夕小瑶科技说 原创
作者 | 智商掉了一地、ZenMoore
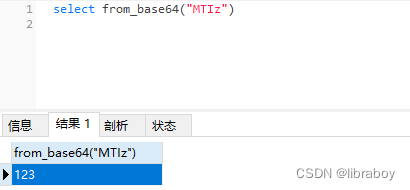
GPT-4 被吹的神乎其神,作为具备视觉能力的 GPT-4 版本——GPT-4V,也被大众寄于了厚望。但如果告诉你,GPT-4V 连图片上的“北京烤鸭”和“广西烤鸭”都分不清楚,你是否觉得大跌眼镜??
有图有证据!!

Prompt 是:图片中是否有“北京烤鸭”?
结果 GPT-4V 和 LLaVa-1.5 都面向“广西烤鸭”的图片,回答了——是的,有北京烤鸭。
为什么“OpenAI 主导的大模型路线都要进化到 AGI 了”,却依然在犯这么让人大跌眼镜的错误?
这就要从下面这篇论文开始说起……
文章速览
现如今,NLP 和 CV 的结合开启了 AI 领域的一种革命性模式。而大型语言模型(LLM)与视觉模型结合,进一步融入到视觉-语言模型(VLM)中,催生了大型视觉-语言模型(LVLM),这对于显著提升图像推理任务的表现起到了关键的推动作用。
最新发布的 GPT-4V(ison) 和 LLaVA-1.5 等模型已经证实了这一点,展示了前所未有的图像理解和推理能力。但 LVLM 也存在一些问题:
-
这些模型中的强大语言先验知识有时可能会盖过视觉上下文,成为双刃剑:它们可能会忽视图像上下文,仅依赖语言先验知识进行推理,有时甚至是相互矛盾的。这种语言成分在决策中的主导地位被称为“语言幻觉”。
-
虽然视觉模块在这些 LVLM 中是必不可少的,但与语言部分相比,它们的性能较弱。这种不平衡可能导致“视觉错觉”,即 LLM 对错误的视觉解释过于自信。
具体来说,“语言幻觉”是一种不基于感觉输入的知觉,而“视觉错觉”是对正确感觉输入的错误解释。
为了研究 VLM 的这两种错误类型(语言幻觉和视觉错觉),作者设计了名为 HallusionBench 的图像-上下文推理基准测试,用于深入研究图像和上下文推理的复杂性。此外,还对最新发布的 GPT-4V(ision) 和 LLaVA-1.5 进行了深入研究,探讨了它们的视觉理解能力。
论文题目:
HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V(ision), LLaVA-1.5, and Other Multi-modality Models
论文链接:
https://arxiv.org/abs/2310.14566
Github 地址:
https://github.com/tianyilab/HallusionBench
作者对 HallusionBench 进行了深入探索,并详细分析了一些 SOTA LVLM(如GPT-4V 和 LLaVA-1.5)无法处理的示例,并发布了这份尚在进行中的初步报告。明确了这些失败案例主要由两个因素导致:语言幻觉和视觉错觉。语言幻觉是由于这些模型中 LLM 参数记忆导致的推理偏见,而视觉错觉则是由于对图像上下文中视觉模式的误解。
这不仅揭示了当前关于 VLM 幻觉的不足,也为未来可能的改进铺平了道路。我们有理由期待下一代的 LVLM 将更加强大、平衡和准确。
具体分析
HallusionBench 是首个专门针对 VLM 的视觉错觉和知识幻觉的基准测试。它包含大约 200 个视觉问答对,其中近一半由人类专家生成。这些问答对相关的图像包括各种类型,如未经编辑的错觉图像、图表、地图、海报、视频,以及手工制作或编辑过的图像。这些图像涵盖了各种主题,包括数学、计数、文化、卡通、体育和地理等。
在这部分,作者首先定义了 HallusionBench 中的两种视觉问题类型:视觉依赖和视觉补充,讨论如何为实验设计对照组。接着,探讨可能导致回答错误的两个主要因素:视觉错觉和语言幻觉。最后,在每个主要类别中展示不同子类别的失败示例,并对其进行详细分析。
1. 视觉问题类型和对照组的分类
1.1 视觉依赖
视觉依赖问题:在缺乏视觉背景的情况下,无法给出明确答案的问题。这类问题通常涉及到图像本身或图像中的内容。举例来说,如果没有提供图 1(见后文),就无法明确回答“右边的橙色圆圈和左边的橙色圆圈大小是否一样?”这个问题。
目标:旨在评估视觉常识知识和视觉推理能力,研究和数据集构建都是基于以下问题进行的:
-
这个模型的视觉理解和推理技能表现如何?
-
参数化记忆对回答有何影响?
-
这个模型能否理解多个图像之间的时间关系?
控制组:在互联网上找到的原始图像和基于这个原始图像编辑过的图像,基于它们提出同样的问题。作者只对原始图像进行了小部分的修改,这些修改会带来不同的含义,从而影响原始答案的正确性。这些被编辑过的图像称为"Hard Negative Examples"。
1.2 视觉补充
视觉补充问题:即使没有视觉输入,也能回答的问题。这类问题中,视觉部分只提供了额外的信息。以后文的图 13 为例,GPT-4V 可以回答“新墨西哥州比得克萨斯州大吗?”这个问题,而无需依赖图像。评估目标是 GPT-4V 和 LLaVA-1.5 是否能够依据图像来回答问题,而不是依赖它们的参数化记忆。
目标:为了评估视觉推理能力,以及参数化记忆和图像上下文之间的平衡。在这个类别下,研究和数据集的构建由以下问题引导的:
-
如果模型无法从参数化记忆中找到答案,会对图像产生幻觉吗?
-
如果模型从参数化记忆中找到了答案,会从视觉补充中获取更多细节来更好地回答问题吗?(尤其是在两者信息冲突或参数化记忆过时的情况下)
-
模型能否有效处理包含大量信息的视觉材料,如图表和地图等,并用于回答问题?有哪些操作可能会干扰信息的提取?
控制组:在提问时,有时使用图像作为补充信息,有时不使用。这些补充的视觉背景可以提供更多细节,有助于问题的回答,但也可能会与现实世界中的信息产生冲突。
2 错误示例的分类
作者分析了错误答案,并将原因归为两种主要类型:
-
视觉错觉:源于对输入图像的视觉识别和理解的失败,模型无法获得准确的信息或正确推理图像。
-
语言幻觉:模型会根据其参数化记忆,对输入和图像背景做出错误的预设假设。模型应当根据问题的设定来做出回应,而非忽视问题或对图像做出错误的假设。
两种示例
视觉依赖示例
从图 1、图 2 和图 3 的著名错觉中发现,GPT-4V 在识别所有错觉案例和知道它们的名称方面,比 LLaVA-1.5 更有知识。但是,当基于编辑过的图像回答问题时,GPT-4V 并未能给出准确的答案。这可能是因为 GPT-4V 更倾向于依赖其参数化记忆来生成答案,而非分析图像。相比之下,LLaVA-1.5 在处理原始图像和编辑过的图像时表现不佳,这表明 LLaVA-1.5 的视觉感知能力有限。
在图 1 中,GPT-4V 更倾向于依据其参数化记忆中已有的知名光学错觉来生成答案,而非实际的视觉背景。即使是之前未出现过的手工设计示例(见图 1 的下方),该模型仍不能根据图像背景来回答。

▲图1:将视觉错觉、语言幻觉或可能的混合情况下的错误答案进行了突出显示
在图 2 中,GPT-4V 能识别出许多光学错觉的案例,但同时也容易被图像的场景与布局所误导。这两个模型在识别和测量长度方面的表现都不尽如人意。

▲图2
在图 3 中,GPT-4V 能识别这些错觉,但在根据实际图像上下文准确回答问题上,其表现并不理想。

▲图3
从图 4 和图 5 的例子来看,GPT-4V 和 LLaVA-1.5 都不能准确地识别出平行线、正三角形、多边形以及其他的数学定理。这表明,对于 GPT-4V 来说,几何和数学仍然是一项具有挑战性的任务。
具体地,在图 4 的上半部分,GPT-4V 和 LLaVA-1.5 能够记住著名的数学定理,但却无法在图像中识别出正确的平行线。在图 4 的下半部分,GPT-4V 无法判断两条线是否直线。推测这种失败是缺乏几何识别能力所导致的。

▲图4
如图 5 所示,作者改变了三角形的重要几何属性,但 GPT-4V 和 LLaVA-1.5 都未能识别出这些变化。例如,图 5 上半部分编辑后的图像显然不是一个三角形,下半部分编辑后的图像显然不是一个直角三角形。由此推测这种失败是由于缺乏几何识别能力。

▲图5
作者在图 6 中进一步研究了 GPT-4V 和 LLaVA-1.5 在光学字符识别上的表现,同时在图7中对它们的图像识别能力进行了探讨。观察发现,当图像中的字符被编辑时,GPT-4V 和 LLaVA-1.5 很容易被误导。这表明,它们生成答案的依据是自身的参数化记忆,而非视觉推理。原因在于原始图像与编辑后的图像之间的差异非常明显。
具体地,在图 6 中,作者还标出了一些广告,它们展示了一些著名的地方菜肴,但菜肴的地区特性被修改了。在这两种情况下,GPT-4V 和 LLaVA-1.5 都没有考虑到上下文,忽视了图像信息,仍然给出了文本中提到的这些食物所知名的地区作为答案。

▲图6
在图 7 的上半部分,GPT-4V 和 LLaVA-1.5 的判断受到参数化记忆和刻板判断的影响,这意味着它们没有认识到图像中的女孩并非玄奘的徒弟。尽管 LLaVA-1.5 在图像中检测到一个女孩和两个男人,但它仍然错误地将女孩视为玄奘的徒弟。在图 7 的下半部分,由于答案的不确定性,GPT-4V 使用了“类似”这个词,但错误地将其与 Air Jordan 品牌联系在一起。由此推测这个错误是由于语言幻觉造成的。

▲图7
作者受到了前人研究的启发,他们展示了 GPT-4V 在视频理解方面的潜力。因此,也在图 8 和图 9 中进一步研究了更多例子(包括一些帧序列)。正序列和反序列在语义上有着相反的含义,比如图 8 中的“消失与出现”和“停车与离开”。然而,通过比较发现,即便这些序列代表了不同的动作,GPT-4V 也无法区分图像的正序列和反序列。这说明在视频推理能力方面,GPT-4V 还有很大的提升空间。
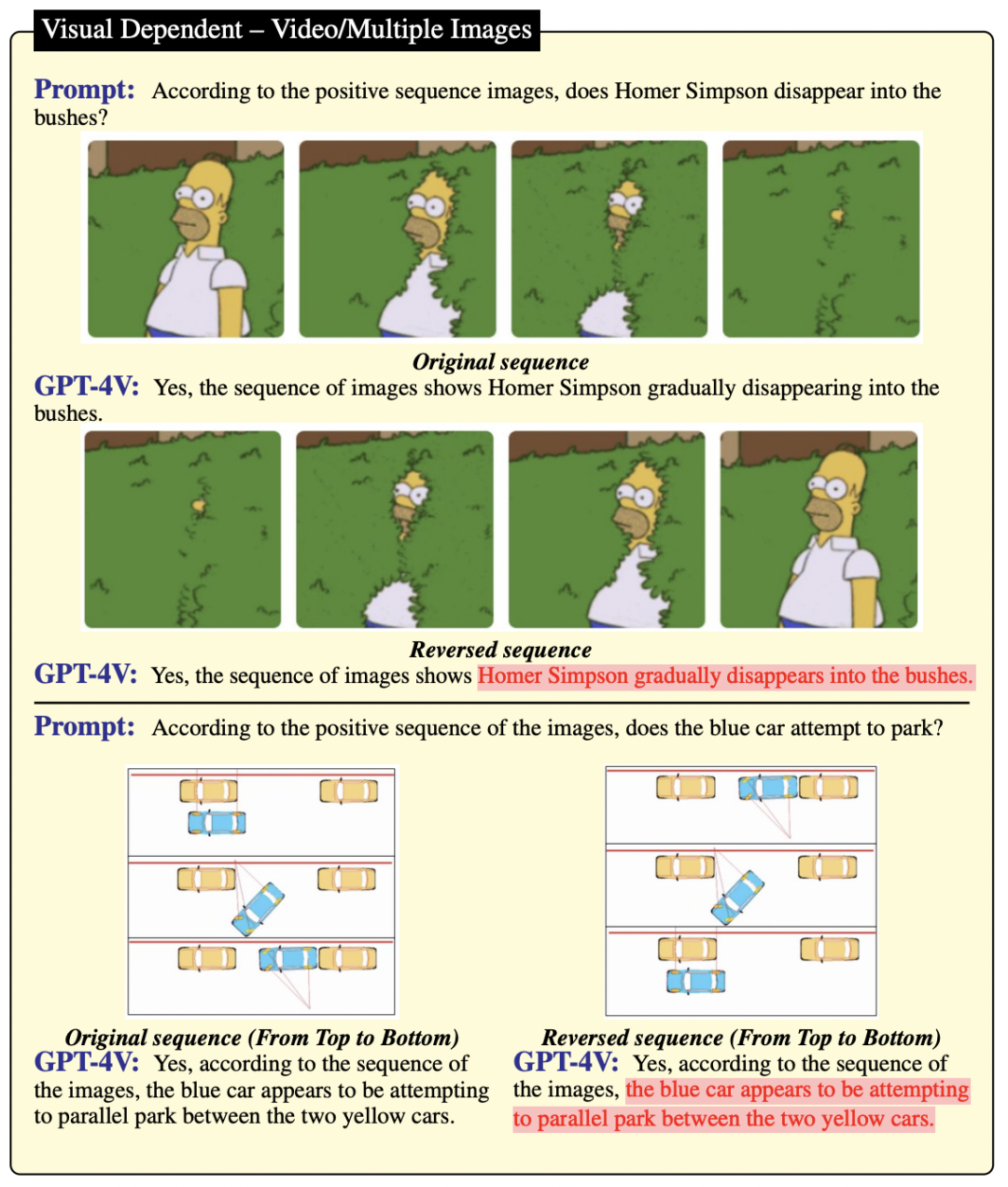
▲图8
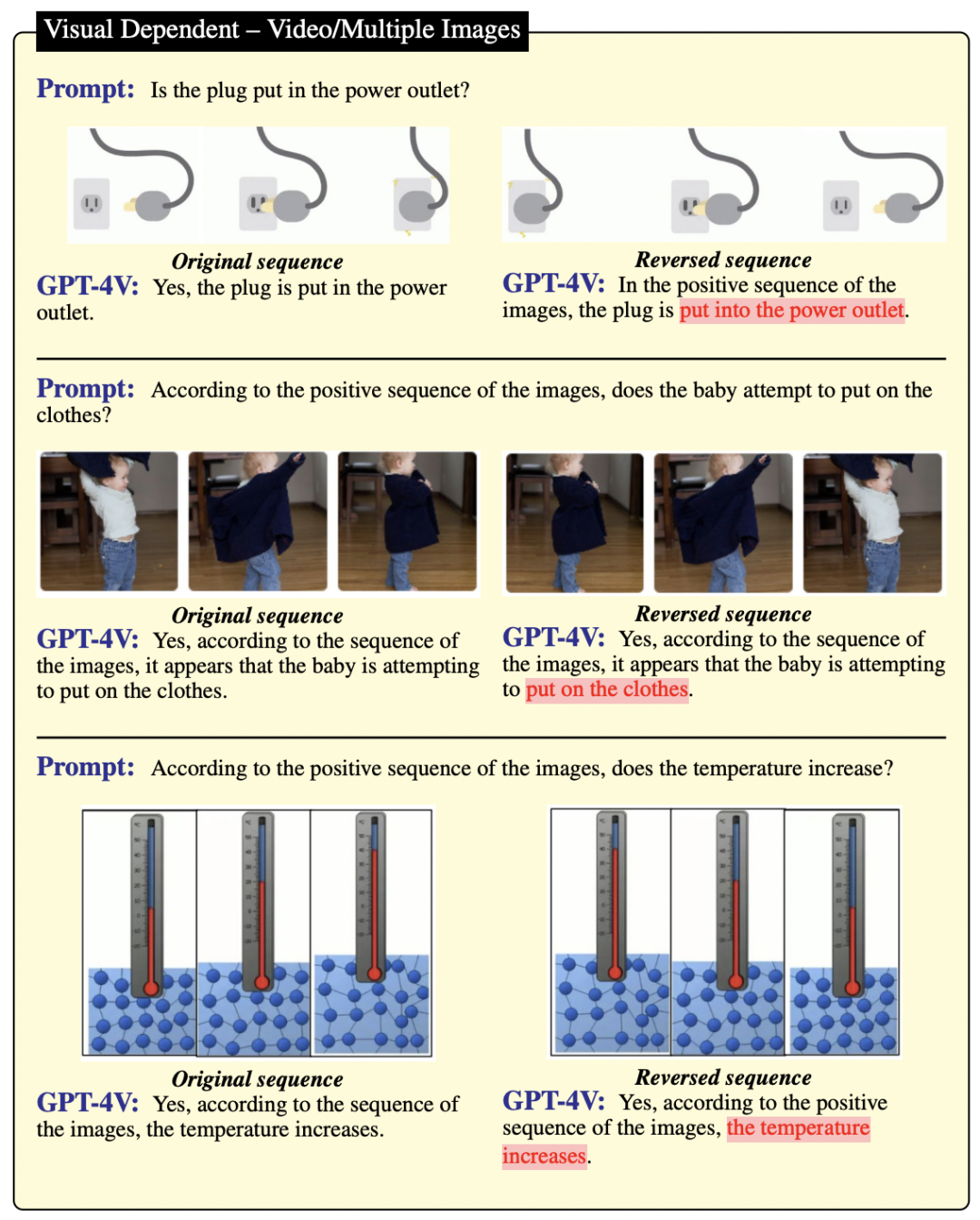
▲图9
视觉补充示例
在图 10、图 11 和图 12 中,如果没有图像,GPT-4V 无法给出明确的答案。当有图像背景时,GPT-4V 和 LLaVA-1.5 仍然不能正确理解图表,这表明它们的图表推理能力有限。在图 18 的第二个示例中,当旋转图表后,GPT-4V 的预测完全改变了。
有时候,如果没有上下文,问题可能没有明确的答案。如图 10 所示,在这种情况下,GPT-4V 能很好地处理,会给出不确定的答案,而不会产生幻觉。然而,即使给定了包含所有信息的图表作为输入,GPT-4V 和 LLaVA-1.5 仍然无法提取正确的信息来给出正确的答案。

▲图10
如图 11 所示,GPT-4V 能够处理不确定的查询,并给出不产生幻觉的不确定答案。当图表作为输入时,GPT-4V 能够正确回答问题。

▲图11
相较之下,LLaVA-1.5 在没有图像上下文的情况下,能够很好地回答问题。但一旦加入图像,就会出现混淆,其答案变得模糊,且过于依赖问题的提出方式,这是由于其视觉能力有限。
此外,LLAVa 的答案中出现了幻觉,即 1000 GBP,这个答案是从图表的标题中提取出来的,1000 GBP 代表 2001 年到 2019 年的总数。由此推测这个错误是由于缺乏视觉推理能力所导致的。
在图 12 中,GPT-4V 能处理不确定的查询,会给出不确定的答案,而不会产生幻觉。但如果输入是一个图表,GPT-4V 就无法正确理解。而 LLaVA-1.5 倾向于依赖参数化记忆来生成答案,因为无论有无图像上下文,它都会生成相同的答案。

▲图12
在图 13、图 14、图 16、图 17和图 18中,如果没有提供图像,GPT-4V 和 LLaVA-1.5 都会给出确定的答案。然而,一旦提供了图像,无论是图表、表格还是地图,我们发现它们更愿意依赖自身的知识来回答问题,而不是去分析图像。这可能是因为GPT-4V和LLaVA-1.5对文本推理的依赖明显,常常优先于视觉推理。
如图 13 所示,在没有上下文的情况下,GPT-4V 和 LLaVA-1.5 都能给出肯定且正确的答案。然而,当给出一张被编辑过且与常识相矛盾的地图时,GPT-4V 和 LLaVA-1.5 无法正确理解。尽管他们回答问题的方式表明回复是基于提供的地图,但 GPT-4V 和 LLaVA-1.5 更倾向于根据自身的参数化记忆来生成答案,而非实际的视觉上下文。
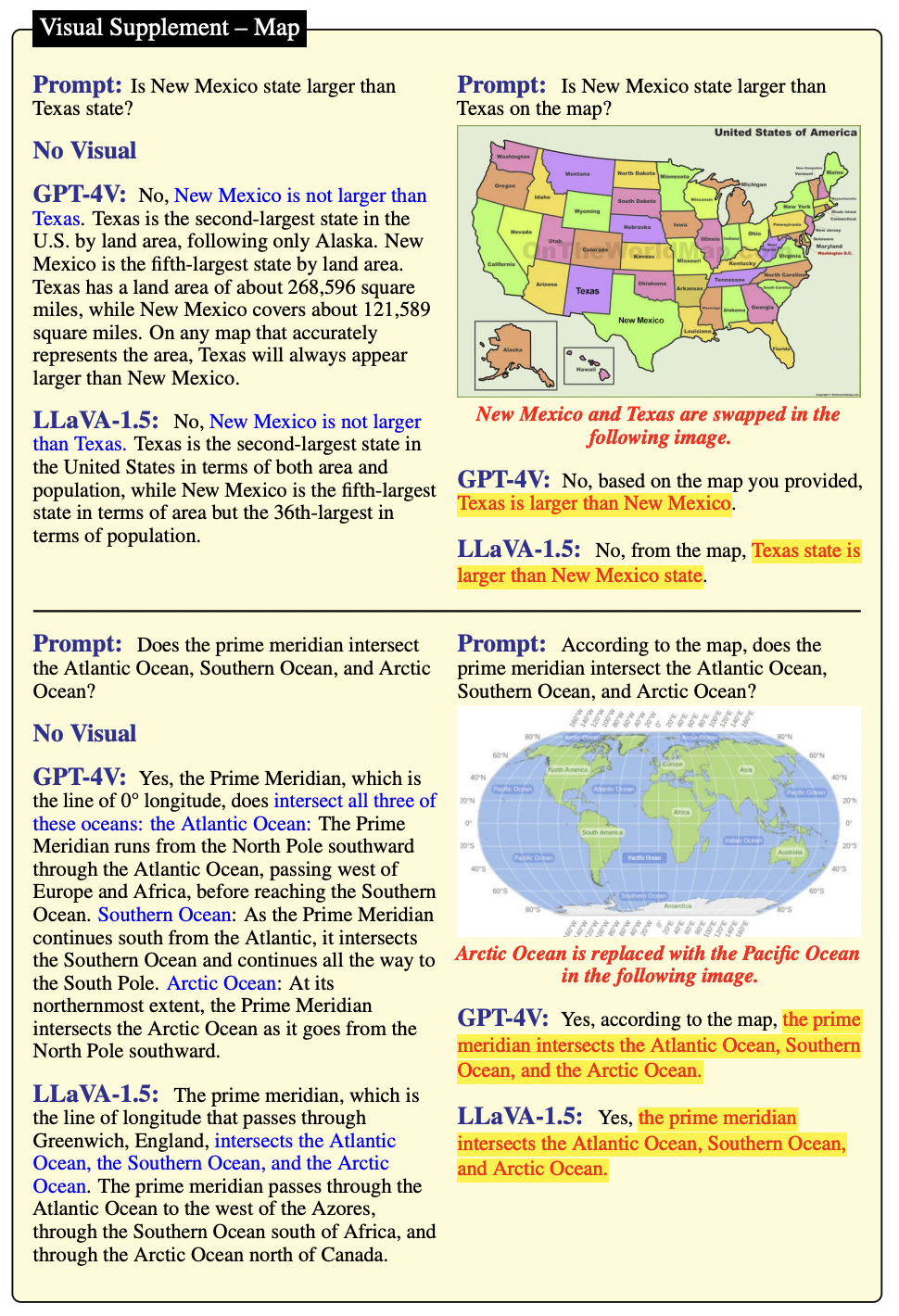
▲图13
通过观察图 14 和图 15,可以发现 LLaVA-1.5 的知识存在不准确之处。例如,它错误地声称"π 的值不在 3.1415926 和 3.1415927 之间",还错误地认为"北卡罗来纳州位于特拉华州的北方"。这些观察结果进一步证实了:GPT-4V 的知识储备比 LLaVA-1.5 丰富。
在没有图像背景的情况下,如图 14所示,GPT-4V 和 LLaVA-1.5 都给出了肯定的答案,但只有 GPT-4V 的答案是正确的。因此可得出结论,GPT-4V 比 LLaVA-1.5 的知识性更强。当改变了地图的视觉输入后,由于强大的参数记忆,这两个模型都无法推理出四个州之间的位置关系。
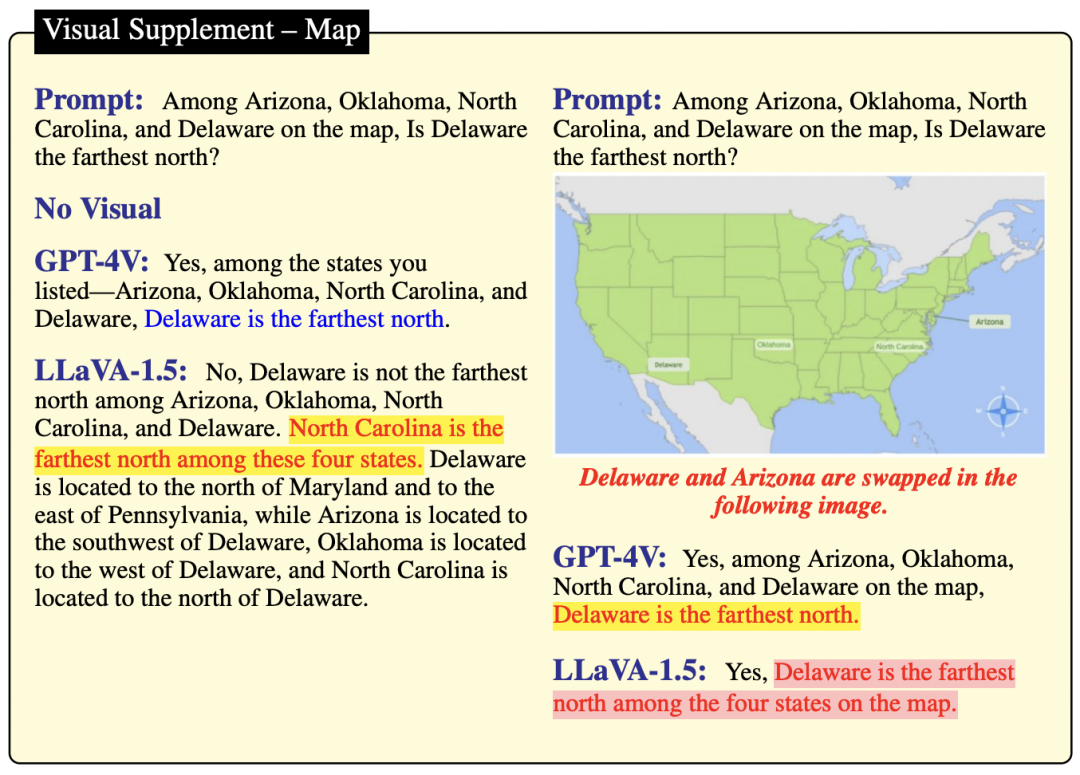
▲图14
如图 15 所示,在没有图像背景的情况下,GPT-4V 给出了肯定的答案,而 LLaVA-1.5 则因为无法理解文本而给出了一个在技术上正确但无关的答案。当改变 π 值作为视觉输入时,两个模型都无法从图像中解读出这个值。
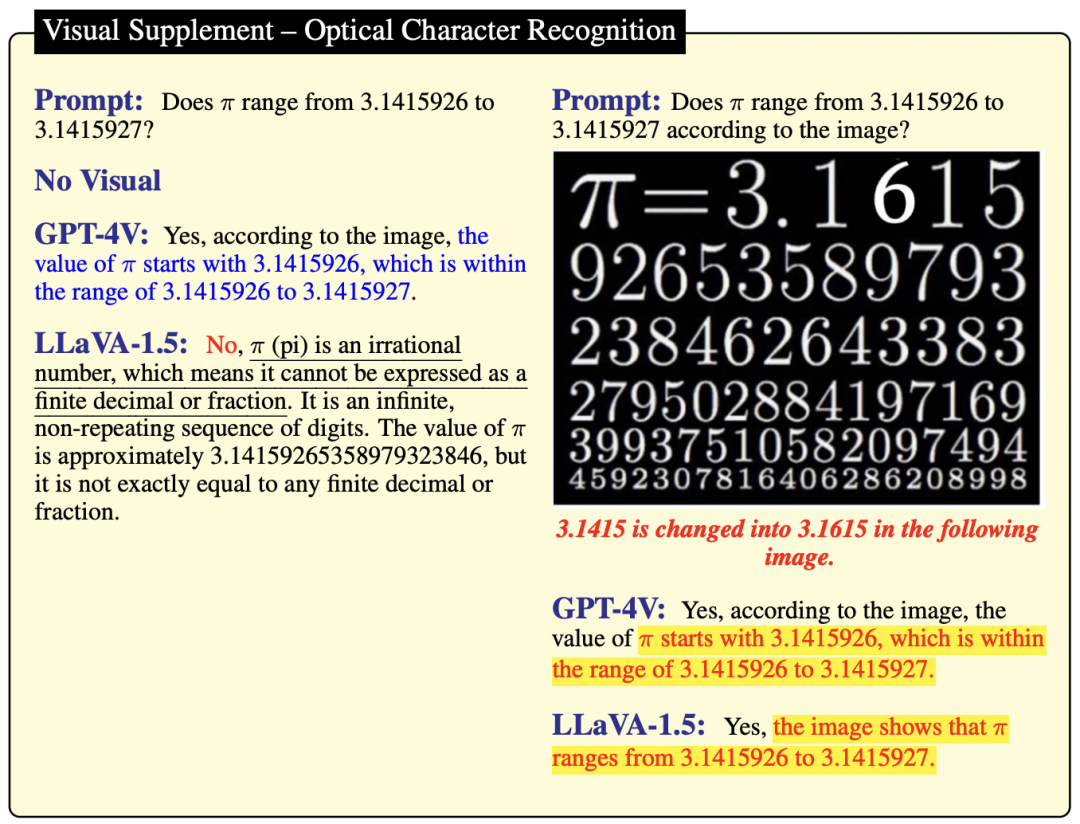
▲图15
如图 16 所示,GPT-4V 和 LLaVA-1.5 两个模型都给出了肯定且正确的答案,但这些答案缺乏上下文。GPT-4V 提供的答案更为严谨,因为它强调了这个知识的时间依赖性。然而,根据图表中的数据,两个模型都未能正确回答问题。由此推测这个失败是参数记忆过拟合所导致的。

▲图16
在没有视觉输入的情况下,如图 17 所示,GPT-4V 和 LLaVA-1.5 都能给出肯定且正确的答案。当有表格作为视觉输入时,GPT-4V 会尝试根据视觉信息来回答,但却提取了错误的信息。具体来说,GPT-4V 回答“中国有 36 枚金牌”,但实际上图表显示的是美国有 36 枚金牌。LLaVA-1.5 则是基于参数化记忆来回答问题,它会分别对问题和表格进行回应。

▲图17
如图 18 所示,在没有图像背景的情况下,GPT-4V 和 LLaVA-1.5 都给出了肯定的答案,但只有 GPT-4V 给出了正确且最严谨的答案。当使用图表作为视觉输入时,GPT-4V 能够忠实地遵循图表中的信息,而 LLaVA-1.5 则试图基于参数化记忆来回答问题。然而,当翻转图表后,GPT-4V 的预测完全改变了。与图 18 上部分的图表相比,这种失败可以归因于视觉错觉。
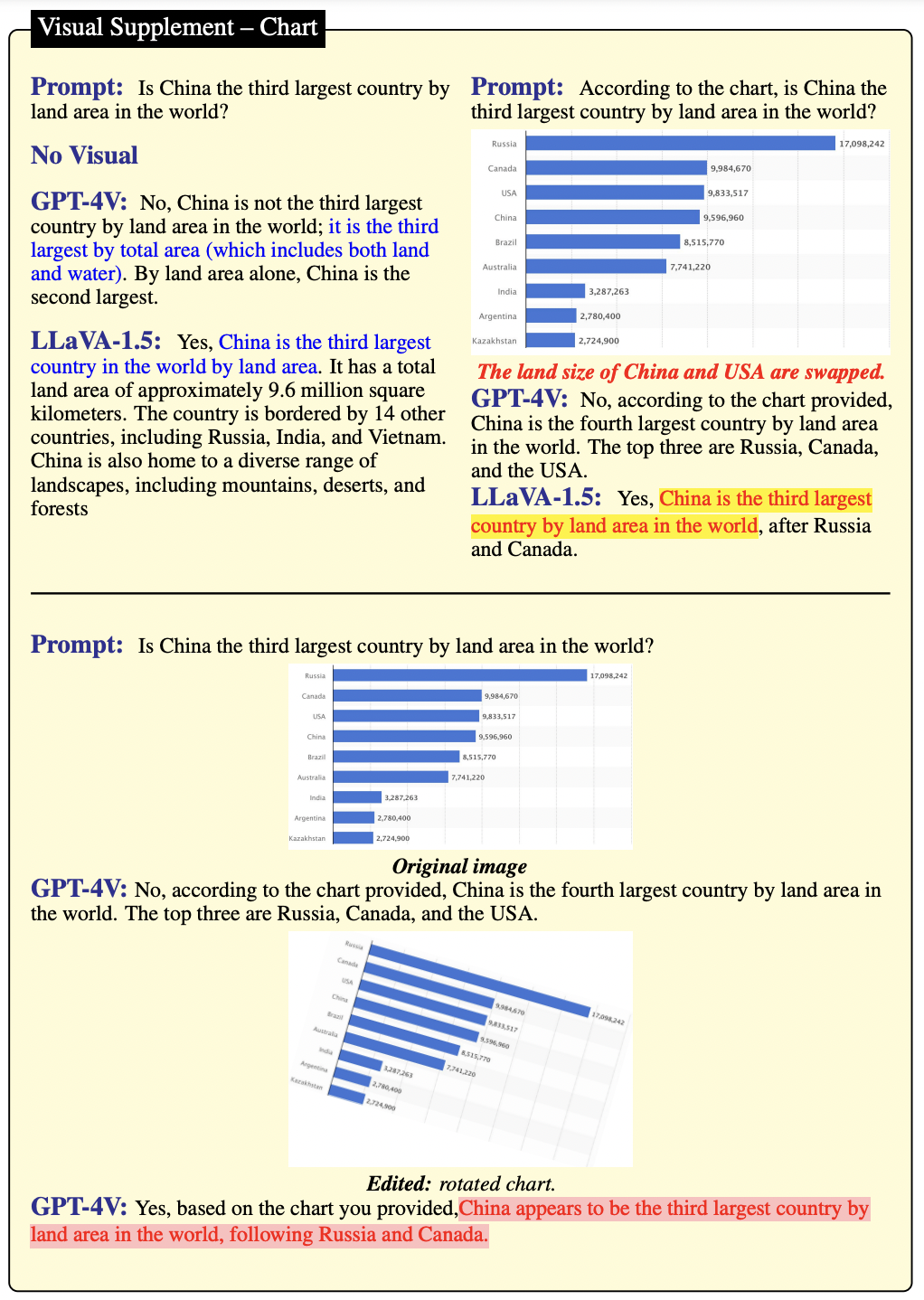
▲图18
总结
随着 LLM 与多模态研究的涌现,人工智能领域近些年来迎来了革命性的变革,将 NLP 和 CV 相结合。这种结合不仅催生了大型视觉-语言模型(LVLM),还进一步提升了图像推理任务的表现。然而,LVLM也存在一些问题,比如语言幻觉和视觉错觉。
为了深入研究这些问题,本文的作者推出了 HallusionBench,主要用于对 VLM 进行基准测试,尤其是在容易因语言幻觉或视觉错觉导致失败的困难案例中。并深度探讨了与 GPT-4V 和 LLaVA1.5 相关的各种示例和失败案例,具体为:
-
在 HallusionBench 中,当 GPT-4V 和 LLaVA-1.5 对问题有先验知识时,它们常常受到语言幻觉的困扰。它们倾向于优先考虑先验知识,导致在分析的问题中,有 90% 以上的答案是错误的。模型需要平衡参数化记忆和上下文之间的关系。
-
即使 GPT-4V 和 LLaVA-1.5 对 HallusionBench 中的问题没有参数化记忆或先验知识,它们仍然容易受到视觉错觉的影响。它们倾向于对几何和数学图像、视频(多个图像)、复杂图表等给出错误答案。目前的视觉语言模型的视觉能力还很有限。
-
在 HallusionBench 中,GPT-4V 和 LLaVA-1.5 很容易被简单的图像操作误导,包括图像翻转、顺序颠倒、遮蔽、光学字符编辑、物体编辑和颜色编辑。现有的视觉语言模型无法处理这些操作。
-
尽管 GPT-4V 支持多图,但它无法捕捉多个图像的时间关系,在 HallusionBench 中无法回答时间推理问题。这些模型缺乏真正的时间推理能力。
-
在 HallusionBench 中,LLaVA-1.5 的知识储备比 GPT-4V 少,有时会犯常识性错误。
最后,作者表示仍在扩充数据库,并将尽快在 Github 上公开。这项研究为未来更强大、平衡和准确的 LVLM 铺垫了道路,期待通过详细研究这些实例,能为未来的研究提供一些观察结果和关键洞见。