module的动机
C++20中新增了四大特性之一的模块(module),用以解决传统的头文件在编译时间及程序组织上的问题。
modules 试图解决的痛点
能最大的痛点就是编译慢, 头文件的重复替换, 比如你有多个翻译单元, 每一个都调用了 iostream, 就得都处理一遍. 预处理完的源文件就会立刻膨胀. 真的会很慢.
有了 modules 以后, 我们可以模块化的处理. 已经编译好的 modules 直接变成编译器的中间表示进行保存, 需要什么就取出什么, 这就非常地快速了.
比如你只是用了 cout 的函数, 那么编译器下次就不需要处理几万行, 直接找 cout 相关函数用就行了. 太快了, 太快了! Google 使用 modules 的经验表明, 编译速度飞快.
除此之外, 封装什么的也可以做得很好, 可以控制 modules 的哪些部分可以暴露于外界. 这些也是非常不错的地方.
可以看倒数第二节, C++ 之父介绍了 modules 的发展进程.
modules 的痛点
modules 目前没有构建系统.
modules 的构建必须是按照依赖关系进行构建的. 也就是说子模块必须提前构建, 这就对传统的并行构建系统提出了挑战. 手工写编译命令是权宜之计, 想用上像 cmake 这样的构建工具, 得等到未来才有了.
#include头文件有下面这些负面影响:
- 低效:头文件的本职工作是提供前置声明,而提供前置声明的方式采用了文本拷贝,文本拷贝过程不带有语法分析,会一股脑将需要的、不需要的声明全部拷贝到源文件中。
- 传递性:最底层的头文件中宏、变量等实体的可见性,可以通过中间头文件“透传”给最上层的头文件,这种透传会带来很多麻烦。
- 降低编译速度:加入 a.h 被三个模块包含,则 a 会被展开三次、编译三次。
- 顺序相关:程序的行为受头文件的包含顺影响,也受是否包含某一个头文件影响,在 C++ 中尤为严重(重载)。
- 不确定性:同一个头文件在不同的源文件中可能表现出不同的行为,导致这些不同的原因,可能源自源文件(比如该源文件包含的其他头文件、该源文件中定义的宏等),也可能源自编译选项。
module模块机制优势:
- 无需重复编译:一个模块的所有接口文件、实现文件,作为一个翻译单元,一次编译后生成 pcm,之后遇到 Import 该模块的代码,编译器会从 pcm 中寻找函数声明等信息,该特性会极大加快 C++ 代码的编译速度。
- 隔离性更好:模块内 Import 的内容,不会泄漏到模块外部,除非显式使用 export Import 声明。
- 顺序无关:Import 多个模块,无需关心这些模块间的顺序。
- 减少冗余与不一致:小的模块可以直接在单个 cppm 文件中完成实体的导出、定义,但大的模块依然会把声明、实现拆分到不同文件。
- 子模块、Module Partition 等机制让大模块、超大模块的组织方式更加灵活。
- 全局模块段、Module Map 制使得 Module 与老旧的头文件交互成为可能。
为什么会变快?
modules 编译出来会有两个部分:
编译器缓存, 基本上代表了全部源代码信息. 编译器已经处理好了源代码, 并且把内部缓存留了下来. 下次读取的时候会更快. 主流三大编译器都有 lazy loading 的功能, 可以只取出需要的部分. 这不就快了?
编译出来的 object, 这个 object 只有链接的时候才需要,而且不需要特别处理, 也不需要再次编译.
所以啊, 就是有了这个缓存, 才会让它更快. 各个编译器不能通用哦. 而且编译选项不同的时候, 内部的表示不一样, 所以也不能通用.
这个缓存文件:
在 Clang 那里, 叫 BMI, 后缀名是 .pcm.
在 GCC 那里, 叫 CMI, 后缀名是 .gcm.
在 MSVC 那里, 叫 IFC, 后缀名是 .ifc.
对于这个缓存文件, 这三家编译器还使用了 lazy loading 的技术. 也就是说需要哪些定义/声明就加载哪些. 编译器的这种 lazy loading 进一步提升了速度.
模块单元(Module Unit)
C++中的基本编译单元称为“翻译单元(即translation unit)”。一个翻译单元由一个源文件和该源文件所直接或间接包括的头文件的内容组成。C++20中的模块是一种新的翻译单元,称为模块单元。
为了支持module, c++20 引入了三个关键字export/import/module。
module关键字:module用于声明一个模块,其前方也可以带上export。
export关键字:export用于声明一个module名和标记内容的导出性。
import关键字:import用于导入一个module。
模块声明
翻译单元可以有一个模块声明,这种情况下它们会被视为模块单元。模块声明在有提供时必须是翻译单元的首个声明(后面提到的全局模块片段除外)。每个模块单元都对应一个模块名(可以带一个分区),它在模块声明中提供。
模块名包含由点分隔的一个或多个标识符(例如:mymodule,mymodule.mysubmodule,mymodule2...)。点没有内在含义,不过它们会非正式地用于表示继承关系。
一个具名模块是一组模块名相同的模块单元。
声明中带有关键词 export 的模块单元是模块接口单元。其他模块单元被称为模块实现单元。
对于每个具名模块,必须有恰好一个未指定模块分区的模块接口单元。这个模块单元被称为主模块接口单元。在导入对应的具名模块时可以使用它导出的内容。
// (每行表示一个单独的翻译单元)
export module A;// 为具名模块 'A' 声明主模块接口单元
module A;// 为具名模块 'A' 声明一个模块实现单元
module A;// 为具名模块 'A' 声明另一个模块实现单元,比如:一个模块接口单元对应多个模块实现单元时
export module A.B;// 为具名模块 'A.B' 声明主模块接口单元
module A.B;// 为具名模块 'A.B' 声明一个模块实现单元
导出声明和定义
模块接口单元可以导出声明和定义,这些内容可以导入到其他翻译单元。它们可以有 export 关键词作为前缀,或者处于 export 块中。
使用export关键字从模块中导出实体(如,类、函数、常量、其他模块等)。任何没有从模块导出的内容只在该模块可见。所有导出实体的集合称为模块接口。
被导出的C++实体需在第一次声明时用export关键字,其后的声明或定义均不需再指定export。
export 声明
| export { 声明序列(可选) } |
| export module 模块名; |
export module A; // 为具名模块 'A' 声明主模块接口单元
// hello() 会在所有导入 'A' 的翻译单元中可见
export char const* hello() { return "hello"; }
// world() 不可见
char const* world() { return "world"; }
// one() 和 zero() 均可见
export
{
int one() { return1; }
int zero() { return0; }
}
export class MyClass
{
……
};
// 也可以导出命名空间:hi::english() 和 hi::french() 均可见
export namespace hi
{
char const* english() { return "Hi!"; }
char const*french() { return"Salut!"; }
}导入模块和头文件
模块可以通过导入声明导入:
export(可选) import 模块名 属性(可选) ;
所有在给定具名模块的模块接口单元中导出的声明和定义都会在使用导入声明的翻译单元中可见。
导入的声明在模块接口单元里可以再导出。也就是说,如果模块 A 导入 B 后又导出,那么导入 A 也会使所有从 B 导出的内容可见。
在模块单元里,所有导入声明(包括带导出的导入)必须集中在模块声明后以及所有其他声明前。
/// A.cpp ('A' 的主模块接口单元)
export module A;
export char const* hello() { return "hello"; }
/// B.cpp ('B' 的主模块接口单元)
export module B;
export import A;
export char const* world() { return "world"; }
/// main.cpp (非模块单元)
#include <iostream>
import B;
int main()
{
std::cout << hello() << ' ' << world() << '\n';
}以上简单从概念和定义上介绍了下module/export/import三个关键字;
现在我们通过例子进一步来详细介绍。
模块的编译:
所有的c++头文件,都是所谓的可导入头文件,可以通过import声明导入。
//test_module.cpp
import <iostream>; //导入iostream module
int main()
{
std::cout << "Hello, World" << std::endl;
}现在我们通过g++编译器来进行编译test_module.cpp文件,module是C++20加的,所以编译要加上-std=c++20,又因为import只有在开启-fmodules-ts下才能使用,所以还要加上-fmodules-ts:
g++ -fmodules-ts -std=c++20 test_module.cpp -o hellworld
会出现如下报错:
In module imported at test_module.cpp:3:1:
/opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/iostream: error: failed to read compiled module: No such file or directory
/opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/iostream: note: compiled module file is ‘gcm.cache/./opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/iostream.gcm’
/opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/iostream: note: imports must be built before being imported
/opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/iostream: fatal error: returning to the gate for a mechanical issue
compilation terminated.
在C++20中STL库iostream的module并不会自动生成,而需要我们使用生成。要到C++23才会完成STL库的molule化;
如果在导入某个头文件编译报错为没有这个文件时候,需要加上编译选项 -xc++-system-header [需要添加的头文件名字], 需要注意的是对于c语言的某些头文件兼容还不够好,并不是所有的头文件都可以导入,这时候,需要使用传统的#include的方式加入。而且它必须出现在全局模块片段中,在任何具名模块之前!全局模块片段我们稍后会讲解;
可以使用下面的命令生成iostream的module:
g++ -std=c++20 -fmodules-ts -xc++-system-header iostream 或者 g++ -std=c++20 -fmodules-ts -x c++-system-header iostream
这个操作会在当前目录下生成一个gcm.cache目录,其目录结构如下所示:
tree gcm.cache/
gcm.cache/
└── opt
└── gcc
└── x86_64
└── 12.2.0a-1
└── include
└── c++
└── 12.2.0
└── iostream.gcm
7 directories, 1 file
其次,在编译test_module.cpp 时需要添加-fmodules-ts的flag,即使用下面的编译语句:
g++ test_module.cpp -o testModule -std=c++20 -fmodules-ts
经过这样的操作之后,可以成功的编译,并打印Hello, World
./testModule
Hello, World
上面的例子说明了如何生成module,接下来我们通过一个简单的例子来说明如何使用module;一般gcc编译时推荐模块接口单元使用.cppm后缀名文件;
//helloworld.cpp
export module helloworld; // 模块声明
import <iostream>; // 导入声明
import <string>; // 导入声明
//https://stackoverflow.com/questions/70456868/vector-in-c-module-causes-useless-bad-file-data-gcc-output
//namespace std _GLIBCXX_VISIBILITY(default){}
export void hello() // 导出声明
{
std::string str = "Hello world!";
std::cout << str << std::endl;
}
// main.cpp
import helloworld; // 导入声明
import <iostream>;
import <string>;
int main()
{
hello();
}首先我们手动生成iostream和string的module:
g++ -c -std=c++20 -fmodules-ts -x c++-system-header iostream string
-c选项: Compile and assemble, but do not link.
可以看到在当前目录下生成
tree gcm.cache/
gcm.cache/
└── opt
└── gcc
└── x86_64
└── 12.2.0a-1
└── include
└── c++
└── 12.2.0
├── iostream.gcm
└── string.gcm
7 directories, 2 files
当扩展名为helloworld.cppm时
g++ -fmodules-ts -std=c++20 helloworld.cppm main.cpp -o helloworld
编译报错:
/usr/bin/ld:helloworld.cppm: file format not recognized; treating as linker script
/usr/bin/ld:helloworld.cppm:1: syntax error
collect2: error: ld returned 1 exit status
当扩展名为helloworld.cpp时
g++ -fmodules-ts -std=c++20 helloworld.cpp main.cpp -o helloworld
编译成功,但是在我的系统中执行./helloworld时又报错如下:
./helloworld
./helloworld: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by ./helloworld)
./helloworld: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found (required by ./helloworld)
./helloworld: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.29' not found (required by ./helloworld)
目前编译已经成功了,是缺少库的问题,先不管了!
例1:
//my_module.cppm
export module myModule; //module关键字指明这是一个模块,export关键字指明这是一个模块接口单元
import <iostream>; //导入iostream
void internal_function()//这是一个只在该模块内部可见的函数,不可导出
{
std::cout << "I am internal function";
}
export void say_hello() //export关键字指明本模块导出函数say_hello()
{
std::cout << "hello! ";
internal_function();
std::cout << std::endl;
}
//export void say_world(); //导出函数say_world, 函数在此处只提供声明
//当需要导出的C++实体太多时,不必一一指定,可以在下面的大括号中统一指定
export
{
int var;
void i_am_export_function(){ std::cout << "I am export function" << std::endl; }
//other export entity
}
// main.cpp
import myModule;
int main()
{
say_hello();
i_am_export_function();
return 0;
}首先我们手动生成iostream的module:
g++ -c -std=c++20 -fmodules-ts -x c++-system-header iostream
编译:
g++ -fmodules-ts -std=c++20 my_module.cppm main.cpp -o testmain
/usr/bin/ld:A.cppm: file format not recognized; treating as linker script
/usr/bin/ld:A.cppm:2: syntax error
collect2: error: ld returned 1 exit status
这里需要加上-x c++, 详见:https://gcc.gnu.org/onlinedocs/gcc/C_002b_002b-Modules.html#DOCF2
g++ -fmodules-ts -std=c++20 -x c++ my_module.cppm main.cpp -o testmain
例2:
//A.cpp
export module A; // (1)declares the primary module interface unit for named module 'A'
// hello() will be visible by translations units importing 'A'
export char const* hello() { return "hello"; } //(2)
// world() will NOT be visible.
char const* world() { return "world"; } //(3)
// Both one() and zero() will be visible.
export // (4)
{
int one() { return 1; }
int zero() { return 0; }
}
// Exporting namespaces also works: hi::english() and hi::french() will be visible.
export namespace hi //(5)
{
char const* english() { return "Hi!"; }
char const* french() { return "Salut!"; }
}语句1声明了一个模块的名字。
语句2声明hello函数是可以导出的。
语句3没有export,代表其是不可以导出的。
语句4同时导出了两个函数。
语句5导出了整个namespace
// main.cpp (非模块单元)
#include <iostream>
import A;
int main()
{
std::cout << hello() << std::endl;
//std::cout << world() << std::endl; //error: ‘world’ was not declared in this
std::cout << one() << std::endl;
std::cout << hi::english() << std::endl;
}编译: g++ -fmodules-ts -std=c++20 A.cpp main.cpp -o testmain
输出:
./testmain
hello
1
Hi!
全局模块(global module)
当我们通过module关键字声明一个模块时,从声明语句后开始,我们就再不允许通过#include来导入头文件了。C++标准规定需用import关键字导入头文件,或者在全局模块中用#include来导入头文件这一方法来作为过渡。
如果一个模块单元有一个全局模块片段,那么它的首个声明必须是 module。然后在全局模块片段中只能出现预处理指令(例如#include,#define等)。然后用一个标准的模块声明结束这个全局模块片段,后面就是模块内容。
由于标准库的大多数头文件尚未模块化,通全局模块段则可以进行方便的过渡。
module;
预处理指令序列(可选)
模块声明
//helloworld.cpp
module; //声明一个全局模块片段,预处理指令#include必须出现在该行之后、模块声明之前
#include <iostream> //传统方式导入头文件
#include <string>
export module helloworld; // 模块声明
export void hello() // 导出声明
{
std::string str = "Hello world!";
std::cout << str << std::endl;
}
// main.cpp
import helloworld; // 导入声明
int main()
{
hello();
}编译: g++ -fmodules-ts -std=c++20 helloworld.cpp main.cpp -o helloworld
模块单元
通常,模块由多个模块单元组成。模块单元是翻译兰苑,是属于一个模块;所有模块单元都必须以某种方式进行编译。即使它们只包含声明已经放在传统代码的头文件中,需要进行某种预编译。文件被转换为内部二进制格式,这可以用来避免您必须编译相同的代码一次又一次。但是,我们有不同的方法将模块拆分为多个文件:
•模块实现单元允许程序员只提供以传统方式编译的代码进入对象文件。
•内部分区允许程序员提供仅在内部可见的声明和定义模块。然而,即使只是声明,它们也是预编译的,以避免多次编译。
•接口分区允许程序员将导出的模块API拆分为多个文件。
接口与实现分离
当模块的规模变大、接口变多之后,将所有的实体定义都放在模块接口文件中会非常不利于代码的维护,C++20的模块机制还支持接口与实现分离。
module_hello.cppm:我们假设say_hello_to、foo、bar等函数十分复杂,.cppm文件中只包含函数的声明;
//module_hello.cppm //模块接口文件
export module hello; //module关键字指明这是一个模块,export关键字指明这是一个模块接口单元
import <iostream>;
import <string_view>;
void internal_helper();
export void say_hello_to(const std::string_view&);
//缩写的函数模板,C++20新糖果
export auto square(const auto& x)
{
return x*x;
}
export void foo();
export void bar();
//module_hello.cpp //模块实现文件
module hello; //
void internal_helper()
{
//do something;
}
void say_hello_to(const std::string_view& something)
{
internal_helper();
std::cout << "Hello " << something << " !" << std::endl;
return;
}
void foo()
{
//do something;
}
void bar()
{
//do something;
}
//main.cpp
import hello;
import <iostream>;
import <string>;
import <string_view>;
int main(void)
{
std::string str = " C++ 20 module";
say_hello_to(str);
std::cout << square(10);
foo();
bar();
return 0;
}编译:
g++ -c -std=c++20 -fmodules-ts -x c++-system-header iostream string string_view
g++ -fmodules-ts -std=c++20 -x c++ hello.cppm hello.cpp main.cpp -o split
整个hello模块分成了 module_hello.cppm和module_hello.cpp两个文件,前者是模块接口文件(module声明前有export关键字),后者是模块实现文件(module implementation file)。当前各大编译器并未规定模块接口文件的后缀必须是cppm。
模块实现文件中不能export任何实体。
函数模板,比如代码中的square函数,定义必须放在模块接口文件中,使用auto返回值的函数,定义也必须放在模块接口文件。
注意:当头文件中的类定义中包含方法的实现,那么这些方法是隐式的内联,尽管没有使用inline关键字标识他们。对于在模块接口文件中的类定义里的方法实现来说,却不太一样。如果要变成内联方法,就需要使用inline关键字显示标识他们。
同一个模块多个实现单元(模块实现单元)
首先,我们有一个主模块接口单元,它定义了我们导出的内容:
//mod1.cppm
module; // start module unit with global module fragment
#include <string>
#include <vector>
export module Mod1; // module declaration
struct Order //An internal data structure Order
{
int count;
std::string name;
double price;
Order(int c, std::string n, double p)
: count{c}, name{n}, price{p}
{
}
};
export class Customer
{
private:
std::string name;
std::vector<Order> orders;
public:
Customer(std::string n)
: name{n}
{
}
void buy(std::string ordername, double price)
{
orders.push_back(Order{1, ordername, price});
}
void buy(int num, std::string ordername, double price)
{
orders.push_back(Order{num, ordername, price});
}
double sumPrice() const;
double averagePrice() const;
void print() const;
};要提供不随模块导出的源代码,可以使用模块实现单元。
他们像普通的CPP翻译单元一样,使用它们应用于特定模块的前置声明。我们可以拥有任意数量的实现单元。在我们的示例中,我提供了两个,一个用于实现
数字运算和一个用于实现I/O运算。数字运算的模块实现单元如下所示:
//mod1price.cpp
module Mod1; // implementation unit of module Mod1
double Customer::sumPrice() const
{
double sum = 0.0;
for (const Order& od : orders)
{
sum += od.count * od.price;
}
return sum;
}
double Customer::averagePrice() const
{
if (orders.empty())
{
return 0.0;
}
return sumPrice() / orders.size();
}这是一个模块实现单元,因为它以module开头,module Mod1这个声明隐式导入主模块接口,因此类型order和customer是已知的,我们可以直接提供其成员的实现功能。
注意,模块实现单元不导出任何内容。仅允许在模块接口中导出,模块接口是用export module声明的(请记住,只有一个主模块每个模块允许的接口)。
同样,模块实现单元可以从全局模块片段开始,我们可以在I/O模块实现单元:
//mod1io.cpp
module; // start module unit with global module fragment
#include <iostream>
#include <format> //gcc 13.1
module Mod1; // implementation unit of module Mod1
void Customer::print() const
{
// print name:
std::cout << name << ":\n";
// print order entries:
for (const auto& od : orders)
{
std::cout << std::format("{:3} {:14} {:6.2f} {:6.2f}\n",
od.count, od.name, od.price, od.count * od.price);
}
//rint sum:
std::cout << std::format("{:25} ------\n", ' ');
std::cout << std::format("{:25} {:6.2f}\n", " Sum:", sumPrice());
}使用模块:
//testmod1.cpp
#include <iostream>
import Mod1;
int main()
{
Customer c1{"Kim"};
c1.buy("table", 59.90);
c1.buy(4, "chair", 9.20);
c1.print();
std::cout << " Average: " << c1.averagePrice() << '\n';
}编译: g++ -fmodules-ts -std=c++2b -x c++ mod1.cppm mod1price.cpp mod1io.cpp testmod1.cpp testmod1
可达性与可见性(Reachable versus Visible)
在使用模块时,一个新的区别开始发挥作用:可达性与可见性。export数据时,我们可能无法看到并直接使用模块的名称或符号;尽管我们可能能够间接使用它。
当一个export API提供了访问没有被export类型时,会出现符号是可达的但是不可见的情况;考虑如下示例:
//reach.cppm
export module modReach; // declare module ModReach
struct Data // declare a type not exported
{
int value;
};
export struct Customer // declare an exported type
{
public:
Customer(int i): data{i}
{
}
Data getData() const // yield not exported type
{
return data;
}
private:
Data data;
};当import这个模块时,类型Data是不可见的因此不能直接使用:
import modReach;
Data d{11}; //error: ‘Data’ was not declared in this scope
Customer c{42};
const Data& dr = c.getData(); //error: ‘Data’ does not name a type
然而,如果间接使用的话,类型Data是可达的:
import modReach;
Customer c{42};
const auto& dr = c.getData(); //OK: type Data is used
auto d = c.getData(); //OK: d has type Data
std::cout << d.value << std::endl; //OK:type Data is used甚至可以申明类型Data的对象如下:
decltype(std::declval<Customer>().getData()) d; // d has non-exported type Data
模块传递性(可见性)
需要注意的是导入的模块不具有传递性,比如我们在模块B中导入模块A,则模块B中能看到模块A中导出的内容。main.cpp中导入了B,则在main.cpp中可以看到B中的导出接口,但是看不到A中的导出接口;
//A.cpp ('A' 的主模块接口单元)
export module A;
export char const* hello() { return "hello"; }
// B.cpp ('B' 的主模块接口单元)
export module B;
import A; //模块 A 导入 B 模块,在其他导入 B 模块的地方 A 模块时不可见的
export char const* world() { return "world"; }
// main.cpp (非模块单元)
#include <iostream>
import B;
int main()
{
std::cout << hello() << ' ' << world() << '\n';
}编译时:g++ -fmodules-ts -std=c++20 -x c++ A.cppm B.cppm main.cpp -o transfer,会报错如下:
main.cpp: In function ‘int main()’:
main.cpp:7:18: error: ‘hello’ was not declared in this scope; did you mean ‘ftello’?
7 | std::cout << hello() << ' ' << world() << '\n';
如果main.cpp中也想看到A中的导出接口的话,那么在B中必须用export import A;的方式导出。
//A.cpp ('A' 的主模块接口单元)
export module A;
export char const* hello() { return "hello"; }
// B.cpp ('B' 的主模块接口单元)
export module B;
export import A; //模块 A 导入 B 模块后又导出,那么导入 A 也会使所有从 B 导出的内容可见
export char const* world() { return "world"; }
// main.cpp (非模块单元)
#include <iostream>
import B;
int main()
{
std::cout << hello() << ' ' << world() << '\n';
}编译:g++ -fmodules-ts -std=c++20 -x c++ A.cppm B.cppm main.cpp -o transfer
子模块
模块名包含由点分隔的一个或多个标识符(mymodule.mysubmodule)。点没有内在含义,不过它们会非正式地用于表示继承关系,或者逻辑上划分模块的归属关系。
当模块变得再大一些,仅仅是将模块的接口与实现拆分也有点力不从心:模块实现文件会变得非常大,不便于代码的维护。C++20的模块机制支持子模块。
这次module_hello.cppm文件不再定义、声明任何函数,而是仅仅显式导出hello.foo、hello.bar两个子模块,外部需要的方法都由上述两个子模块定义,module_hello.cppm充当一个“汇总”的角色。
//module_hello.cppm
export module hello;
export import hello.foo; //导入hello.foo的同时导出hello.foo
export import hello.bar;子模块module hello.foo采用了接口与实现分离的定义方式:“.cppm”中给出定义,“.cpp”中给出实现。
//module_hello_foo.cppm(子模块foo的接口文件)
export module hello.foo;
export void foo();
//module_hello_foo.cpp(子模块foo的实现文件)
module hello.foo;
void foo()
{
//do something;
}子模块module hello.bar同上
//module_hello_bar.cppm(子模块bar的接口文件)
export module hello.bar;
export void bar();
//module_hello_bar.cpp(子模块bar的实现文件)
module hello.bar;
void bar()
{
//do something;
}
//main.cpp
import hello;
int main(void)
{
foo();
bar();
return 0;
}编译: g++ -fmodules-ts -std=c++20 -x c++ hello_foo.cppm hello_bar.cppm hello.cppm hello_foo.cpp hello_bar.cpp main.cpp -o submodules
这样,hello模块的接口和实现文件各自被拆分到了两个文件中。值得注意的是,C++20的子模块是一种“模拟机制”,模块hello.foo是一个完整的模块,中间的点并不代表语法上的从属关系,不同于函数名、变量名等标识符的命名规则,模块的命名规则中允许点存在于模块名字当中。点只是从逻辑语义上帮助程序员理解模块间的逻辑关系。
模块分区(Module partitions)
当模块的规模过大时,可以将大模块划分为多个模块分区;它们是模块声明中包含了一个模块分区的模块单元,模块分区在模块名之后,以一个冒号 : 开头。
export module A:B;// Declares a module interface unit for module 'A', partition ':B'.
一个模块分区表示恰好一个模块单元(两个模块单元不能指定同一个模块分区)。它们只在自己所在的具名模块内部可见(在该具名模块外的翻译单元不能直接导入这些模块分区)。模块分区只能被相同具名模块的模块单元导入。
模块分区分为两种:
module implementation partition:可以通俗的理解为:将模块的实现文件拆分成多个。
module interface partition可以理解为模块声明拆分到多个文件中。
helloworld.cppm文件:给出模块的声明、导出函数的声明,充当了”汇总“的角色。
/// helloworld.cppm
export module A; // primary module interface unit
export import :B; // Hello() is visible when importing 'A'.
import :C; // WorldImpl() is now visible only for 'A.cpp'.
// export import :C; // ERROR: Cannot export a module implementation unit.
// World() is visible by any translation unit importing 'A'.
export char const* World()
{
return WorldImpl();
}模块的另一部分实现拆分到hello.cpp文件,该文件实现了hello函数
/// hello.cpp
export module A:B; // partition module interface unit
// Hello() is visible by any translation unit importing 'A'.
export char const* Hello() { return "Hello"; }模块的一部分实现代码在world.cpp文件,该文件实现了一个内部方法。该模块也被称之为内部模块分区(internal module partitions);
/// world.cpp
module A:C; // partition module implementation unit
// WorldImpl() is visible by any module unit of 'A' importing ':C'.
char const* WorldImpl() { return "World"; }
/// main.cpp
// g++ -fmodules-ts -std=c++20 -x c++ hello.cpp world.cpp helloworld.cppm main.cpp -o partition
#include <iostream>
import A;
int main()
{
std::cout << Hello() << ' ' << World() << '\n';
// WorldImpl(); // ERROR: WorldImpl() is not visible.
}对于模块实现分区再看一个例子:
module_hello.cppm文件:给出模块的声明、导出函数的声明。
//module_hello.cppm
export module hello;
export void func_a();
export void func_b();
模块的一部分实现代码拆分到module_hello_partition_internal.cpp文件,该文件实现了一个内部方法。
//module_hello_partition_internal.cpp(parititon internal的实现文件,无需给出接口文件)
module hello:internal;
void internal_helper()
{
//do something;
}模块的另一部分实现拆分到module_hello.cpp文件,该文件实现了func_a、func_b,同时引用了内部方法internal_helper。(func_a、func_b当然也可以拆分到两个cpp文件中)
//module_hello.cpp
module hello;
import :internal;
void func_a()
{
internal_helper();
//....
}
void func_b()
{
internal_helper();
//....
}使用module
#include <iostream>
import hello;
int main(void)
{
func_a();
func_b();
return 0;
}编译:g++ -fmodules-ts -std=c++20 -x c++ module_hello.cppm module_hello_partition_internal.cpp module_hello.cpp main.cpp -o partition
值得注意的是, 模块内部import 一个module partition时,不能import hello:internal;而是直接import :internal; 。
模块接口分区
接口分区允许程序员将导出的模块API拆分为多个文件。module interface partition可以理解为模块声明拆分到多个文件中。上面的module implementation partition的例子中,函数声明只集中在一个文件中,module interface partition可以将这些声明拆分到多个文件。
首先定义一个内部helper:internal_helper
//module_hello_partition_internal.cpp(parititon internal的实现文件,无需给出接口文件)
module hello:internal;
void internal_helper()
{
//do something;
}hello模块的a部分采用声明+定义合一的方式,定义在module_hello_partition_a.cppm中:
//module_hello_partition_a.cppm(partition a的声明+实现)
export module hello:partition_a;
export int func_a()
{
//do something;
return 10;
}hello模块的b部分采用声明+定义分离的方式,module_hello_partition_b.cppm只做声明:
//module_hello_partition_b.cppm(partition b的声明)
export module hello:partition_b;
export int func_b();
module_hello_partition_b.cpp给出hello模块的b部分对应的实现:
//module_hello_partition_b.cpp(partition b的实现)
module hello;//不能使用module hello:partition_b ,否则报错:main.cpp:8:18: error: ‘func_b’ was not declared in this scope std::cout << func_b() << std::endl;
int func_b()
{
//do something;
return 20;
}module_hello.cppm再次充当了”汇总“的角色,将模块的a部分+b部分导出给外部使用:
//module_hello.cppm //primary module interface file
export module hello;
export import :partition_a;
export import :partition_b;
//export :internal; //编译错误!!!!编译:g++ -fmodules-ts -std=c++20 -x c++ module_hello_partition_a.cppm module_hello_partition_internal.cpp module_hello_partition_b.cppm module_hello_partition_b.cpp module_hello.cppm main.cpp -o partition
module implementation partition的使用方式较为直观,相当于我们平时编程中“一个头文件声明多个cpp实现”这种情况。module interface partition有点类似于submodule机制,但语法上有较多差异:
module_hello_partition_b.cpp 第一行不能使用 import hello:partition_b;虽然这样看上去更符合直觉,但是,就是不允许。一个partition name只能创建一个文件
每个module partition interface最终必须被primary module interface file导出,不能遗漏。
primary module interface file 不能导出module implementation file,只能导出module interface file。故在module_hello.cppm中export :internal;是错误的。
同样作为处理大模块的机制,module partition与子模块最本质的区别在于:子模块可以独立的被外部使用者import,而module partition只在模块内部可见,外部无法使用。
内部分区
内部分区允许程序员提供仅在内部可见的声明和定义模块。然而,即使只是声明,它们也是预编译的,以避免多次编译。
在同一个模块多个实现单元(模块实现单元)中,我们引入了一个仅在模块内部使用的数据结构Order。它看起来我们必须在主模块接口中声明它,以使它对所有implementation units都可用。在大型项目中使用内部分区,即在单独的文件中定义模块的内部内容。内部分区是分区实现单元的一种;
使用内部分区,我们可以定义在自己的模块单元中定义内部使用类型Order,如下所示:
//mod2order.cppp
module; // start module unit with global module fragment
#include <string>
module Mod2:Order; // internal partition declaration
struct Order
{
int count;
std::string name;
double price;
Order(int c, std::string n, double p)
: count{c}, name{n}, price{p}
{
}
};接着我们主模块接口单元分区如下:
//mod2.cppm
module; // start module unit with global module fragment
#include <string>
#include <vector>
export module Mod2; // module declaration
import :Order; // import internal partition Order
export class Customer
{
private:
std::string name;
std::vector<Order> orders;
public:
Customer(std::string n)
: name{n}
{
}
void buy(std::string ordername, double price)
{
orders.push_back(Order{1, ordername, price});
}
void buy(int num, std::string ordername, double price)
{
orders.push_back(Order{num, ordername, price});
}
double sumPrice() const;
double averagePrice() const;
};主模块接口必须导入内部分区,因为它使用了Order类型。导入内部分区可以在模块的所有实现单元中都可用Order类型。如果主模块接口不需要Order类型并且不import那么其他所有需要Order类型的模块单元都必须import这个Order所在的内部分区。
请注意,分区只是模块的内部实现的一个方面,代码是否在分区对导入模块的代码没有影响。
其他代码:
//mod2price.cpp
module;
#include <vector> // gcc needs this
module Mod2; // implementation unit of module Mod2
import :Order; // import internal partition Order
double Customer::sumPrice() const
{
double sum = 0.0;
for (const Order& od : orders) { // ERROR with VC++
//for (const auto& od : orders) { // OK
sum += od.count * od.price;
}
return sum;
}
double Customer::averagePrice() const
{
if (orders.empty())
{
return 0.0;
}
return sumPrice() / orders.size();
}测试代码:
//testmod2.cpp
#include <iostream>
import Mod2;
int main()
{
Customer c1{"Kim"};
c1.buy("table", 59.90);
c1.buy(4, "chair", 9.20);
//c1.print();
std::cout << " Average: " << c1.averagePrice() << '\n';
}编译:g++ -fmodules-ts -std=c++20 -x c++ mod2order.cppp mod2price.cpp mod2.cppm testmod2.cpp -o partition
目前在我的环境中编译失败:
during RTL pass: expand
In file included from /opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/string:41,
from mod2order.cppp:3,
of module Mod2:Order, imported at mod2.cppm:8:
In member function ‘constexpr _Tp* std::allocator< <template-parameter-1-1> >::allocate(std::size_t) [with _Tp = char]’,
inlined from ‘static constexpr _Tp* std::allocator_traits<std::allocator<_CharT> >::allocate(allocator_type&, size_type) [with _Tp = char]’ at /opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/bits/alloc_traits.h:464:28:
/opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/bits/allocator.h:183:39: internal compiler error: in make_decl_rtl, at varasm.cc:1446
183 | if (__builtin_mul_overflow(__n, sizeof(_Tp), &__n))
| ~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~
0x6b34d0 make_decl_rtl(tree_node*)
../../gcc/varasm.cc:1446
0xa78b89 expand_expr_real_1(tree_node*, rtx_def*, machine_mode, expand_modifier, rtx_def**, bool)
../../gcc/expr.cc:10552
0xa84dbd expand_expr_real(tree_node*, rtx_def*, machine_mode, expand_modifier, rtx_def**, bool)
../../gcc/expr.cc:8736
0xa84dbd store_expr(tree_node*, rtx_def*, int, bool, bool)
../../gcc/expr.cc:6087
0xa86508 expand_assignment(tree_node*, tree_node*, bool)
../../gcc/expr.cc:5819
0x96de9f expand_gimple_stmt_1
../../gcc/cfgexpand.cc:3935
0x96de9f expand_gimple_stmt
../../gcc/cfgexpand.cc:4033
0x972c37 expand_gimple_basic_block
../../gcc/cfgexpand.cc:6080
0x9748ce execute
../../gcc/cfgexpand.cc:6806
Please submit a full bug report, with preprocessed source (by using -freport-bug).
Please include the complete backtrace with any bug report.
See <GCC Bugs- GNU Project> for instructions.
during RTL pass: expand
In file included from /opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/string:41,
from mod2order.cppp:3,
from mod2.cppm:8,
of module Mod2, imported at testmod2.cpp:3:
In member function ‘constexpr _Tp* std::allocator< <template-parameter-1-1> >::allocate(std::size_t) [with _Tp = char]’,
inlined from ‘static constexpr _Tp* std::allocator_traits<std::allocator<_CharT> >::allocate(allocator_type&, size_type) [with _Tp = char]’ at /opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/bits/alloc_traits.h:464:28:
/opt/gcc/x86_64/12.2.0a-1/include/c++/12.2.0/bits/allocator.h:183:39: internal compiler error: in make_decl_rtl, at varasm.cc:1446
183 | if (__builtin_mul_overflow(__n, sizeof(_Tp), &__n))
| ~~~~~~~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~~
0x6b34d0 make_decl_rtl(tree_node*)
../../gcc/varasm.cc:1446
0xa78b89 expand_expr_real_1(tree_node*, rtx_def*, machine_mode, expand_modifier, rtx_def**, bool)
../../gcc/expr.cc:10552
0xa84dbd expand_expr_real(tree_node*, rtx_def*, machine_mode, expand_modifier, rtx_def**, bool)
../../gcc/expr.cc:8736
0xa84dbd store_expr(tree_node*, rtx_def*, int, bool, bool)
../../gcc/expr.cc:6087
0xa86508 expand_assignment(tree_node*, tree_node*, bool)
../../gcc/expr.cc:5819
0x96de9f expand_gimple_stmt_1
../../gcc/cfgexpand.cc:3935
0x96de9f expand_gimple_stmt
../../gcc/cfgexpand.cc:4033
0x972c37 expand_gimple_basic_block
../../gcc/cfgexpand.cc:6080
0x9748ce execute
../../gcc/cfgexpand.cc:6806
Please submit a full bug report, with preprocessed source (by using -freport-bug).
Please include the complete backtrace with any bug report.
See <GCC Bugs- GNU Project> for instructions.
私有模块(Private module)--gcc13.1目前不支持
主模块接口单元后可以随一个私有模块片段,这样就可以在不会把模块的所有内容暴露给导入方的情况下将模块表示为单个编译单元,即module可以将interface和implementation分开,但有时候,我们既想把它分开(指用途上把接口和实现分开),但又只想使用一个源码文件的时候,可以使用私有模块。
module : private;
声明序列(可选)
私有模块片段会终止模块接口单元中可以影响其他编译单元的行为的部分。如果模块单元包含了私有模块片段,那么它就是它的模块中唯一的模块单元。
export module foo;
export int f();
module : private; // 终止模块接口单元中可以影响其他编译单元的行为的部分,开始私有模块片段
int f() // 定义对 foo 的导入方不可及
{
return 42;
}
void bar() {} //bar对导入方不可见如果在主模块接口单元中声明模块,有时可能需要一个私有模块,它允许程序员在模块接口单元中进行声明和定义任何其他模块或翻译单元既不可见也不可达。使用它的一种方法是禁用导出类或函数的定义,尽管已导出其声明。
例如,考虑以下模块接口单元:
export module MyMod;
export class C; // class C is exported
export int print(const C& c); // print() is exported
class C // provides details of the exported class
{
public:
int print() const { return 42;};
private:
int value;
};
int print(const C& c) // provides details of the exported function
{
return c.print();
}export只能在引入名称的第一次时指定。因此如何翻译单元都可以import 这个MyMod模块并使用C类型:
import MyMod;
….
C c; // OK, definition of class C was exported
print(c); // OK (compiler can replace the function call by its body)但是,如果您想将定义封装在模块中,以便导入代码只看到声明并且你仍然希望在模块接口单元中定义它,则必须放置在私有模块片段中的定义:
export module MyMod;
export class C; // declaration is exported
export int print(const C& c); // declaration is exported
module :private; // stuff from here is not (implicitly) exported
class C // complete class not exported
{
private:
int value;
public:
int print() const { return 42;};
};
int print(const C& c) // definition not exported
{
return c.print();
}私有模块片段被声明为:module : private;
私有模块片段只能出现在主模块接口单元中,并且只能出现一次。在其声明中文件不再(隐式)导出。之后使用export导出任何内容都是错误的。通过将定义移动到私有模块片段中,导入代码的模块单元就不能看到它的定义。导入MyMod模块单元只能使用C类(class C is an incomplete type)和print函数的前项声明。
例如,你不能创建C class的object:
import MyMod;
C c; //ERROR (C only declared, not defined)
print(c); // OK (compiler can replace the function call by its body)然而,对于C对象的引用和指针类型MyMod的声明是可以使用的:
import MyMod;
Void foo(const C& c) //OK
{
print(c); //OK
}目前gcc13.1不支持private module,打印如下:
sorry, unimplemented: private module fragment
Private Module fragments allow authors to truly hide details of a library without having to create a separate C++ source file to contain implementation details.
C++20 added a new section to a primary Module interface known as the private Module fragment, [module.private.frag]. Private Module fragments allow authors to truly hide details of a library without having to create a separate C++ source file to contain implementation details. Imagine a scenario where a PIMPL pattern is used in a primary Module interface:
module;
#include <memory>
export module m;
struct Impl;
export
class S
{
public:
S();
~S();
void do_stuff();
Impl* get() const { return impl.get(); }
private:
std::unique_ptr<Impl> impl;
};
module :private; // Everything beyond this point is not available to importers of 'm'.
struct Impl
{
void do_stuff() { }
};
S::S():impl{ std::make_unique<Impl>() }
{
}
S::~S() { }
void S::do_stuff()
{
impl->do_stuff();
}
And on the import side:
import m;
int main()
{
S s;
s.do_stuff(); // OK.
s.get(); // OK: pointer to incomplete type.
auto impl = *s.get(); // ill-formed: use of undefined type 'Impl'.
}The private Module partition is an abstraction barrier shielding the consumer of the containing Module from anything defined in the purview of the private partition, effectively enabling single-“header” libraries with better hygiene, improved encapsulation, and reduced build system administrivia.
模块所有权
通常情况下,如果一个名称声明出现在module的声明之后,那么这个名称就会绑定到这个module上。并且,如果名称的声明被绑定到这个module上,那么它的定义也只能绑定到这个module上。
如果绑定到具名module上的声明没有被export,那么该名称具有module linkage
export module lib_A;
int f() { return 0; } // f 具有模块链接
export int x = f(); // x 等于 0
export module lib_B;
int f() { return 1; } // OK,lib_A 中的 f 和 lib_B 中的 f 指代不同的实体
export int y = f(); // y 等于 1如果两个匹配的声明附着于不同的模块,并且它们都声明了具有外部链接的名字,那么程序非良构;在两个声明互相不可及时不要求诊断。在实践中有两种模型:
在 弱模块所有权 模型中,这些声明被视为声明了相同的实体。
在 强模块所有权 模型中,这些声明被视为声明了不同的实体。
export module lib_A;
export constexpr int f() { return 0; } // f 具有外部链接
export module lib_B;
export constexpr int f() { return 1; }// 在弱模块所有权模型中:存在多个 f 的定义;链接器会选择其中任意一个
// 在强模块所有权模型中:OK,lib_A 中的 f 和 lib_B 中的 f 是不同的实体 [MSVC]
C++ 标准中新提出了一种 module linkage, 意味着只有同一个 module 内部可见. 之前的 C++ 标准中只有 external linkage (全局可见) 和 internal linkage (同一个翻译单元可见).
为了实现这个 module linkage 功能, GCC 和 Clang 共同使用了一种新的 name mangling 技术. 具体地说, 如果
- modules 对外 export 的名称, 按照平时方式进行 name mangling.
- 对于 modules 内部, 需要 module linkage 的名称, 使用一种全新的 _ZW 开头的 name mangling.
这两个技术一结合, 编译器就能分辨出啥是好的, 啥是坏的了. 编译器编译的时候, 就知道 _ZW 开头的函数只能同一个 module 内互相调用, 就在编译的时候进行隔离了.
这样做有一个巨大利好, 不用改动链接器了. 在链接器的角度看来 module linkage 和 external linkage 是一回事.
但 MSVC 希望能更进一步. 比如在 A, B 两个 module 同时 export 一个函数的时候, MSVC 希望能够区分出这俩函数是不同的. 为此, 他们既改了编译器, 又改了链接器. 具体可以看看下面这篇博客.
Standard C++20 Modules support with MSVC in Visual Studio 2019 version 16.8 - C++ Team Blog
但是,前面说的是“通常情况下”名称会绑定到前面的module上,那什么情况下不会绑定呢?有两个例外:
- 当名称是namespace时;
- 名称声明时使用了语言链接说明(language linkage specification);
export module lib_A;
namespace ns // ns 不附着于 lib_A
{
export extern "C++" int f(); // 函数f 没有绑定到 lib_A上
extern "C++" int g(); // 函数g 没有绑定到 lib_A上
export int h(); // 函数h 绑定到 lib_A上
}ns::h 必须在 lib_A 中定义,但 ns::f 和 ns::g 可以在其他地方定义(例如在传统源文件中)。
不过,namespace可以显式的进行export:
export namespace ns
{
int a= 7030; // 正确,export了ns::a
static int b= 7030; // 错误,internal linkage的符号不能export(参考模块使用限制)
}模块编译顺序
按照设计, GCC 会按照你给定的文件顺序进行编译, 而你顺序错了必定编译失败.
我们来看下面的例子, 修改自 C++20 的标准文件
// 1.ccpm
export module A; // 对外暴露一个叫 A 的 module
export import :Foo; // 对外暴露 A:Foo 这个模块
export int baz(); // 对外暴露 int baz();
// 2.ccpm
export module A:Foo; // 对外暴露 A:Foo 这个模块
import :Internals; // 引入 A:Internals 这个模块
// 给出函数 int foo() 的实现, 并且对外暴露
export int foo() { return 2 * (bar() + 1); }
// 3.ccpm
module A:Internals; // 表明我就是 A:Internals 这个模块
int bar(); // 表明本模块里面有一个 int bar() 函数.
// 4.ccpm
module; // 表明现在我是 global module fragment
#include <iostream>
module A; // 表明现在我是模块 A 的 module implementation unit
import :Internals; // 引入 A:Internals 这个模块
// 给出了 A:Internals 之中 int bar() 的定义 (具有 module linkage)
int bar() { return baz() - 10; }
// 给出了 1.cc 中 int baz() 的定义 (具有 external linkage)
int baz()
{
std::cout << 30;
return 30;
}
// main.cpp
import A;
int main()
{
foo();
}1.cc 是 module A 的 interface unit.
2.cc 是一个 module partition, 叫做 A:Foo, 同时也是 module A 的 interface 一部分.
3.cc 也是一个 module partition, 叫做 A:Internals, 但是不是 module A 的 interface 一部分.
4.cc 是一个 module implementation unit. 给之前这些 interface 提供实现. 但是无法被外部 import.
从上面的代码中, 我们看到 3 被 2 and 4 需要, 1 被 4 需要, 2 被 1 需要, 于是我们的编译顺序就是.
所以必须先编译 3.cc, 然后是 2.cc 必须在 1.cc 之前, 1.cc 必须在 4.cc 之前, 他们都必须在 main.cpp 之前, 所以编译的顺序为
g++ -fmodules-ts -std=c++20 3.cc 2.cc 1.cc 4.cc main.cpp -o main
换句话说, 想要生成 A.gcm, 必须先生成 A-Internals.gcm, 再生成 A-Foo.gcm.
你也可以分开编译
g++ -fmodules-ts -std=c++20 -c 3.cc -o 3.o # 生成 A-Internals.gcm
g++ -fmodules-ts -std=c++20 -c 2.cc -o 2.o # 读取 A-Internals.gcm, 生成 A-Foo.gcm
g++ -fmodules-ts -std=c++20 -c 1.cc -o 1.o # 读取 A-Foo.gcm, 生成 A.gcm
g++ -fmodules-ts -std=c++20 -c 4.cc -o 4.o # 读取 A.gcm, A-Internals.gcm, 写入 A.gcm
g++ -fmodules-ts -std=c++20 -c main.cpp -o main.o # 读取 A.gcm
g++ 1.o 2.o 3.o 4.o main.o -o main # 链接阶段就不需要了特殊处理了
模块使用限制
export的限制
1. export已经是C++保留关键字,export不能导出具有内部链接的C++实体,静态变量、函数以及定义在匿名命名空间中的类、变量、函数皆具有内部链接。
//unExported.cppm
export module myModule;
//静态变量,函数具有内部链接
export static int data = 1; //错误, static变量
export static void function() {} //错误, static函数
//匿名命名空间具有内部链接
namespace
{
export class Demo {} ; //错误,匿名namespace
export void foo() {} //错误,匿名namespace
export int size = 1024; //错误,匿名namespace
}
//main.cpp
import myModule;
int main()
{
std::cout<<data<<"\n"; //error: 'data' was not declared in this scope
function(); //error: 'function' was not declared in this scope
Demo d; //error: 'Demo' was not declared in this scope
}2. 只能在命名空间作用域或全局命名空间中导出实体。
export class Demo
{
int a;
export int b; // Illegal
};
export void function()
{
export int value = 30; // Illegal
}3.“using声明”中所指向的具有非内部链接或非模块链接的C++实体也可进行导出,但using namespace声明不能被导出。
namespace NS1
{
export class Demo1{};
class Demo2{};
namespace
{
class Demo3{};
}
}
export using NS1::Demo1; // Okay
export using NS1::Demo2; // Illegal
export using NS1::Demo3; // Illegal
export using namespace NS1; // Illegal4. 命名空间也可以被导出,但是只能导出命名空间中那些满足条件的C++实体。
export namespace NS
{
int Var= 8; // Okay. Var is exported as NS::Var;
static int ill= 0; // Illegal
namespace
{
void ill_function() {} // Illegal
}
}5. 被导出的C++实体需在第一次声明时用export关键字,其后的声明或定义均不需再指定export。
export class Domo; //OK
export class Domo; //OK,只不过重复了
class Domo //隐式带有export关键字
{
int m_a;
int m_b;
};
class Demo1; //OK,没有export
export class Demo1; // 错误! 要export的符号必须在首次声明时就export!关于import关键字的使用限制import的限制
1. import语句必须出现在任何C++实体的声明之前。
export module myModule;
import mouduleB;
void func();
import moduleC; // illegal! Move it above `function`2. import语句仅能出现在全局作用域中。
void function()
{
import myModule; // Illegal
}
namespace
{
import myModule; // Illegal
}3.如果import后面跟一个<, 与import<header>语法一样
template<typename T> class import{};
import<int> f(); //以前可以,现在clang报错,gcc可以
::import<int> g(); //修改为这种方式:clang可以,gcc也可以4.module和import作为top-level声明时,使用方法与C++20的方式冲突了
struct module;
int main(void)
{
module *m ; //测试gcc和clang都可以,标准中现在不行?
::module *pm;//测试gcc和clang都可以
}
struct module {};
class import {};
import J; //以前是声明及定义,并实例化一个import类型的对象,现在则是导入module J
::import J; // 声明并实例化一个import类型对象;
struct module
{
module(int i): v{i}
{}
int v;
};
int main(void)
{
module m = module(100); //gcc和clang都可以
::module pm = module{200}; //gcc和clang都可以
std::cout << m.v;
std::cout << pm.v;
}编译器如何实现对外隐藏module内部符号的
在module机制出现之前,符号的链接性分为外部连接性(external linkage,符号可在文件之间共享)、内部链接性(internal linkage,符号只能在文件内部使用),可以通过extern、static等关键字控制一个符号的链接性。
module机制引入了模块链接性(module linkage),符号可在整个模块内部共享(一个模块可能存在多个partition文件)
对于模块export的符号,编译器根据现有规则(外部连接性)对符号进行名称修饰(name mangling)
对于module内部的符号,统一在符号名称前面添加“_Zw”名称修饰,这样链接器链接时便不会链接到内部符号。
# create module cache for system headers
for item in iostream string vector
do
g++ -fmodules-ts -std=c++20 -x c++-system-header $item
done
编译器支持C++20特性: Compiler support for C++20 - cppreference.com
其他可参考学习链接:
模块 (C++20 起) - cppreference.com
c++20模块导入module
一文读懂C++20 新特性之module(模块)_c++ module_云飞扬_Dylan的博客-CSDN博客
c++20 module的理解_c++20 模块-CSDN博客
【精选】C++20四大之一:module特性详解-CSDN博客
C++的modules - 知乎
C++20 新特性: modules 及实现现状 - 知乎
C++ 20中module的优势
模块是C++ 20的四大功能之一:概念,范围,协程和模块。模块还是有很多前景:编译时改进了宏隔离,废除头文件等极其不优美的解决方法。我会通过一段浅显易懂的代码带你解析模块的优势。
执行一段大家都懂的Demo
// helloWorld.cpp
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}编译一下,我们来创建可执行文件helloWorld,屏幕截图中的100和12928代表字节数,如下图所示。

编译
经典的构建过程
我们都知道经典的构建过程包括三个步骤:预处理,编译和链接。下面就分别详细展开介绍一下吧!
预处理
预处理器处理预处理器指令“#include”和“#define”。预处理程序将#inlude指令替换为相应的头文件,并替换宏(#define)。当然有些指令,例如#if,#else,#elif,#ifdef,#ifndef,和#endif中的部分可以被替换排除。
我们通过使用GCC上的-E或Windows上/E的编译器参数,可以观察到源码的替换过程,如下图所示。

-E
由上图可知,预处理步骤的输出超过50万字节。所以你就不要责怪GCC慢了,因为其他编译器也很冗长,当然你可以用CompilerExplorer实际测试一下。
预处理器的输出是编译器的输入,那么我们接下来看看代码展开后是如何编译成汇编代码的?
汇编
编译是在预处理器的每个输出上单独执行的,编译器解析C++源代码并将其转换为汇编代码。生成的文件称为目标文件,是二进制形式的已编译代码。目标文件可以引用没有定义的符号。可以将目标文件归档到文件中,以供以后复用,我们称这些存档为静态库。
编译器生成的对象或转换单元是链接器的输入,接下来我们看看链接器。
链接器
链接器的输出可以是可执行文件,也可以是静态或共享库。链接程序的工作是将对引用的引用解析为未定义的符号,这些符号需要在目标文件或库中定义。
以上三步的构建过程是从C继承过来的,当然C++还有翻译单元。我们的程序由一个或多个翻译单元组成,当同一名称在不同的翻译单元中有两个不同的定义时,将发生链接器错误,这个问题在20中已经解决啦,且听下解!
构建过程中存在的问题
在经典构建过程中可能会遇到如下一些缺陷。在C++20 中,模块被引入的替代方法,是可以完全克服这些问题。
预处理器重复处理问题
首先预处理程序将#inlude指令替换为相应的头文件。我来更改一下上面的helloWorld.cpp程序以使得头重复定义出来。我重构了程序,并添加了两个源文件hello.cpp和world.cpp。源文件hello.cpp提供功能“hello”,源文件world.cpp提供功能“world”。两个源文件都包含相应的头。重构意味着该程序执行与先前程序helloWorld.cpp相同的操作。 虽然分开重构了,但是内部结构发生了变化,如下:
- hello.cpp和hello.h
// hello.cpp
#include "hello.h"
void hello()
{
std::cout << "hello ";
}
// hello.h
#include <iostream>
void hello();world.cpp和world.h
// world.cpp
#include "world.h"
void world()
{
std::cout << "world";
}
// world.h
#include <iostream>
void world();
helloWorld2.cpp
// helloWorld2.cpp
#include <iostream>
#include "hello.h"
#include "world.h"
int main()
{
hello();
world();
std::cout << std::endl;
}构建和执行程序:

编译
这里就有一个问题了:预处理程序在每个源文件上运行,意味着头文件<iostream>在每个转换单元中是包含3次。因此每个源文件被编译输出超过五十万行,如下所示。

编译出3次
显然,重复预处理的做法会增加编译时间。不过在C++20中你只需要导入模块一次,根本就不会造成重复预处理操作。
与预处理器宏的隔离问题
根据C++发展的一个方向,那就是应该摆脱预处理器宏。为什么呢?使用宏只是文本替换,不包括任何C ++语义。预处理器宏带来了很多麻烦,例如包含宏的顺序问题,宏名称冲突等。
有如下webcolors.h和productinfo.h:
// webcolors.h
#define RED 0xFF0000
// productinfo.
h#define RED 0
当源文件client.cpp包含这两个标头时,宏RED的值取决于标头包含的顺序,所以有时会出错。但是,导入模块的顺序是没有区别。
符号的多重定义
ODR代表“定义规则”,其功能如下:
- 一个功能在任何翻译单元中的定义不得超过一个。一个函数在程序中的定义不能超过一个。具有外部链接的内联函数可以在多个翻译中进行定义。定义必须满足每个定义必须相同的要求。让我们看看,当我来违反上面一个定义规则时,看看链接器输出是什么。以下代码示例包含两个头文件header.h和header2.h。主程序包含两次头文件header.h,所以就打破了第一个定义规则,因为其中包括了func的两个定义。
// header.h
void func() {}
// header2.h
#include "header.h"
// main.cpp
#include "header.h"
#include "header2.h"
int main()
{}
链接器报错有多个func的定义:
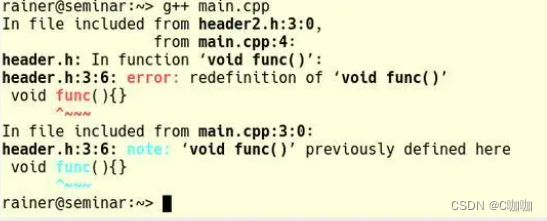
报错
之前我们是用比较傻的解决方法,在标头周围放置一个包含保护来解决此问题:
// header.h#ifndef FUNC_H#define FUNC_Hvoid func(){}#endif但是,在带有模块中包含有相同符号是几乎不可能滴!
C++20模块的用法
为了照顾部分还没有接触过C++20的朋友,特意新增加了模块的用法部分。那么我们要怎么创建一个 Module 呢?20中引入了新的关键字 import、module,并使用保留关键字 export来导入、定义和导出 Module,具体示例如下:
// hello_world.cpp
export module demos.hello.world;
export auto get_start()
{
return "Hello C++ Modules!";
}
// main.cpp
import demos.hello.world;
import <iostream>;
int main()
{
std::cout << get_start() << std::endl;
}以上就是一个 C++20 Modules版的Hello World,方便部分读者调试扩展。本文的目的是通过C++11标准的语法来暴露问题,来充分体现出C++20的优势,这样方能体现C++标准迭代的良好延续性,而非一上来就介绍C++20的语法糖,这部分需要读者自行了解。
模块优势总结
以上我用最简单的代码带你深入浅出的理解了C++11存在的问题,在20中模块都给出了解决方案。最后那就做个模块优点的总结归纳:
- 模块仅导入一次,不会造成重复编译输出。导入模块的顺序没有区别。模块中避免出现相同符号。模块的代码逻辑结构更清晰。由于使用了模块,因此无需将源代码分为接口和实现部分