一、说明
在Python中,函数包装器被称为装饰器,它们在数据科学中具有各种有用的应用。本指南介绍如何使用它们来管理模型运行时和调试。
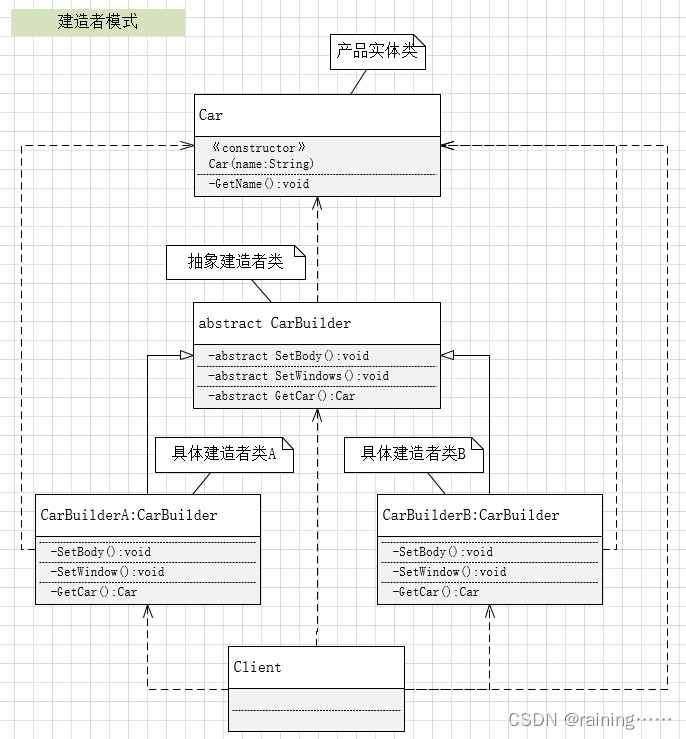
二、函数的封装
函数包装器是用于修改函数行为的有用工具。在Python中,它们被称为装饰器。装饰器允许我们扩展函数或类的行为,而无需更改包装函数的原始实现。
装饰器的一个特别有用的应用程序是监视函数调用的运行时,因为它允许开发人员监视函数成功执行和运行所需的时间。此过程对于管理时间和成本等计算资源至关重要。
函数包装器的另一个应用程序是调试其他函数。在 Python 中,定义打印函数参数和返回值的调试器函数包装器非常简单。此应用程序可用于使用几行代码检查函数执行失败的原因。
Python 中的 functools 模块使定义自定义装饰器变得容易,它可以“包装”(修改/扩展)另一个函数的行为。事实上,正如我们将看到的,定义函数包装器与在 Python 中定义普通函数非常相似。定义函数装饰器后,我们只需在要修改或扩展的函数前面的代码行中使用“@”符号和包装函数的名称。定义计时器和调试器函数包装器的过程遵循类似的步骤。
在这里,我们将研究如何为简单的分类模型定义和应用函数包装器来分析机器学习模型运行时。我们将使用此函数包装器来监视简单机器学习工作流中的数据准备、模型拟合和模型预测步骤的运行时。我们还将看到如何定义和应用函数包装器来调试这些相同的步骤。
我将使用Deepnote,这是一个数据科学笔记本,它使管理机器资源变得容易,并提供在各种数据科学工具之间的无缝切换。这些功能使运行可重现的实验变得简单。我们将使用虚构的Telco Churn数据集,该数据集在Kaggle上公开可用。该数据集可在 Apache 2.0 许可证下免费使用、修改和共享。
三、什么是 PYTHON 包装器?
更多关于 PYTHON 的信息如何使用 Python 复制文件
3.1 数据准备
让我们通过导航到 Deepnote 平台来开始数据准备过程(如果您还没有帐户,注册是免费的)。让我们创建一个项目。
并将我们的项目命名为function_wrappers并将我们的笔记本命名为profiling_debugging_mlworkflow:

图片:作者截图。
让我们将数据添加到 Deepnote:
图片:作者截图。
我们将使用熊猫库来处理我们的数据。让我们导入它:
import pandas as pd接下来,让我们定义一个data_preparation调用的函数:
def data_preparation():
pass让我们添加一些基本的数据处理逻辑。此函数将执行五项任务:
- 读入数据
- 选择相关列:该函数将列名列表作为输入
- 清理数据:指定列数据类型
- 拆分数据以进行训练和测试:该函数将测试大小作为输入
- 返回训练和测试集
让我们首先添加要读取数据的逻辑。我们还添加逻辑来显示前五行:
def data_preparation(columns, test_size):
df = pd.read_csv("telco_churn.csv")
print(df.head())我们调用数据准备函数。现在,让我们传递“none”作为列和测试大小的参数:
def data_preparation(columns, test_size):
df = pd.read_csv("telco_churn.csv")
print(df.head())
data_preparation(None, None)
图片:作者截图。
接下来,在我们的 data_preparation 方法中,让我们使用 columns 变量来过滤数据框,定义我们将使用的列名列表,并使用 columns 变量调用我们的函数:
def data_preparation(columns, test_size):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
print(df_subset.head())
columns = ["gender", "tenure", "PhoneService", "MultipleLines", "TotalCharges", "Churn"]
data_preparation(columns, None)
接下来,让我们指定另一个函数参数,我们将使用它来指定每列的数据类型。在函数的 for 循环中,我们将指定每列的数据,这些数据将从数据类型映射的输入字典中获取:
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
print(df_subset.head())
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
data_preparation(columns, None, datatype_dict)在另一个 for 循环中,我们将所有分类列转换为机器可读的代码:
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
data_preparation(columns, None, datatype_dict)最后,让我们指定输入和输出,拆分用于训练和测试的数据,并返回训练集和测试集。首先,让我们 从Scikit-learn中的模型选择模块导入训练测试拆分方法:
from sklearn.model_selection import train_test_splitNext, let’s specify our inputs, outputs, training and testing sets:
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
X = df_subset[["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges",]]
y = df_subset["Churn"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
X_train, X_test, y_train, y_test = data_preparation(columns, 0.33, datatype_dict)
3.2 模型训练
现在我们已经准备好了训练和测试数据,让我们训练我们的分类模型。为简单起见,让我们定义一个函数,该函数使用默认参数训练随机森林分类器并设置随机状态可重现性。该函数将返回经过训练的模型对象。让我们从导入随机森林分类器开始:
from sklearn.ensemble import RandomForestClassifier接下来,让我们定义我们的拟合函数并存储经过训练的模型对象:
def fit_model(X_train,y_train):
model = RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
return model
model = fit_model(X_train,y_train)
3.3 模型预测和性能
我们还定义将返回模型预测的预测函数
def predict(X_test, model):
y_pred = model.predict(X_test)
return y_pred
y_pred = predict(X_test, model)最后,让我们定义一个报告分类性能指标的方法
def model_performance(y_pred, y_test):
print("f1_score", f1_score(y_test, y_pred))
print("accuracy_score", accuracy_score(y_test, y_pred))
print("precision_score", precision_score(y_test, y_pred))
model_performance(y_pred, y_test)
图片:作者截图。
现在,如果我们想使用函数包装器来定义我们的计时器,我们需要导入函数工具和时间模块:
import functools
import time接下来,让我们定义我们的计时器函数。我们称之为runtime_monitor。它将采用一个名为 input_function 的参数作为参数。我们还会将输入函数传递给 functools 包装器中的 wraps 方法,我们将将其放在实际计时器函数之前,称为 runtime_wrapper:
def runtime_monitor(input_function):
@functools.wraps(input_function)
def runtime_wrapper(*args, **kwargs):接下来,在运行时包装器范围内,我们指定用于计算输入函数的执行运行时的逻辑。我们定义一个开始时间值,函数的返回值(这是我们执行函数的位置)一个结束时间值,以及运行时值,这是开始时间和结束时间之间的差异
def runtime_wrapper(*args, **kwargs):
start_value = time.perf_counter()
return_value = input_function(*args, **kwargs)
end_value = time.perf_counter()
runtime_value = end_value - start_value
print(f"Finished executing {input_function.__name__} in {runtime_value} seconds")
return return_value我们的计时器函数 (runtime_wrapper) 在我们的 runtime_monitor 函数范围内定义。完整功能如下:
def runtime_monitor(input_function):
@functools.wraps(input_function)
def runtime_wrapper(*args, **kwargs):
start_value = time.perf_counter()
return_value = input_function(*args, **kwargs)
end_value = time.perf_counter()
runtime_value = end_value - start_value
print(f"Finished executing {input_function.__name__} in {runtime_value} seconds")
return return_value
return runtime_wrapper然后我们可以使用runtime_monitor来包装我们的data_preparation、fit_model、predict和model_performance函数。对于 data_preparation,我们有以下内容:
@runtime_monitor
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
X = df_subset[["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges",]]
y = df_subset["Churn"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
X_train, X_test, y_train, y_test = data_preparation(columns, 0.33, datatype_dict)![]()
我们看到我们的数据准备函数需要 0.04 才能执行。对于fit_model,我们有:
@runtime_monitor
def fit_model(X_train,y_train):
model = RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
return model
model = fit_model(X_train,y_train)![]()
对于我们的预测:
@runtime_monitor
def predict(X_test, model):
y_pred = model.predict(X_test)
return y_pred
y_pred = predict(X_test, model)![]()
最后,对于模型性能:
@runtime_monitor
def model_performance(y_pred, y_test):
print("f1_score", f1_score(y_test, y_pred))
print("accuracy_score", accuracy_score(y_test, y_pred))
print("precision_score", precision_score(y_test, y_pred))
model_performance(y_pred, y_test)
图片:作者截图。
我们看到拟合方法是最耗时的,这是我们所期望的。在构建诸如此类的简单机器学习工作流时,能够可靠地监视这些函数的运行时对于资源管理至关重要。
3.4 调试机器学习模型
定义调试器函数包装器也是一个简单的过程。 让我们从定义一个名为调试方法的函数开始。与我们的计时器函数类似,iit 将一个函数作为输入。我们还会将输入函数传递给 functools 包装器中的 wraps 方法,我们将将其放在实际的调试器函数(称为 debugging_wrapper)之前。debugging_wrapper将参数和关键字参数作为输入:
def debugging_method(input_function):
@functools.wraps(input_function)
def debugging_wrapper(*args, **kwargs):接下来,我们将参数的表示、关键字及其值分别存储在称为参数和keyword_arguments的列表中:
def debugging_wrapper(*args, **kwargs):
arguments = []
keyword_arguments = []
for a in args:
arguments.append(repr(a))
for key, value in kwargs.items():
keyword_arguments.append(f"{key}={value}")接下来,我们将连接参数和keyword_argument,然后将它们连接在一个字符串中:
def debugging_wrapper(*args, **kwargs):
...#code truncated for clarity
function_signature = arguments + keyword_arguments
function_signature = "; ".join(function_signature) 最后,我们将打印函数名称、签名和返回值:
def debugging_wrapper(*args, **kwargs):
...#code truncated for clarity
print(f"{input_function.__name__} has the following signature: {function_signature}")
return_value = input_function(*args, **kwargs)
print(f"{input_function.__name__} has the following return: {return_value}") debugging_wrapper函数还将返回输入函数的返回值。完整功能如下:
def debugging_method(input_function):
@functools.wraps(input_function)
def debugging_wrapper(*args, **kwargs):
arguments = []
keyword_arguments = []
for a in args:
arguments.append(repr(a))
for key, value in kwargs.items():
keyword_arguments.append(f"{key}={value}")
function_signature = arguments + keyword_arguments
function_signature = "; ".join(function_signature)
print(f"{input_function.__name__} has the following signature: {function_signature}")
return_value = input_function(*args, **kwargs)
print(f"{input_function.__name__} has the following return: {return_value}")
return return_value
return debugging_wrapper
3.5 数据准备
我们现在可以用我们的debugging_method包装我们的data_preparation函数:
@debugging_method
@runtime_monitor
def data_preparation(columns, test_size, datatype_dict):
df = pd.read_csv("telco_churn.csv")
df_subset = df[columns].copy()
for col in columns:
df_subset[col] = df_subset[col].astype(datatype_dict[col])
for col in columns:
if datatype_dict[col] == "category":
df_subset[col] = df_subset[col].cat.codes
X = df_subset[["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges",]]
y = df_subset["Churn"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
return X_train, X_test, y_train, y_test
columns = ["gender", "tenure", "PhoneService", "MultipleLines","MonthlyCharges", "Churn"]
datatype_dict = {"gender":"category", "tenure":"float", "PhoneService":"category", "MultipleLines":"category", "MonthlyCharges":"float", "Churn":"category"}
X_train, X_test, y_train, y_test = data_preparation(columns, 0.33, datatype_dict)
3.6 模型训练
我们可以对 fit 函数做同样的事情:
@debugging_method
@runtime_monitor
def fit_model(X_train,y_train):
model = RandomForestClassifier(random_state=42)
model.fit(X_train,y_train)
return model
model = fit_model(X_train,y_train)
3.7 模型预测和性能
对于我们的预测函数:
@debugging_method
@runtime_monitor
def predict(X_test, model):
y_pred = model.predict(X_test)
return y_pred
y_pred = predict(X_test, model)
最后,对于我们的性能函数:
@debugging_method
@runtime_monitor
def model_performance(y_pred, y_test):
print("f1_score", f1_score(y_test, y_pred))
print("accuracy_score", accuracy_score(y_test, y_pred))
print("precision_score", precision_score(y_test, y_pred))
model_performance(y_pred, y_test)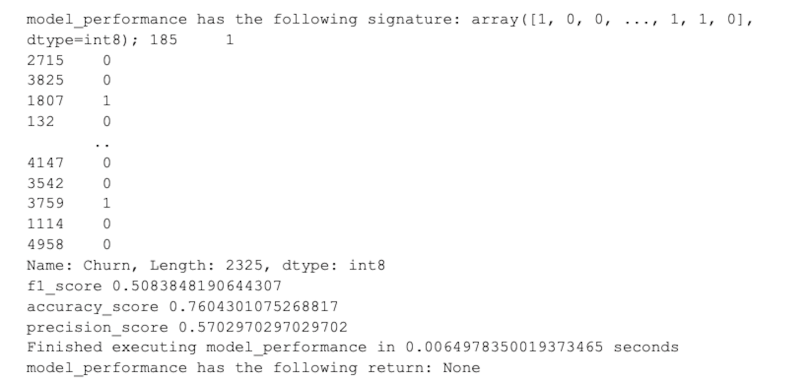
这篇文章中的代码可在GitHub上找到。
四、函数包装器在 Python 中的使用
函数包装器在软件工程、数据分析和 机器学习。在开发机器学习模型时,涉及数据准备、模型训练和预测的操作运行时是一个主要关注领域。在数据准备的情况下,读取数据、执行聚合和插补缺失值等操作在运行时可能会有所不同,具体取决于数据的大小和操作的复杂性。考虑到这一点,监视这些操作的运行时在数据更改时如何变化非常有用。
此外,将模型拟合到训练数据可以说是机器学习管道中最昂贵的步骤。训练(拟合)模型到数据的运行时间可以随数据大小而显着变化,包括包含的特征数和数据中的行数。在许多情况下,机器学习的训练数据会使用更多的数据进行刷新。这会导致模型训练步骤在运行时增加,并且通常需要更强大的计算机才能成功完成模型训练。
模型预测调用也可能因预测输入数而异。尽管数十到几百个预测调用可能没有显著的运行时,但在某些情况下,需要进行数千到数百万次预测,这可能会极大地影响运行时。能够监视预测函数调用的运行时对于资源管理也至关重要。
除了监视运行时之外,在构建机器学习模型时,使用函数包装器进行调试也很有用。与运行时监视类似,此过程对于解决数据准备、模型拟合调用和模型预测调用的问题非常有用。在数据准备步骤中,数据刷新可能会导致一次可执行的函数失败。此外,刷新数据或修改用于训练的模型输入时可能会出现问题和错误。使用函数包装器进行调试有助于指示输入、数组形状和数组长度的更改如何导致 fit 调用失败。在这种情况下,我们可以使用函数包装器来查找此错误的来源并解决它。
Python 中的函数包装器使运行时监控和调试变得简单明了。虽然我只介绍了一个非常简单的示例的数据准备、模型拟合和模型预测,但这些方法对于更复杂的数据变得更加有用。在数据准备的情况下,运行时监视和调试函数对于其他类型的数据准备非常有用,例如预测缺失值、组合数据源以及通过规范化或标准化转换数据。此外,在拟合模型并进行预测时,模型类型和模型超参数可能会对运行时和错误产生重大影响。拥有可靠的运行时监视和调试工具对于数据科学家和机器学习工程师都很有价值。
Function Wrappers in Python: Model Runtime and Debugging | Built In