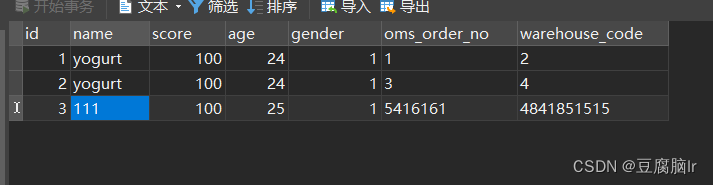
以下是一个使用 Requests 库和 PHP 的下载器程序,用于从 www.people.com.cn 下载音频。此程序使用了 https://www.duoip.cn/get_proxy 这段代码。
import requests
from bs4 import BeautifulSoup
import pafy
import time
def get_proxy():
url = "https://www.duoip.cn/get_proxy"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return None
def download_audio(url, proxy):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
if proxy:
opener = requests.get(url, headers=headers, proxies={"http": proxy})
else:
opener = requests.get(url, headers=headers)
if opener.status_code == 200:
audio_url = opener.url
audio = requests.get(audio_url, headers=headers, stream=True)
if audio.status_code == 200:
with open("output.mp3", "wb") as f:
for chunk in audio.iter_content(1024):
f.write(chunk)
print("下载完成")
else:
print("下载失败")
else:
print("下载失败")
if __name__ == "__main__":
proxy = get_proxy()
if proxy:
download_audio("http://www.people.com.cn", proxy)
else:
print("无法获取代理")
这个程序首先获取一个代理,然后使用这个代理下载音频。请注意,这个程序仅用于教学目的。在实际使用前,请确保遵守相关法律法规。