一、介绍
图书管理与推荐系统。使用Python作为主要开发语言。前端采用HTML、CSS、BootStrap等技术搭建界面结构,后端采用Django作为逻辑处理,通过Ajax等技术实现数据交互通信。在图书推荐方面使用经典的协同过滤算法作为推荐算法模块。主要功能有:
- 角色分为普通用户和管理员
- 普通用户可注册、登录、查看图书、发布评论、收藏图书、对图书评分、借阅图书、归还图书、查看个人借阅、个人收藏、猜你喜欢(针对当前用户个性化推荐图书)
- 管理员可以管理图书以及用户信息
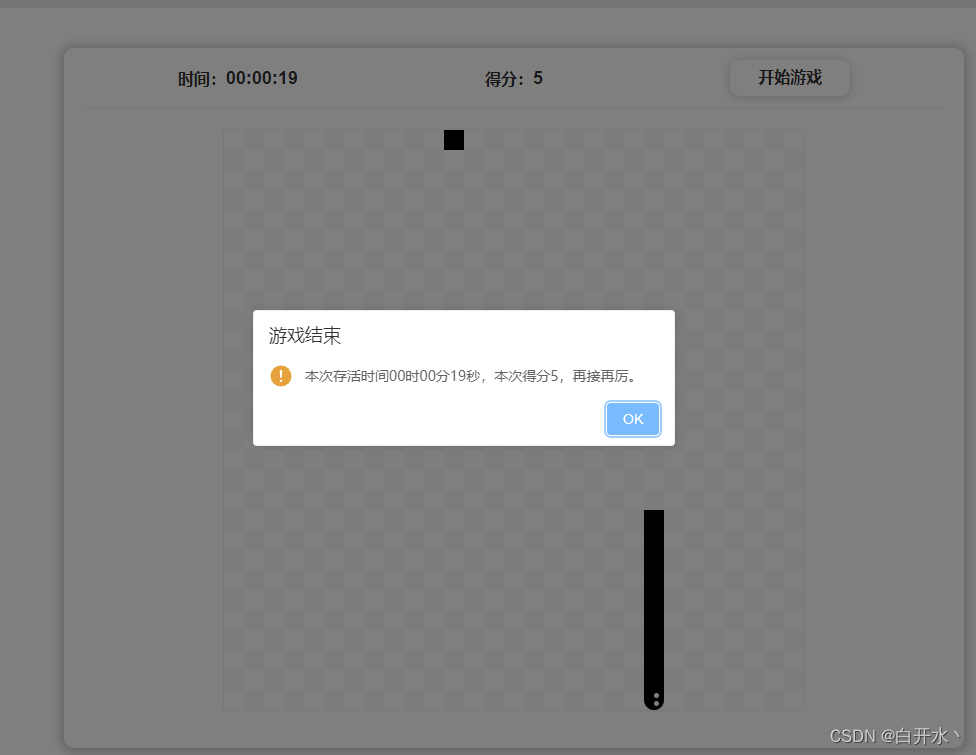
二、部分效果展示图片
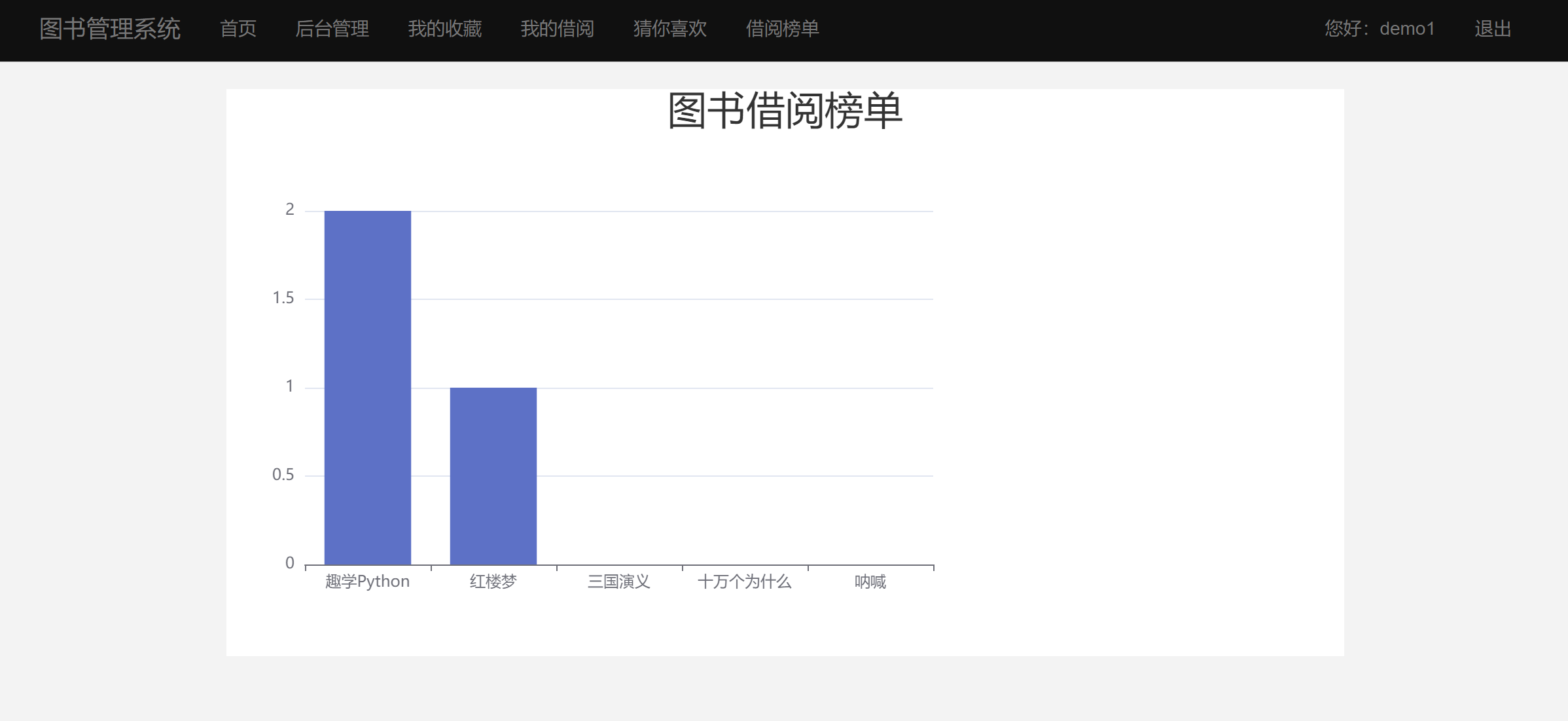
三、演示视频 and 代码 and 介绍
视频+代码+介绍:https://www.yuque.com/ziwu/yygu3z/kpq3wsbzgif4vkpi
四、协同过滤算法
协同过滤(Collaborative Filtering, CF)是推荐系统中的一种常用方法。它基于一个简单的假设:过去喜欢相似物品的用户在未来也可能喜欢相似的物品。
协同过滤的特点:
- 个性化推荐:它可以为每个用户提供个性化的推荐,因为它是基于用户的历史行为来做推荐的。
- 无需物品内容:CF方法不需要对物品的内容进行分析,只需要用户的交互数据。
- 冷启动问题:协同过滤受到所谓的“冷启动”问题的困扰,即新用户或新物品缺乏足够的交互数据来做出准确的推荐。
下面是一个简单的基于用户的协同过滤的Python示例代码:
from scipy.spatial.distance import cosine
# 模拟用户评分数据
user_ratings = {
'Alice': {'Item1': 5, 'Item2': 3, 'Item3': 4},
'Bob': {'Item1': 3, 'Item2': 1, 'Item3': 2},
'Charlie': {'Item1': 4, 'Item2': 2, 'Item3': 5}
}
def compute_similarity(user1, user2):
"""计算两个用户之间的相似度,使用余弦相似度"""
common_ratings = set(user1.keys()) & set(user2.keys())
if not common_ratings:
return 0
# 提取两个用户的评分向量
vec1 = [user1[item] for item in common_ratings]
vec2 = [user2[item] for item in common_ratings]
return 1 - cosine(vec1, vec2)
def get_recommendations(target_user, user_ratings):
"""为目标用户推荐物品"""
total_scores = {}
total_similarity = {}
# 遍历每一个用户
for user, ratings in user_ratings.items():
if user == target_user:
continue
# 计算相似度
similarity = compute_similarity(user_ratings[target_user], ratings)
for item, score in ratings.items():
if item not in user_ratings[target_user]:
total_scores.setdefault(item, 0)
total_scores[item] += score * similarity
total_similarity.setdefault(item, 0)
total_similarity[item] += similarity
# 计算加权平均得分
rankings = [(item, total_scores[item] / total_similarity[item])
for item in total_scores]
# 返回排序后的推荐列表
return sorted(rankings, key=lambda x: x[1], reverse=True)
# 为Alice推荐物品
print(get_recommendations('Alice', user_ratings))
代码注释:
- 首先,我们模拟了三个用户的评分数据。
- compute_similarity 函数计算两个用户之间的相似度,这里我们使用余弦相似度。
- get_recommendations 函数为目标用户推荐物品。它考虑了与目标用户相似的用户对物品的评分,并使用加权平均的方式来计算推荐分数。
这只是协同过滤的一个简单示例,实际应用中还需要考虑许多其他因素和优化手段。







![2023年中国汽车铸造模具竞争现状及行业市场规模前景分析[图]](https://img-blog.csdnimg.cn/img_convert/86735421771191cdfc89a36f22745a32.png)
![【C++入门到精通】哈希 (STL) _ unordered_map _ unordered_set [ C++入门 ]](https://img-blog.csdnimg.cn/4868d249e6f9452abf489fbc82caf53b.jpeg#pic_center)