文章目录
- 前言
- 一、目录项简介
- 二、struct dentry
- 2.1 简介
- 2.2 dentry和inode关联
- 2.3 目录项状态
- 2.4 目录项特点
- 三、dentry cache
- 3.1 简介
- 3.2 dentry cache 初始化
- 3.3 dentry cache 查看
- 四、dentry与mount、file的关联
- 五、其他
- 参考资料
前言
这两篇文章介绍了:
VFS 之 struct file:Linux文件系统 struct file 结构体解析
VFS 之 struct inode:Linux文件系统 struct inode 结构体解析
接下来介绍 VFS 之 struct dentry。
虚拟文件系统(Virtual File System,VFS),也被称为Virtual Filesystem Switch,是 Linux 内核中的一个软件层,为用户空间程序提供了文件系统接口。它还在内核中提供了一个抽象层,允许不同的文件系统实现共存。
VFS 通过抽象底层文件系统,为用户空间程序提供了一组统一的系统调用接口,例如 open()、stat()、read()、write()、chmod() 等,用于进行文件操作。
当一个用户空间进程调用诸如 open(2)、stat(2)、read(2)、write(2)、chmod(2) 等系统调用时,它是在进程上下文中执行的。这些系统调用用于执行与文件相关的操作,最终由内核中的 VFS 层处理。
VFS 接收来自进程上下文的这些系统调用,解释并将实际的文件系统特定操作委托给相应的文件系统实现。VFS 为应用程序提供了一个一致的接口,无论使用的底层文件系统是什么,都可以以统一的方式进行文件操作。
VFS 在内核中充当了一个中间层,它隐藏了底层文件系统的细节,提供了一个统一的文件系统接口给用户空间程序使用。这样,应用程序可以通过调用相同的系统调用来访问不同的文件系统,而不需要关心底层文件系统的具体细节。
一、目录项简介
在 Linux 的虚拟文件系统(VFS)中,实现了诸如 open()、stat()、chmod() 等系统调用。这些系统调用的路径名参数被 VFS 用于通过目录项缓存(也称为 dentry 缓存或 dcache)进行查找。目录项缓存提供了一种非常快速的查找机制,将路径名(文件名)转换为特定的目录项(dentry)。目录项存储在 RAM 中,不会保存到磁盘上,它们存在的唯一目的是为了提高性能。
目录项缓存被设计为对整个文件空间的视图。由于大多数计算机无法同时容纳所有的目录项,缓存中可能会缺少一些部分。为了将路径名解析为目录项,VFS 可能需要在路径上创建新的目录项,并加载相应的 i-node。这是通过查找 i-node 来完成的。
当一个进程调用诸如 open()、stat()、chmod() 等系统调用时,VFS 首先会在目录项缓存中查找相应的目录项(dentry)。如果找到了对应的目录项,VFS 将使用该目录项来获取文件的 i-node,并执行相应的文件操作。如果目录项不在缓存中,VFS 将根据路径名逐级查找并创建相应的目录项,然后加载相应的 i-node。
目录项缓存(dcache)的存在使得文件的访问更加高效。它允许系统在查找文件时避免频繁的磁盘访问,而是通过在缓存中进行查找和操作来提高性能。目录项缓存的设计目标是减少对磁盘的访问,加快文件系统操作的速度。
目录项对象(struct dentry):目录项对象代表文件系统中的目录项,也就是文件或目录的条目。它包含了文件名、inode指针、父目录等信息。目录项对象构成了文件系统的树状结构,用于表示文件系统中的文件和目录之间的层次关系。目录项对象是VFS中非常重要的数据结构,它允许内核高效地进行路径解析和文件查找操作。
每个目录项对象代表了路径中的一个特定部分。
比如路径:/home/xiaoming/c_dir/test.c:
其中 /、home、xiaoming、c_dir和test.c都属于目录项对象。/、home、xiaoming、c_dir属于目录,test.c属于普通的文件。因此在路径中。每一部分都是目录项对象,每一部分也都存在一个索引节点对象。
VFS在执行目录操作时(如果有需要)会现场创建目录项对象。在文件路径查找时,对于路径中的每一个部分都会为其创建一个目录项对象,目录项对象将路径中的每一部分与其相应的索引节点相关联。
事实上,dentry属于所有文件系统对象,包括目录、常规文件、符号链接、块设备文件、字符设备文件等,反映的是文件系统对象在内核中所在文件系统树中的位置。
目录项对象刚开始在内存构造时,要从磁盘的目录项读入相关地数据,比如ext4文件系统:
// linux-5.4.18/fs/ext4/ext4.h
/*
* The new version of the directory entry. Since EXT4 structures are
* stored in intel byte order, and the name_len field could never be
* bigger than 255 chars, it's safe to reclaim the extra byte for the
* file_type field.
*/
struct ext4_dir_entry_2 {
__le32 inode; /* Inode number */
__le16 rec_len; /* Directory entry length */
__u8 name_len; /* Name length */
__u8 file_type;
char name[EXT4_NAME_LEN]; /* File name */
};
二、struct dentry
2.1 简介
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
union {
struct list_head d_lru; /* LRU list */
wait_queue_head_t *d_wait; /* in-lookup ones only */
};
struct list_head d_child; /* child of parent list */
struct list_head d_subdirs; /* our children */
/*
* d_alias and d_rcu can share memory
*/
union {
struct hlist_node d_alias; /* inode alias list */
struct hlist_bl_node d_in_lookup_hash; /* only for in-lookup ones */
struct rcu_head d_rcu;
} d_u;
} __randomize_layout;
各个dentry实例组成了一个网络,与文件系统的结构形成一定的映射关系。与给定目录下的所有文件和子目录相关联的dentry实例,都归入到d_subdirs链表(在目录对应的dentry实例中)。子结点的d_child成员充当链表元素。
但其中并非完全映射文件系统的拓扑结构,因为dentry缓存只包含文件系统结构的一小部分。最常用文件和目录对应的目录项才保存在内存中。原则上,可以为所有文件系统对象都生成dentry项,但物理内存空间和性能原因都限制了这样做。
dentry结构的主要用途是建立文件名和相关的inode之间的关联,结构中有3个成员用于该目的:
(1) d_inode是指向相关的inode实例的指针。如果dentry对象是为一个不存在的文件名建立的,则d_inode为NULL指针。这有助于加速查找不存在的文件名,通常情况下,这与查找实际存在的文件名同样耗时。
(2) d_name指定了文件的名称。qstr是一个内核字符串的包装器。它存储了实际的char *字符串以及字符串长度和散列值,这使得更容易处理查找工作。这里并不存储绝对路径,只有路径的最后一个分量,例如对/usr/bin/emacs只存储emacs,因为上述链表结构已经映射了目录结构。
/*
* "quick string" -- eases parameter passing, but more importantly
* saves "metadata" about the string (ie length and the hash).
*
* hash comes first so it snuggles against d_parent in the
* dentry.
*/
struct qstr {
union {
struct {
HASH_LEN_DECLARE;
};
u64 hash_len;
};
const unsigned char *name;
};
用于表示"quick string",即快速字符串。它用于方便地传递参数,并且更重要的是保存字符串的"元数据"(例如长度和哈希值)。
结构体的定义包括以下字段:
hash_len:这是一个64位的联合体(union),包含了字符串的哈希值和长度。哈希值和长度共享相同的内存空间,以节省内存。
name:这是一个指向无符号字符(unsigned char)的指针,指向实际的字符串数据。
struct qstr的设计目的是提供一个轻量级的字符串表示形式,同时包含相关的元数据,如哈希值和长度。通过将哈希值和长度与字符串指针一起存储,可以更方便地传递字符串参数,并执行需要同时使用字符串数据和元数据的操作。
(3) 如果文件名只由少量字符组成,则保存在d_iname中,而不是dname中,以加速访问。
字段说明:
d_flags:目录项的标志位,用于标识目录项的状态和属性。
d_seq:用于实现读-复制更新(RCU)机制的序列计数器,用于保护目录项的访问。
d_hash:用于在哈希表中进行目录项的快速查找。除根dentry以外,所有dentry加入到一个dentry_hashtable全局哈希表中,其哈希项的索引计算基于父dentry描述符的地址以及它的文件名哈希值。因此,这个哈希表的作用就是方便查找给定目录下的文件。
static struct hlist_bl_head *dentry_hashtable __read_mostly;
哈希表 dentry_hashtable:dcache 中的所有 dentry 对象都通过 d_hash 指针链到相应的 dentry 哈希链表中;
d_parent:指向父目录的目录项。指向当前结点父目录的dentry实例,当前的dentry实例即位于父目录的d_subdirs链表中。对于根目录(没有父目录),d_parent指向其自身的dentry实例。
d_name:目录项的名称,以struct qstr结构体表示,包含了名称的字符串和长度等信息。
d_inode:指向与目录项关联的索引节点(inode),表示该目录项所对应的文件或目录。
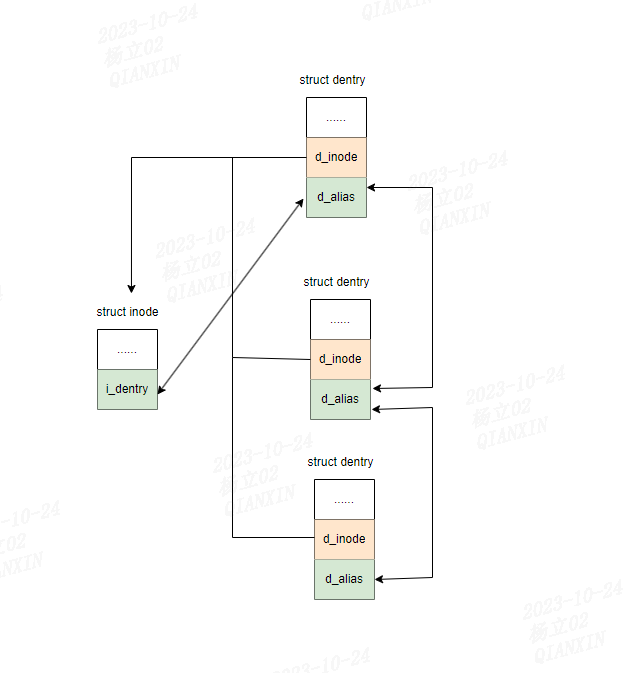
一个目录项对象对应一个索引节点对象。但一个索引节点对象可以对象多个目录项对象。
因为inode反映的是文件系统对象的元数据,而dentry则表示文件系统对象在文件系统树中的位置。dentry和inode是多对一的关系。每个dentry只有一个inode,由d_inode指向;而一个inode可能对应多个dentry(例如硬链接),它将这些dentry组成以i_dentry的链表,每个dentry通过d_alias加入到所属inode的i_dentry链表中。
d_iname:用于存储短名称(长度小于等于DNAME_INLINE_LEN)的内部缓冲区,避免动态分配内存。
d_lockref:这个字段结合了锁和引用计数,用于对目录项进行同步和引用计数,确保对目录项对象的并发访问的安全性。
struct lockref {
union {
#if USE_CMPXCHG_LOCKREF
aligned_u64 lock_count;
#endif
struct {
spinlock_t lock;
int count;
};
};
};
d_op:这个字段指向struct dentry_operations类型的结构体,其中包含了指向各种在目录项上执行的操作的函数指针。文件系统可以定义自己的一套目录项操作,以定制目录项的行为。
d_sb:这个字段指向与目录项相关联的超级块(superblock)。超级块代表文件系统的根,并提供与整个文件系统相关的信息和操作。d_sb是一个指针,指向dentry对象所属文件系统超级块的实例。该指针使得各个dentry实例散布到可用的(已装载的)文件系统。由于每个超级块结构都包含了一个指针,指向该文件系统装载点对应目录的dentry实例,因此dentry组成的树可以划分为几个子树。
d_time:这个字段用于缓存目的。它存储了目录项最后一次验证或访问的时间戳,用于dentry_operations中的d_revalidate操作。d_revalidate函数用d_time来做判断dentry是否还有效的依据。
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
}
d_revalidate对网络文件系统特别重要。它检查内存中的各个dentry对象构成的结构是否仍然能够反映当前文件系统中的情况。因为网络文件系统并不直接关联到内核/VFS,所有信息都必须通过网络连接收集,可能由于文件系统在存储端的改变,致使某些dentry不再有效。该函数用于确保一致性。
本地文件系统通常不会发生此类不一致情况,VFS对d_revalidate的默认实现什么都不做。
由于大多数文件系统都没有实现前述的这些函数,内核的惯例是这样:如果文件系统对每个函数提供的实现为NULL指针,则将其替换为VFS的默认实现。
d_fsdata:这个字段用于存储与目录项相关的特定于文件系统的数据。文件系统可以利用这个字段存储特定于其实现的附加信息。
d_lru 和 d_wait:这些字段是一个联合体中的一部分,用于在目录项查找操作期间进行缓存和同步。d_lru字段用于在最近最少使用(LRU)列表中维护目录项,而d_wait字段用于查找操作期间的等待队列。
d_child 和 d_subdirs:这些字段用于维护目录树中父目录和子目录之间的关系。d_child字段是一个list_head,将目录项链接到其父目录的子目录列表,而d_subdirs字段是一个list_head,将目录项链接到其子目录的列表中。
d_alias 和 d_in_lookup_hash:这些字段是一个联合体中的一部分,根据上下文的不同用于不同的目的。
d_alias字段用于链接表示相同索引节点(inode)的目录项别名。d_alias用作链表元素,以连接表示相同文件的各个dentry对象。在利用硬链接用两个不同名称表示同一文件时,会发生这种情况。对应于文件的inode的i_dentry成员用作该链表的表头。各个dentry对象通过d_alias连接到该链表中。
一个目录项对象对应一个索引节点对象,但一个索引节点对象可以对应多个目录项对象。
d_in_lookup_hash字段在查找操作期间用于in-lookup目录项,以提高查找性能。
d_rcu:这个字段与RCU机制结合使用,用于安全地管理和删除目录项的内存。它是struct rcu_head结构体的一个成员,在优雅期(grace period)后可以安全地释放目录项。
2.2 dentry和inode关联
struct dentry {
......
struct inode *d_inode;
......
struct hlist_node d_alias; /* inode alias list */
......
}
d_inode是指向相关的inode实例的指针。
d_alias字段用于链接表示相同索引节点(inode)的目录项别名。d_alias用作链表元素,以连接表示相同文件的各个dentry对象。在利用硬链接用两个不同名称表示同一文件时,会发生这种情况。对应于文件的inode的i_dentry成员用作该链表的表头。各个dentry对象通过d_alias连接到该链表中。
struct inode {
......
struct hlist_head i_dentry;
......
}
硬链接可以让一个inode(一个文件)会对应多个目录项,i_dentry用于管理该inode的多个目录项。i_dentry引用这个inode的dentry链表的表头。dentry结构的d_alias域链入到所属inode的i_dentry(别名)链表的“连接件”。
前面说过,一个目录项对象对应一个inode对象,但一个inode对象可以对应多个目录项对象(硬链接)。
如下图所示:
2.3 目录项状态
目录项对象有三种有效的状态:被使用,未被使用和负状态(无效的目录项)。
(1)被使用:一个被使用的目录项对应一个有效的索引节点(即d_inode指向对应的索引节点),并且表明该对象存在一个或多个使用(d_lockref.count为正值)。一个目录项处于被使用的状态,意味着它正在被VFS使用并且指向有效的数据,因此不能被丢弃。
(2)未被使用:一个未被使用的目录项对应一个有效的索引节点(即d_inode指向对应的索引节点),但是应指明VFS当前并未使用它(d_lockref.count为0)。该目录项对象仍然指向一个有效的对象,而且被保留在缓存中以便需要时在使用它。由于该目录项不会过早的被撤销,所以以后在需要它时,不必重新创建,与为缓存的目录项比,这样使路径查找更迅速。如果要回收内存,可以撤销未使用的目录项。
(3)负状态(无效的目录项):一个无效的目录项没有对应的有效索引节点(即d_inode指向NULL)。因此索引节点已被删除了,或者路径不在正确了,但目录项仍然保留,以便快速解析以后的路径查询。无效的目录项实际上很少用到,有必要可以撤回回收该目录项。
// linux-5.4.18/fs/dcache.c
static DEFINE_PER_CPU(long, nr_dentry);
static DEFINE_PER_CPU(long, nr_dentry_unused);
static DEFINE_PER_CPU(long, nr_dentry_negative);
#if defined(CONFIG_SYSCTL) && defined(CONFIG_PROC_FS)
/*
* Here we resort to our own counters instead of using generic per-cpu counters
* for consistency with what the vfs inode code does. We are expected to harvest
* better code and performance by having our own specialized counters.
*
* Please note that the loop is done over all possible CPUs, not over all online
* CPUs. The reason for this is that we don't want to play games with CPUs going
* on and off. If one of them goes off, we will just keep their counters.
*
* glommer: See cffbc8a for details, and if you ever intend to change this,
* please update all vfs counters to match.
*/
static long get_nr_dentry(void)
{
int i;
long sum = 0;
for_each_possible_cpu(i)
sum += per_cpu(nr_dentry, i);
return sum < 0 ? 0 : sum;
}
static long get_nr_dentry_unused(void)
{
int i;
long sum = 0;
for_each_possible_cpu(i)
sum += per_cpu(nr_dentry_unused, i);
return sum < 0 ? 0 : sum;
}
static long get_nr_dentry_negative(void)
{
int i;
long sum = 0;
for_each_possible_cpu(i)
sum += per_cpu(nr_dentry_negative, i);
return sum < 0 ? 0 : sum;
}
int proc_nr_dentry(struct ctl_table *table, int write, void __user *buffer,
size_t *lenp, loff_t *ppos)
{
dentry_stat.nr_dentry = get_nr_dentry();
dentry_stat.nr_unused = get_nr_dentry_unused();
dentry_stat.nr_negative = get_nr_dentry_negative();
return proc_doulongvec_minmax(table, write, buffer, lenp, ppos);
}
#endif
以上源码用来获取这三种状态目录项的数目。
#define D_FLAG_VERIFY(dentry,x) WARN_ON_ONCE(((dentry)->d_flags & (DCACHE_LRU_LIST | DCACHE_SHRINK_LIST)) != (x))
static void d_lru_add(struct dentry *dentry)
{
D_FLAG_VERIFY(dentry, 0);
dentry->d_flags |= DCACHE_LRU_LIST;
this_cpu_inc(nr_dentry_unused);
if (d_is_negative(dentry))
this_cpu_inc(nr_dentry_negative);
WARN_ON_ONCE(!list_lru_add(&dentry->d_sb->s_dentry_lru, &dentry->d_lru));
}
static void d_lru_del(struct dentry *dentry)
{
D_FLAG_VERIFY(dentry, DCACHE_LRU_LIST);
dentry->d_flags &= ~DCACHE_LRU_LIST;
this_cpu_dec(nr_dentry_unused);
if (d_is_negative(dentry))
this_cpu_dec(nr_dentry_negative);
WARN_ON_ONCE(!list_lru_del(&dentry->d_sb->s_dentry_lru, &dentry->d_lru));
}
d_lru_add 函数的实现。它将指定的 dentry 添加到 LRU 列表中。首先,通过调用 D_FLAG_VERIFY 宏验证 dentry 的标志位是否符合预期(应为 0)。然后,将 DCACHE_LRU_LIST 标志位设置到 dentry 的 d_flags 中,表示它已经在 LRU 列表中。接着,通过 this_cpu_inc 增加 nr_dentry_unused 计数器,表示未使用的 dentry 数量增加了。如果 dentry 是负面的(即表示一个不存在的目录项),则通过 this_cpu_inc 增加 nr_dentry_negative 计数器。最后,通过调用 list_lru_add 函数将 dentry 添加到与其所属的超级块 (d_sb) 相关联的 LRU 列表中。
d_lru_del 函数是 d_lru_add 函数的对应操作,用于从 LRU 列表中删除指定的 dentry。首先,通过调用 D_FLAG_VERIFY 宏验证 dentry 的标志位是否符合预期(应为 DCACHE_LRU_LIST)。然后,从 dentry 的 d_flags 中移除 DCACHE_LRU_LIST 标志位,表示它不再在 LRU 列表中。接着,通过 this_cpu_dec 减少 nr_dentry_unused 计数器,表示未使用的 dentry 数量减少了。如果 dentry 是负面的,则通过 this_cpu_dec 减少 nr_dentry_negative 计数器。最后,通过调用 list_lru_del 函数将 dentry 从与其所属的超级块 (d_sb) 相关联的 LRU 列表中删除。
这些函数用于在 Linux 内核中维护 dentry 的 LRU 列表,以便进行高效的缓存管理和回收。LRU 列表的目的是跟踪最近使用和未使用的 dentry,以优化文件系统的性能和资源利用。
static void d_shrink_del(struct dentry *dentry)
{
D_FLAG_VERIFY(dentry, DCACHE_SHRINK_LIST | DCACHE_LRU_LIST);
list_del_init(&dentry->d_lru);
dentry->d_flags &= ~(DCACHE_SHRINK_LIST | DCACHE_LRU_LIST);
this_cpu_dec(nr_dentry_unused);
}
static void d_shrink_add(struct dentry *dentry, struct list_head *list)
{
D_FLAG_VERIFY(dentry, 0);
list_add(&dentry->d_lru, list);
dentry->d_flags |= DCACHE_SHRINK_LIST | DCACHE_LRU_LIST;
this_cpu_inc(nr_dentry_unused);
}
收缩列表是用于释放不再使用的 dentry 资源的一种机制。当一个 dentry 不再被使用时,它可以从超级块的 LRU 列表中移除,并放入收缩列表中。通过将不再需要的 dentry 移动到收缩列表,可以更容易地进行资源回收,而不会影响超级块的 LRU 列表中的其他 dentry。
当 dentry 被添加到收缩列表时,会将 DCACHE_SHRINK_LIST 标志位设置到 dentry 的 d_flags 中。相反,当 dentry 从收缩列表中删除时,会从 dentry 的 d_flags 中移除 DCACHE_SHRINK_LIST 标志位。
这样,通过检查 dentry 的 d_flags 是否包含 DCACHE_SHRINK_LIST 标志位,就可以确定它当前是否位于收缩列表中。
d_shrink_del 函数用于从收缩列表中删除指定的 dentry。首先,通过调用 D_FLAG_VERIFY 宏验证 dentry 的标志位是否符合预期(应为 DCACHE_SHRINK_LIST 和 DCACHE_LRU_LIST)。然后,通过调用 list_del_init 函数将 dentry 从其所属的列表中删除并进行初始化。接着,从 dentry 的 d_flags 中移除 DCACHE_SHRINK_LIST 和 DCACHE_LRU_LIST 标志位,表示它不再在收缩列表和 LRU 列表中。最后,通过调用 this_cpu_dec 减少 nr_dentry_unused 计数器,表示未使用的 dentry 数量减少了。
d_shrink_add 函数用于将指定的 dentry 添加到收缩列表中。首先,通过调用 D_FLAG_VERIFY 宏验证 dentry 的标志位是否符合预期(应为 0)。然后,通过调用 list_add 函数将 dentry 添加到指定的列表中。接着,将 DCACHE_SHRINK_LIST 和 DCACHE_LRU_LIST 标志位设置到 dentry 的 d_flags 中,表示它同时存在于收缩列表和 LRU 列表中。最后,通过调用 this_cpu_inc 增加 nr_dentry_unused 计数器,表示未使用的 dentry 数量增加了。
这些函数用于在 Linux 内核中维护 dentry 的收缩列表,以便进行动态的缓存管理和回收。收缩列表是用于释放不再使用的 dentry 资源的一种机制。通过将不需要的 dentry 移动到收缩列表,可以将其与 LRU 列表分开处理,以更有效地回收资源。
2.4 目录项特点
(1)缓存:目录项对象通常在VFS层面被缓存,以提高性能。目录项缓存,也称为dcache,将最近访问的目录项缓存起来,避免频繁的磁盘访问。缓存可以加快目录结构的查找和遍历速度。
(2)基于名称的查找:目录项对象的主要作用是提供文件名和相应inode之间的映射关系。当使用文件路径访问文件时,内核通过遍历目录项对象的树状结构来进行基于名称的查找,以定位目标目录项对象。
(3)目录项操作:目录项对象支持与路径解析、文件查找和缓存相关的各种操作。这些操作包括查找(在给定目录中按名称查找目录项)、创建新目录项、失效(从缓存中移除目录项)和重新验证(确保缓存的目录项仍然有效)等。
(4)挂载点:目录项对象在处理Linux文件系统中的挂载点时起着关键作用。挂载点是目录层次结构中的位置,可以挂载不同的文件系统。在进行挂载操作时,会创建一个新的目录项对象来表示挂载点,并指向挂载的文件系统的根目录项。
(5)共享目录项:目录项可以在多个访问同一文件或目录的进程或线程之间共享。共享目录项可以减少内存消耗,并通过避免冗余的目录项分配和缓存提高性能。
(6)命名空间操作:目录项对象用于实现Linux的命名空间,提供进程隔离和资源分离。每个命名空间都有自己的目录项树,允许命名空间内的进程对文件系统层次结构具有不同的视图。
(7)生命周期管理:目录项对象具有引用计数,用于跟踪它们的使用情况。当一个目录项不再需要时,其引用计数减少,如果计数达到零,则释放该目录项。引用计数确保目录项被正确管理,并在不再使用时释放内存。
录项对象是Linux VFS层面的重要组成部分,实现了高效的文件查找、路径解析和缓存。
对于路径解析和文件查找的基本过程:
(1)路径解析:当用户提供一个文件路径时,内核需要解析该路径以定位目标文件。路径解析从根目录的目录项对象开始,逐级遍历目录项对象的树状结构,直到找到目标文件的目录项对象。
路径解析过程中的关键步骤如下:
从根目录的目录项对象开始。
根据路径中的每个目录名,在当前目录项对象的子目录中查找对应的目录项对象。
逐级向下遍历,直到找到路径中最后一个目录名对应的目录项对象。
如果路径中包含文件名,最后一级目录项对象中存储了该文件名对应的目录项对象。
(2)文件查找:一旦路径解析找到了目标文件的目录项对象,就可以通过该目录项对象中的inode指针获取文件的元数据信息,并执行相应的文件操作。文件查找的关键步骤如下:
获取路径解析得到的目标目录项对象。
从目标目录项对象的inode指针获取文件的inode对象。
通过inode对象获取文件的元数据信息,如文件大小、权限等。
根据文件的inode对象执行相应的文件操作,如读取、写入或执行等。
目录项对象的树状结构允许内核按照层次结构进行路径解析和文件查找操作,从而提供了高效的文件系统访问机制。通过遍历目录项对象的树,内核能够快速定位和访问文件系统中的目录和文件。同时,目录项对象的缓存机制可以进一步提高路径解析和文件查找的性能,避免频繁的磁盘访问。
三、dentry cache
3.1 简介
由于从磁盘读入一个目录项并构造对应的目录项对象需要花费大量的时间,所以,在完成对目录项对象的操作后,可能后面还会在使用它,因此仍然在内存中保存。
为了最大限度地提高处理这些目录项对象地效率,Linux使用目录项高速缓存,它由两种类型地数据结构组成:
(1)哈希表 dentry_hashtable:dcache 中的所有 dentry 对象都通过 d_hash 指针链到相应的 dentry 哈希链表中。
// linux-5.4.18/fs/dcache.c
static struct hlist_bl_head *dentry_hashtable __read_mostly;
static inline struct hlist_bl_head *d_hash(unsigned int hash)
{
return dentry_hashtable + (hash >> d_hash_shift);
}
(2)未使用的 dentry 对象链表 s_dentry_lru:dentry 对象通过其 d_lru 指针链入 LRU 链表中。LRU 的意思是最近最少使用,只要有它,就说明长时间不使用,就应该释放了。其中不再使用的对象将授予一个最后宽限期,宽限期过后才从内存移除。该链表包含了两种状态的目录项:未被使用和负状态(无效的目录项)。
哈希表 dentry_hashtable也包括了未使用的 dentry 对象,即 d_lru链表中地dentry 对象都在哈希表 dentry_hashtable中。
LRU链表的处理有一点技巧。该链表的表头是全局变量dentry_unused,包含的对象是struct dentry实例,使用的链表元素是struct dentry的d_lru成员。
在dentry对象的使用计数器(dentry->d_lockref.count)到达0时,会被置于LRU链表上,这表明没有什么应用程序正在使用该对象。新项总是置于该链表的起始处。换句话说,一项在链表中越靠后,它就越老,这是经典的LRU原理。即最后释放的目录项对象放在链表的首部,所以最近最少使用的目录项对象总是靠近LRU链表的尾部。一旦目录项高速缓存的空间变少(比如系统开始回收内存,就会回收page cache缓存),内核就从链表的尾部删除元素,是的最近最常使用的对象得以保留。
如下图所示:
 图片来自于:极客时间趣谈Linux操作系统
图片来自于:极客时间趣谈Linux操作系统
这两个列表之间会产生复杂的关系:
(1)引用为 0:一个在散列表中的 dentry 变成没有人引用了,就会被加到 LRU 表中去;
(2)再次被引用:一个在 LRU 表中的 dentry 再次被引用了,则从 LRU 表中移除;
(3)分配:当 dentry 在散列表中没有找到,则从 Slub 分配器中分配一个;
(4)过期归还:当 LRU 表中最长时间没有使用的 dentry 应该释放回 Slub 分配器;
(5)文件删除:文件被删除了,相应的 dentry 应该释放回 Slub 分配器;
(6)结构复用:当需要分配一个 dentry,但是无法分配新的,就从 LRU 表中取出一个来复用。
根据文件名查找目录项时,首先在 dentry cache缓存中查找,如果没有查找到就需要真的到文件系统里面去找了,查找的过程会创建一个新的 dentry,然后加入到dentry cache缓存以便下次查找。
与dentry cache相对应的还有inode cache ,inode cache为了加速VFS inode对象的查找,如下图所示:

图片来自于:极客时间Linux性能优化实战
3.2 dentry cache 初始化
// linux-5.4.18/init/main.c
start_kernel()
-->vfs_caches_init_early();
......
-->vfs_caches_init();
(1)
// linux-5.4.18/fs/dcache.c
static void __init dcache_init_early(void)
{
/* If hashes are distributed across NUMA nodes, defer
* hash allocation until vmalloc space is available.
*/
if (hashdist)
return;
dentry_hashtable =
alloc_large_system_hash("Dentry cache",
sizeof(struct hlist_bl_head),
dhash_entries,
13,
HASH_EARLY | HASH_ZERO,
&d_hash_shift,
NULL,
0,
0);
d_hash_shift = 32 - d_hash_shift;
}
void __init vfs_caches_init_early(void)
{
int i;
for (i = 0; i < ARRAY_SIZE(in_lookup_hashtable); i++)
INIT_HLIST_BL_HEAD(&in_lookup_hashtable[i]);
dcache_init_early();
inode_init_early();
}
(2)
// linux-5.4.18/fs/dcache.c
static void __init dcache_init(void)
{
/*
* A constructor could be added for stable state like the lists,
* but it is probably not worth it because of the cache nature
* of the dcache.
*/
dentry_cache = KMEM_CACHE_USERCOPY(dentry,
SLAB_RECLAIM_ACCOUNT|SLAB_PANIC|SLAB_MEM_SPREAD|SLAB_ACCOUNT,
d_iname);
/* Hash may have been set up in dcache_init_early */
if (!hashdist)
return;
dentry_hashtable =
alloc_large_system_hash("Dentry cache",
sizeof(struct hlist_bl_head),
dhash_entries,
13,
HASH_ZERO,
&d_hash_shift,
NULL,
0,
0);
d_hash_shift = 32 - d_hash_shift;
}
void __init vfs_caches_init(void)
{
names_cachep = kmem_cache_create_usercopy("names_cache", PATH_MAX, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, 0, PATH_MAX, NULL);
dcache_init();
inode_init();
files_init();
files_maxfiles_init();
mnt_init();
bdev_cache_init();
chrdev_init();
}
从源码中我们可以看到 dcache 和 icache 这两种缓存的初始化的都在/fs/dcache.c目录下。
因为dcache在一定意义上提供了对索引节点的缓存。和目录项对象相关的索引节点对象不会被释放,因为目录项会让相关索引节点的使用计数为正,这样就可以确保索引节点留在内存中了。只要目录项被缓存,其相应的索引节点也就被缓存。所以只要路径名在缓存中找到了,那么相应的索引节点肯定也在内存中缓存着。
因为文件访问呈现空间和时间的局部性,所以对目录项和索引节点进行缓存非常有益。文件访问有时间上的局部性,是因为程序可能一次又一次地访问相同地文件。因此,当一个文件被访问时,所缓存地相关目录项和索引节点在不久被命中地概率比较高。文件访问具有空间地局部性是因为程序可能在同一个目录下访问多个文件,因此对一个文件对应地目录项缓存后极有可能被命中,因为相关地文件可能在下次又被使用。
3.3 dentry cache 查看
查看/proc/slabinfo这个文件可以得到,所有目录项和各种文件系统索引节点的缓存情况:
# cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
mqueue_inode_cache 17 17 960 17 4 : tunables 0 0 0 : slabdata 1 1 0
fuse_inode 76 76 832 19 4 : tunables 0 0 0 : slabdata 4 4 0
ecryptfs_inode_cache 0 0 1024 16 4 : tunables 0 0 0 : slabdata 0 0 0
fat_inode_cache 40 40 792 20 4 : tunables 0 0 0 : slabdata 2 2 0
squashfs_inode_cache 4163 4163 704 23 4 : tunables 0 0 0 : slabdata 181 181 0
ext4_fc_dentry_update 0 0 96 42 1 : tunables 0 0 0 : slabdata 0 0 0
ext4_inode_cache 124356 124389 1192 27 8 : tunables 0 0 0 : slabdata 4607 4607 0
hugetlbfs_inode_cache 24 24 664 24 4 : tunables 0 0 0 : slabdata 1 1 0
sock_inode_cache 992 1140 832 19 4 : tunables 0 0 0 : slabdata 60 60 0
proc_inode_cache 5556 6003 712 23 4 : tunables 0 0 0 : slabdata 261 261 0
shmem_inode_cache 3664 3675 776 21 4 : tunables 0 0 0 : slabdata 175 175 0
inode_cache 35985 36150 640 25 4 : tunables 0 0 0 : slabdata 1446 1446 0
dentry 202794 202986 192 21 1 : tunables 0 0 0 : slabdata 9666 9666 0
使用 slabtop ,来找到占用内存最多的缓存类型。
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
$ slabtop
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
124389 124356 99% 1.16K 4607 27 147424K ext4_inode_cache
202986 202794 99% 0.19K 9666 21 38664K dentry
36150 35985 99% 0.62K 1446 25 23136K inode_cache
4256 4238 99% 4.00K 532 8 17024K kmalloc-4k
26852 26823 99% 0.57K 959 28 15344K radix_tree_node
182750 182574 99% 0.05K 2150 85 8600K shared_policy_node
62016 61565 99% 0.12K 1938 32 7752K kernfs_node_cache
33915 32818 96% 0.20K 1785 19 7140K vm_area_struct
68757 68757 100% 0.10K 1763 39 7052K buffer_head
765 601 78% 6.38K 153 5 4896K task_struct
2320 2301 99% 2.00K 145 16 4640K kmalloc-2k
6003 5556 92% 0.70K 261 23 4176K proc_inode_cache
7056 6839 96% 0.50K 441 16 3528K kmalloc-512
412 412 100% 8.00K 103 4 3296K kmalloc-8k
4163 4163 100% 0.69K 181 23 2896K squashfs_inode_cache
3675 3664 99% 0.76K 175 21 2800K shmem_inode_cache
14280 14172 99% 0.19K 680 21 2720K kmalloc-192
9840 9840 100% 0.25K 615 16 2460K kmalloc-256
9264 7659 82% 0.25K 579 16 2316K filp
......
可以看到目录项和索引节点占用了最多的Slab缓存。
四、dentry与mount、file的关联
// linux-5.4.18/include/linux/fs.h
struct file {
......
struct path f_path;
......
}
// linux-5.4.18/include/linux/path.h
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;
// linux-5.4.18/include/linux/mount.h
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
} __randomize_layout;
// linux-5.4.18/fs/mount.h
struct mount {
struct hlist_node mnt_hash;
struct mount *mnt_parent;
struct dentry *mnt_mountpoint;
struct vfsmount mnt;
......
}
我们假设根文件系统下面有一个目录 home,有另外一个文件系统 A 挂载在这个目录 home 下面。在文件系统 A 的根目录下面有另外一个文件夹 hello。由于文件系统 A 已经挂载到了目录 home 下面,所以我们就有了目录 /home/hello,然后有另外一个文件系统 B 挂载在 /home/hello 下面。在文件系统 B 的根目录下面有另外一个文件夹 world,在 world 下面有个文件夹 data。由于文件系统 B 已经挂载到了 /home/hello 下面,所以我们就有了目录 /home/hello/world/data。
为了维护这些关系,操作系统创建了这一系列数据结构。具体你可以看下面的图:
tu
图片来自于极客时间:趣谈Linux操作系统
文件系统是树形关系。
第一条线是最左边的向左斜的 dentry 斜线。每一个文件和文件夹都有 dentry,用于和 inode 关联。第二条线是最右面的向右斜的 mount 斜线,因为这个例子涉及两次文件系统的挂载,再加上启动的时候挂载的根文件系统,一共三个 mount。第三条线是中间的向右斜的 file 斜线,每个打开的文件都有一个 file 结构,它里面有两个变量,一个指向相应的 mount,一个指向相应的 dentry。
我们从最上面往下看。根目录 / 对应一个 dentry,根目录是在根文件系统上的,根文件系统是系统启动的时候挂载的,因而有一个 mount 结构。这个 mount 结构的 mount point 指针和 mount root 指针都是指向根目录的 dentry。根目录对应的 file 的两个指针,一个指向根目录的 dentry,一个指向根目录的挂载结构 mount。
我们再来看第二层。下一层目录 home 对应了两个 dentry,而且它们的 parent 都指向第一层的 dentry。这是为什么呢?这是因为文件系统 A 挂载到了这个目录下。这使得这个目录有两个用处。一方面,home 是根文件系统的一个挂载点;另一方面,home 是文件系统 A 的根目录。
因为还有一次挂载,因而又有了一个 mount 结构。这个 mount 结构的 mount point 指针指向作为挂载点的那个 dentry。mount root 指针指向作为根目录的那个 dentry,同时 parent 指针指向第一层的 mount 结构。home 对应的 file 的两个指针,一个指向文件系统 A 根目录的 dentry,一个指向文件系统 A 的挂载结构 mount。
我们再来看第三层。目录 hello 又挂载了一个文件系统 B,所以第三层的结构和第二层几乎一样。
接下来是第四层。目录 world 就是一个普通的目录。只要它的 dentry 的 parent 指针指向上一层就可以了。我们来看 world 对应的 file 结构。由于挂载点不变,还是指向第三层的 mount 结构。
接下来是第五层。对于文件 data,是一个普通的文件,它的 dentry 的 parent 指向第四层的 dentry。对于 data 对应的 file 结构,由于挂载点不变,还是指向第三层的 mount 结构。
五、其他
多个struct file 可以对应一个dentry,比如多个进程打开同一个文件,那么 struct file都是不同的,但是dentry对象和inode对象都是一样的,如下图所示:

一个绝对文件路径只会对应一个dentry。
一个inode可以对应多个dentry(比如硬链接)。
参考资料
Linux 5.4.18
https://static.lwn.net/kerneldoc/filesystems/vfs.html
https://blog.csdn.net/sydyh43/article/details/111058552
极客时间趣谈Linux操作系统
极客时间Linux性能优化实战







![[蓝桥双周赛]铺地砖](https://img-blog.csdnimg.cn/f09d2d6c6a824cc39b30b8b4cfbab1b9.png)