Hamming distance
定义
汉明距离,定义是两个码字之间的不同的位的数量,例如4’b0000和4’b0011的汉明距离为2,4’b0000和4’b1110的汉明距离为3。
一种编码方式的(最小)汉明距离,它的定义就是,这套编码方案中,任意两个编码的码字之间的汉明距离,最小值是多少。
minimum Hamming distance = 1
如果一组编码的码长为n,那么这组编码共可以表示2^n种符号,但这样一来这个编码就没有任何抗干扰能力,因为合法码字之间的最小汉明码距为1,任何一个符号的编码的任意一位发生错误,就变成了另外一个合法的符号编码。因此接收端也无法判断是否有错误发生。
例如将数据如下方式对应
| 数据 | 编码 |
| 0 | 0000 |
| 1 | 0001 |
| 2 | 0010 |
| 3 | 0011 |
假设数据0在传输过程中发生了1bit错误,则可能出现的情况是,4‘b0001,4‘b0010,4‘b0100,4‘b1000,这几个编码在编码方案中很容易找到对应的编码,因此RX不能判断出此次传输出现了传输错误。
minimum Hamming distance = 2
如果编码的最小汉明距离为2,那么任何合法码字发生一位错误都会变成非法码字,但不能确定是由哪一个合法码字错误而来,因此这个编码可以发现一位错误;
例如下面的编码方式
| 数据 | 编码 |
| 0 | 0000 |
| 1 | 0011 |
| 2 | 1100 |
| 3 | 1111 |
假设数据0在传输过程中发生了1bit错误,则可能出现的情况是,4‘b0001,4‘b0010,4‘b0100,4‘b1000,这几个编码都在编码方案中找不到对应的编码,因此是非法的码字,RX可以判断出此次传输出现了1bit传输错误,但是这个错误是谁发生的,不能确定,因为4’b0001也可以是数据1的编码4’b0011的第[1]位从1错误变成0,因此,可以检测1bit错误,但是无法纠错。
最简单的**奇偶校验码( parity code)**就是汉明距离等于2的一种编码,可以这样考虑:除去parity bit剩下的数据位的最小汉明距离为1,如果两个数只有一位不一样,那parity bit肯定不一样,所以整个数据的汉明距离就是2,如果数据位的汉明距离就≥2,整个数据的距离就一定≥2。
minimum Hamming distance = 3
如果编码的最小汉明距离为3,那么任何合法码字发生一位错误都会变成非法码字,而且距离原来的码字距离为1,而距离其他任何合法码字的最小距离为2(这样就可以很明显区分是由哪一个合法编码发生错误转化而来)。
最小汉明距离为3的编码如果发生了两位错误,也可以发现,但是不能够区分到底是一位还是两位,因为存在一个合法的编码与这个错了两位的数据的汉明距离为1,所以接收端并不能分辨到底是什么情况,只能都当成一位的错误去修正。但是如果试图纠正这个错误就会产生新的错误。
举例简单的编码方式如下面这种编码
| 数据 | 编码 |
| 0 | 000000 |
| 1 | 000111 |
| 2 | 111000 |
| 3 | 111111 |
假设数据0在传输过程中发生了1bit错误,则可能出现的情况是,6‘b000001,6‘b000010,6‘b000100,6‘b001000,6‘b010000,6‘b100000,这几个编码都在编码方案中找不到对应的编码,因此是非法的码字,RX可以判断出此次传输出现了1bit传输错误,并且这些错误的码字与数据0的码字汉明距离是1,而与其他的码字的汉明距离都大于等于2,因此可以判断出是数据0的码字在传输过程中发生了错误。
Hamming Error Correction Code (ECC) 就是一种最小距离为3的编码。
汉明[7,4]是一种汉明距离为3的编码。
minimum Hamming distance = 4
如果最小距离为4,发生一位和两位就是可以区分的,因为错了两位的数据和任意一个合法的数据的最小汉明距离都是2,而错了一位的数据离最近的合法数据的距离是1,所以它们是可区分的,但是两位错误还是不能修正。
比如汉明提出的SEC/DED:


在原来(汉明[7,4]码)的基础上加上一个奇偶校验位,就把最小汉明距离又增加了1,使得它可以correct single bit error and detect double bit errors。
总结
我们可以在2^n个可用的码字中间选择一些码字来对信源符号进行编码,把这些码字称为合法码字,而其他没有使用的码字称为非法码字。这样合法码字之间的汉明距离就会拉开,有些合法码字发生错误后有可能变成非法码字,接收端收到这些非法码字后就可以判断出传输过程中出现了错误。码字之间的最小汉明距离越大,编码的抗干扰能力就越强。
可以看出,检验位的长度越长,合法码字所占的比例就越小,如果这些码字能够尽可能地在所有的码字中均匀分布的话,合法码字之间的最小汉明码距就越大,编码的抗干扰能力也就越强,因此设计编码方法的最重要的任务就是使合法码字尽可能地均匀分布。
原文链接:【精选】最小汉明码距和数据编码的纠错能力的关系_最小汉明距离计算纠错能力-CSDN博客
[7,4] hamming code
根据对汉明距离的理解,如果想要实现能够纠错1bit的功能,需要设计一种最小汉明距离为3的编码方案。
根据奇偶校验码的经验,我们感觉到添加奇偶校验位可以增加编码方案的最小汉明距离。
如下表所示,通过添加奇偶校验位,实现了一套汉明距离为2的编码
| 数据 | 编码 | 奇偶校验位 | 最终的编码 |
| 0 | 0000 | 0 | 00000 |
| 1 | 0001 | 1 | 00011 |
| 2 | 0011 | 0 | 00110 |
| 3 | 0010 | 1 | 00101 |
假设数据是{d1,d2,d3,d4}或{d4,d3,d2,d1},奇偶校验位是4个d的异或结果,编码时,数据码发生了汉明距离为1的形式,奇偶校验码一定会跟着翻转,以增加1个汉明距离,因此,最小汉明距离增加到2。
按照这个思路,增加2个校验位,是否就可以做到汉明距离为3的编码方案。
| 数据 | 编码 | 奇偶校验位1 | 奇偶校验位2 | 最终的编码 |
| 0 | 0000 | 0 | 0 | 000000 |
| 1 | 0001 | 1 | 1 | 000111 |
| 2 | 0011 | 0 | 0 | 001100 |
| 3 | 0010 | 1 | 1 | 001011 |
将全部数值写出来,发现有问题
| 数据 | 编码 | 奇偶校验位1 | 奇偶校验位2 | 最终的编码 |
| 0 | 0000_0000 | 0 | 0 | 000000 |
| 1 | 0000_0001 | 1 | 1 | 000111 |
| 2 | 0000_0011 | 0 | 0 | 001100 |
| 3 | 0000_0010 | 1 | 1 | 001011 |
| 4 | 0000_0110 | 0 | 0 | 011000 |
| 5 | 0000_0111 | 1 | 1 | 011111 |
| 6 | 0000_0101 | 0 | 0 | 010100 |
| 7 | 0000_0100 | 1 | 1 | 010011 |
| 8 | 0000_1100 | 0 | 0 | 110000 |
| 9 | 0000_1101 | 1 | 1 | 110111 |
| 10 | 0000_1111 | 0 | 0 | 111100 |
| 11 | 0000_1110 | 1 | 1 | 111011 |
| 12 | 0000_1010 | 0 | 0 | 101000 |
| 13 | 0000_1011 | 1 | 1 | 101111 |
| 14 | 0000_1001 | 0 | 0 | 100100 |
| 15 | 0000_1000 | 1 | 1 | 100011 |
如图上2个码之间的汉明距离是2,原因是,当码字本身之间的汉明距离为2,会导致奇偶校验码相同,从而导致失效,因此,这样看奇偶校验码1和2,并不能都直接用全数据异或的方式,奇偶校验码1和2之间也必须有所不同,否则无法实现汉明距离为3的方案。
直接能想到的方式是d1、d3用奇偶校验位1,d2、d4用奇偶校验位2,但是明显的,当d2、d4都存在翻转时,也会出现汉明距离为2的情况。(这样看2个校验码似乎无法完成任务)
汉明74码给的方法是加了3个奇偶校验位,假设数据是{d1,d2,d3,d4}或{d4,d3,d2,d1}。
p1 是 d1, d2, d4的异或
p2 是 d1, d3, d4的异或
p3 是 d2, d3, d4的异或
且数据的形式为{p1、p2、d1、p3、d2、d3、d4}

这样设置我认为有2个目的
- 实现汉明距离为3
- 校验码可以直接对应错误的bit位
到这里,就会有个疑问,是否只要是汉明距离为3的编码,都可以纠错1bit?如果是,那汉明距离更进一步地设置了校验码在传输过程中的位置,是为了什么呢?例如下面这样的编码也是汉明距离为3的方式,只是校验位在编码上的位置与hanming code不同。
| 数据 | 编码 | p1 | p2 | p3 | 最终的编码 |
| 0 | 0000_0000 | 0 | 0 | 0 | 0000000 |
| 1 | 0000_0001 | 1 | 1 | 1 | 0001111 |
| 2 | 0000_0011 | 1 | 0 | 0 | 0011100 |
| 3 | 0000_0010 | 0 | 1 | 1 | 0010011 |
| 4 | 0000_0110 | 1 | 1 | 0 | 0110110 |
| 5 | 0000_0111 | 0 | 0 | 1 | 0111001 |
| 6 | 0000_0101 | 0 | 1 | 0 | 0101010 |
| 7 | 0000_0100 | 1 | 0 | 1 | 0100101 |
| 8 | 0000_1100 | 0 | 1 | 1 | 1100011 |
| 9 | 0000_1101 | 1 | 0 | 0 | 1101100 |
| 10 | 0000_1111 | 1 | 1 | 1 | 1111111 |
| 11 | 0000_1110 | 0 | 0 | 0 | 1110000 |
| 12 | 0000_1010 | 1 | 0 | 1 | 1010101 |
| 13 | 0000_1011 | 0 | 1 | 0 | 1011010 |
| 14 | 0000_1001 | 0 | 0 | 1 | 1001001 |
| 15 | 0000_1000 | 1 | 1 | 0 | 1000110 |
我认为,是为了在对传输数据进行简单异或运算后,可以快速地得到错误bit的位置,因此才这样设置的。
[8,4]hamming code
为了在74汉明码的基础上,添加可以检测2bit错误的功能,根据对汉明距离的理解,需要再添加一个校验码以增加汉明距离,让编码的最小汉明距离达到4,这样,就是达到了所谓的SEC DED功能,single error correct,double error detect。
如果是只用74汉明码的话,是无法达到检测2bit错误的效果的。
关于校验位的位置的讨论
如果想要定位一个数据的某个错误bit的位置,根据常用算法分析,使用二分法是比较好的方式。Hanming code对校验码的排布方式就类似于二分法,以一半一半的形式去设置code,01的二进制编码方式,也符合二分法的场景。
假设有个6bit数据,abcdef,每个字母代表一个bit。
为了能够达到检错纠错的功能,我需要给它们编一个码。
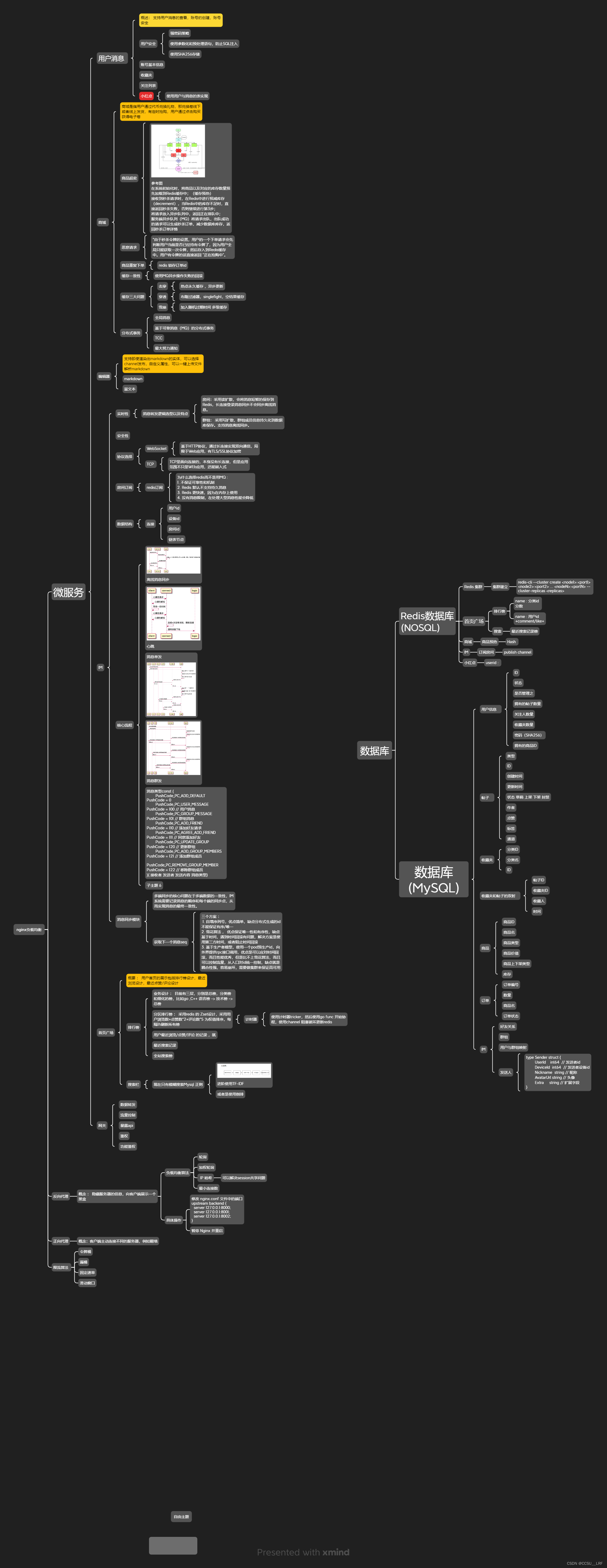
正常来说,编码是这样。
| 000 | 001 | 010 | 011 | 100 | 101 |
| a | b | c | d | e | f |
如果某个位错了,我希望有个3bit error code告诉我。比如,传输过程中,a错了,我需要一个error code,它的值是000,如果c错了,error code这个值又变成了010。
显然,我需要一个3bit code。
Ok,接下来要想一个办法,让3bit error code可以正确指示error bit的位置。
假设c错了,因为是二进制数,所以c错的时候,c会是c的取反。例如,c原数据是0,错了之后,只会是1。
那么要有一种运算,这种运算在bit取反时,它算出的结果也要变化,这样才能指示。异或0或者异或1就是这样一种运算。
C xor 0 = C,C出错时,运算结果也会跟着翻转。
那么根据上表,我发现一个规律,当b、d、f出错时,我认为Error_code[0]要为1,否则为0.
设计一个P0=b^d^f。
Error_code[0]=P0^B^D^F
b、d、f是发送端的原数据,P是由原数据计算得到的。Error_code[0]这里是接收端的B、D、F计算的。传输未出错时,B=b,d=D,f=F,那么Error_code[0]=0。假设b传输出错了,B=~b。那么Error_code[0]计算结果就会是1.
按照上述思路,P1=c^d
Error_code[1]=P1^C^D.
P2=e^f
Error_code[2]=P2^E^F.
这样做下来,发现b、c、d、e、f出错时,是可以指示出来。
但明显的,这里会有2个问题:
- a没办法指示出来。
- P0、P1、P2也要传输。
- P0、P1、P2本身也可能在传输过程中出错。
为了解决第一个问题,可以重新编码,将000编码去掉。
| 001 | 010 | 011 | 100 | 101 | 110 |
| a | b | c | d | e | f |
这样看起来就可以解决了。
然后要解决第2个问题。
| 001 | 010 | 011 | 100 | 101 | 110 |
|
|
|
| a | b | c | d | e | f | P0 | P1 | P2 |
解决的时候发现,数据超过3bit编码标准了,所以,编码要变成4bit,对应的P也要多加一个P3.
| 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 |
| a | b | c | d | e | f | P0 | P1 | P2 | P3 |
这样编码会发现,很奇怪的,因为P不能异或其他的P,不然会嵌套,
然后,P0出错时,Error_code只会等于0001,
P1出错时,Error_code只会等于0010,
P2出错时,Error_code只会等于0100,
P3出错时,Error_code只会等于1000,
这样,Pn所放置的位置就只能先固定下来。
| 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 |
| P0 | P1 |
| P2 |
|
|
| P3 |
|
|
然后,其他数据可以按顺序或者其他方式去放。
| 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 |
| P0 | P1 | a | P2 | b | c | d | P3 | e | f |
总结
在我看来,汉明码是一种既满足的汉明距离大于等于3的编码方式,又满足以校验信息就可以定位错误bit位置的编码,它这2个很实用的特点,使他成为了最受欢迎的纠错方式之一。
目前很多存储设备都还是使用ECC去增强存储电路的可靠性。
参考文献
https://en.wikipedia.org/wiki/Hamming_code#[7,4]_Hamming_code
【精选】最小汉明码距和数据编码的纠错能力的关系_最小汉明距离计算纠错能力-CSDN博客