1.你先作个自我介绍吧
面试官您好,我叫张睿超,来自湖南长沙,大学毕业于湖南农业大学,是一名智能科学与技术专业的统招一本本科生。今天主要过来面试贵公司的Java后端开发工程师岗位。
大学里面主修的课程是Java、Python、数字图像处理、JavaEE。
大学期间,英语获得6级460分,参加过华为云的比赛,获得了全国高校绿色计算系列大赛团体三等奖。
我熟悉的技术栈在简历上都写了,我自己认为自己的亮点在以下几点:能进行简单的JVM调优;有实际处理高并发问题的经验;熟悉MySQL的操作,了解数据库调优原理;熟悉Linux的基本操作。
我自学C#两周、听学校讲解Python的Django框架2周,都写出了简单的项目;半年时间研究出了一个图像加密算法,并发表为了毕业论文。Java学习了一个学期、自学了2个月,之后在校企合作的项目中做出了这两个Java项目。
领导过小组作出Django框架的项目,参与过校企合作的两个Java项目。
了解到贵公司的业务需求偏向于xxx,我正好擅长xxx,所以我来应聘贵公司的Java开发岗位。
(或者衔接)
了解到贵公司的业务需求偏向于xxx,我最近做了一个xx项目,正好做了xxx,您看需不需要作一个简单的项目介绍。
2.你说一下这个IoC和AOP
IoC:(Inverse of Control)控制反转,也叫DI依赖注入,指的是将对象的创建权交给 Spring 容器去创建。(然后举例轮子和汽车)
其实,IoC有很多种方式。不仅是Spring技术中最常用的Bean注入,还有构造方法、Setter方法实现。
AOP:(Aspect Oriented Programming)面向切面编程,能增强Spring中具体业务的功能,能实现鉴权或公共字段填充的业务。
动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。
SpringMVC用的三级缓存而不是二级缓存,其中原因之一就是方便使用AOP。
关于SpringMVC使用三级缓存,我这里可以给你讲一下,……
关于我们用AOP做的公共字段填充,我这里可以给你讲一下,……
3.JWT了解过吗,有用过吗
了解的,有用过。
JWT就是JSON Web Token,是继Cookie、Session之后一个比较好用的身份验证技术。
Cookie是HTTP协议支持的技术,这是它的优点。
但它的缺点也很明显,它不支持移动端APP,比如Android、IOS;第二点是它不安全,用户自己可以禁用Cookie;第三点是它不能跨域。
Session则是基于Cookie的服务器会话跟踪技术,优点是存储在服务端,安全。
缺点也很明显,因为是基于Cookie的,Cookie自带的毛病它都有:移动端APP不能用、用户自己可以禁用、不能跨域;除此以外,搭建了集群的服务器它也无法使用;它还占用服务器内存。
而企业常用的JWT技术则完美解决了上述的问题。PC端、移动端,它都行;集群中,它也能用;不需要服务器存储,不给服务器带来存储压力。
如果要说它有什么缺点,那就是需要自己实现吧。
那么怎么实现呢?我们这样把JWT加入我们的登录流程:
首先浏览器中访问登录界面,校验用户登录成功后,我们后端就生成一个JWT令牌,并将这个JWT令牌返回给前端。
前端拿到JWT令牌后存起来,后续的请求的请求头都带上这个。
然后后端统一拦截就检查这个JWT,就完成了校验。
JWT令牌包括三部分:
Header头,记录令牌类型、签名算法等。 例如:{"alg":"HS256","type":"JWT"}
Payload有效载荷,携带一些自定义信息、默认信息等。 例如:{"id":"1","username":"Tom"}
Signature签名,防止Token被篡改、确保安全性。将header、payload,加入指定秘钥,通过指定签名算法计算而来。
4.es用过吗,你们是怎么用到的
我们用到了es,在我的外卖项目中,为了提供商家搜索的功能,我们设计了es的搜索流程。
首先,基本的搜索接口4方面分别是,请求方式POST,请求路径为/shopSearch/list,请求参数有关键词、页数、分页大小、排序方式,返回值为页面结果类。
首先定义好Controller;
然后准备设置好ES官方提供的Java语言客户端,Java HighLevel Rest Client,在启动类中创建一个对应Bean,初始化时传入ES客户端的ip地址;
最后写业务处理Service层。
- 首先准备请求Request
- 然后准备DSL,包括query和请求分页
- 第三步发送请求
- 第四步进行解析
解析的具体流程是:
- 对响应response.getHits()初步解析
- getTotalHits().value获取总条数
- 再getHits()获取文档数组
- 开始遍历,getSourcceAsString()获取文档source
- 然后反序列化parseObject
- 最后放入集合
- 最后的最后封装返回
然后,我们扩展基础搜索,加上过滤条件,比如在排序上,可以综合排序、销量优先、速度优先等;在优惠活动中,可以选择一些日常举办的活动;还有选择价格的范围等。

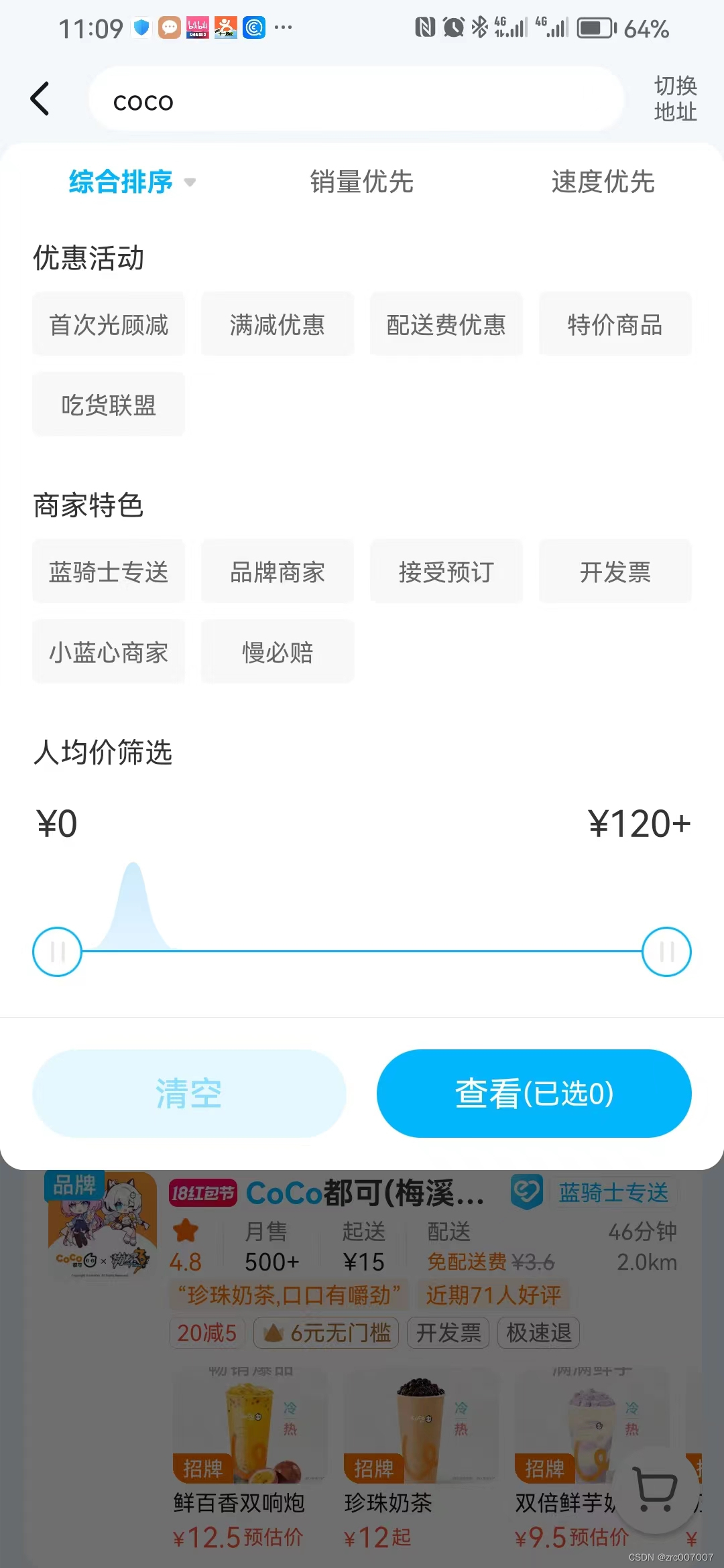
明确了业务之后,我们做具体的代码工作:
- 我们对对应传参的实体类进行修改,增加这些字段的选项
- 然后在业务逻辑,即service层中,在准备DSL的阶段增加绑定查询字段的步骤。
- 首先构建BoolQueryBuilder bool = new ~;
- 然后添加过滤条件:
- 分别判断传入的实体类中过滤参数不为空,比如优惠活动 params.getEvent()!=null && !params.getEvent().equals("");
- 一旦不为空,就对构建的BoolQueryBuilder进行过滤条件的构建,即bool.filter(QueryBuilders.termQuery("event", params.getEvent());
- 至于价格过滤,filter中的参数是这样的:QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice())
- 最后放入查询请求的source中, request.source().query(bool);
第二个扩展是添加根据地理位置选择就近的餐馆。
这个在请求和响应中分别添加排序的操作就可以。
第三个扩展是添加店家竞价排名。
我们用function_score查询实现,它包括了3个方面要确定:
- 过滤条件:查询出符合条件的,进一步进行分数计算。
- 算分函数:计算出来分数,以便进行比较。包括
- weight使用权重
- random_score计算随机数
- field_value_factor以文档中的某个字段值作为函数结果
- script_score自定义算分函数算法
- 运算模式:计算的分数和原始值,原始值是根据词频等计算出的,进行操作,得到最终结果。包括
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
我们这里确定的三个方面是:
- 过滤条件:添加isAD字段,为true则进行加权计算
- 算分函数:weight
- 运算模式:默认的multiply
代码层面的改动,
- 首先在实体类中添加isAD字段
- 然后在DSL中绑定过滤条件时,添加算分,即
FunctionScoreQueryBuilder functionScoreQuery = QueryBuilders.functionScoreQuery( // 原始查询,相关性算分的查询 boolQuery, // function score的数组 new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{ // 其中的一个function score 元素 new FunctionScoreQueryBuilder.FilterFunctionBuilder( // 过滤条件 QueryBuilders.termQuery("isAD", true), // 算分函数 ScoreFunctionBuilders.weightFactorFunction(10) ) }); - 最后suorce的不是bool,而是包装号的function的。
5.Neo4j数据库是怎么存数据的,里面有什么类型的节点,什么类型的路线
我们节点存的是机构,分为三种标签:一级转运中心、二级转运中心和节点。
节点的属性包括:Neo4j自带的id、业务id、名称、电话、地址、坐标等。
关系存的是路线,属性包括自带id和成本。
6.你说查询最短路线和成本最低路线,Neo4j查询语言是什么样的
Neo4j语句:
查询最短
MATCH path = shortestPath((start:AGENCY) -[*..10]-> (end:AGENCY))
WHERE start.bid = 123123 AND end.bid = 123456
RETURN path
查询成本最低
MATCH path = (start:AGENCY) -[*..10]->(end:AGENCY)
WHERE start.bid = 123123 AND end.bid = 123456
UNWIND relationships(path) AS r
WITH sum(r.cost) AS cost, path
RETURN path ORDER BY cost ASC, LENGTH(path) ASC LIMIT 1
Java语句:
查询最短
- 获取网点的类型
- 构造查询语句
- 执行查询
- 设置参数
- 设置响应数据类型
- 对结果进行封装处理
- 读取节点数据,进入stream流
- 取第一个标签作为类型
- 封装好经纬度数据
- 读取节点数据,进入stream流
@Override
public TransportLineNodeDTO findShortestPath(AgencyEntity start, AgencyEntity end) {
//获取网点数据在Neo4j中的类型
String type = AgencyEntity.class.getAnnotation(Node.class).value()[0];
//构造查询语句
String cypherQuery = StrUtil.format("MATCH path = shortestPath((start:{}) -[*..10]-> (end:{}))\n" +
"WHERE start.bid = $startId AND end.bid = $endId \n" +
"RETURN path", type, type);
//执行查询
Optional<TransportLineNodeDTO> optional = this.neo4jClient.query(cypherQuery)
.bind(start.getBid()).to("startId") //设置参数
.bind(end.getBid()).to("endId")//设置参数
.fetchAs(TransportLineNodeDTO.class) //设置响应数据类型
.mappedBy((typeSystem, record) -> { //对结果进行封装处理
PathValue pathValue = (PathValue) record.get(0);
Path path = pathValue.asPath();
TransportLineNodeDTO dto = new TransportLineNodeDTO();
// 读取节点数据
List<OrganDTO> nodeList = StreamUtil.of(path.nodes())
.map(node -> {
Map<String, Object> map = node.asMap();
OrganDTO organDTO = BeanUtil.toBeanIgnoreError(map, OrganDTO.class);
//取第一个标签作为类型
OrganTypeEnum organTypeEnum = OrganTypeEnum.valueOf(CollUtil.getFirst(node.labels()));
organDTO.setType(organTypeEnum.getCode());
//查询出来的数据,x:经度,y:纬度
organDTO.setLatitude(BeanUtil.getProperty(map.get("location"), "y"));
organDTO.setLongitude(BeanUtil.getProperty(map.get("location"), "x"));
return organDTO;
})
.collect(Collectors.toList());
dto.setNodeList(nodeList);
//提取关系中的 cost 数据,进行求和计算,算出该路线的总成本
double cost = StreamUtil.of(path.relationships())
.mapToDouble(relationship -> {
Map<String, Object> objectMap = relationship.asMap();
return Convert.toDouble(objectMap.get("cost"), 0d);
}).sum();
dto.setCost(cost);
//取2位小数
dto.setCost(NumberUtil.round(dto.getCost(), 2).doubleValue());
return dto;
}).one();
return optional.orElse(null);
}查询成本最优,略
7.你的项目是前端后端都有吗,前端有什么了解
前端我学过HTML、CSS、JS的基础,接触过一些Vue、Ajax的算法,了解最新的技术中有饿了么开发的ElementUI等。
8.你的整型数据预测,这个是做的什么预测
这个做的是拨叉整型数据的预测。拨叉是汽车上的一个零件,像一把只有两个头的叉子。从塑型的机器中做出来的初始拨叉形状精度还达不到,需要二次整型。其中,机器的参数就是我们的输入,整型的形变量就是我们的输出。我们用已经测好的数据作为训练集样本,以期预测输入参数后的形变量。
9.我看你还做了个人脸识别,是自己做的吗
是我们组做的,我是组长,负责其他模块,对这个人脸识别了解一点。
这个人脸识别调用的是训练好的模型,用opencv做的。我还记得组员解决不了,我找到了源码给他们看,他们自己看完后就完成进度了。
10.核函数了解吗
了解。它是一种数学函数,能将高维数据经过它数学函数的计算降成低维结果。
核函数有很多应用场景,其中之一就是替代SVM(支持向量机)中计算距离的函数,方便对数据分类。
11.SVM用什么核函数知道吗
一般有线性核,除此之外还有高斯核、高斯径向基函数、Sigmoid核等。
12.论文的创新点是什么
我结合了该领域的两种主流思想,位图标记与位图嵌入,并运用在经典算法中,实现了嵌入秘密信息的能力上的进步。
13.Java的基本数据类型有哪些
四类八种。
巴拉巴拉
14.说一下==和equals的区别
- “==”是运算符,如果是基本数据类型,则比较存储的值;如果是引用数据类型,则比较所指向对象的地址值。
- equals是Object的方法,比较的是所指向的对象的地址值,一般情况下,重写之后比较的是对象的值。
(摘自详解“==”和equals的区别)
15.Spring的配置文件有几种
3种。properties、yml和yaml。优先级顺序是:
properties>yml>yaml
此外,还有两种设置参数的方式,
一种是Java系统属性配置,格式为:-Dkey=value,这个开发人员偶尔用。例如:
-Dserver.port=9000还有一种是命令行参数,格式为:--key=value,这个测试人员经常用。例如:
--server.port=10010总结,有3种配置文件。
此外,这三种配置文件,加上5种设置参数方式,优先级如下(从低到高):
- application.yaml(忽略)
- application.yml (企业实用)
- application.properties
- java系统属性(-Dxxx=xxx)
- 命令行参数(--xxx=xxx)(测试人员实用)
16.StringBuilder和StringBuffer有什么区别,效率的比较呢
StringBuilder是线程不安全的,效率比后者快;
StringBuffer是线程安全的,效率比前者慢;
对字符串拼接操作时,都比String快。
17.Linux想要获取当前文件夹的路径怎么办
pwd
18.有没有做项目的部署,部署过哪些项目
我们用Docker做项目的部署。
Docker是一个容器管理工具,它能将某一个组件,比如MySQL,需要运行的环境单独封装,在Linux上跑,这样就能方便地部署与使用。
首先安装Docker,镜像源之类的就不说了,直接
yum install -y docker-ce关闭防火墙,systemctl start docker启动,docker -v查看版本,没问题就装好了。
然后是拉取镜像,比如拉取mysql,直接
docker pull mysql:latest19.Python的Pytest框架你有了解吗
20.写过接口服务吗,后端和前端怎么交互的
写过。
前端呈现页面,用户通过浏览器操作页面,不同的操作发送HTTP请求给后端服务器,服务器对这些请求作出反应,处理业务,并查找数据库,返回响应结果给前端。
21.数据库有用过什么
有。有用过关系型数据库MySQL、非关系型数据库MongoDB、Neo4j等。
22.MySQL分类查询怎么查询
group by
23.如果我想复制一张表,该怎么写,如果我要删除/创建呢
复制:
create table 表1 select * from 表2
删除:
drop table 表1
创建:
create table 表1 if not exists
24.写过比较复杂的查询吗,复杂查询是什么样子的
写过。复杂查询通常涉及多表,需要灵活运用内外连接。比如两个表table1、table2,连接的字段为id,则写为如下:
select * from table1 as t1 inner join table2 as t2 on t1.id = t2.id where 条件1, 条件2