文章目录
- 前言
- 应用层协议
- 常见的几种数据格式
- 1. xml
- 2. JSON
- 3. protobuffer
- 端口号
- 传输层
- UDP 报文协议格式
- 源端口号和目的端口号
- UDP 长度
- 校验和
前言
前面我们学习了如何使用 UDP 数据报 和 TCP 流实现网络编程一个回显服务器,在知道了 UDP 和 TCP 协议的基本原理之后,这篇文章我将为大家分享关于一些应用层方面的协议和传输层中的 UDP 协议。
应用层协议
应用层协议是指在计算机网络中,应用程序之间通信的协议。它定义了运行在不同端系统上的应用程序进程如何相互传递报文,将传输层提供的服务转化为应用程序所需要的服务,使得应用程序之间的通信变得更加高效、可靠。
应用层协议通常是由程序员自己定义的协议,应用层协议往往是用来组织数据的,规定数据是如何传输和如何分用的。例如:一个数据“18,180,男,1234567”,在应用层规定用逗号 , 来分隔数据,当得到这个数据的时候就以 ,为分隔符来解析这个数据,这个数据就表示年龄18,身高180,性别男,电话号1234567.应用层的协议是非常灵活的,可以根据不同的情况随时变换,只要客户端和服务器端这边的协议能够对应上就行。
但是这种以文本方式构造的协议就属于比较粗糙的方式了,在实际开发中很少用到这种形式的协议,那么生活中常用的几种数据格式有哪些呢?
常见的几种数据格式
- xml
- json
- protobuffer
1. xml
XML全称为Extensible Markup Language,即可扩展标记语言,它是一种用于存储和传输数据的文本格式。
XML的目的是为了创建一种通用的数据交换格式,它具有以下特点:
- XML是一种元语言,它用于创建标记语言(如HTML)。与HTML不同,XML的标签可以由用户根据需要进行自定义,而非预定义。
- XML数据存储为纯文本格式,可以轻松地在不同系统之间进行传输。
- XML具有自我描述性,它能够表达数据结构,使得数据易于阅读和理解。
在XML文档中,数据被标记为树状结构,具有以下特点:
- XML文档必须包含根节点,这是XML文档的起点。
- XML标签成对出现,每一个开始标签必须有一个对应的结束标签。如果某个标签没有内容,可以使用单标签形式表示。
- 在XML中,大小写是有区别的,例如 和 是两个不同的标签。
- XML中的空格(例如换行和制表符)会被保留,不能随意删除。
XML的应用非常广泛,例如在Web服务、数据库、移动应用等场景中都有它的身影。它常被用于在不同的系统之间交换数据,是一种非常通用的数据交换格式。
xml 是使用标签来组织数据的。
<request>
<userId>1000</userId>
<position>100,30</position>
</request>
通过使用 xml 的数据格式,可读性提高了,但是呢标签写起来非常的繁琐,并且在传输的时候会占用更多的网络带宽,所以呢就出现了一种可读性比较高的数据格式——json。
2. JSON
JSON数据格式,全称JavaScript Object Notation,是一种轻量级的数据交换格式。它采用完全独立于语言的文本格式,基于JavaScript的语法,易于人阅读和编写,同时也易于机器解析和生成。
JSON的基础结构主要包含两种类型:
- “名称/值”对的集合,通常在各种语言中被理解为对象(object),记录(record),结构(struct),字典(dictionary),哈希表(hash table),或者关联数组(associative array)。每一个“名称/值”对的组合构成了一个属性(property),其中名称通常被称为属性名(property name)或者键(key),值则是属性值(property value)。
- 值的有序列表,通常在大多数语言中被理解为数组(array)。数组是一种特殊的“名称/值”对集合,它的每一个元素都是一个值,而且这些值在集合中的顺序是固定的。
在JSON中,数据是以键值对的形式存储的。键是字符串,而值可以是各种不同的数据类型,包括数字、字符串、布尔值、数组、另一个JSON对象等。
JSON对象通常以大括号 {} 包围,并由键和值组成,例如:{key: value}。在JSON中,对象的键和值之间用冒号 “:” 分隔,而不同的键和值之间则用逗号 “,” 分隔。
举个例子,如果有一个名为"user"的对象,可以表示为:
json
{
"username": "zhangsan",
"age": 28,
"password": "123",
"addr": "北京"
}
这个例子的JSON对象包含了四个属性:username、age、password和addr,它们的值分别是"zhangsan"、“28”、“123"和"北京”。
此外,JSON数组是以方括号 [] 包围的值的列表,例如:[“apple”, “banana”, “cherry”]。在JSON中,数组的元素之间用逗号 “,” 分隔。
总的来说,JSON是一种非常常用的数据格式,它的结构简洁明了,易于阅读和理解,同时也方便机器解析和传输。它已经成为了一种广泛接受的数据交换格式,特别是在Web服务和移动应用等领域。
JSON 数据格式的可读性比较高,但是呢,JSON 数据在网络传输的过程中会消耗额外的带宽,因为 JSON 数据还需要将 key 值也进行传输。虽然会消耗额外的带宽,但是 JSON 依旧是当今使用最广泛的一种数据格式,因为现在在开发过程中,公司更注重的是开发效率,而有好的代码可读性就可以极大提高开发效率,除非是一些对数据传输效率要求非常高的场景,一般情况下使用的都是 JSON 数据格式。
3. protobuffer
Protocol Buffers(Protobuf)是Google公司开发的一种数据描述语言,它使用了一种轻便、高效的结构化数据存储格式,可以将结构化的数据进行串行化或者说序列化。
在Protobuf中,数据以二进制格式进行序列化,可以很方便地进行数据存储或用于远程过程调用(RPC)的数据交换格式。Protobuf具有语言无关、平台无关、可扩展的特性,可以用于不同语言之间的数据交换,也可以用于不同平台之间的数据传输。
在序列化过程中,Protobuf使用了“字段标签”和“字段类型”两个概念来描述数据的结构。每个字段都包含一个标签和一个类型,标签用于标识字段,类型用于描述数据的种类。
Protobuf支持多种数据类型,包括整数、浮点数、布尔值、字符串、字节数组、枚举值、复合类型等。复合类型可以包括其他类型的字段,形成一个树状结构,可以很好地描述复杂的数据结构。
在序列化过程中,Protobuf采用了二进制编码方式,对数据进行压缩和优化,可以大大减少数据的大小,提高传输效率。同时,Protobuf也支持对数据进行自描述,可以自动生成数据结构的定义和序列化代码,方便开发人员进行使用和维护。
因为protobuffer数据格式是以二进制的形式组织数据的,所以它在传输的过程中会采用最少的网络带宽,在此基础上 protobuffer 数据的传输速率就更高,但也正因为 protobuffer 是以二进制形式组织数据的,所以它的代码可读性就非常低,也就影响了开发效率。
端口号
在学习传输层相关的协议之前,我们需要先知道什么是端口号。
端口号是网络编程中用于标识计算机或设备上特定服务的数字标识符。
在网络通信中,为了将数据发送到正确的接收者,需要对不同的应用程序进行区分。端口号就是用来实现这种区分的,每个应用程序都使用一个特定的端口号,以便在网络上准确传输数据。
例如,HTTP服务的默认端口号是80,SSH服务的默认端口号是22,SMTP服务的默认端口号是25。这意味着,如果你正在尝试与运行在目标计算机80端口上的HTTP服务器通信,那么你的计算机将会把所有发送到该端口的数据都发送给这个HTTP服务器。
需要注意的是,端口号范围从0到65535,其中1-1023是保留的端口号,用于知名服务。例如HTTP服务使用80端口,FTP服务使用21端口等。
传输层
传输层在网路中主要起到确定起点和终点的作用,而在传输层中常见的协议就是 UDP 协议和 TCP 协议,在这篇文章中我主要为大家分享关于 UDP 协议方面的知识。
UDP 报文协议格式

UDP 报文是由 8 个字节大小的报头部分和 UDP 载荷组成的。UDP 载荷就是我们网络传输的数据部分也就是完整的应用层数据报,网络传输的过程就类似于字符串拼接的过程,每到达一层,该层对应的应用层协议就会给上一层传输过来的数据报加上一个报头。
源端口号和目的端口号
因为网络传输需要知道是谁发送来的数据以及该数据要发送给谁,所以 UDP 报头中的,16位源端口号就是指传输数据的一方哪个端口号的程序发送的数据,16位目的端口号就是指将该数据发送到目的 IP 的哪个端口(应用程序)上。16个比特位能表示的范围是 0 ~ 65535 这也就跟我们的端口号的范围是吻合的。
UDP 长度
16位 UDP 长度是指整个 UDP 数据报的长度,整个长度包括 UDP 数据报也包括 UDP 载荷(数据部分)。16个比特位能表示的范围是 0~65535,也就是说:使用 UDP 协议最多能传输的数据的大小是 64 kb。那么这个 64 kb的数据在现在的生活中够用吗?显然是不够的,现在随随便便的一个图片都是几 mb ,更别说 kb 了。
如果我是用 UDP 协议传输一个大于64 kb 的数据会怎样呢?在使用 UDP 协议进行传输层的数据传输的时候,在 UDP 报头中会记录出 UDP 的长度,当接收方拿到数据报对数据报进行分用拆包的时候会根据 UDP 报头中存储的长度来读取数据,因为能存储的最大长度是64 kb,所以超出64 kb 的数据部分就不会被读取到,最终导致部分数据丢失,也就导致读取的数据有误。
既然两个字节大小的 UDP 长度已经不能满足现在的一般需求了,那么是否可以将表示 UDP 长度的两个字节改为4个字节、8个字节呢?这个做法实际上是可以的,但是道德上不可以,因为如果你将 UDP 长度改为4个字节或者 8 个字节的话,那么前面所有用 UDP 写的程序和现在写的程序进行交互的话就会出现问题,所以之前写的 UDP 相关的代码就需要做出更改,这是不切实际的。这个时候就有人提出了:是否可以将大的 UDP 数据报分成多个小的数据报然后进行传输呢?虽然可以是可以,但是当这个想法提出来的时候就遭到了反对,因为要想实现这个想法的话就需要额外做出很多的更改和测试。
因为 UDP 能够携带的数据大小受到限制,所以当在传输较大数据的时候,人们往往会选择 TCP 进行传输。
校验和
UDP校验和是在UDP数据报文中添加的一项用于检测数据传输是否有误的一种校验机制。它是一种简单的错误检测方法,通过给每个数据报添加一个校验和,接收方可以验证数据是否被篡改或损坏。
在UDP协议中,校验和是由发送端计算得出的,并在数据报中发送给接收端。接收端在收到数据后同样计算校验和,然后与接收到的校验和进行比较。如果两个校验和相同,那么接收端就认为数据是正确的,否则就认为数据在传输过程中出现了错误。
如何基于校验和来校验数据呢?
- 发送方把要发送的数据整理好成为 data1,然后根据一定的算法计算出校验和 checksu1.
- 发送方将这个整理好的数据 data1 和校验和 checksum1 通过网络一起发送出去。
- 接收方通过网络接收到 data2 和校验和 checksum1。
- 接收方通过相同的算法计算出校验和 checksum2.
- 判断校验和 checksum1 和 checksum2 是否相同。
如果 checksum1 不等于 checksum2,就说明 data1 数据和 data2 数据一定不一样
如果 checksum1 等于 checksum2,data1 数据和 data2 数据大概率是相同的.
这里 UDP 中的校验和的算法就是简单的 CRC 算法(循环冗余算法):把当前要计算校验和的数据的每个字节都进行累加,然后将这个和数据保存到两个字节的校验和当中,即使在计算校验和的过程中出现了溢出的问题也是没关系的,不会影响最终的结果。
但是这个 CRC 计算校验和方法不是很靠谱,当我前面一个字节在传输的过程中恰好变成了少 1 的数据,而后面的某个字节确变成了多 1 的情况,那么最后计算校验和的时候校验和是相等的,就会认为这个数据在传输的过程中没有出现问题,但实际上这个数据是出现了问题的。
除了 CRC 计算校验和的方法之外,还有一些计算校验和的方法——md5 / sha1,它们计算校验和的正确率可能更高,因为 md5 和 sha1 的计算方式类似,所以这里我们简单介绍一下 md5 计算校验和的方式。
md5 计算校验和的时候i会调用一系列的公式,通过这些公式最终会得到一个 校验和。
md5 计算校验和的特点:
- 定长
- 分散
- 不可逆
不管原始数据的长度相差有多大,最终计算出来的校验和的长度都是相等的。
定长
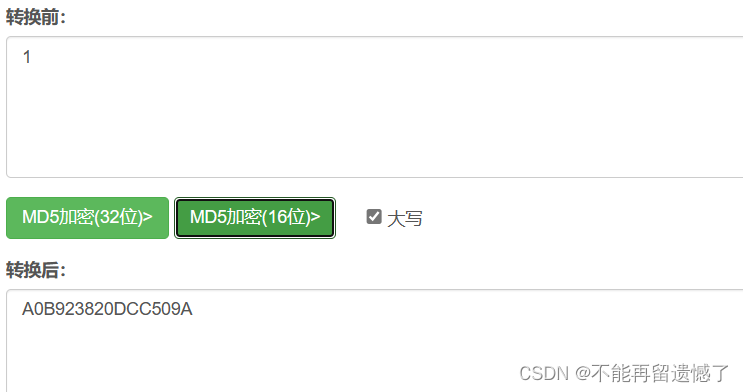
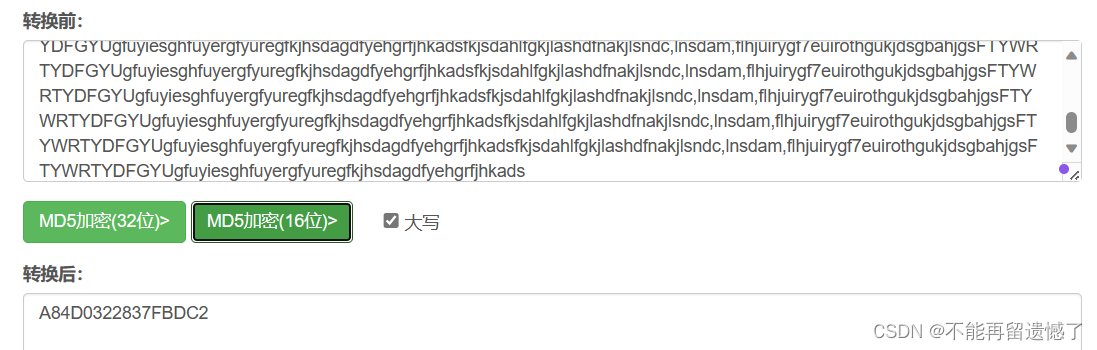
分散
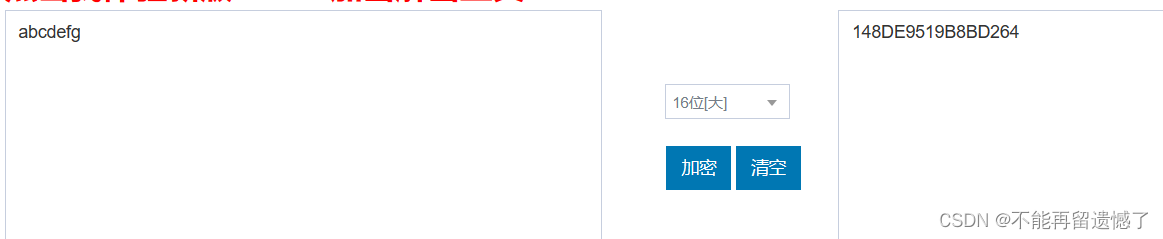

两个相差很小的字符串经过md5码加密之后的差别很大。
不可逆
数据经过 md5 加密之后不能根据 md5 转换后的数据得到原始数据,因为现在计算机的算力无法达到那么大的计算量。





![[SWPUCTF 2023 秋季新生赛]——Web方向 详细Writeup](https://img-blog.csdnimg.cn/img_convert/31411750ecae70fbd6261b5083491d21.png)