步骤一:
目标:*安装虚拟机,在自己虚拟机上完成hadoop的伪分布式安装。(安装完成后要检查)*
1)前期环境准备:(虚拟机、jdk、ssh)
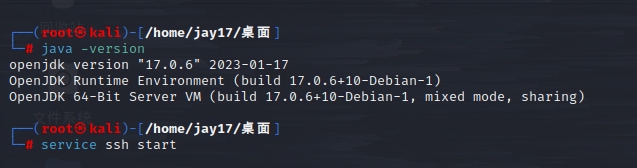
2)SSH相关配置
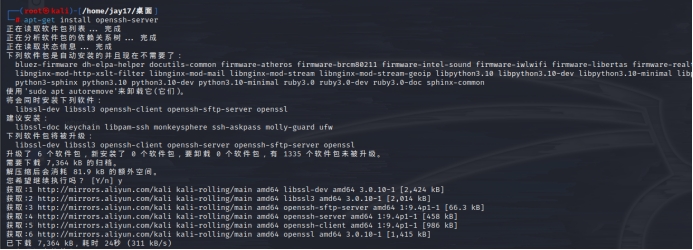
安装SSH Server服务器:apt-get install openssh-server
更改默认的SSH密钥
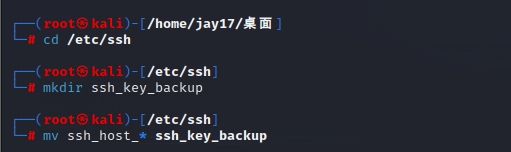
cd /etc/ssh
mkdir ssh_key_backup
mv ssh_host_* ssh_key_backup
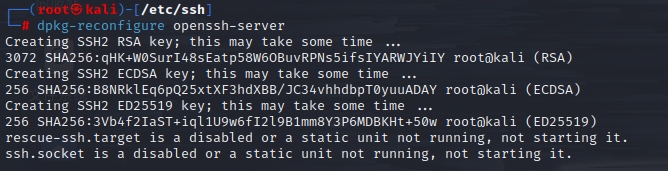
创建新密钥:dpkg-reconfigure openssh-server
允许 SSH Root 访问,修改SSH 配置文件 /etc/ssh/sshd_config :vim /etc/ssh/sshd_config

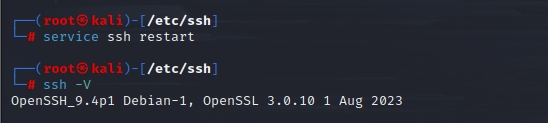
重启SSH:service ssh restart
查看是否安装成功:ssh -V
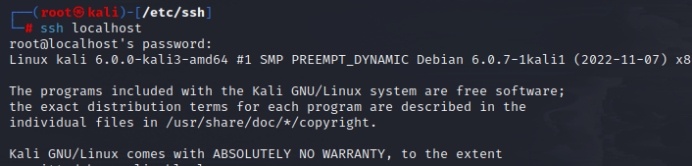
SSH登录本机:ssh localhost
若是登陆失败提示权限不足:
sudo passwd root 注意此处的root为当前登录本机所在的用户名,不一定是root
sudo service ssh restart
ssh localhost
SSH无密登录:
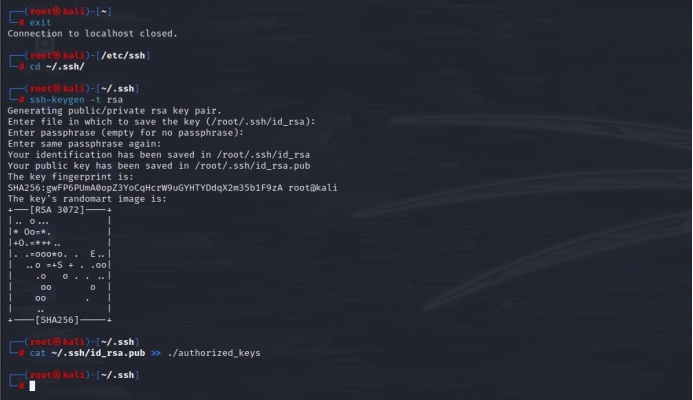
退出刚才的ssh localhost:exit
cd ~/.ssh/
ssh-keygen -t rsa 这里一直回车就行
cat ~/.ssh/id_rsa.pub >> ./authorized_keys
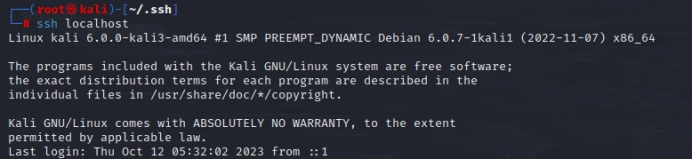
最后,SSH授权完成,再次ssh localhost 则不再需要密码了,也不再影响伪分布hadoop启动。
3)安装Hadoop
首先在官网上下载压缩包(版本3.2.2)。然后将压缩包拖进自己喜欢的目录(个人是/home/jay17)。
1、之后创建一个空的文件夹,用来解压hadoop
mkdir /home/Hadoop
2、解压,-C 指定解压路径到创建的文件夹路径。
tar zxvf hadoop-3.2.2.tar.gz -C /home/jay17/Hadoop/
3、授权,使文件夹具有读写文件的权利,否则直接影响其他相关操作,必须要执行!!
chown -R root /home/jay17/Hadoop/hadoop-3.2.2/
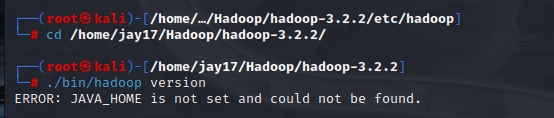
4、检测Hadoop是否解压安装正确:
cd /home/jay17/Hadoop/hadoop-3.2.2/
./bin/hadoop version
遇到报错说java环境变量不存在。
5、解决方法如下:
切换目录: cd etc/hadoop
执行:vim hadoop-env.sh
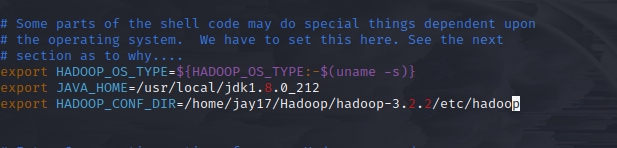
修改java_home路径和hadoop_conf_dir路径为具体的安装路径,例如:
export JAVA_HOME=/usr/local/jdk1.8.0_212
export HADOOP_CONF_DIR=/home/jay17/Hadoop/hadoop-3.2.2/etc/hadoop
重新加载使修改生效:source hadoop-env.sh
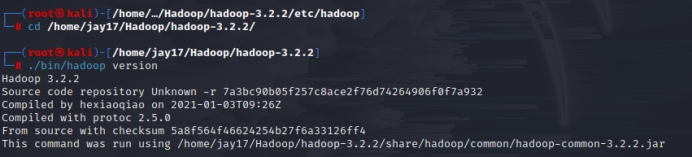
6、回去检测Hadoop,已经解压安装!
cd /home/jay17/Hadoop/hadoop-3.2.2/
./bin/hadoop version
4)配置Hadoop环境变量
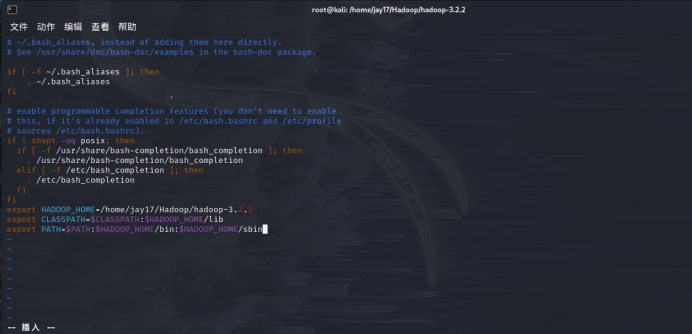
与java环境变量的配置类似,用编辑器打开.bashrc文件(vim /root/.bashrc),保存修改后,执行source /root/.bashrc命令使其生效:
export HADOOP_HOME=/home/jay17/Hadoop/hadoop-3.2.2
export CLASSPATH= C L A S S P A T H : CLASSPATH: CLASSPATH:HADOOP_HOME/lib
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并生效后,便可在任何路径下使用hadoop命令了,使用hadoop version命令验证。出现此前执行./bin/hadoop version命令时所出现的信息,则证明环境变量修改无误。

一定要确定写对后再执行生效,避免不必要的麻烦,如果操作不当,导致命令几乎失效的话,请执行该命令恢复:
export PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
5)伪分布模式配置
Hadoop的伪分布运行是指,同一个节点既是名称节点(Name Node),也是数据节点(Data Node),读取分布式文件系统HDFS的文件。安装不同模式Hadoop,就是修改其配置文件符合模式要求。
Hadoop有俩配置文件,一个是core-site.xml文件,另一个是hdfs-site.xml,其相对路径是在 hadoop-3.2.2/etc/hadoop/ 下。
首先,修改core-site.xml配置文件
vim /home/jay17/Hadoop/hadoop-3.2.2/etc/hadoop/core-site.xml
修改添加的内容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/jay17/Hadoop/hadoop-3.2.2/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
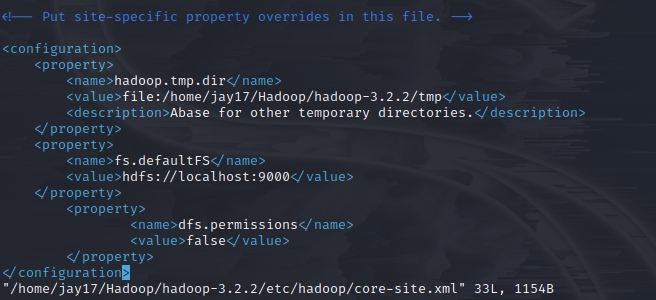
参数fs.defaultFS为默认文件系统名称,其值为Hadoop的Name Node地址和端口号,如hdfs://localhost:9000,即表示Name Node是本机,端口9000是HDFS的RPC端口,是HDFS的默认端口。
参数hadoop.tmp.dir用于确定Hadoop文件系统的原信息与数据保存在哪个目录下,是Hadoop文件系统依赖的基础配置,很多路径都依赖,如果hdfs-site.xml文件中不配置Name Node和Data Node的存放位置,默认放在此路径中。
参数dfs.permissions的值如果是true则检查权限,否则不检查权限(每个人都可以存取文件),该参数NameNode上设定。
其次,修改hdfs-site.xml配置文件
vim /home/jay17/Hadoop/hadoop-3.2.2/etc/hadoop/hdfs-site.xml
修改添加的内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/jay17/Hadoop/hadoop-3.2.2/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/jay17/Hadoop/hadoop-3.2.2/tmp/dfs/data</value>
</property>
</configuration>
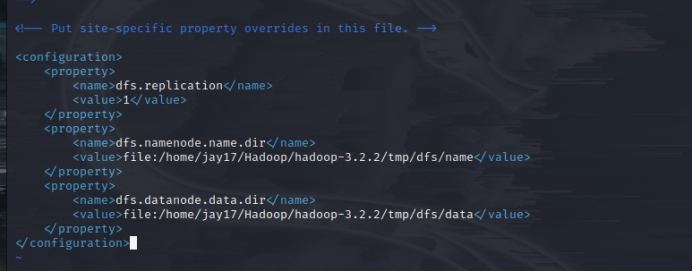
参数dfs.replication指明设置hdfs副本数,因为是伪分布模式,所以设置为“1”,默认备份3个副本。
参数dfs.namenode.name.dir 对应的value是存放名称节点的路径,参数dfs.datanode.data.dir 对应的value是存放数据节点的路径。这俩路径也可自行设置,但最好与临时文件路径一致,在初期实验时,遇到问题可以一并处理。
Hadoop的运行方式是由配置文件决定的,因为运行Hadoop时会读取配置文件,如果需要切换模式,只需要重新增加,删除或者修改core-site.xml和hdfs-site.xml文件中的配置项。
6)Name Node的格式化和hadoop启动关闭
配置完成,执行Name Node的格式化:(由于,hadoop生效了环境变量,所以在任何路径下均可执行。)
hdfs namenode -format
出现"successfully formatted"和"Exiting with status 0"的字样,则证明格式化成功!
start-dfs.sh只启动Name Node和Data Node,启动命令如下:
cd /home/jay17/Hadoop/hadoop-3.2.2
./sbin/start-dfs.sh
遇到以下报错请参考以下文章:
hadoop启动报错:Attempting to operate on hdfs namenode as root_hzp666的博客-CSDN博客
Hadoop单点安装FAQ-CSDN博客
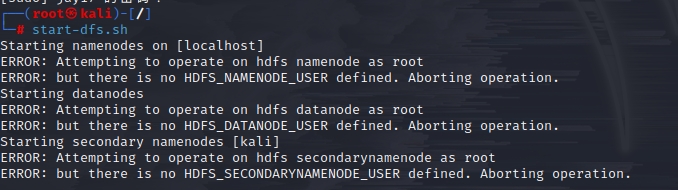
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER.-CSDN博客

查看进程命令:jps
起来四个进程如303108 DataNode 303012 NameNode 303453 Jps 303274 SecondaryNameNode就是正常的。
停止命令如下:
./sbin/stop-dfs.sh
所有命令连贯展示:
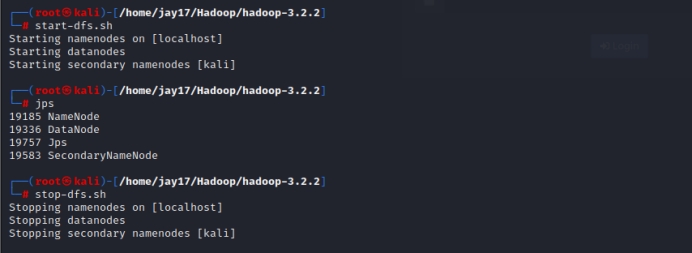
如果NameNode一直起不来,看看是不是端口冲突了,hadoop配置文件里面我们改的是9000端口,我的portainer(docker管理平台)也是9000端口,导致我因为NameNode起不来卡了好几天。。。。
步骤二:
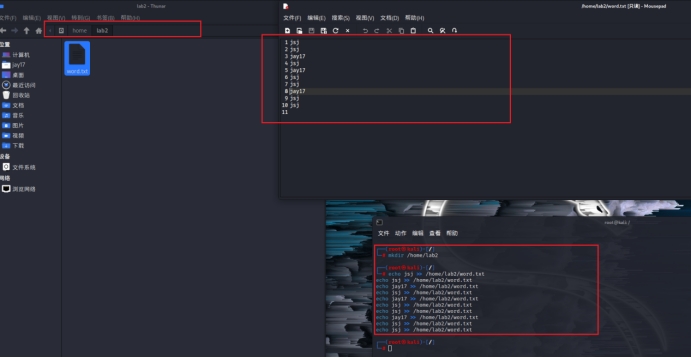
1)在hdp家目录下新建lab2目录,在lab2目录中新建word.txt,并在其中录入若干单词。
mkdir /home/lab2
echo jsj >> /home/lab2/word.txt
echo jsj >> /home/lab2/word.txt
echo jay17 >> /home/lab2/word.txt
echo jsj >> /home/lab2/word.txt
echo jay17 >> /home/lab2/word.txt
echo jsj >> /home/lab2/word.txt
echo jsj >> /home/lab2/word.txt
echo jay17 >> /home/lab2/word.txt
echo jsj >> /home/lab2/word.txt
echo jsj >> /home/lab2/word.txt
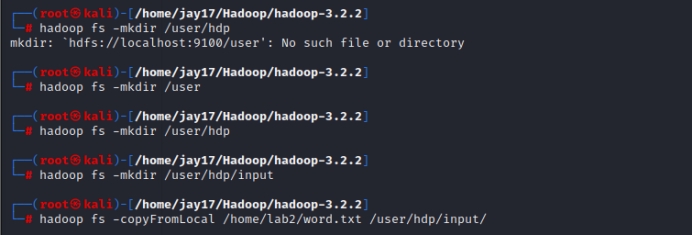
2)在HDFS的根目录下新建hdp用户目录/user/hdp目录,并在用户目录下新建input目录,将本地文件系统中的lab2目录中的word.txt文件上传到HDFS的input目录中。
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hdp
hadoop fs -mkdir /user/hdp/input
hadoop fs -copyFromLocal /home/lab2/word.txt /user/hdp/input/
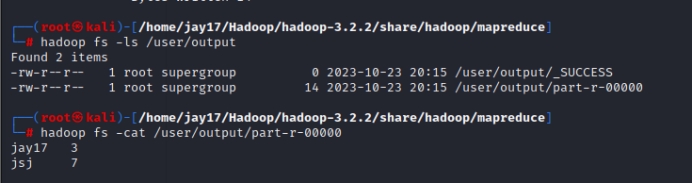
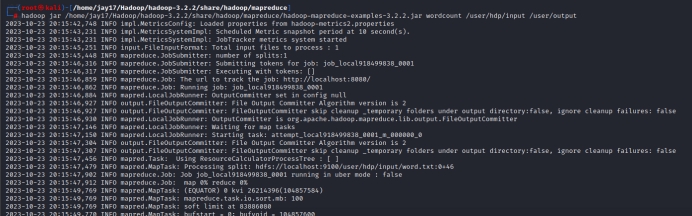
3)调用wordcount示例程序统计word.txt中的单词出现次数,将结果写入用户目录的output中,查看统计结果。
hadoop jar /home/jay17/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /user/hdp/input /user/output
Hadoop: 是$HADOOP_HOME/bin下的shell脚本名。
jar:hadoop脚本需要的command参数。
/home/jay17/Hadoop/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar :要执行的jar包在本地文件系统中的完整路径,参递给RunJar类。
wordcount :main方法所在的类,参递给RunJar类。
/user/hdp/input:传递给WordCount类,作为DFS文件系统的路径,指示输入数据来源。
/user/output:传递给WordCount类,作为DFS文件系统的路径,指示输出数据路径。
hadoop fs -ls /user/output
hadoop fs -cat /user/output/part-r-00000