【TensorFlow1.X】系列学习笔记【入门四】
大量经典论文的算法均采用 TF 1.x 实现, 为了阅读方便, 同时加深对实现细节的理解, 需要 TF 1.x 的知识
【TensorFlow1.X】系列学习文章目录
文章目录
- 【TensorFlow1.X】系列学习笔记【入门四】
- 前言
- 损失函数作用
- 均方误差(MSE)
- 交叉熵(Cross Entropy)
- 自定义损失函数
- 总结
前言
实现神经网络的搭建,下一步需要学习神经网络优化原理和实现细节,本篇博文将详解损失函数作用。
损失函数作用
损失函数在深度学习中起着重要的作用,它用于衡量模型预测结果与实际标签之间的差异,指导模型的训练过程,是评估模型性能和优化模型参数的关键组成部分。损失函数具有以下几个主要作用:
- 衡量模型性能:损失函数用于衡量模型在给定数据上的性能。通过计算预测结果与真实标签之间的差异,可以评估模型的准确性和误差大小。
- 反映优化目标:损失函数定义了优化算法的目标,即最小化损失函数的值。通过最小化损失函数,模型可以尽量减少预测结果与真实标签之间的差异,并提高模型的性能。
- 指导参数更新:在优化过程中,损失函数的梯度被用于指导参数的更新方向和幅度。通过计算损失函数对于模型参数的梯度,可以确定参数更新的方向,使得损失函数的值逐渐减小。
- 支持模型选择和比较:不同的损失函数适用于不同的任务和问题。选择适合任务的损失函数可以帮助模型更好地学习和拟合数据。此外,通过比较不同模型在相同损失函数下的性能,可以选择最佳的模型架构和超参数。
深度学习常见的损失函数包括:
- 均方误差(Mean Squared Error,MSE):适用于回归问题,衡量预测值和真实值之间的平均平方差。
- 交叉熵(Cross Entropy):适用于分类问题,衡量预测概率分布与真实概率分布之间的差异。
选择合适的损失函数取决于任务类型、数据特征和模型要解决的问题。不同的损失函数对模型的训练和优化过程产生不同的影响,因此需要仔细选择和调整以达到最佳结果。
均方误差(MSE)
均方误差mse:n 个样本的预测值
y
y
y与真实值
y
_
y\_
y_之差的平方和,再求平均值。
M
S
E
(
y
_
,
y
)
=
∑
i
=
1
n
(
y
−
y
_
)
2
n
MSE({\rm{y\_}},y) = \frac{{\sum\nolimits_{i =1 }^n {{{(y - y\_)}^2}} }}{n}
MSE(y_,y)=n∑i=1n(y−y_)2
在 Tensorflow1.X中用 loss_mse = tf.reduce_mean(tf.square(y_ - y))
举个小案例:两个神经网络模型解决二分类问题中,已知标准答案为
y
_
=
(
1
,
0
)
{\rm{y\_ = (1, 0)}}
y_=(1,0),第一个神经网络模型预测结果为
y
1
=
(
0.7
,
0.5
)
{\rm{y_1= (0.7, 0.5)}}
y1=(0.7,0.5),第二个神经网络模型预测结果为
y
2
=
(
0.8
,
0.1
)
{\rm{y_2= (0.8, 0.1)}}
y2=(0.8,0.1),判断哪个神经网络模型预测的结果更接近标准答案。
根据均方误差的计算公式得:
M
S
E
_
1
(
(
1
,
0
)
,
(
0
.
7
,
0
.
5
)
)
=
(
0
.
7
−
1
)
2
+
(
0
.
5
−
0
)
2
=
0
.
34
{\rm{MSE\_1((1,0),(0}}{\rm{.7, 0}}{\rm{.5)) = (0}}{\rm{.7 - 1}}{{\rm{)}}^2} + {{\rm{(0}}{\rm{.5 - 0)}}^2} = {\rm{0}}{\rm{.34}}
MSE_1((1,0),(0.7,0.5))=(0.7−1)2+(0.5−0)2=0.34
M
S
E
_
2
(
(
1
,
0
)
,
(
0
.
8
,
0
.
1
)
)
=
(
0
.
8
−
1
)
2
+
(
0
.
1
−
0
)
2
=
0
.
05
{\rm{MSE\_2((1,0),(0}}{\rm{.8, 0}}{\rm{.1)) = (0}}{\rm{.8 - 1}}{{\rm{)}}^2} + {{\rm{(0}}{\rm{.1 - 0)}}^2} ={\rm{0}}{\rm{.05}}
MSE_2((1,0),(0.8,0.1))=(0.8−1)2+(0.1−0)2=0.05
由于0.34>0.05,所以预测值
y
2
y_2
y2与真实值
y
_
y\_
y_更接近,
y
2
y_2
y2预测更准确。
对于多分类问题,MSE并不是一个常用的评估指标
在上一篇博文【TensorFlow1.X入门三】中的线性回归和非线性回归中都用到了此方法。
交叉熵(Cross Entropy)
交叉熵 Cross Entropy:n 个样本的预测值
y
y
y与真实值
y
_
y\_
y_的概率分布之间的距离,交叉熵越大,两个概率分布距离越远,两个概率分布越相异;交叉熵越小,两个概率分布距离越近,两个概率分布越相似。
H
(
y
_
,
y
)
=
−
∑
i
=
1
n
y
_
∗
log
y
H({\rm{y\_}},y) = - \sum\nolimits_{i = 1}^n {y\_} *\log y
H(y_,y)=−∑i=1ny_∗logy
在 Tensorflow1.X中用loss_ce = -tf.reduce_mean(y_* tf.log(tf.clip_by_value(y, 1e-12, 1.0)))
同一个小案例,根据交叉熵的计算公式得:
H
_
1
(
(
1
,
0
)
,
(
0.7
,
0.5
)
)
=
−
(
1
∗
l
o
g
0.7
+
0
∗
l
o
g
0.3
)
≈
0.36
H\_1\left( {\left( {1,0} \right),\left( {0.7,0.5} \right)} \right){\rm{ }} = {\rm{ }} - \left( {1*log0.7{\rm{ }} + {\rm{ }}0*log0.3} \right) \approx {\rm{ }}0.36
H_1((1,0),(0.7,0.5))=−(1∗log0.7+0∗log0.3)≈0.36
H
_
2
(
(
1
,
0
)
,
(
0.8
,
0.1
)
)
=
−
(
1
∗
l
o
g
0.8
+
0
∗
l
o
g
0.1
)
≈
0.22
H\_2\left( {\left( {1,0} \right),\left( {0.8,0.1} \right)} \right){\rm{ }} = {\rm{ }} - \left( {1*log0.8{\rm{ }} + {\rm{ }}0*log0.1} \right) \approx {\rm{ }}0.22
H_2((1,0),(0.8,0.1))=−(1∗log0.8+0∗log0.1)≈0.22
由于0.36>0.22,所以预测值
y
2
y_2
y2与真实值
y
_
y\_
y_更接近,
y
2
y_2
y2预测更准确。
这里 n n n分类的输出概率并没有什么联系,而且通常会将每个概率值都压缩在min和max之间:小于min的值等于min,大于max的值等于max。tf.clip_by_value(y, 1e-12, 1.0)即在0到1之间,这样的话上面的H_1的值就被压缩成是 H _ 1 ( ( 1 , 0 ) , ( 0.7 , 0.3 ) ) ≈ 0.36 H\_1\left( {\left( {1,0} \right),\left( {0.7,0.3} \right)} \right){\rm{ }}\approx {\rm{ }}0.36 H_1((1,0),(0.7,0.3))≈0.36,所以 H _ 1 H\_1 H_1公式博主并没有写错。
在深度学习中,一般让模型的输出经过softmax函数,以获得输出分类的概率分布,再与真实值对比,求出交叉熵,得到损失函数。softmax函数要求
n
n
n分类的输出满足以下概率分布要求的函数:
p
(
X
=
x
i
)
∈
[
0
,
1
]
p(X = {x_i}) \in [0,1]
p(X=xi)∈[0,1]且
∑
i
n
p
(
X
=
x
i
)
=
1
\sum\nolimits_i^n {p(X = {x_i}) = 1}
∑inp(X=xi)=1,softmax函数具体表示为:
p
(
X
=
x
i
)
=
s
o
f
t
m
a
x
(
x
i
)
=
e
x
i
∑
i
=
1
n
e
x
i
p(X = {x_i}) = {\rm{softmax}}({x_i}) = \frac{{{e^{{x_i}}}}}{{\sum\nolimits_{i = 1}^n {{e^{{x_i}}}} }}
p(X=xi)=softmax(xi)=∑i=1nexiexi。
在 Tensorflow1.X中结合softmax和Cross Entropy后用loss_ce = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)))
同一个小案例,根据改良版本的交叉熵的计算公式得:
H
_
1
(
(
1
,
0
)
,
s
o
f
t
m
a
x
(
0.7
,
0.5
)
)
≈
H
_
1
(
(
1
,
0
)
,
(
0.57
,
0.43
)
)
=
0.56
H\_1\left( {\left( {1,0} \right),softmax\left( {0.7,0.5} \right)} \right) \approx H\_1\left( {\left( {1,0} \right),\left( {0.57,0.43} \right)} \right){\rm{ }} = {\rm{ }}0.56
H_1((1,0),softmax(0.7,0.5))≈H_1((1,0),(0.57,0.43))=0.56
H
_
2
(
(
1
,
0
)
,
s
o
f
t
m
a
x
(
0.8
,
0.1
)
)
≈
H
_
1
(
(
1
,
0
)
,
(
0.79
,
0.21
)
)
=
0.24
H\_2\left( {\left( {1,0} \right),softmax\left( {0.8,0.1} \right)} \right) \approx H\_1\left( {\left( {1,0} \right),\left( {0.79,0.21} \right)} \right){\rm{ }} = {\rm{ }}0.24
H_2((1,0),softmax(0.8,0.1))≈H_1((1,0),(0.79,0.21))=0.24
由于0.56>0.24,所以预测值
y
2
y_2
y2与真实值
y
_
y\_
y_更接近,
y
2
y_2
y2预测更准确。
在上一篇博文【TensorFlow1.X入门三】中的逻辑回归中都用到了此方法。
自定义损失函数
根据问题的实际情况,定制合理的损失函数。
举个例子:对于预测酸奶日销量问题,如果预测销量大于实际销量则会损失成本;如果预测销量小于实际销量则会损失利润。在实际生活中,往往制造一盒酸奶的成本和销售一盒酸奶的利润是不等价的。因此,需要使用符合该问题的自定义损失函数:
l
o
s
s
=
∑
i
=
0
n
f
(
y
_
,
y
)
loss = \sum\nolimits_{i = 0}^n {f(y\_,y)}
loss=∑i=0nf(y_,y)
自定义损失函数制作为分段函数:
f
(
y
_
,
y
)
=
{
p
r
o
f
i
t
×
(
y
_
−
y
)
,
y
<
y
_
c
o
s
t
×
(
y
_
−
y
)
,
y
>
=
y
_
f(y\_,y) = \left\{ {\begin{array}{cc} {profit \times (y\_ - y),y < y\_}\\ {cost \times (y\_ - y),y > = y\_} \end{array}} \right.
f(y_,y)={profit×(y_−y),y<y_cost×(y_−y),y>=y_
若预测结果 y 小于标准答案 y_,损失函数为利润乘以预测结果 y 与标准答案 y_之差;
若预测结果 y 大于标准答案 y_,损失函数为成本乘以预测结果 y 与标准答案 y_之差。
在 Tensorflow1.X中用loss = tf.reduce_sum(tf.where(tf.greater(y,y_),COST(y-y_),PROFIT(y_-y)))
自定义损失函数的完整的代码:
#coding:utf-8
#酸奶成本1元, 酸奶利润9元
#预测少了损失大,故不要预测少,故生成的模型会多预测一些
#0导入模块,生成数据集
import tensorflow as tf
import numpy as np
BATCH_SIZE = 8
SEED = 23455
COST = 8
PROFIT = 2
rdm = np.random.RandomState(SEED)
X = rdm.rand(32,2)
# 假设市场的真实利润Y=3*COST+2*PROFIT
Y = [[3*x1+2*x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]
# 定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
# 希望训练好的网络权重接近w=(a,b)接近(3,2)
w = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w)
#定义损失函数及反向传播方法。
loss = tf.reduce_sum(tf.where(tf.greater(y, y_), (y - y_)*COST, (y_ - y)*PROFIT))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#生成会话,训练STEPS轮。
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 3000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = (i*BATCH_SIZE) % 32 + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
print ("After %d training steps, w1 is: " % (i))
print (sess.run(w), "\n")
print ("Final w1 is: \n", sess.run(w))

采用均方损失函数的完整的代码:
只需要修改loss部分
#coding:utf-8
#酸奶成本1元, 酸奶利润9元
#预测少了损失大,故不要预测少,故生成的模型会多预测一些
#0导入模块,生成数据集
import tensorflow as tf
import numpy as np
BATCH_SIZE = 8
SEED = 23455
COST = 8
PROFIT = 2
rdm = np.random.RandomState(SEED)
X = rdm.rand(32,2)
# 假设市场的真实利润Y=3*COST+2*PROFIT
Y = [[3*x1+2*x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]
# 定义神经网络的输入、参数和输出,定义前向传播过程。
x = tf.placeholder(tf.float32, shape=(None, 2))
y_ = tf.placeholder(tf.float32, shape=(None, 1))
# 希望训练好的网络权重接近w=(a,b)接近(3,2)
w = tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))
y = tf.matmul(x, w)
#定义损失函数及反向传播方法。
loss = tf.reduce_mean(tf.square(y_ - y))
train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss)
#生成会话,训练STEPS轮。
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
STEPS = 3000
for i in range(STEPS):
start = (i*BATCH_SIZE) % 32
end = (i*BATCH_SIZE) % 32 + BATCH_SIZE
sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})
if i % 1000 == 0:
print ("After %d training steps, w1 is: " % (i))
print (sess.run(w), "\n")
print ("Final w1 is: \n", sess.run(w))
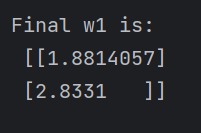
由执行结果可知,无论怎么修改COST和PROFIT的值,采用自定义损失函数预测的权重(2.98,1.98)都比采用均方误差预测的权重(1.88,2.83)更接近真实值(3,2),更符合实际需求。
总结
损失函数在机器学习和深度学习中起着非常重要的作用。它是用来衡量模型预测结果与真实标签之间的差异或误差的函数。通过最小化损失函数,我们可以训练模型的参数以使其能够更好地拟合训练数据,并在新的未见数据上做出准确的预测。博文对深度学习常见的损失函数进行的讲解,并根据问题的实际情况,举例分析讲解了如何定制合理的损失函数。