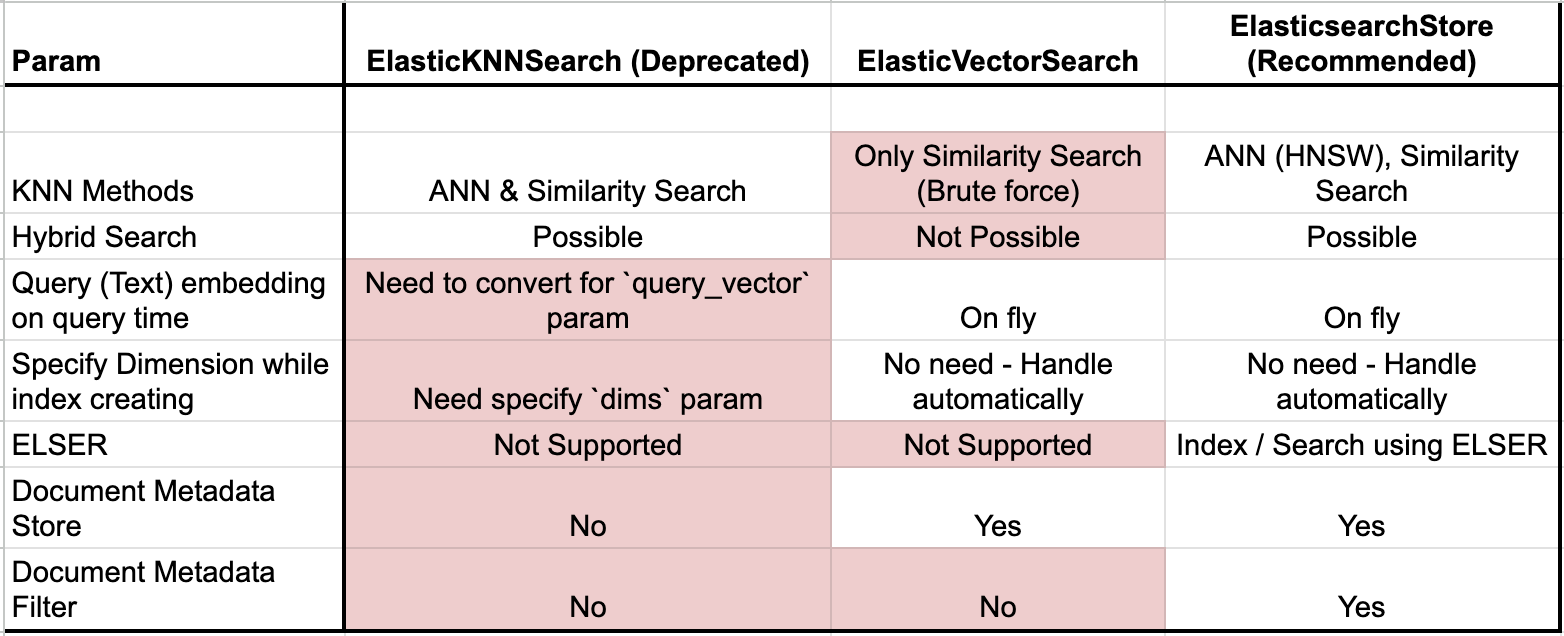
这是继之前文章:
-
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (一)
-
Elasticsearch:使用 Open AI 和 Langchain 的 RAG - Retrieval Augmented Generation (二)
的续篇。在今天的文章中,我将详述如何使用 ElasticsearchStore。这也是被推荐的使用方法。如果你还没有设置好自己的环境,请详细阅读第一篇文章。
创建应用并展示
安装包
#!pip3 install langchain导入包
from dotenv import load_dotenv
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticsearchStore
from langchain.text_splitter import CharacterTextSplitter
from urllib.request import urlopen
import os, json
load_dotenv()
openai_api_key=os.getenv('OPENAI_API_KEY')
elastic_user=os.getenv('ES_USER')
elastic_password=os.getenv('ES_PASSWORD')
elastic_endpoint=os.getenv("ES_ENDPOINT")
elastic_index_name='elasticsearch-store'添加文档并将文档分成段落
with open('workplace-docs.json') as f:
workplace_docs = json.load(f)
print(f"Successfully loaded {len(workplace_docs)} documents")
metadata = []
content = []
for doc in workplace_docs:
content.append(doc["content"])
metadata.append({
"name": doc["name"],
"summary": doc["summary"],
"rolePermissions":doc["rolePermissions"]
})
text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = text_splitter.create_documents(content, metadatas=metadata)
把数据写入到 Elasticsearch
from elasticsearch import Elasticsearch
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
connection = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
es = ElasticsearchStore.from_documents(
docs,
embedding = embeddings,
es_url = url,
es_connection = connection,
index_name = elastic_index_name,
es_user = elastic_user,
es_password = elastic_password)
展示结果
def showResults(output):
print("Total results: ", len(output))
for index in range(len(output)):
print(output[index])Similarity / Vector Search (Approximate KNN Search) - ApproxRetrievalStrategy()
query = "work from home policy"
result = es.similarity_search(query=query)
showResults(result)
Hybrid Search (Approximate KNN + Keyword Search) - ApproxRetrievalStrategy()
我们在 Kibana 的 Dev Tools 里打入如下的命令:
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
es = ElasticsearchStore(
es_url = url,
es_connection = connection,
es_user=elastic_user,
es_password=elastic_password,
embedding=embeddings,
index_name=elastic_index_name,
strategy=ElasticsearchStore.ApproxRetrievalStrategy(
hybrid=True
)
)
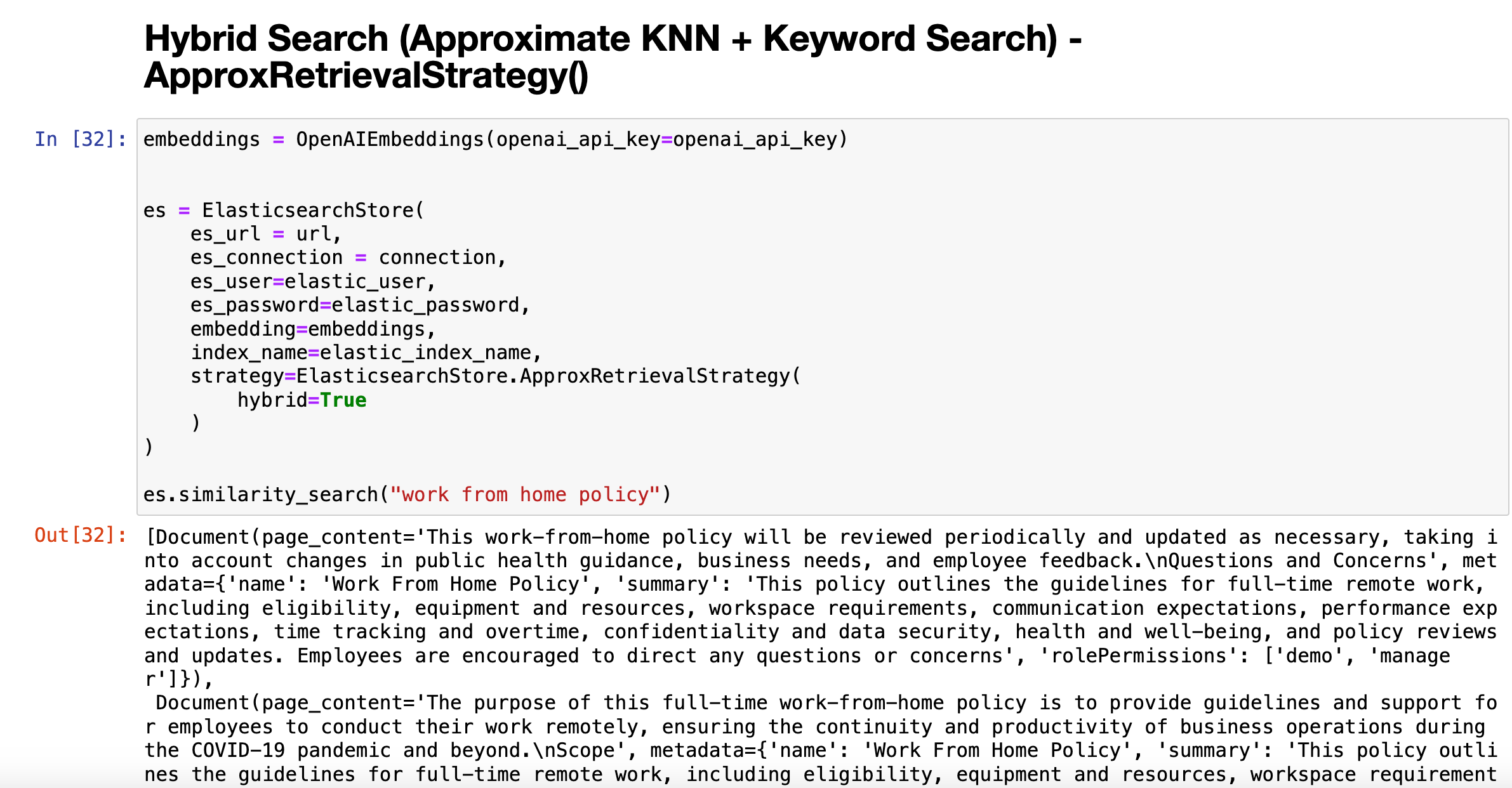
es.similarity_search("work from home policy")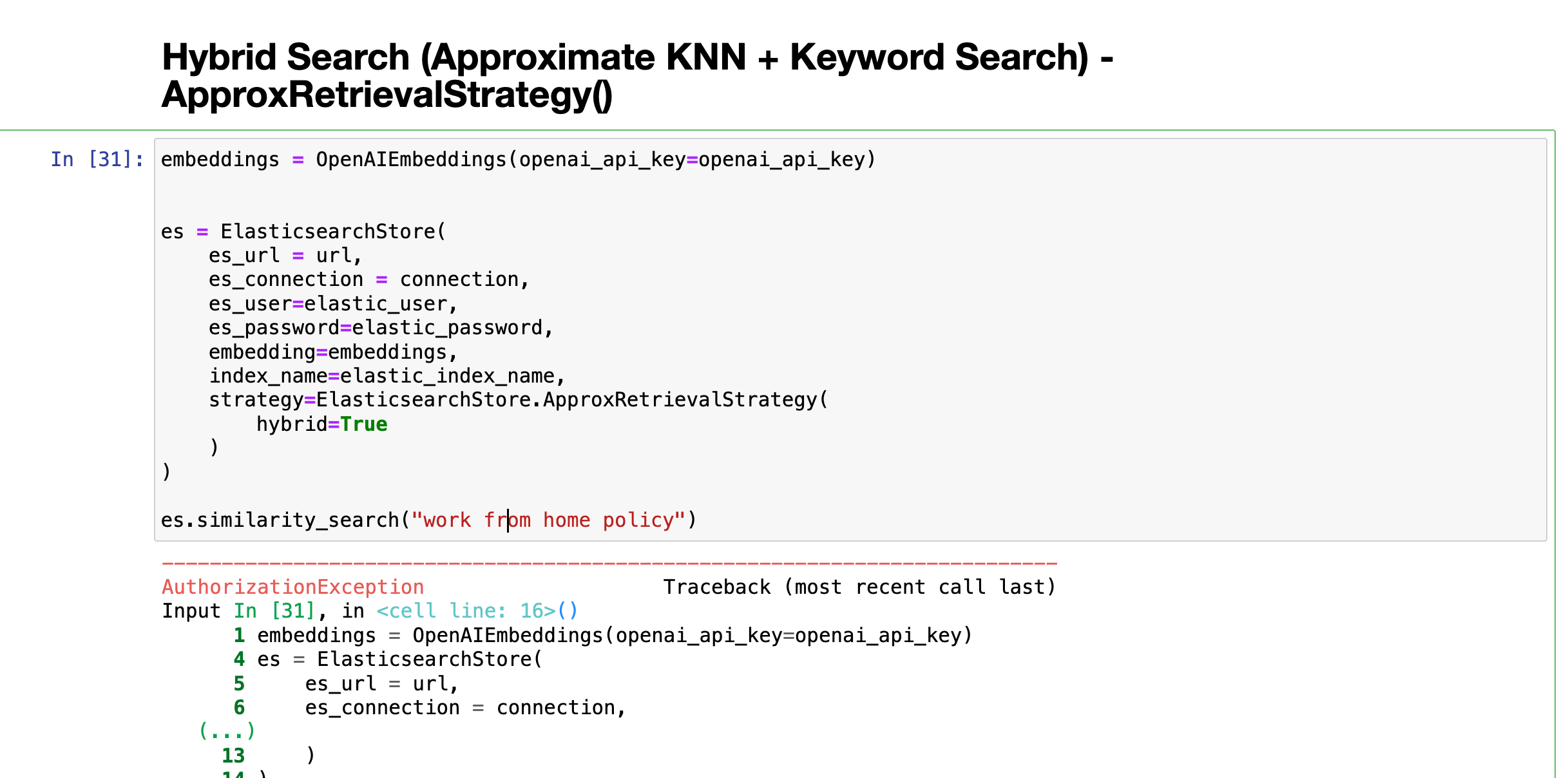
造成这个错误的原因是因为当前的 License 模式不支持 RRF。我们去 Kibana 启动当前的授权:

我们再次运行代码:
Exact KNN Search (Brute Force) - ExactRetrievalStrategy()
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
es = ElasticsearchStore(
es_url = url,
es_connection = connection,
es_user=elastic_user,
es_password=elastic_password,
embedding=embeddings,
index_name=elastic_index_name,
strategy=ElasticsearchStore.ExactRetrievalStrategy()
)
es.similarity_search("work from home policy")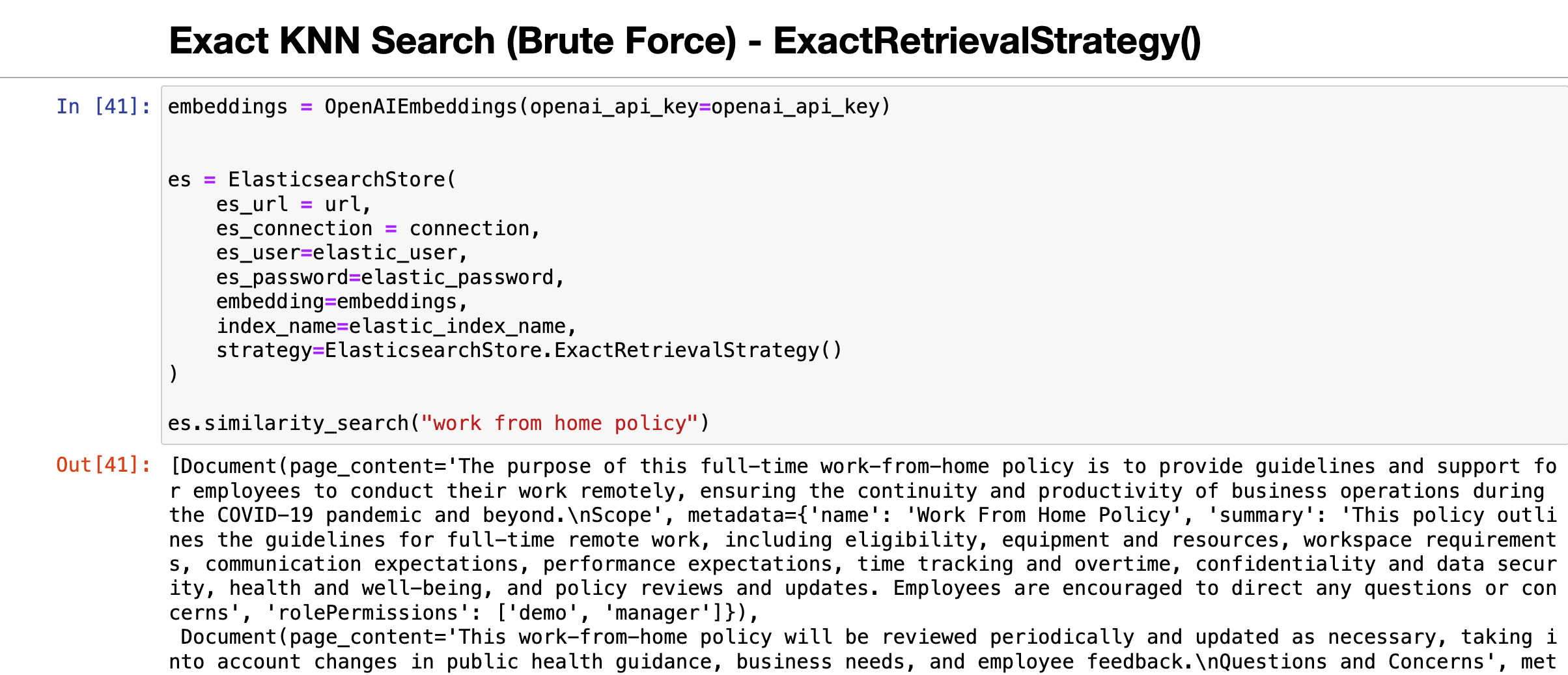
Index / Search Documents using ELSER - SparseVectorRetrievalStrategy()
在这个步骤中,我们需要启动 ELSER。有关 ELSER 的启动,请参阅文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR”。
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
es = ElasticsearchStore.from_documents(
docs,
es_url = url,
es_connection = connection,
es_user=elastic_user,
es_password=elastic_password,
index_name=elastic_index_name+"-"+"elser",
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy()
)
es.similarity_search("work from home policy")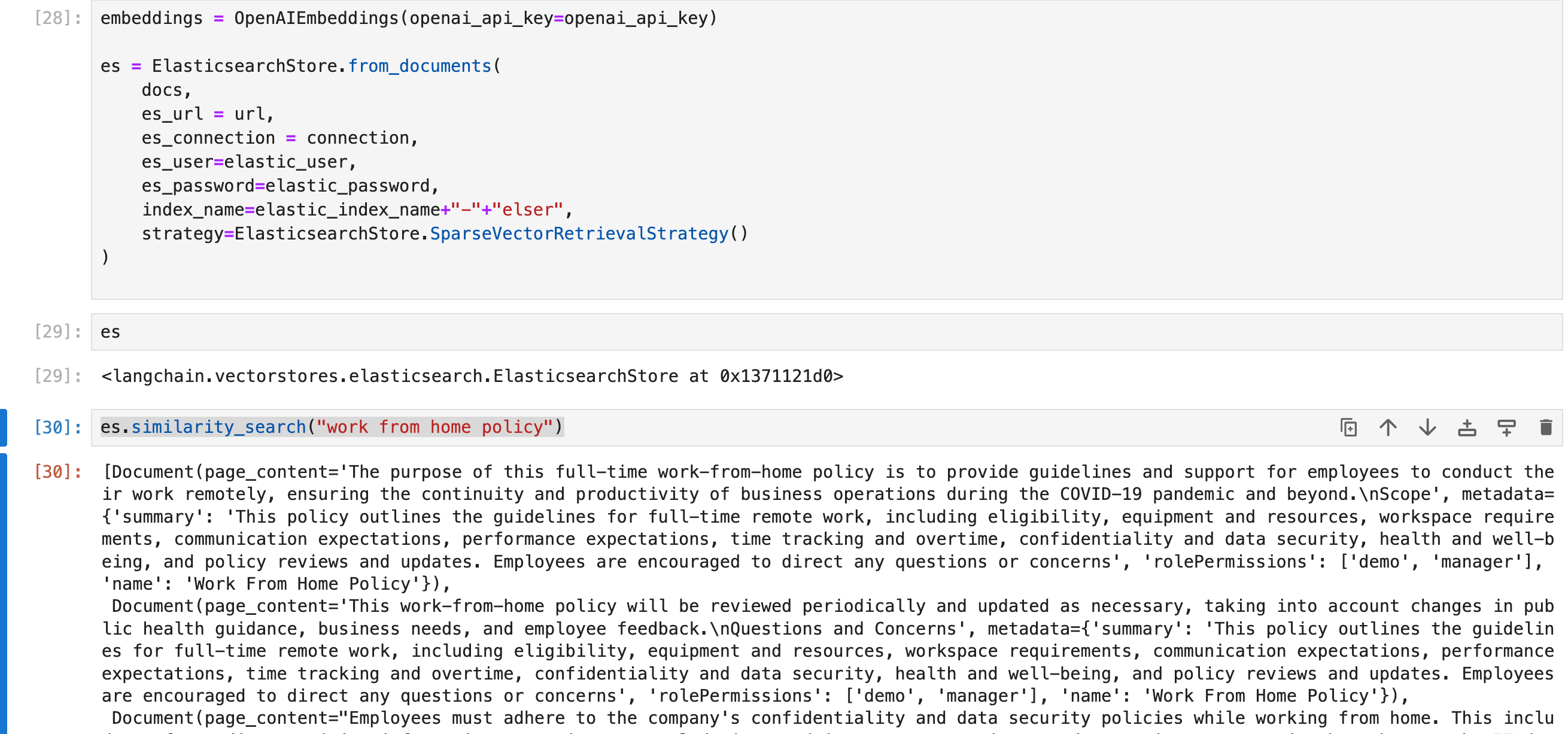
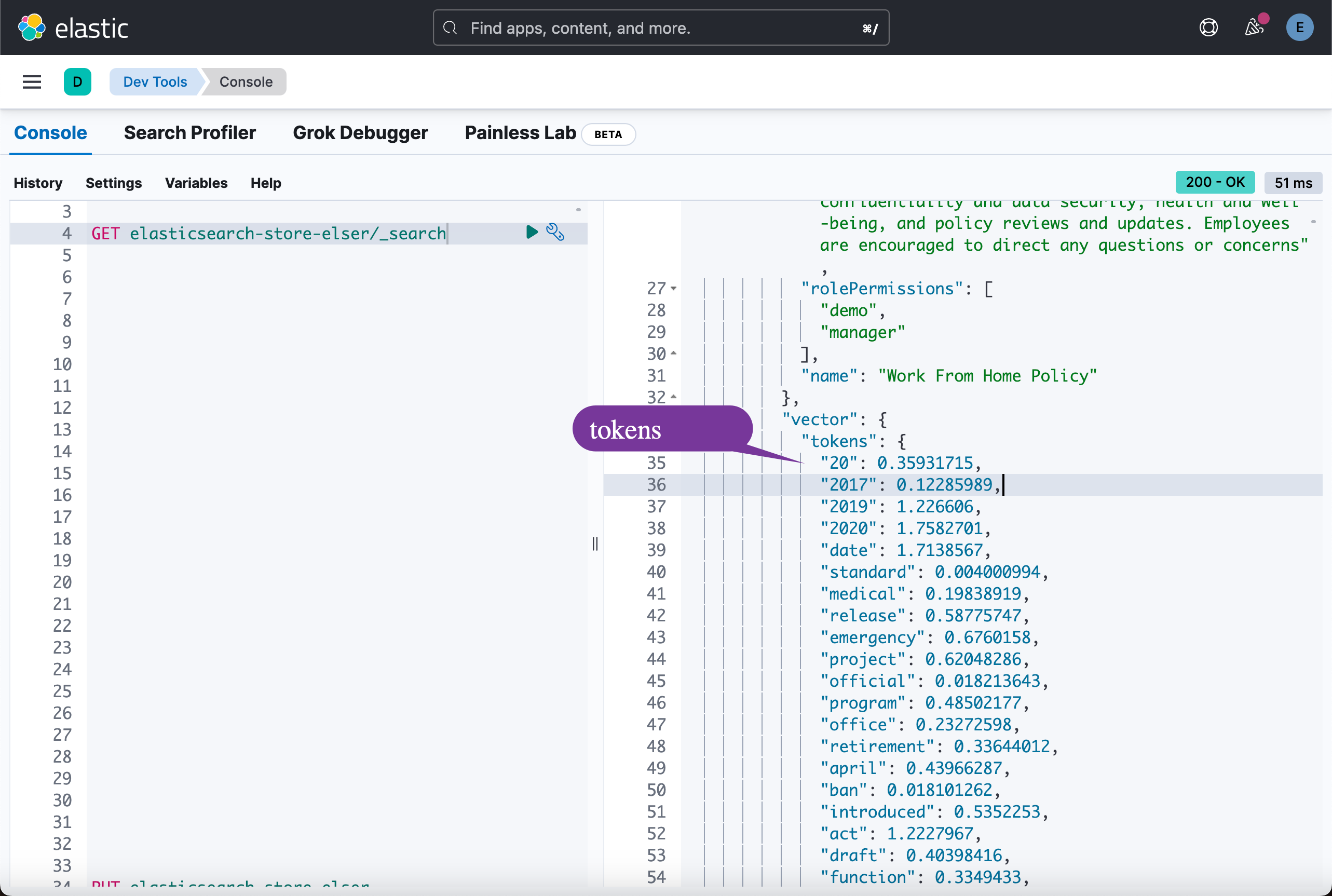
在运行完上面的代码后,我们可以在 Kibana 中进行查看所生成的字段:
上面代码的整个 jupyter notebook 可以在地址 https://github.com/liu-xiao-guo/semantic_search_es/blob/main/ElasticsearchStore.ipynb 下载。