在这篇文章中,我们描述了一个小型射击游戏样本,它可以动画和渲染几个交互式对象。许多演示只针对高端pc,但这里的目标是在使用GLES 3.0的廉价手机上实现高帧率。这个例子使用了BatchRendererGroup, Burst编译器和c#作业系统。它运行在Unity 2022.3中,不需要实体或实体。图形DOTS包。
让我们开始吧。
介绍样本
让我们直接进入样本是什么。这个示例在2019年预算的三星Galaxy A51(使用Mali G72-MP3 GPU)上以稳定的60 fps运行。图形API设置为gles3.0。
u
您可以通过从GitHub下载该项目来研究代码并在您最喜欢的平台上试用。你只需要Unity 2022.3。
在这篇文章中,我们主要关注BatchRendererGroup和样例类BRG_Container.cs。你也可以在BRG_Background.cs和BRG_Debris.cs类中学习动画和物理代码。
场景设置
-
在深入研究如何制作它之前,让我们先探索一下我们所看到的。
-
背景地板由许多立方体构成。所有的盒子都可以上下移动。
-
主船在屏幕上水平移动,并向彩色球体发射导弹。(你可以通过点击屏幕更快地发射导弹。)
-
当一枚导弹飞过地板时,一个磁场会轻微提升并突出地板细胞。它还将地面碎片抛向空中。
-
当导弹击中球体时,它会爆炸成彩色碎片。
-
当碎片撞到地板上时,地板上的碰撞细胞会闪烁出白色。撞击细胞的碎片越多,细胞的颜色就越暗。此外,碎片的重量会在地面上造成凹痕。
Rendering
地板细胞和碎片都是由立方体构成的。每个立方体都有不同的位置和颜色。我们想要动画和管理一切使用CPU,使地板和碎片之间的相互作用更容易。(碎片不仅仅是一种美观的视觉效果,所以它不能只使用GPU。)
对于渲染,我们不会为每个道具创建一个GameObject,以避免在低端移动设备上造成不必要的性能冲击。相反,我们使用新引入的BatchRendererGroup API。
为什么不使用经典的Graphics.DrawMeshInstanced?
Graphics.DrawMeshInstanced是一种方便快捷的方法,可以在不同位置渲染许多相似的网格。然而,与BatchRendererGroup API相比,它有以下限制:
- 它需要提供带有矩阵的托管内存数组,因此您可能会获得垃圾收集。此外,反向矩阵是cpu计算的,即使着色器不需要它(例如,使用URP/unlit)。
- 如果你想自定义obj2world矩阵以外的任何属性(比如每个实例有一种颜色),你需要提供你自己的自定义着色器,要么从头开始编写,要么使用着色器图形。
- 矩阵或自定义数据必须在每次绘制时上传到GPU内存。你不能用Graphics.DrawMeshInstanced拥有持久的GPU内存数据。根据上下文的不同,这可能会对性能造成巨大影响。
什么是 BatchRendererGroup?
BatchRendererGroup(或BRG)是一个API,可以有效地从c#生成绘制命令并生成gpu实例化绘制调用。由于它不使用托管内存,您还可以使用Burst编译器生成命令。
| 优点 | 缺点 |
| 能够从突发作业中快速生成drawstance命令 | 你必须自己生成最优批次的绘制命令 |
| 使用持久的大型GPU缓冲区来存储每个实例的任何自定义属性 | 您必须自己管理GPU内存和自定义属性偏移分配 |
| 支持广泛的平台,包括OpenGLES 3.0及以上版本 | |
| 兼容标准的SRP着色器(点亮和未点亮)。不需要编写自定义着色器 |
提示: entities.graphics entities. graphics 包是用来渲染实体(ECS包),并建立在BRG之上。实体。软件包为您完成所有GPU内存管理和最佳绘制命令创建。在这个样本中我们没有使用ECS,所以我们将直接驱动BRG。
BRG着色器数据模型
BRG使用特定的GPU数据布局和专用的着色器变体。shader变体可以从标准常量缓冲区(UnityPerMaterial)或自定义的大型GPU缓冲区(BRG raw缓冲区)中获取数据。这是由你来管理你如何存储你的数据在原始缓冲区,这是一个Shader存储缓冲对象(SSBO,或字节地址缓冲区)。默认的BRG数据布局是数组结构(SoA)类型。
Properties per instance – or not
你可以实例化材料的任何属性,而不必创建自定义着色器。在这个示例中,我们希望实例化每个盒子实例的obj2world矩阵(用于定位立方体)、world2obj矩阵(用于照明)和BaseColor(因为每个地板单元或碎片都有自己的颜色)。
所有其他属性对于所有多维数据集都是相同的(例如,平滑度值),并且您可以使用元数据描述哪些属性将具有每个实例的自定义值。
BRG metadata
BRG元数据是一个可选的32位值,你可以设置每个着色器属性。它告诉着色器代码如何从GPU内存和从哪里加载属性值。第0-30位定义BRG原始缓冲区中属性的偏移量,第31位告诉我们属性值对于所有实例是相同的,还是偏移量是数组的开始,每个实例有一个值。
BRG元数据的确切含义也取决于着色器属性类型。让我们总结一下所有的可能性:
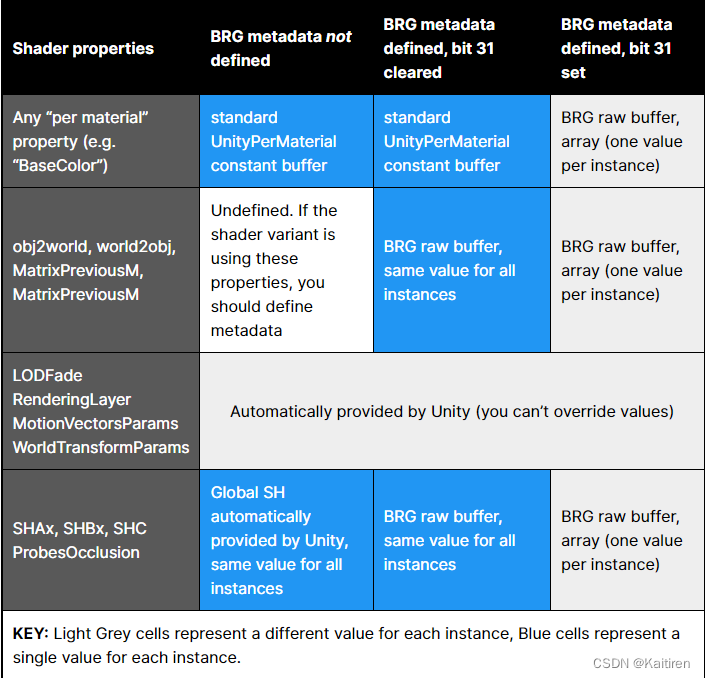
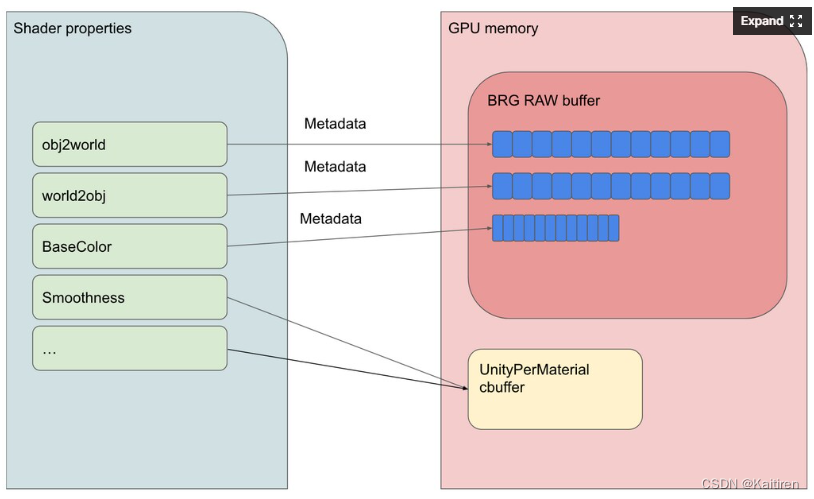
图1:使用BRG元数据,您可以描述每个实例中哪些属性具有自定义值(如obj2world、world2obj、baseColor)。所有其他属性对所有实例具有完全相同的值(并且仍然使用经典UnityPerMaterial cbuffer作为数据源)。
BRG剔除和能见度指数
不同的图形。drawmeshinstance, BRG使用一个持久的GPU内存缓冲区。假设在原始缓冲区中有10个立方体位置和颜色,但是只有立方体0、3和7是可见的。你只想画三个立方体,但你需要着色器正确读取这些立方体的位置和颜色。为了做到这一点,BRG着色器使用了一个小的额外间接。这个可见性缓冲区只是一个在生成绘制命令时填充的“int”数组。
在这个例子中,你需要用{0,3,7}填充一个包含三个整数的数组,然后生成一个包含三个实例的BRG绘制命令。
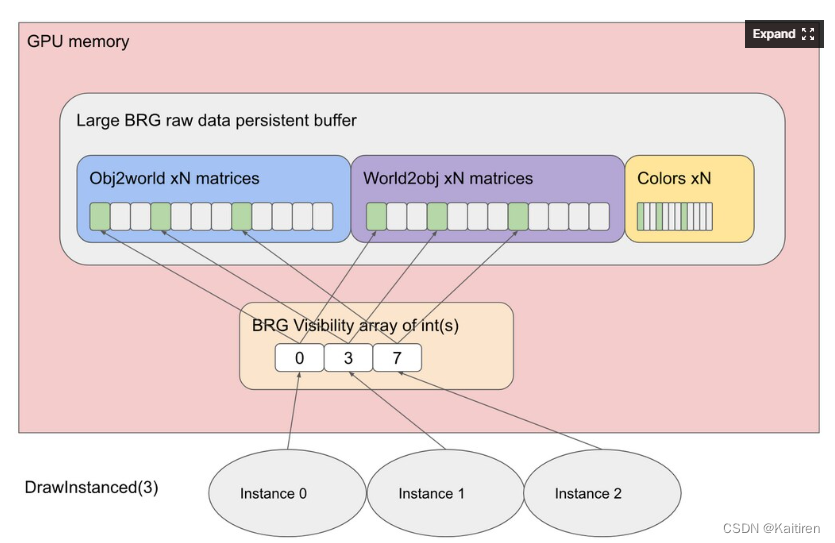
图2: BRG着色器变体总是使用可见性间接从持久原始缓冲区中获取数据。这个小的可见性间接缓冲可以根据你的需要为每一帧生成。
获取“baseColor”属性的着色器代码如下所示:
if ( metadata_baseColor&(1<<31) )
{
// get the real index from the visibility buffer indirection
int visibleId = brg_visibility_array[GPU_instanceId];
uint base = (metadata_baseColor&0x7ffffffc);
uint offset = visibleId * sizeof(baseColor);
// fetch data from a custom array in BRG raw buffer
baseColor = brg_raw_buffer.Load( base + offset );
}
else
{
// fetch data from UnityPerMaterial (as usual)
baseColor = UnityPerMaterial.baseColor;
}更进一步:因为你可以实例化SRP着色器的任何属性(unlit, simplelit, lit),所有材质属性都有一个“if元数据&(1<<31)”分支。即使您不需要为每个实例定制平滑度值,这也会带来一些性能成本。在这个示例中,我们只想实例化baseColor。你可以创建一个Shader Graph,其中只有颜色将被定义为BRG实例化。因此,生成的代码有大量的数据获取间接只有颜色属性。Shader应该在低端GPU上运行得稍微快一点。
Rendering floor cells
在我们的游戏样本中,地板由32x100个单元格构成,即3200个单元格。每个单元都有位置、高度和颜色,并且单元格在相机保持静止时滚动。当一行滚动出视图时,我们注入一个包含32个单元格的新行。

当整行滚动出视图时,将插入一行新的单元格。新单元使用随机的高度和颜色。您可以查看示例中的BRG_Background.InjectNewSlice()。
在任何时间点都有3,200个单元格,因此实际上没有必要进行剔除(所有单元格始终在相机的视图内)。要定位每个单元格,您需要每个单元格一个obj2world矩阵,照明的逆矩阵和一个颜色。要渲染完整的地板,我们将使用单个BRG绘制命令。
渲染爆炸碎片

所有的碎片都有简单的重力物理,并与地板细胞相互作用。一切都是使用Burst c#作业在CPU上运行的
样本的碎片由小立方体组成,每个立方体都有一个位置、颜色和垂直轴上的旋转。这与地板细胞非常相似。为此,我们创建了BRG_Container.cs。这个类管理一个BRG对象来渲染地板单元或爆炸碎片。所有的物理动画和交互都是用c#代码使用BRG_Debris.cs完成的。
与地板单元不同,整个框架的碎片数量各不相同。在初始化时,指定BRG_Container的最大条目数。在我们的样本中,碎片是16,384(每次爆炸由1,024个碎片立方体组成),我们使用异步作业来动画重力场中的碎片。当碎片撞击到地板细胞时,它会通过挖入地面来相互作用。
BRG matrix format
为了优化GPU内存存储和带宽,BRG使用float3x4而不是float4x4来存储矩阵。请记住,原始缓冲区中的BRG矩阵是48字节,而不是64字节。
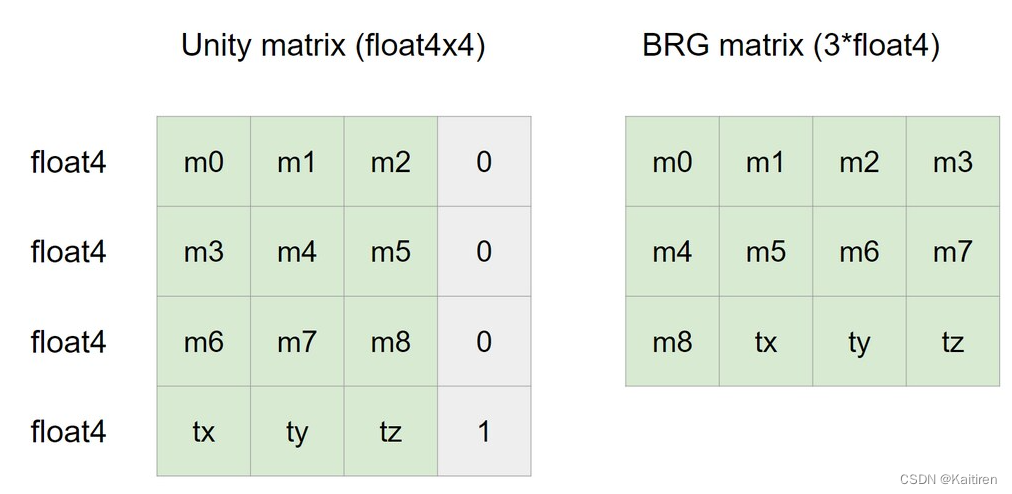
BRG矩阵仅为48字节(即三个float4),以提高GPU带宽
原始缓冲区看起来像这样:

图3:使用SoA布局,350kib的SSBO原始缓冲区包含3200个实例的数据。
提示: 碎片原始缓冲区数据看起来与地板数据相似,因为它也使用三个自定义属性(obj2world, world2obj和color)。碎片的最大条目数为16,384,这意味着原始缓冲区为112x16,384字节,即1.75 MiB。并不是所有的碎片在大多数情况下都会被渲染,这取决于给定时间存在的碎片立方体的数量。
Animating floor cells
我们有一个358,400字节的GPU GraphicsBuffer。由于动画是用CPU完成的,我们也在系统内存中分配了一个类似的缓冲区(CPU可以在系统内存中全速处理数据)。让我们将第二个缓冲区称为GPU内存的“影子副本”。c#代码将使地板单元格动画化,使用sin和来自阴影副本的碎片。动画完成后,我们使用GraphicsBuffer将阴影复制缓冲区上传到GPU - SetData API。
比示例更进一步: 优化GPU渲染通常意味着优化数据量。在我们的示例中,我们使用标准和库存SRP着色器。这就是为什么我们为矩阵使用三个float4,为颜色使用一个float4。你可以更进一步,编写一个自定义着色器来减少数据大小,或者你可以使用一个32位的地板单元格高度值。
如果你想继续,使用单元索引来计算它的世界位置,然后在着色器中计算矩阵和逆矩阵。最后,使用32位整数来存储颜色。最后,每个项目上传8字节而不是112字节。这使得GPU数据上传的速度提高了14倍。这意味着重写着色器获取代码。
BRG BatchID
任何BRG绘制命令都需要一个MeshID, MaterialID和BatchID。前两个很容易理解,但BatchID更微妙。可以将BatchID视为“某种批处理”。要渲染地板,需要注册一种批次,定义如下:
- “unity_ObjectToWorld”属性是一个从BRG原始缓冲区的偏移量0开始的数组;
- " unity_WorldToObject "属性是一个从偏移量153,600开始的数组;
- “_BaseColor”属性是一个数组,从偏移量307,200开始;
在创建时注册这种批处理的代码看起来类似于:
int objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
int worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
int colorID = Shader.PropertyToID("_BaseColor");
var batchMetadata = new NativeArray<MetadataValue>(3, Allocator.Temp, NativeArrayOptions.UninitializedMemory);
batchMetadata[0] = CreateMetadataValue(objectToWorldID, 0, true); // matrices
batchMetadata[1] = CreateMetadataValue(worldToObjectID, 3200*3*16, true); // inverse matrices
batchMetadata[2] = CreateMetadataValue(colorID, 3200*3*16*2, true); // colors
m_batchId = m_BatchRendererGroup.AddBatch(batchMetadata, m_GPUPersistentRawBuffer.bufferHandle, 0, 0);我们在创建时获得m_batchId,然后可以将其用于每个BRG绘制命令(因此着色器确切地知道如何为这种批处理获取数据)。
提示:BatchRendererGroup。AddBatch不是渲染命令。它用于注册一种批处理,用于将来的呈现命令。
The devil’s in the details: GLES exception
到目前为止,我们可以动画地板细胞,将阴影复制系统内存缓冲区上传到GPU,并使用3200个实例的单个DrawCommand渲染所有细胞。
这将在大多数平台上工作:DirectX, Vulkan, Metal和各种游戏控制台,但不支持GLES。问题是大多数GLES 3.0设备无法在顶点阶段访问SSBO(即GL_MAX_VERTEX_SHADER_STORAGE_BLOCKS值为0),因此,当图形API设置为GLES时,BRG将使用恒定缓冲区或UBO来存储原始数据。
这增加了约束:一个恒定的缓冲区可以是任何大小,但只有一小部分(一个窗口)是可见的,在任何给定的时间,当着色器正在运行。窗口大小取决于硬件和驱动程序,但普遍接受的值是16 KiB。
提示: 在UBO模式下,您应该始终使用BatchRendererGroup.GetConstantBufferMaxWindowSize() API来获得正确的BRG窗口大小。
让我们看看如果我们想在GLES上运行,我们的代码是如何变化的。对于底层单元,数据总量为350kib。我们不能做一个单一的drawstance(3200),因为着色器不能一次看到350kib。因此,我们必须在UBO中拆分数据,以最大限度地提高每次抽取的实例数量,使其适合16 KiB块。一个层单元是112字节(两个矩阵和一种颜色),因此您可以在一个16 KiB块中容纳16,384除以112或146个实例。为了呈现3200个实例,我们需要发出21个drawinststance(146)和最后一个drawinststance(134)。
现在,350KiB的UBO将被分成22个窗口块,每个16KiB,如下所示:
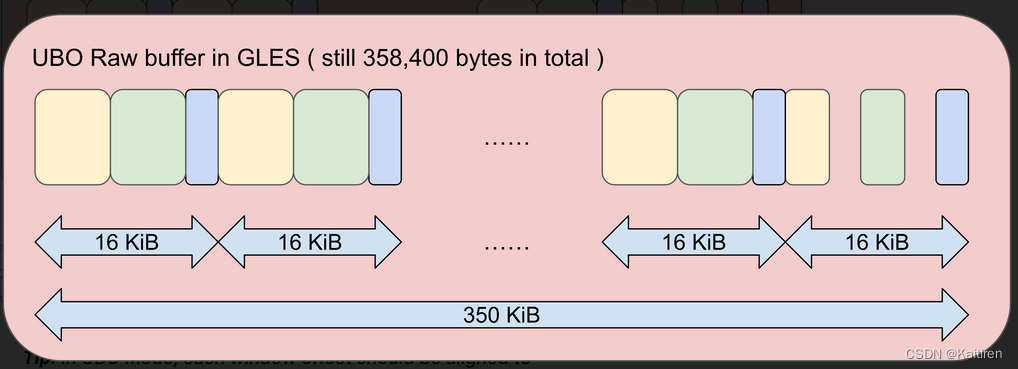
图4:在GLES中,原始缓冲区是UBO(而不是SSBO)。3200个实例的数据被分成22个窗口。每个drawinstance(146)将从16 KiB区域获取数据。请注意,最后一个窗口只包含134个实例,这就是为什么最后一个黄色、绿色和蓝色区域之间有一个小间隙。
提示:在UBO模式下,每个窗口偏移量应该对齐到batchrenderergroup . getconstantbufferoffsetalalignment()。典型的对齐值范围是4到256字节。
在GLES中,由于UBO和16个KiB窗口,您需要注册22个BatchID来存储每个窗口的偏移量。然后初始化代码需要一个循环:
// Register one BatchID per 16KiB window, using the right offsets
m_batchIDs = new BatchID[m_windowCount];
for (int b = 0; b < m_windowCount; b++)
{
batchMetadata[0] = CreateMetadataValue(objectToWorldID, 0, true); // matrices
batchMetadata[1] = CreateMetadataValue(worldToObjectID, m_maxInstancePerWindow * 3 * 16, true); // inverse matrices
batchMetadata[2] = CreateMetadataValue(colorID, m_maxInstancePerWindow * 3 * 2 * 16, true); // colors
int offset = b * m_alignedGPUWindowSize;
m_batchIDs[b] = m_BatchRendererGroup.AddBatch(batchMetadata, m_GPUPersistentInstanceData.bufferHandle, (uint)offset,(uint)m_alignedGPUWindowSize);提示: 为了在游戏示例中支持GLES (UBO)和其他图形API (SSBO), BRG_Container.cs在初始化时设置了一些变量。在SSBO模式下,m_windowCount为1,m_alignedGPUWindowSize为总缓冲区大小。在UBO模式下,m_alignedGPUWindowSize为16 KiB, m_windowCount包含16 KiB块的个数。(16kib的值是为了可读性。使用GetConstantBufferMaxWindowSize() API来获得正确的值。
上传数据
一旦CPU更新了系统内存中的所有矩阵和颜色,您就可以将数据上传到GPU。这是通过BRG_Container完成的。UploadGpuData函数。由于SoA数据模型的原因,您不能上传单个内存块。对于碎片,缓冲区为16,384项。在GLES模式下,如果屏幕上有16,384个碎片,这意味着每个16 KiB的113个窗口。
但是如果在一个给定的框架中只有5300个碎片立方体呢?因为每个窗口有146个项目,这意味着应该上传前36个连续的16 KiB窗口,这样您就可以使用单个SetData (36x16 KiB)。在最后一个窗口中,应该只显示44个碎片立方体。要上传44个矩阵,反转矩阵和颜色,并使用三个SetData命令。在最后,应该发出四个SetData命令。
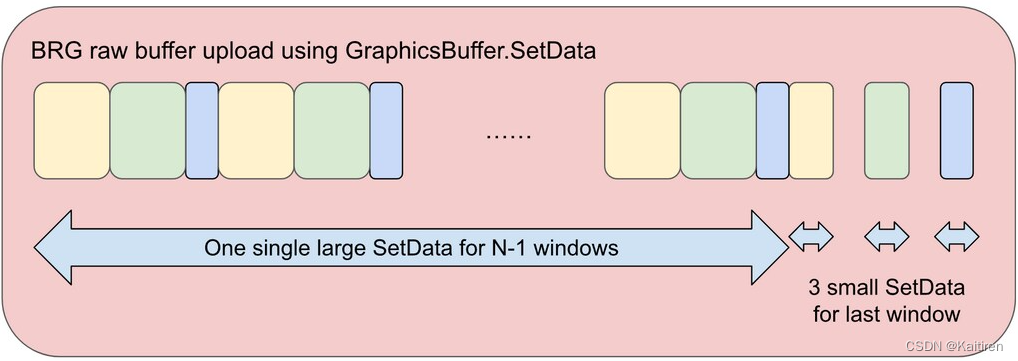
最多四个GfxBuffer。需要使用SetData命令上传N个项目。
BRG主用户回呼
BRG的主要入口点是在创建时提供的剔除回调函数。原型看起来像:
public JobHandle OnPerformCulling(BatchRendererGroup rendererGroup, BatchCullingContext cullingContext, BatchCullingOutput cullingOutput, IntPtr userContext)你在这个回调中的代码负责两件事:
- 将所有绘制命令生成到输出BatchCullingOut结构中;
- 在您自己的筛选代码中使用(或不使用)BatchCullingContext只读结构体中提供的信息;
通用场景
注意:如果您希望启动异步作业来执行这些操作,则回调将返回JobHandle。引擎将使用它在需要结果的点同步,因此您的命令生成代码不会阻塞主线程。
BatchCullingContext包含像相机矩阵,相机截锥体计划等信息。基本上,您需要剔除所有数据并生成更少的绘制命令。在示例中,所有对象都适合相机视图(地板细胞和碎片),因此不需要使用剔除代码。
BatchCullingOutputDrawCommands结构包含各种数据,包括数组。为这些数组分配本机内存是用户的责任。引擎负责在数据被消耗后释放内存(你负责分配,Unity负责释放)。内存分配应该是Allocator.TempJob类型。
private static T* Malloc<T>(uint count) where T : unmanaged
{
return (T*)UnsafeUtility.Malloc(
UnsafeUtility.SizeOf<T>() * count,
UnsafeUtility.AlignOf<T>(),
Allocator.TempJob);
}您应该分配的第一个数组是可见性int数组。在示例中,我们假设所有内容都是可见的,所以我们只是用增量值填充可见性int数组,例如{0,1,2,3,4,…}。
Draw commands generation
一个BRG绘制命令几乎是一个GPU drawstance调用。分配和填充最重要的数组是BatchDrawCommand。假设当前帧中有4737个碎片立方体。
m_maxInstancePerWindow在GLES模式下为146。你可以计算绘制命令的数量,并使用m_instanceCount除以m_maxInstancePerWindow的上限值来分配缓冲区:
int drawCommandCount = (m_instanceCount + m_maxInstancePerWindow - 1) / m_maxInstancePerWindow;
drawCommands.drawCommands = Malloc<BatchDrawCommand>((uint)drawCommandCount);为了避免在几个绘制命令中重复类似的参数,BatchCullingOutputDrawCommands有一个BatchDrawRange结构数组。您可以在BatchDrawRange中设置各种参数。filterSettings,如renderingLayerMask,接收阴影标志等。由于所有绘制命令将共享相同的渲染设置,您可以分配一个单一的DrawCommandRange结构,它将从绘制命令0应用并包含所有drawCommandCount命令。
drawCommands.drawRanges[0] = new BatchDrawRange
{
drawCommandsBegin = 0,
drawCommandsCount = (uint)drawCommandCount,
filterSettings = new BatchFilterSettings
{
renderingLayerMask = 1,
layer = 0,
motionMode = MotionVectorGenerationMode.Camera,
shadowCastingMode = m_castShadows ? ShadowCastingMode.On : ShadowCastingMode.Off,
receiveShadows = true,
staticShadowCaster = false,
allDepthSorted = false
}
};然后,填充绘制命令。每个BatchDrawCommand包含一个meshID, batchID(知道如何使用元数据)和materialID。它还包含可见性int数组缓冲区中的起始偏移量。因为我们在上下文中不需要任何截锥体剔除,所以我们用{0,1,2,3,…}填充可见性数组。然后,所有绘制命令将引用相同的{0,1,2,3,…} indirection,因此每个BatchDrawCommand将使用0作为可见性数组的开始偏移量。下面的代码分配和填充所有需要的绘制命令:
drawCommands.drawCommands = Malloc<BatchDrawCommand>((uint)drawCommandCount);
int left = m_instanceCount;
for (int b = 0; b < drawCommandCount; b++)
{
int inBatchCount = left > maxInstancePerDrawCommand ? maxInstancePerDrawCommand : left;
drawCommands.drawCommands[b] = new BatchDrawCommand
{
visibleOffset = (uint)0, // all draw command is using the same {0,1,2,3...} visibility int array
visibleCount = (uint)inBatchCount,
batchID = m_batchIDs[b],
materialID = m_materialID,
meshID = m_meshID,
submeshIndex = 0,
splitVisibilityMask = 0xff,
flags = BatchDrawCommandFlags.None,
sortingPosition = 0
};
left -= inBatchCount;
}End.