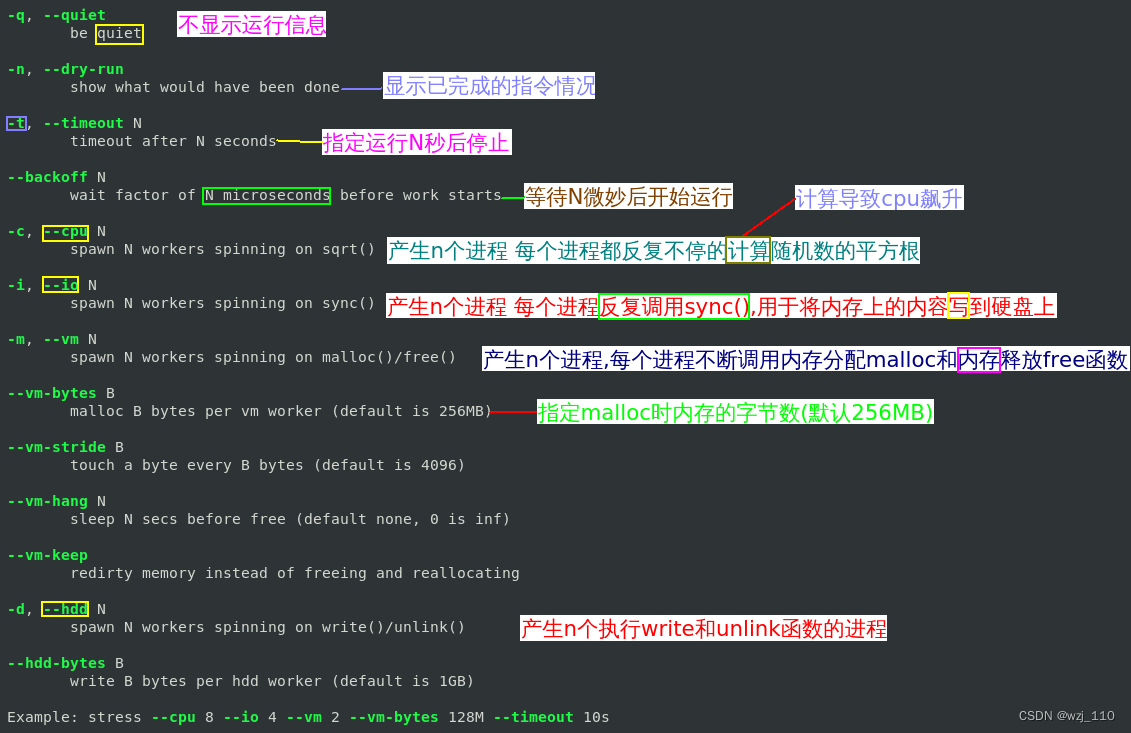
⑥ 模拟'CPU密集型进程
场景'一': stress '模拟' CPU '密集型' 进程
1、第一个'终端'运行 'stress' 命令,模拟一个 CPU 使用率 '100%' 的场景
目的: stress '测试cpu' 主要是在'用户态'将cpu'耗尽'
2、接着在'第二个终端'运行 uptime 查看平均负载的变化情况:
watch -n1 -d uptime
-d 参数表示'高亮'显示'变化'的区域
![]()
3、最后在'第三个终端'运行 mpstat 查看 CPU 使用率的'变化'情况:
mpstat -P ALL 5
-P ALL 表示'监控所有CPU',后面数字5表示'间隔5秒后'输出一组数据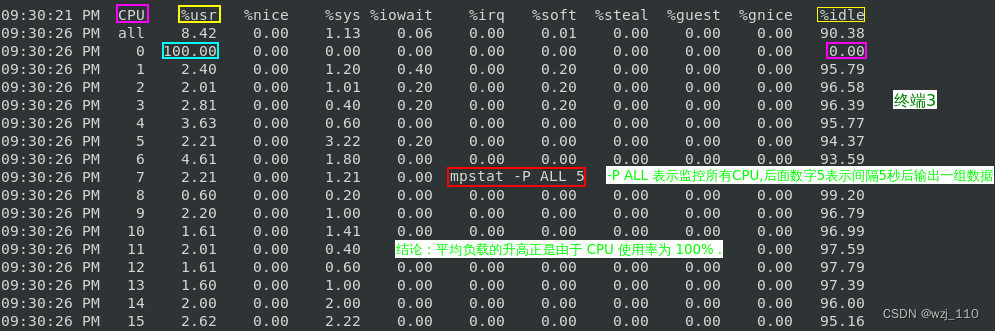
现象:正好有一个 CPU 的'使用率'为 100%,但它的 'iowait' 只有 '0'.
结论:说明'平均负载的升高'正是由于 'CPU使用率为 100%' 导致.
思考: 到底是'哪个进程'导致了 CPU 使用率为 '100%' 呢?
可以使用 'pidstat' 来查询:
pidstat -u 5 1
备注: -u表示'CPU指标',间隔'5秒后'输出一组数据pidstat命令详解
⑦ 模拟 I/O 密集型进程
友情提示: 做'下一个'实验之前把'上一个'实验复原
1、首先还是运行 'stress' 命令,但这次'模拟 I/O' 压力,即不停地执行 'sync':
stress -i 1 --timeout 600
补充: stress -i 1 --hdd 1 --timeout 600 可以实现'IO负载'的效果
2、在'第二个'终端运行 uptime 查看'平均负载'的'变化'情况:
watch -n 1-d uptime
3、然后'第三个'终端运行 'mpstat' 查看 'CPU 使用率'的变化情况:
显示'所有CPU'的指标,并在'间隔5秒'输出一组数据
mpstat -P ALL 5 1
现象:
1、其中'一个 CPU' 的系统 'CPU 使用率'升高到了 '63.39%'
2、而 iowait 高达 '21.47%'
结论: 这说明'平均负载的升高'是由于 'iowait 的升高'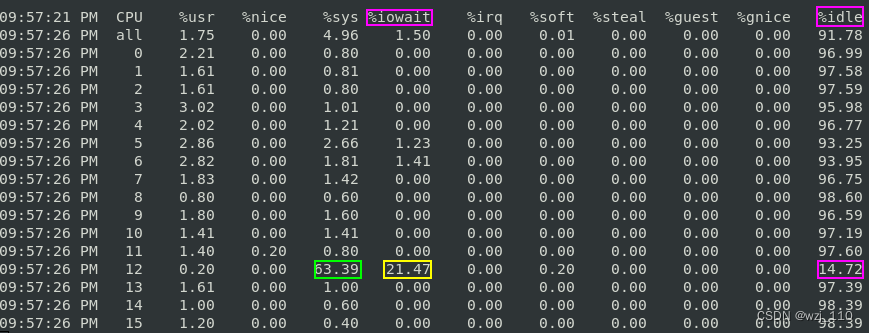
4、思考:到底是'哪个进程'导致 iowait 这么'高'呢?
# 间隔5秒后输出一组数据,-u表示CPU指标
pidstat -u 5 1 '或' iotop 观察
结论: 平均负载的升高是由于 'iowait 的升高',还是由于 'stress 进程'导致的
iowait 过高问题的查找及解决linux
⑧ 模拟大量进程的场景
铺垫: 当系统中'运行进程'超出 'CPU 运行能力'时,就会出现'等待 CPU' 的进程
即: 进程 '等待cpu 调度'的场景
1、这里我们'还是'使用 stress,但这次模拟的是 '64' 个进程:
stress -c 64 --timeout 600![]()
说明:
1)、由于系统有 '16 个CPU',明显比 '64个进程' 要'少'得多
2)、因而系统的 CPU 处于'严重过载'状态,平均负载高达'57.89'
2、接着再运行 'pidstat' 来看一下'进程的情况':
间隔'5秒后'输出'一组'数据:
pidstat -u 5 1源码安装升级sysstat包 1.11.5 sysstat包下载地址

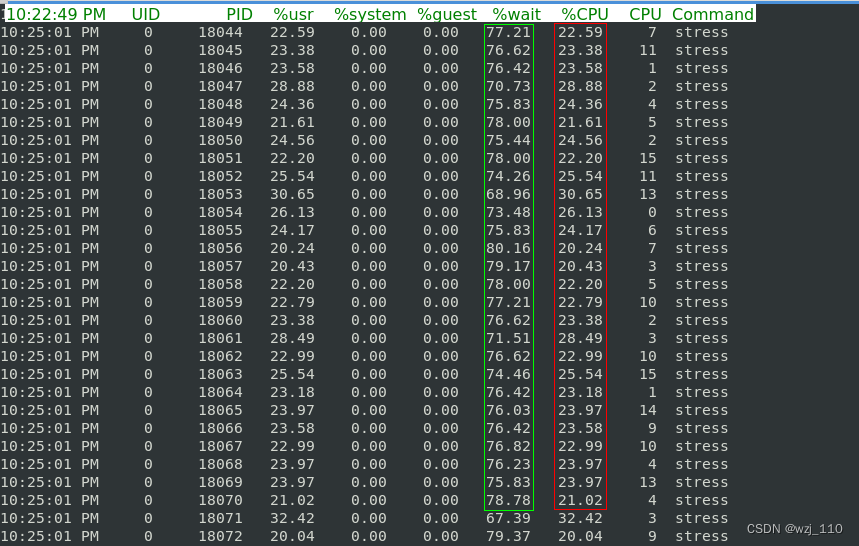
结论:
1、可以看出'64 个进程'在争抢 '16' 个 CPU
机制: 某一时刻只能某一个'进程'占用'CPU',这里相当于 '4' 个进程在争抢 '1' 个 CPU
2、每个进程'等待 CPU' 的时间 '也就是代码块中的 %wait 列' 高达 75%
3、这些'超出' CPU 计算能力的进程,最终导致 'CPU 过载'
遗留: 等待cpu进程为什么也'导致CPU利用率高'呢?
⑨ 平均负载小结

⑩ 补充
/proc/loadavg 平均负载

思考: 遇到客户反馈'慢'的情况,这个时候我们'怎么分析'呢?
说明: 刻意使用'htop'更清晰的查看'负载'
说明: 恰当的'比喻'
思考: 如何观察'线程级别'的工具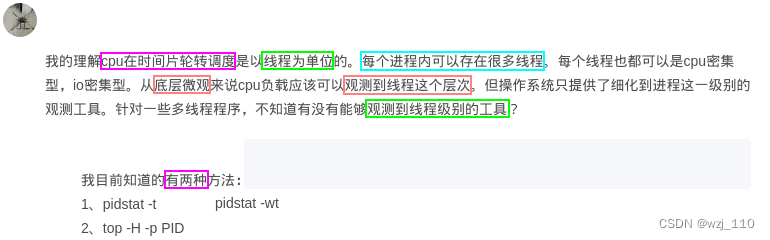
思考: ls命令为什么'无法'使用?
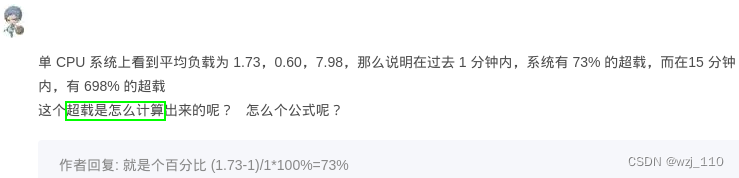
思考: '超载'如何计算?