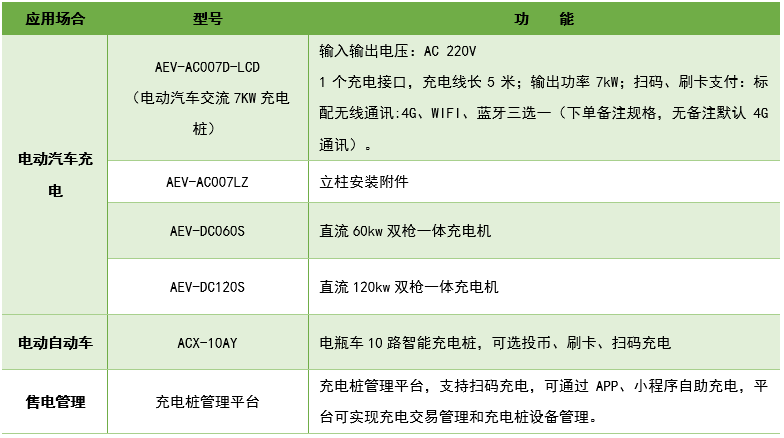
一文搞定分布式训练:dataparallel、distirbuted、deepspeed、accelerate、transformers、horovod - 知乎代码地址:taishan1994/pytorch-distributed-NLP: pytorch分布式训练 (github.com)pytorch-distributed-NLPpytorch单机多卡分布式训练-中文文本分类。一直想尝试来着,苦于没有卡,只好花过年的压岁钱去Autodl上租…![]() https://zhuanlan.zhihu.com/p/628022953大模型分布式训练并行技术(一)-概述 - 知乎近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练…
https://zhuanlan.zhihu.com/p/628022953大模型分布式训练并行技术(一)-概述 - 知乎近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练…![]() https://zhuanlan.zhihu.com/p/598714869目前大模型的几个方式包括:
https://zhuanlan.zhihu.com/p/598714869目前大模型的几个方式包括:
单卡python直接训练:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py多卡训练:
accelerate:
accelerate config # 首先配置分布式环境
accelerate launch src/train_bash.py 在config中选择MULTI_GPU,DeepSpeed/FullySharedDataParallel/Megatron-LM...
deepspeed:
deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \
--deepspeed ds_config.json \
...torchrun:
torchrun --nproc_per_node={num_gpus} train.py --train_args_file train_args/llama2-13b-ext.yaml低版本的pytorch多卡训练(torchrun是其升级版本):
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 --master_addr=localhost --master_port=22222 train.py数据并行:数据集被分割成几个碎片,每个碎片被分配到一个设备上。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练,在反向传播之后,模型的梯度将被全部减少,以便在不同设备上的模型参数能够保持同步。DDP
模型并行:模型被分割并分布在一个设备阵列上,有两种方式:张量并行/流水线并行。
张量并行:张量是将一个张量沿特定维度分成N块,每个设备只持有整个张量的1/N,需要额外的通信来确保结果的正确性。
流水线并行:模型按层分割成若干块,每块交给一个设备,在前向传播过程中,每个设备将中间激活传递给下一个阶段;在反向传播中,每个设备将输入张量的梯度传回给前一个流水线阶段。这允许设备同时进行计算,从而增加训练的吞吐量。
优化器并行:单个GPU的显存无法放下大模型,通常来说,模型训练过程中,GPU上需要进行存储的参数包括了模型本身的参数、优化器状态、激活函数的输出值、梯度以及一些零时的Buffer。其中模型状态参数(优化器状态+梯度+模型参数)占到了一大半以上。优化器相关的并行是一种去除冗余数据的并行,ZeRO,零冗余优化器,针对模型状态的存储优化,ZeRO使用的是分片,即每张卡只存1/N的模型状态量,这样系统只维护一份模型状态,ZeRO有3个级别,1.ZeRO-1,对优化器状态分片;2.ZeRO-2对优化器状态和梯度分片;3.ZeRO-3对优化状态、梯度分片以及模型权重参数分片。

异构系统并行: 上述方法通常需要大量的GPU来训练一个大型模型,与GPU相比,CPU内存要大得多,在不使用张量时,将其卸载回CPU内存或NVME磁盘。