目录
- 0. 简介
- 1. 获取交易数据
- 2. 数据库搭建
- 2.1. 数据库安装
- 2.2. 创建数据库
- 2.3. 创建超级表
- 2.4. 创建子表
- 3.数据导入
- 4. Grafana 安装
- 4.1. 安装Grafana
- 4.2. 安装TDengine插件
- 附件
- 数据导入脚本
- 历史交易数据-1分钟K线
0. 简介
-
Python:最常用的量化分析语言,不多说。
-
TDengine:时序数据库,存储历史交易数据。
虽然历史数据的存储用CSV文件、MySQL、PG等都可以,采用 TDengine 作为数据库,主要是考虑交易数据本质上是时序数据,TDengine 作为时序数据块,对时序数据的存储提供了较高的压缩率(比较谁家的磁盘都不赋予,有空间存点有意思的东西不更好),此外 TDengine 还提供了很多的分析函数,虽然在金融领域不如 DolphinDB,但是 DolphinDB 的语法有点让人望而却步,还是 SQL 用起来简单一些。 -
Grafana:绘图工具。Python 的 matplotlib 虽然功能强大,但是用法确实让人望而却步(后期还是要用的)。Grafana 主要用于监控领域,可以绘制非常丰富的图表,正好 TDengine 提供了 Granfana 插件,可以无缝结合。
1. 获取交易数据
这部分就不多说了,网上很多免费的历史数据,大部分是分钟级的。如果想要更多的数据或实时数据,最方便的渠道就是付费。
如果只是自己学习用,就无所谓了。我在本文最后有个网盘的链接,放了一些测试用的交易数据(数据质量不太好,仅供学习用)。
后期补充获取通过接口获取实时交易的方式。
2. 数据库搭建
2.1. 数据库安装
从官网下载最新的安装包,下载地址:
https://docs.taosdata.com/releases/tdengine/
安装很简单,解压缩,运行安装脚本即可。想了解详细安装步骤的可以参考我之前的文档:TDengine3.0 基础操作
注意:自己的主机名千万不能是localhost, 这是 TDengine 安装部署中最大的坑,千万别跳。
安装完成后启动服务:
systemctl start taosd
systemctl start taosadapter
因为我下面的程序使用的是 Restful 方式(不想下载TD的连接器了),因此需要启动 taosadapter 服务。
2.2. 创建数据库
自己学习用,不需要做什么优化,直接默认参数即可。执行 taos 进入操作界面。
create database trade_data_a wal_retention_period 0;
加上
WAL_RETENTION_PERIOD 0主要是为了能及时清理 WAL,也可以不加。
2.3. 创建超级表
相比MySQL、PG,TDengine 多了个超级表概念,可以方便的进行数据的聚合。相关介绍见官方文档:https://docs.taosdata.com/concept/
create stable tdata (tdate timestamp,open float,close float,high float,low float,cjl int,cje double,cjjj float) tags(fcode binary(6),fname nchar(20));
taos> describe tdata;
field | type | length | note |
=====================================================================================
tdate | TIMESTAMP | 8 | |
open | FLOAT | 4 | |
close | FLOAT | 4 | |
high | FLOAT | 4 | |
low | FLOAT | 4 | |
cjl | INT | 4 | |
cje | DOUBLE | 8 | |
cjjj | FLOAT | 4 | |
fcode | VARCHAR | 6 | TAG |
fname | NCHAR | 20 | TAG |
Query OK, 10 row(s) in set (0.004054s)
表结构说明:
| 列名 | 说明 |
|---|---|
| tdate | 交易时间 |
| open | 开盘价 |
| close | 收盘价 |
| high | 最高价 |
| low | 最低价 |
| cjl | 持仓量 |
| cje | 成交额 |
| cjjj | 成交均价 |
标签说明:
| 标签名 | 说明 |
|---|---|
| fcode | 股票代码 |
| fname | 股票名称 |
2.4. 创建子表
子表也是 TDengine 独有的概念,子表属于超级表,和超级表具有相同的表结构,通过标签来进行区分。
我设计是每只股票一个子表,表名称用 t_+股票代码 保证唯一性。标签有两个,分别是股票代码和股票名称。
由于子表数据比较多,使用脚本进行批量创建。
for ff in $(cat filelist)
do
fcode=$(echo $ff|awk -F '_' '{print $1}')
fname=$(echo $ff|awk -F '_' '{print $2}')
tbname=$(echo "t_${code}")
echo "create table trade_data_a.${tbname} using trade_data_a.tdata tags('${fcode}','${fname}')" >> create_tb.sql
done
taos -f create_tb.sql
说明:
- 示例数据都是每支股票单独一个CSV文件,文件名称为:股票代码_股票名称.csv
taos -f filename可以将sql 直接导入到数据库执行。
创建的子表如下:
taos> select distinct tbname,fcode,fname from tdata;
tbname | fcode | fname |
=============================================================================
t_000001 | 000001 | 平安银行 |
t_000004 | 000004 | ST国华 |
t_000009 | 000009 | 中国宝安 |
t_000014 | 000014 | 沙河股份 |
t_000017 | 000017 | 深中华A |
t_000019 | 000019 | 深粮控股 |
t_00001 | 00001 | 长和 |
t_000020 | 000020 | 深华发A |
t_000021 | 000021 | 深科技 |
t_000023 | 000023 | 深天地A |
t_000026 | 000026 | 飞亚达 |
t_000027 | 000027 | 深圳能源 |
t_000029 | 000029 | 深深房A |
t_000032 | 000032 | 深桑达A |
t_000034 | 000034 | 神州数码 |
t_000037 | 000037 | 深南电A |
t_000039 | 000039 | 中集集团 |
t_00003 | 00003 | 香港中华煤气 |
t_000045 | 000045 | 深纺织A |
t_000048 | 000048 | 京基智农 |
3.数据导入
测试数据是按照每只股票一个CSV文件分布的,例如平安银行数据如下:
code,tdate,open,close,high,low,cjl,cje,cjjj
000001,2023-02-01 09:30:00,15.03,15.03,15.03,15.03,3601.0,5412300.0,15.03
000001,2023-02-01 09:31:00,15.03,14.97,15.08,14.95,19919.0,2.98901E7,15.01
000001,2023-02-01 09:32:00,14.97,15.03,15.05,14.97,7600.0,1.14196E7,15.014
000001,2023-02-01 09:33:00,15.03,15.02,15.03,15.0,3767.0,5654120.0,15.013
000001,2023-02-01 09:34:00,15.01,15.01,15.02,15.0,5175.0,7767050.0,15.013
为了高效的写入数据,采用 TDengine 推荐的多进程+拼 SQL 方式写入(其实如果采用stmt方式,速度更快。不过需要安装taos客户端和taospy连接器)。
- 批量读取 CSV 文件
使用 Pandas 的read_csv函数将CSV文件导入 DataFrame 中。def csv_read(filename): print("Reading {} ......".format(filename)) data = pd.read_csv(filename,index_col=False,dtype={'code':str,'tdate':str,'open':float,'close':float,'high':float,'low':float,'cjl':int,'cje':float,'cjjj':float}) split_data(data) print("Import {} done!".format(filename)) - 将 CSV 导入数组,批量拼 SQL
为了高效写入,将多条数据拼接到一个SQL中,我设置了每2000条记录拼成1条SQL(TDengine 要求单条 SQL 不能超过1MB)。def export_sql(dbname,tbname,idata): exsql = 'insert into ' for index,row in idata.iterrows(): exsql = exsql + dbname +'.t_' + idata.loc[index,"code"] + ' values (' ts = int(time.mktime(time.strptime(idata.loc[index,"tdate"], "%Y-%m-%d %H:%M:%S"))*1000) exsql = exsql + str(ts) + ',' exsql = exsql + str(idata.loc[index,"open"]) + ',' exsql = exsql + str(idata.loc[index,"close"]) + ',' exsql = exsql + str(idata.loc[index,"high"]) + ',' exsql = exsql + str(idata.loc[index,"low"]) + ',' exsql = exsql + str(idata.loc[index,"cjl"]) + ',' exsql = exsql + str(idata.loc[index,"cje"]) + ',' exsql = exsql + str(idata.loc[index,"cjjj"]) + ') ' exsql = exsql + ';' return exsql - 通过 Restful 方式写入数据库
使用 Restful 方式写入数据,好处是不需要安装客户端和连接器,坏处就是写入效率没有那么高,数据库那边还需要启动taosadapter服务。def request_post(url, sql, user, pwd): try: sql = sql.encode("utf-8") headers = { 'Connection': 'keep-alive', 'Accept-Encoding': 'gzip, deflate, br' } result = requests.post(url, data=sql, auth=HTTPBasicAuth(user,pwd),headers=headers) text=result.content.decode() return text except Exception as e: print(e)
完整代码在本文最后。
脚本使用方法:
#进入数据目录
cd 202311
#生成文件列表
ls > file_list
#执行python脚本
python3 Imprort_csv.py
错误日志会写入当前文件夹的 import_error.log 日志文件中。
我导入了 8 个月的交易数据,占用空间 3GB 左右,看一下压缩率:
taos> show table distributed tdata\G;
*************************** 1.row ***************************
_block_dist: Total_Blocks=[202195] Total_Size=[3038805.57 KB] Average_size=[15.03 KB] Compression_Ratio=[22.58 %]
*************************** 2.row ***************************
_block_dist: Total_Rows=[344493995] Inmem_Rows=[15183] MinRows=[241] MaxRows=[2648] Average_Rows=[1703]
*************************** 3.row ***************************
_block_dist: Total_Tables=[9037] Total_Files=[52] Total_Vgroups=[2]
因为都是float类型,压缩率不是很高,大概压了1/5。TDengine 3.2 支持了float/double 的有损压缩,压缩率应该会更高,我现在用的是 3.1。
4. Grafana 安装
4.1. 安装Grafana
Grafana 安装直接参考官网即可。下载地址:https://grafana.com/grafana/download?edition=enterprise
sudo apt-get install -y adduser libfontconfig1 musl
wget https://dl.grafana.com/enterprise/release/grafana-enterprise_10.1.5_amd64.deb
sudo dpkg -i grafana-enterprise_10.1.5_amd64.deb
4.2. 安装TDengine插件
- 设置变量,因为我没有修改用户名、密码,且在数据库同一服务器上部署,设置变量如下:
export TDENGINE_TOKEN="Basic cm9vdDp0YW9zZGF0YQ=="
export TDENGINE_URL="http://localhost:6041"
- 下载安装脚本并安装。
bash -c "$(curl -fsSL https://raw.githubusercontent.com/taosdata/grafanaplugin/master/install.sh)"
- 重启 Grafana 服务
sudo systemctl restart grafana-server.service
-
配置数据源
以上脚本默认已经安装了数据源,如果需要添加新的数据源,可以参考官方文档 -
配置展示界面
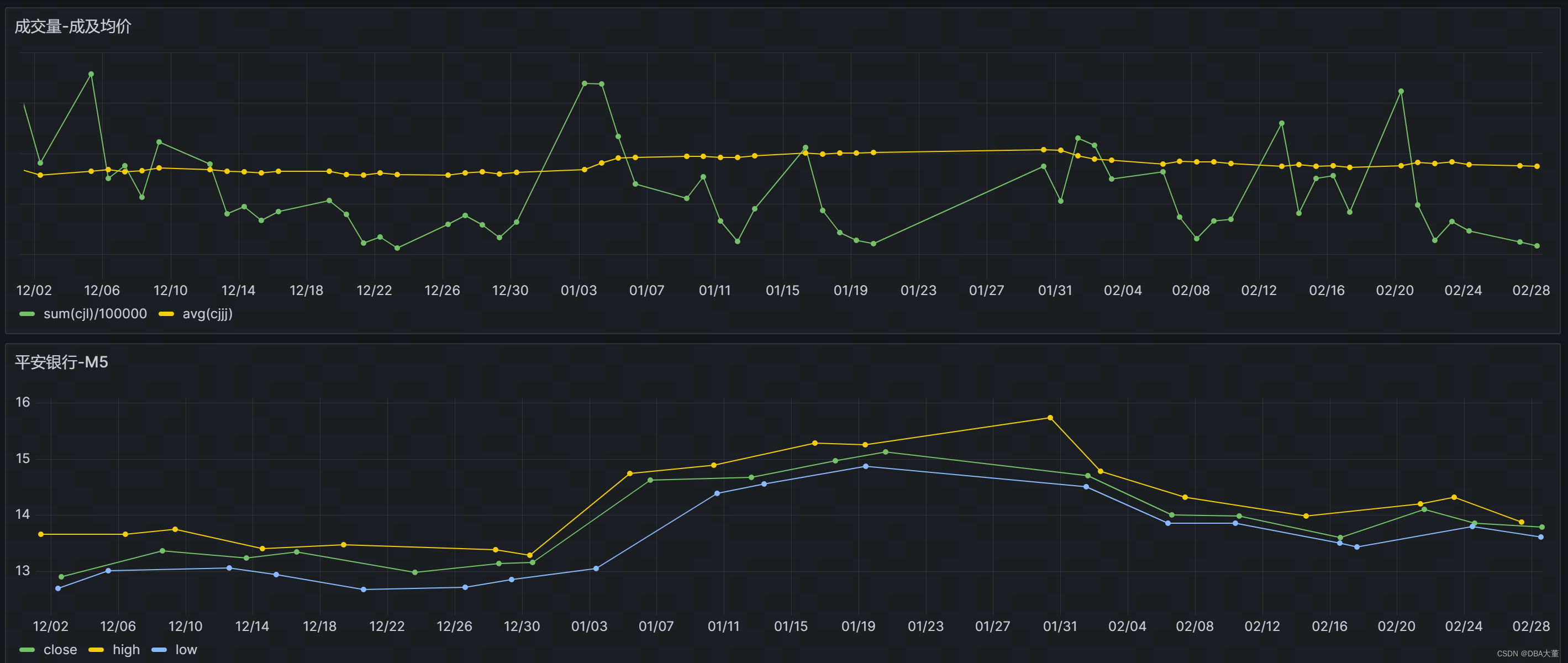
简单画两张图,验证一下系统联通性。
每日振幅:最高价-最低价
select _wstart,max(high)-min(low) from trade_data_a.tdata where fcode='000001' and tdate>=$from and tdate<$to interval(1d)

附件
数据导入脚本
链接:https://pan.baidu.com/s/1zqCCZjoXdgCPgrEaw67XOw
提取码:lnyu
历史交易数据-1分钟K线
链接:https://pan.baidu.com/s/1SUKhde7avpwQiJjH1olOyg
提取码:p4zv
数据来自网络,不保证准确性。
![[support2022@cock.li].faust、[tsai.shen@mailfence.com].faust勒索病毒数据怎么处理|数据解密恢复](https://img-blog.csdnimg.cn/533484f21558448a87465a7dc1e85625.png)