Python之解析式和生成器表达式
列表解析式
- 列表解析式List Comprehension,也叫列表推导式。
语法
- [返回值 for 元素 in 可迭代对象 if 条件]
- 使用中括号[],内部是for循环,if条件语句可选
- 返回一个新的列表
列表解析式是一种语法糖
- 编译器会优化,不会因为简写而影响效率,反而因优化提高了效率
- 减少程序员工作量,减少出错
- 简化了代码,增强了可读性
集合解析式
语法
- {返回值 for 元素 in 可迭代对象 if 条件}
- 列表解析式的中括号换成大括号{}就变成了集合解析式
- 立即返回一个集合
字典解析式
语法
- {key:value for 元素 in 可迭代对象 if 条件}
- 列表解析式的中括号换成大括号{},元素的构造使用key:value形式
- 立即返回一个字典
生成器表达式
语法
- (返回值 for 元素 in 可迭代对象 if 条件)
- 列表解析式的中括号换成小括号就行了
- 返回一个生成器对象
和列表解析式的区别
- 生成器表达式是按需计算(或称惰性求值、延迟计算),需要的时候才计算值
- 列表解析式是立即返回值
生成器对象
- 可迭代对象
- 迭代器
| 生成器表达式 | 列表解析式 |
|---|---|
| 延迟计算 | 立即计算 |
| 返回可迭代对象器,可以迭代 | 返回可迭代列表,不是迭代器 |
| 只能迭代一次 | 可反复迭代 |
生成器表达式和列表解析式对比
- 计算方式
- 生成器表达式延迟计算,列表解析式立即计算
- 内存占用
- 单从返回值本身来说,生成器表达式省内存,列表解析式返回新的列表
- 生成器没有数据,内存占用极少,使用的时候,一次返回一个数据,只会占用一个数据的空间
- 列表解析式构造新的列表需要为所有元素立即占用掉内存
- 计算速度
- 单看计算时间看,生成器表达式耗时非常短,列表解析式耗时长
- 但生成器本身并没有返回任何值,只返回了一个生成器对象
- 列表解析式构造并返回了一个新的列表
x = [] # 构建一个新的列表
for i in range(10):
x.append(i ** 2)
# 循环写法,求平方
x
# 返回结果:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
[ i ** 2 for i in range(10)]
# 解析式的写法
# 返回结果:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
%%timeit
x = [] # 构建一个新的列表
for i in range(10):
x.append(i ** 2)
# 查看效率问题,1.85微秒
# 返回结果:1.85 µs ± 10.5 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
%timeit [ i ** 2 for i in range(10)]
# 查看效率问题,1.75微秒还快了一点
# 返回结果:1.75 µs ± 6.28 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
[ (i+1, i) for i in range(5)]
# 列表中套元组,一个二元对象
# 返回结果:[(1, 0), (2, 1), (3, 2), (4, 3), (5, 4)]
dict([(i+1, i) for i in range(10)])
# 可以创建字典
# 返回结果:{1: 0, 2: 1, 3: 2, 4: 3, 5: 4, 6: 5, 7: 6, 8: 7, 9: 8, 10: 9}
[range(i) for i in range(5)]
# 创建5个range对象
# 返回结果:[range(0, 0), range(0, 1), range(0, 2), range(0, 3), range(0, 4)]
x = []
for i in range(7):
if i > 4:
for j in range(20, 25):
if j > 23:
x.append((i, j))
# 想下这个结果
x
# 返回结果:[(5, 24), (6, 24)]
[(i, j) for i in range(7) if i > 4 for j in range(20, 25) if j > 23]
# 解析式方法
# 返回结果:[(5, 24), (6, 24)]
{i for i in range(9)}
# 集合解析式
# 返回结果:{0, 1, 2, 3, 4, 5, 6, 7, 8}
{i:i+1 for i in range(5)}
# 字典解析式
# 返回结果:{0: 1, 1: 2, 2: 3, 3: 4, 4: 5}
[i for i in range(5)], list(range(5)), [*range(5)]
# 等价
# 返回结果:([0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4])
[str(i) for i in range(5)], list(map(str, range(5)))
# map变形
# 返回结果:(['0', '1', '2', '3', '4'], ['0', '1', '2', '3', '4'])
{chr(0x41 + i) for i in range(5)}
# 获取Ascii码表的字符
# 返回结果:{'A', 'B', 'C', 'D', 'E'}
{chr(0x41 + i):i for i in range(5)}
# 这样就能构建字典了
# 返回结果:{'A': 0, 'B': 1, 'C': 2, 'D': 3, 'E': 4}
{i:j for i in 'abcd' for j in range(3)}
# 思考一下这个得到结果,为什么最后只有4个?
# 返回结果:{'a': 2, 'b': 2, 'c': 2, 'd': 2}
{'a':0, 'a':1, 'a':2}
# 覆盖问题一定要思考
# 返回结果:{'a': 2}
{i:j for i in 'abcd' for j in range(3, 0, -1)}
# 思考的点,覆盖问题,range前包后不包
# 返回结果:{'a': 1, 'b': 1, 'c': 1, 'd': 1}
生成器
x = (i + 1 for i in range(5))
# 这个是什么?元组解析式吗?
x
# 元组的方式是生成器对象,0x那一串是内存地址
# 返回结果:<generator object <genexpr> at 0x000001447C22B120>


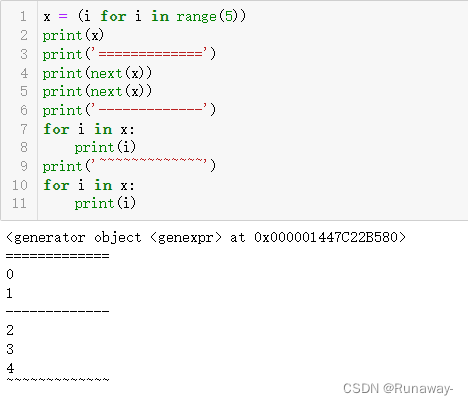

- 列表是可迭代对象,生成器也是可迭代对象
- 生成器也是迭代器一种,但列表不是
- 迭代器特点:
1.一次性迭代,指针不能回头
2.类型range(range不是迭代器),是惰性的。使用next挤一下
3.for循环可以迭代,但是如果已经到头,for相当于迭代空容器。但是next不能迭代,如果使用next会抛出Stop Iteration异常
4.迭代器不可以索引
- 列表立即构建,元素都在了,可以反复使用;生成器对象会立即产生,但是什么元素都没有
- 内存占用:内存:列表元素内存立即都占用了;生成器在内存中只占用了一个生成器对象大小的内存
- 计算角度:使用时,列表中元素就在那里,随手拿就能用;生成器才开始热身造元素,造好了返回
列表预先计算,放在内存中,我们称为 空间换时间 预热
生成器懒计算,等待的时长是否能够容忍,延时计算