行人摔倒检测 — 基于 OpenVINO C# API 部署PP-Human
- 4. 配置 PP-Human_Fall_Detection 项目
- 4.1 环境配置
- 4.2 创建 AlxBoard_deploy_yolov8 项目
- 4.3 添加项目源码
- 4.4 添加 OpenVINO C# API
- 4.5 添加 OpenCvSharp
- 5. 测试 PP-Human_Fall_Detection 项目
- 5.1 创建视频读取器
- 5.2 行人识别
- 5.3 关键点识别
- 5.4 摔倒识别
- 5.5 模型联合部署实现行人摔倒识别
- 6. 总结
随着人口老龄化问题的加重,独居老人、空巢老人数量在不断上升,因此如何保障独居老人、空巢老人健康生活和人身安全至关重要。而对于独居老人、空巢老人,如果出现摔倒等情况而不会及时发现,将会对其健康安全造成重大影响。本项目主要研究为开发一套摔倒自动识别报警平台,使用视频监控其采集多路视频流数据,使用行人检测算法、关键点检测算法以及摔倒检测算法实现对行人摔倒自动识别,并根据检测情况,对相关人员发送警报,实现对老人的及时看护。该装置可以布置在养老院等场所,通过算法自动判别,可以大大降低人力成本以及保护老人的隐私。该项目应用场景不知可以用到空巢老人,还可以用到家庭中的孕妇儿童、幼儿园等场景,实现对儿童的摔倒检测。
项目中采用OpenVINO部署行人检测算法、关键点检测算法以及摔倒检测算法实现对行人摔倒自动识别算法,并在AIxBoard 开发板上使用 OpenVINO C# API 结合应用场景部署多模型。
项目中所使用的代码全部在GitHub上开源,项目链接为:PP-Human_Fall_Detection
项目首发网址:行人摔倒检测 - 在英特尔开发套件上基于 OpenVINO™ C# API 部署 PP-Human | 开发者实战
在上一篇文章中我们讲述项目中所使用的开发套件以及模型获取方式,【OpenVINO】行人摔倒检测 — 基于 OpenVINO C# API 部署PP-Human-上篇,在本文中,我们将基于模型部署流程实现PP-Human模型的部署。
4. 配置 PP-Human_Fall_Detection 项目
项目中所使用的代码已经放在GitHub仓库PP-Human_Fall_Detection,大家可以根据情况自行下载和使用,下面我将会从头开始一步步构建PP-Human_Fall_Detection项目。
4.1 环境配置
在该项目中主要需要配置.NET编译运行环境、OpenVINO Runtime、OpenCvSharp环境,其配置流程可以参考上一篇文章:【2023 Intel有奖征文】爱克斯开发板使用OpenVINO C# API部署Yolov8模型 。
4.2 创建 AlxBoard_deploy_yolov8 项目
在该项目中,我们需要使用OpenCvSharp,该依赖目前在Ubutun平台最高可以支持.NET Core 3.1,因此我们此处创建一个.NET Core 3.1的项目,使用Terminal输入以下指令创建并打开项目文件:
dotnet new console --framework "netcoreapp3.1" -o PP-Human_Fall_Detection
cd PP-Human_Fall_Detection

4.3 添加项目源码
前文中我们已经提供了项目源码链接,大家可以直接再在源码使用,此处由于篇幅限制,因此此处不对源码做太多的讲解,只演示如何使用项目源码配置当前项目。将项目源码中的PP-Human文件夹和HumanFallDown.cs、Program.cs文件复制到当前项目中,最后项目的路径关系如下所示:
PP-Human_Fall_Detection
├──── PP-Human
| ├──── Common.cs
| ├──── PP-TinyPose.cs
| ├──── PP-YOLOE.cs
| └──── STGCN.cs
├──── HumanFallDown.cs
├──── PP-Human_Fall_Detection.csproj
└──── Program.cs
4.4 添加 OpenVINO C# API
OpenVINO C# API 目前只支持克隆源码的方式实现,首先使用Git克隆以下源码,只需要在Terminal输入以下命令:
git clone https://github.com/guojin-yan/OpenVINO-CSharp-API.git

然后将该项目文件夹下的除了src文件夹之外的文件都删除掉,然后项目的文件路径入下所示:
PP-Human_Fall_Detection
├──── OpenVINO-CSharp-API
| ├──── src
| └──── CSharpAPI
├──── PP-Human
| ├──── Common.cs
| ├──── PP-TinyPose.cs
| ├──── PP-YOLOE.cs
| └──── STGCN.cs
├──── HumanFallDown.cs
├──── PP-Human_Fall_Detection.csproj
└──── Program.cs
最后在当前项目中添加项目引用,只需要在Terminal输入以下命令:
dotnet add reference ./OpenVINO-CSharp-API/src/CSharpAPI/CSharpAPI.csproj

4.5 添加 OpenCvSharp
-
安装NuGet Package
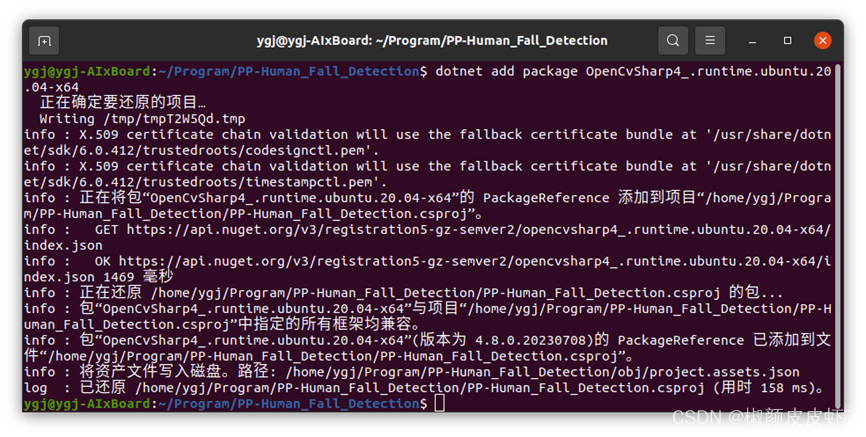
OpenCvSharp可以通过NuGet Package安装,只需要在Terminal输入以下命令:
dotnet add package OpenCvSharp4_.runtime.ubuntu.20.04-x64 dotnet add package OpenCvSharp4

-
添加环境变量
将以下路径添加到环境变量中:
export LD_LIBRARY_PATH=/home/ygj/Program/OpenVINOSharp/tutorial_examples/AlxBoard_deploy_yolov8/bin/Debug/netcoreapp3.1/runtimes/ubuntu.20.04-x64/native/bin/Debug/netcoreapp3.1/runtimes/ubuntu.20.04-x64/native是项目编译后生成的路径,该路径下存放了libOpenCvSharpExtern.so文件,该文件主要是封装的OpenCV中的各种接口。也可以将该文件拷贝到项目运行路径下。
5. 测试 PP-Human_Fall_Detection 项目
5.1 创建视频读取器
当前项目测试内容为视频,此处主要通过OpenCV的VideoCapture类进行读取,实现逐帧读取测试图片。
// 视频路径
string test_video = @"E:\Git_space\基于Csharp和OpenVINO部署PP-Human\demo\摔倒.mp4";
// string test_video = @"E:\Git_space\基于Csharp和OpenVINO部署PP-Human\demo\摔倒2.mp4";
// 视频读取器
VideoCapture video_capture = new VideoCapture(test_video);
// 视频帧率
double fps = video_capture.Fps;
// 视频帧数
int frame_count = video_capture.FrameCount;
Console.WriteLine("video fps: {0}, frame_count: {1}", Math.Round(fps), frame_count);
5.2 行人识别
利用创建好的视频读取器逐帧读取视频图片,将其带入到yoloe_predictor预测器中进行预测,并将预测结果绘制到图片上,期预测结果存放到ResBboxs类中,方便进行数据传输。
// 读取视频帧
if (!video_capture.Read(frame))
{
Console.WriteLine("视频读取完毕!!{0}", frame_id);
break;
}
// 复制可视化图片
visualize_frame = frame.Clone();
// 行人识别
ResBboxs person_result = yoloe_predictor.predict(frame);
// 判断是否识别到人
if (person_result.bboxs.Count < 1)
{
continue;
}
// 绘制行人区域
yoloe_predictor.draw_boxes(person_result, ref visualize_frame);
通过上述代码,可以实现视频所有帧图片预测,将预测结果保存到本地,如图 所示,经过预测器预测,可以很好的捕获到运动的行人。
pedestrian_detection_results
5.3 关键点识别
上一步通过行人跟踪,捕捉到了行人,由于行人是在不断运动的,因此在进行关键点预测时,需要先进行裁剪,将行人区域按照指定要求裁剪下来,并根据裁剪结果对行人关键点进行预测,此处使用的是bath_size=1的预测,适合单人预测,如果出现多人时,可以采用同时预测。
// 裁剪行人区域
List<Rect> point_rects;
List<Mat> person_rois = tinyPose_predictor.get_point_roi(frame, person_result.bboxs, out point_rects);
for (int p = 0; p < person_rois.Count; p++)
{
// 关键点识别
float[,] person_point = tinyPose_predictor.predict(person_rois[p]);
KeyPoints key_point = new KeyPoints(frame_id, person_point, point_rects[p]);
//Console.WriteLine(key_point.bbox);
flag_stgcn = mot_point.add_point(key_point);
tinyPose_predictor.draw_poses(key_point, ref visualize_frame);
}
经过模型预测,第一会将预测结果存到结果容器“mot_point”中,用于后面的摔倒识别;另一点将模型预测结果绘制到图像中,如图所示。
pedestrian_key_point_detection
5.4 摔倒识别
摔倒识别需要同时输入50帧人体关键点识别结果,所以在开始阶段需要积累50帧的关键点识别结果,此处采用自定义的结果保存容器“MotPoint”实现,该容器可以实现保存关键点结果,并将关键点识别结果与上一帧结果进行匹配,当容器已满会返回推理标志,当满足识别条件是,就会进行依次模型预测;同时会清理前20帧数据,继续填充识别结果等待下一次满足条件。
if (flag_stgcn)
{
List<List<KeyPoints>> predict_points = mot_point.get_points();
for (int p = 0; p < predict_points.Count; p++)
{
Console.WriteLine(predict_points[p].Count);
fall_down_result = stgcn_predictor.predict(predict_points[p]);
}
}
stgcn_predictor.draw_result(ref visualize_frame, fall_down_result, person_result.bboxs[0]);
摔倒识别结果为是否摔倒以及对应的权重,此处主要是在满足条件的情况下,进行一次行为识别,并将识别结果绘制到图像上。
pedestrian_fall_detection_resul
5.5 模型联合部署实现行人摔倒识别
通过行人跟踪、关键点识别以及行为识别三个模型联合预测,可以实现行人的行为识别,其识别效果如图 14 所示。在该图中分别包含了三个模型的识别结果:行人位置识别与跟踪是通过PP-YOLOE模型实现的,该模型为下一步关键点识别提供了图像范围,保证了关键点识别的结果;人体骨骼关键点识别时通过dark_hrnet模型实现,为后续行为识别提供了输入;最终的行为识别通过ST-GCN模型实现,其识别结果会知道了行人预测框下部,可以看到预测结果与行人是否摔倒一致。
6. 总结
在该项目中,基于C#和OpenVINO联合部署PP-YOLOE行人检测模型、dark_hrnet人体关键点识别模型以及ST-GCN行为识别模型,实现行人摔倒检测。
在该项目中,主要存在的难点一是PP-YOLOE模型无法直接使用OpenVINO部署,需要进行裁剪,裁剪掉无法使用的节点,并根据裁剪的节点,处理模型的输出数据;难点二是处理好行人预测与关键点模型识别内容的关系,在进行多人识别时,要结合行人识别模型进行对应的人体关键点识别,并且要当前帧识别结果要对应上一帧行人识别结果才可以保证识别的连续性。