文章目录
- 概要
- CoordConv
- SAConv
概要
CoordConv(Coordinate Convolution)和SAConv(Spatial Attention Convolution)是两种用于神经网络中的特殊卷积操作,用于处理图像数据或其他多维数据。以下是它们的简要介绍:
CoordConv(Coordinate Convolution)
CoordConv 是由Uber AI Labs的研究人员提出的一种卷积操作,用于处理图像中的坐标信息。在传统的卷积操作中,卷积核在图像上滑动并执行卷积操作,但是它们对于图像中的位置信息是不敏感的。CoordConv 的目标是使卷积操作变得位置敏感,它在输入特征图中加入了位置信息作为额外的通道。这个位置信息可以是像素的坐标,也可以是归一化的坐标值,具体取决于应用的场景。
通过将坐标信息与输入特征图拼接在一起,CoordConv 能够帮助神经网络更好地学习到输入数据中的空间关系,从而提高模型的性能。它在需要考虑输入数据的空间位置信息时,特别有用。
SAConv(Spatial Attention Convolution)
SAConv 是一种引入了空间注意力机制的卷积操作。传统的卷积操作在所有位置都应用相同的卷积核,而SAConv 具有可学习的空间注意力权重,这意味着它能够动态地调整不同位置的卷积核权重。
SAConv 的关键思想是,在进行卷积操作之前,先计算每个位置的空间注意力权重。这些权重由神经网络学习得出,然后被用来加权输入特征图的不同位置,从而生成具有位置敏感性的特征表示。这种机制使得神经网络在处理输入数据时能够更加关注重要的区域,从而提高了模型的感知能力和性能。
总的来说,CoordConv 和 SAConv 都是为了增强神经网络对输入数据的空间信息处理能力而提出的方法。CoordConv 引入了位置信息通道,使得网络对位置信息更敏感,而 SAConv 引入了空间注意力机制,使得网络能够动态地调整卷积核的权重,提高了对不同位置信息的关注度。这两种方法在特定的任务和场景下都能够带来性能的提升。
CoordConv
common.py添加如下
class AddCoords(nn.Module):
def __init__(self, with_r=False):
super().__init__()
self.with_r = with_r
def forward(self, input_tensor):
"""
Args:
input_tensor: shape(batch, channel, x_dim, y_dim)
"""
batch_size, _, x_dim, y_dim = input_tensor.size()
xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1)
yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2)
xx_channel = xx_channel.float() / (x_dim - 1)
yy_channel = yy_channel.float() / (y_dim - 1)
xx_channel = xx_channel * 2 - 1
yy_channel = yy_channel * 2 - 1
xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
ret = torch.cat([
input_tensor,
xx_channel.type_as(input_tensor),
yy_channel.type_as(input_tensor)], dim=1)
if self.with_r:
rr = torch.sqrt(torch.pow(xx_channel.type_as(input_tensor) - 0.5, 2) + torch.pow(yy_channel.type_as(input_tensor) - 0.5, 2))
ret = torch.cat([ret, rr], dim=1)
return ret
class CoordConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, with_r=False):
super().__init__()
self.addcoords = AddCoords(with_r=with_r)
in_channels += 2
if with_r:
in_channels += 1
self.conv = Conv(in_channels, out_channels, k=kernel_size, s=stride)
def forward(self, x):
x = self.addcoords(x)
x = self.conv(x)
return x
在yolo.py

# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, CoordConv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, CoordConv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, CoordConv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, CoordConv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, CoordConv, [256, 3, 1]],
[88, 1, CoordConv, [512, 3, 1]],
[101, 1, CoordConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
SAConv
在common.py添加
class ConvAWS2d(nn.Conv2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias)
self.register_buffer('weight_gamma', torch.ones(self.out_channels, 1, 1, 1))
self.register_buffer('weight_beta', torch.zeros(self.out_channels, 1, 1, 1))
def _get_weight(self, weight):
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
weight = weight / std
weight = self.weight_gamma * weight + self.weight_beta
return weight
def forward(self, x):
weight = self._get_weight(self.weight)
return super()._conv_forward(x, weight, None)
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
self.weight_gamma.data.fill_(-1)
super()._load_from_state_dict(state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs)
if self.weight_gamma.data.mean() > 0:
return
weight = self.weight.data
weight_mean = weight.data.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
self.weight_beta.data.copy_(weight_mean)
std = torch.sqrt(weight.view(weight.size(0), -1).var(dim=1) + 1e-5).view(-1, 1, 1, 1)
self.weight_gamma.data.copy_(std)
class SAConv2d(ConvAWS2d):
def __init__(self,
in_channels,
out_channels,
kernel_size,
s=1,
p=None,
g=1,
d=1,
act=True,
bias=True):
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=s,
padding=autopad(kernel_size, p),
dilation=d,
groups=g,
bias=bias)
self.switch = torch.nn.Conv2d(
self.in_channels,
1,
kernel_size=1,
stride=s,
bias=True)
self.switch.weight.data.fill_(0)
self.switch.bias.data.fill_(1)
self.weight_diff = torch.nn.Parameter(torch.Tensor(self.weight.size()))
self.weight_diff.data.zero_()
self.pre_context = torch.nn.Conv2d(
self.in_channels,
self.in_channels,
kernel_size=1,
bias=True)
self.pre_context.weight.data.fill_(0)
self.pre_context.bias.data.fill_(0)
self.post_context = torch.nn.Conv2d(
self.out_channels,
self.out_channels,
kernel_size=1,
bias=True)
self.post_context.weight.data.fill_(0)
self.post_context.bias.data.fill_(0)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
# pre-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(x, output_size=1)
avg_x = self.pre_context(avg_x)
avg_x = avg_x.expand_as(x)
x = x + avg_x
# switch
avg_x = torch.nn.functional.pad(x, pad=(2, 2, 2, 2), mode="reflect")
avg_x = torch.nn.functional.avg_pool2d(avg_x, kernel_size=5, stride=1, padding=0)
switch = self.switch(avg_x)
# sac
weight = self._get_weight(self.weight)
out_s = super()._conv_forward(x, weight, None)
ori_p = self.padding
ori_d = self.dilation
self.padding = tuple(3 * p for p in self.padding)
self.dilation = tuple(3 * d for d in self.dilation)
weight = weight + self.weight_diff
out_l = super()._conv_forward(x, weight, None)
out = switch * out_s + (1 - switch) * out_l
self.padding = ori_p
self.dilation = ori_d
# post-context
avg_x = torch.nn.functional.adaptive_avg_pool2d(out, output_size=1)
avg_x = self.post_context(avg_x)
avg_x = avg_x.expand_as(out)
out = out + avg_x
return self.act(self.bn(out))
然后在yolo.py里面添加

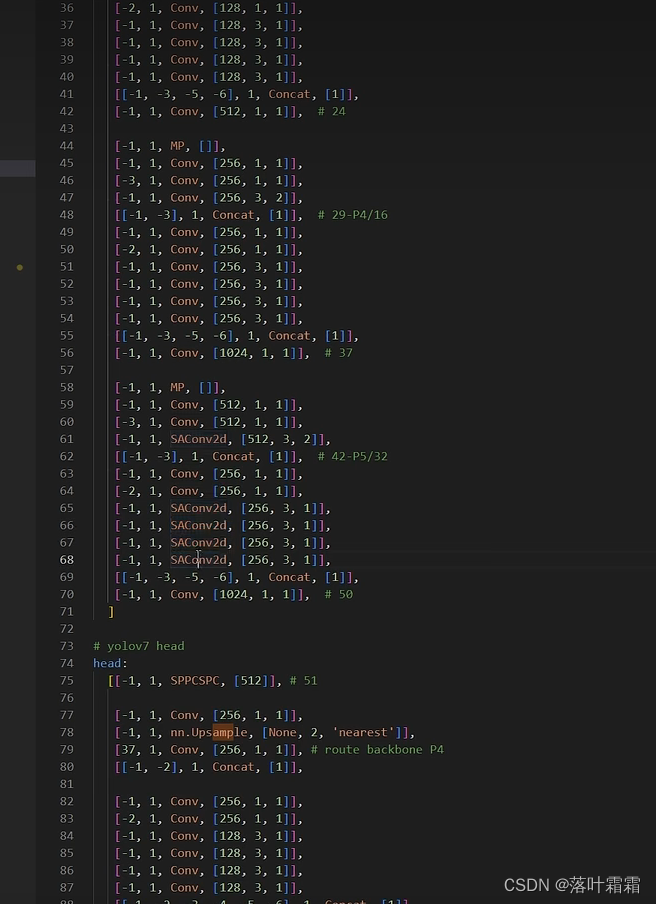
和可变形卷积加法一样,但是不建议加太多,也是只替换3x3卷积上面。比普通卷积复杂度高,不建议加太多,推理速度变慢,尽量少用,提高精度。