5. kubesphere istio使用
5.1 整体架构
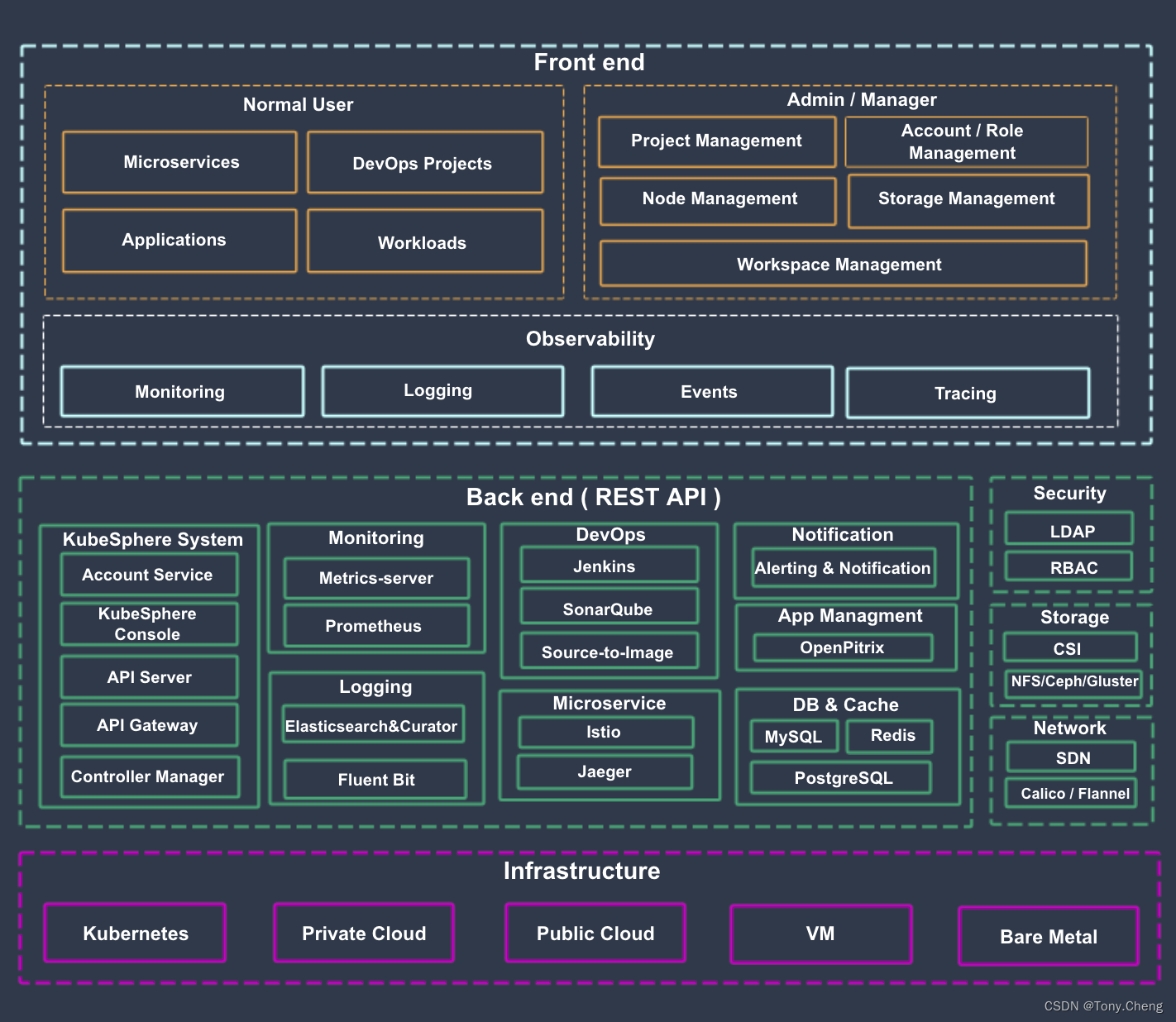
- ks-account 提供用户、权限管理相关的 API
- ks-apiserver 整个集群管理的 API 接口和集群内部各个模块之间通信的枢纽,以及集群安全控制
- ks-apigateway 负责处理服务请求和处理 API 调用过程中的所有任务
- ks-console 提供 KubeSphere 的控制台服务
- ks-controller-manager 实现业务逻辑的,例如创建企业空间时,为其创建对应的权限;或创建服务策略时,生成对应的 Istio 配置等
- Metrics-server Kubernetes 的监控组件,从每个节点的 Kubelet 采集指标信息
- Prometheus 提供集群、节点、工作负载、API 对象等相关监控数据与服务
- Elasticsearch 提供集群的日志索引、查询、数据管理等服务,在安装时也可对接您已有的 ES 减少资源消耗
- Fluent Bit 提供日志接收与转发,可将采集到的⽇志信息发送到 ElasticSearch、Kafka
- Jenkins 提供 CI/CD 流水线服务
- SonarQube 可选安装项,提供代码静态检查与质量分析
- Source-to-Image 将源代码自动将编译并打包成 Docker 镜像,方便快速构建镜像
- Istio 提供微服务治理与流量管控,如灰度发布、金丝雀发布、熔断、流量镜像等
- Jaeger 收集 Sidecar 数据,提供分布式 Tracing 服务
- OpenPitrix 提供应用模板、应用部署与管理的服务
- Alert 提供集群、Workload、Pod、容器级别的自定义告警服务
- Notification 通用的通知服务,目前支持邮件通知
- redis 将 ks-console 与 ks-account 的数据存储在内存中的存储系统
- MySQL 集群后端组件的数据库,监控、告警、DevOps、OpenPitrix 共用 MySQL 服务
- PostgreSQL SonarQube 和 Harbor 的后端数据库
- OpenLDAP 负责集中存储和管理用户账号信息与对接外部的 LDAP
- 存储 内置 CSI 插件对接云平台存储服务,可选安装开源的 NFS/Ceph/Gluster 的客户端
- 网络 可选安装 Calico/Flannel 等开源的网络插件,支持对接云平台 SDN
5.2 ks-apiserver
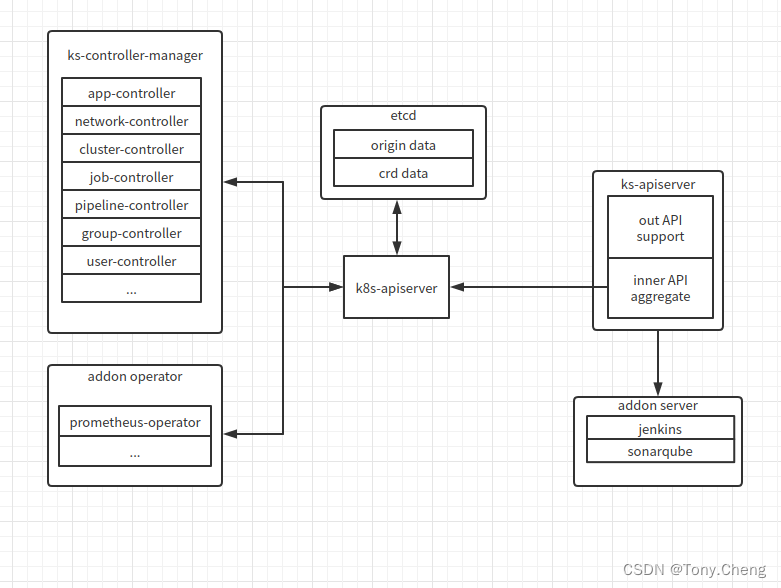
ks-apiserver 的主要功能是聚合整个系统的业务功能对外提供同一的API入口,如下图所示ks-apiserver聚合的功能对象主要包含以下几类
-
kubernetes原生的对象,由ks-apiserver连接api-server,直接获取更改etcd中kubernetes的原始数据(origin data)即可,操作的对象即kubernetes原生的configmap. deployment等对象。
-
ks-controller-manager 封装的对象,ks-controller-manager的封装功能逻辑以crd对象的方式表现在etcd中,ks-apiserver通过连接k8s-apiserver操作etcd中的crd数据(crd data)即可,操作 ks-controller-manager 扩展的逻辑功能。
-
第三方的operator对象,如prometheus-operator等第三方完成的模块以operator的方式运行在系统中,其功能对应的对象也以crd的形式存放载etcd中,ks-apiserver也是通过和k8s-apiserver交互操作对应的crd完成。
-
普通的服务对象,如kenkins,sonarqube等以普通服务的方式运行在系统中,ks-apiserver直接通过网络调用和此类对象交互
以上,ks-apiserver就完成了和各个内部对象的交互,即内部API(inner API aggregate)。ks-apiserver在对这些各个模块的功能进行整合,对外提供统一的API,即外部API(out API aggregate)
5.3 kubesphere的服务网格
kubesphere 使用istio 目前提供的功能:
-
流量管理
-
灰度发布, 支持蓝绿发布、金丝雀发布和流量镜像
-
链路追踪
kubesphere 使用istio 实现服务网格:
- 初始化并启动informer
//初始化 informers, cmd/ks-apiserver/app/options/options.go
informerFactory := informers.NewInformerFactories(kubernetesClient.Kubernetes(), kubernetesClient.KubeSphere(),
kubernetesClient.Istio(), kubernetesClient.Snapshot(), kubernetesClient.ApiExtensions(), kubernetesClient.Prometheus())
apiServer.InformerFactory = informerFactory
// start informer,pkg/informers/informers.go
if f.istioInformerFactory != nil {
f.istioInformerFactory.Start(stopCh)
}
- 创建controller
# 分别创建 virtualservice 和 destinationrule的controller, cmd/controller-manager/app/controllers.go
if serviceMeshEnabled {
vsController = virtualservice.NewVirtualServiceController(kubernetesInformer.Core().V1().Services(),
istioInformer.Networking().V1alpha3().VirtualServices(),
istioInformer.Networking().V1alpha3().DestinationRules(),
kubesphereInformer.Servicemesh().V1alpha2().Strategies(),
client.Kubernetes(),
client.Istio(),
client.KubeSphere())
drController = destinationrule.NewDestinationRuleController(kubernetesInformer.Apps().V1().Deployments(),
istioInformer.Networking().V1alpha3().DestinationRules(),
kubernetesInformer.Core().V1().Services(),
kubesphereInformer.Servicemesh().V1alpha2().ServicePolicies(),
client.Kubernetes(),
client.Istio(),
client.KubeSphere())
}
- VirtualServiceController
监听service、destinationRule、strategy三种资源
// service直接enqueueService
serviceInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: v.enqueueService,
DeleteFunc: v.enqueueService,
UpdateFunc: func(old, cur interface{}) {
// TODO(jeff): need a more robust mechanism, because user may change labels
v.enqueueService(cur)
},
})
// strategy提取出ApplicationLabels,然后根据ApplicationLabels找到services, 然后 enqueue
strategyInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: v.addStrategy,
AddFunc: v.addStrategy,
UpdateFunc: func(old, cur interface{}) {
v.addStrategy(cur)
},
})
// destinationRule找到同ns下同name的 service, 然后 enqueue
destinationRuleInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: v.addDestinationRule,
UpdateFunc: func(old, cur interface{}) {
v.addDestinationRule(cur)
},
})
VirtualServiceController 起 5个协程worker,用于处理workqueue 中item,每个worker 的逻辑是:
- 查询service,若不存在,删除同名的VirtualService和Strategy,若存在,继续
- 查询与service同名的DestinationRule,取出 Subsets
- 根据app label取出strategies,即获取到应用到service的所有strategies(正常只有1个)
- 获取与service同名的virtualservice
- 处理 service.Spec.Ports,组装成 VirtualService 中的 http或者tcp列表
- 应用strategy到VirtualService,strategy.Spec.StrategyPolicy有Paused、Immediately、WaitForWorkloadReady三种,比较destinationRule中subsets和strategy中的subsets,判断subset是否ready,ready时,或者Immediately时,组装VirtualService spec,否则不组装。strategy.Spec.GovernorVersion表示所有流量都走该版本
- 判断原VirtualService和新组装出的VirtualService 是否完全相同,不相同,就创建或更新VirtualService;相同,不做任何操作
- 如果创建或更新VirtualService失败,生成warning 类型事件
func (v *VirtualServiceController) Run(workers int, stopCh <-chan struct{}) error {
...
if !cache.WaitForCacheSync(stopCh, v.serviceSynced, v.virtualServiceSynced, v.destinationRuleSynced, v.strategySynced) {
return fmt.Errorf("failed to wait for caches to sync")
}
for i := 0; i < workers; i++ {
go wait.Until(v.worker, v.workerLoopPeriod, stopCh)
}
...
}
//主逻辑
func (v *VirtualServiceController) syncService(key string) error {
...
}
- DestinationRuleController
监听 deployment、service、servicePolicy三种资源,servicePolicy中template是destinationRule,用于创建destinationRule
// service直接enqueueService
serviceInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: v.enqueueService,
DeleteFunc: v.enqueueService,
UpdateFunc: func(old, cur interface{}) {
v.enqueueService(cur)
},
})
// 处理带有 app.kubernetes.io/name 等3个label的deploy,找到deploy 的service, 并比较selector,相等时 enqueue
// 目的是监听 deploy 的变化,是否还会和service 对应上
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: v.addDeployment,
DeleteFunc: v.deleteDeployment,
UpdateFunc: func(old, cur interface{}) {
v.addDeployment(cur)
},
})
//根据servicePolicy上的 app label找到service,去重后,enqueue
servicePolicyInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: v.addServicePolicy,
UpdateFunc: func(old, cur interface{}) {
v.addServicePolicy(cur)
},
DeleteFunc: v.addServicePolicy,
})
DestinationRuleController 起 5个协程worker,用于处理workqueue 中item,每个worker 的逻辑是:
- 查询对应service,如果不存在,则删除同名的servicePolicy和DestinationRule;存在,继续
- 根据service select labels 找到其对应的所有deploy
- 根据 deploy annotation 的servicemesh.kubesphere.io/enabled是否为true,判读是否开启serviceMesh,
- 如果开启,获取deploy 的version,进而添加到一个 subsets 列表
- 根据service name查找 对应的DestinationRule dr,没有就创建出dr
- 根据 app label 找到对应的servicePolicy(只有一个),将 servicePolicy 中port和destination级别的TrafficPolicy都赋给dr
- dr和开始获取出的DestinationRule是否有变化,如果有变化,来创建或更新DestinationRule
- 如果创建或更新失败,生成 Warning 类型的event
具体代码见 pkg/controller/destinationrule/destinationrule_controller.go的 syncService()
6. istio使用ingress-nginx-controller为网关
6.1 实现步骤
- 修改nginx-controller pod注解
在 ingress-nginx-controller 的pod中加入如下annotation
traffic.sidecar.istio.io/includeInboundPorts: "" # 将指定端口的流量重定向到envoy sidecar
traffic.sidecar.istio.io/excludeInboundPorts: "80,443" # 将指定端口的流量不重定向到envoy sidecar
traffic.sidecar.istio.io/excludeOutboundIPRanges: "10.233.0.1/32" # 将指定ip范围的流出流量不重定向到envoy sidecar。`kubectl get svc kubernetes -n default -o jsonpath='{.spec.clusterIP}'`
- 将envoy注入nginx-controller
kubectl get deployments -n istio-system ingress-nginx-controller -o yaml| istioctl kube-inject -f - | kubectl apply -f -
- VirtualService配置
使用nginx-controller作为网关后,Gateway资源应该就没有作用了。因为nginx-controller是ingress-controller的实现,pilot在watch到gateway资源后不会下发配置到nginx-controller。
所以之后在virtualService中要么不写gateways,写了的话就得加上一个mesh,才能生效vs的规则
spec:
gateways:
- xxx
- mesh
hosts:
- '*'
- 配置应用ingress
本测试中使用的应用为 productpage,ingress 需要加入如下annotations:
kubernetes.io/ingress.class: "nginx"
# 默认nginx是将流量直接打到pod ip中的,而不是通过service ip。这个配置用来禁用它,使他的流量发往service ip
nginx.ingress.kubernetes.io/service-upstream: "true"
# 这里写的是后端Service的完整fqdn。目的是修改Host请求头的值
nginx.ingress.kubernetes.io/upstream-vhost: "nginx-svc.istio-demo.svc.cluster.local"
6.2 实现原理
入口流量路径:
client——>nginx-controller中的nginx——> app svc——>app pod
7. istio排错日志
7.1 开启日志
在istio 启动时添加 如下参数
# 开启envoy 访问日志,输出到stdout
--set meshConfig.accessLogFile=/dev/stdout
# 设置日志格式为json
--set meshConfig.accessLogEncoding=JSON
7.2 五元组日志
envoy 访问日志demo 如下所示:
{
"start_time": "2021-12-03T01:11:54.847Z",
"bytes_received": 0,
"upstream_cluster": "outbound|8000||httpbin.cfd-test.svc.cluster.local",
# httpbin svc
"downstream_local_address": "10.111.183.126:8000",
# sleep pod ip
"downstream_remote_address": "172.30.209.64:50392",
"route_name": "default",
"response_flags": "-",
"duration": 7,
# sleep pod ip
"upstream_local_address": "172.30.209.64:43924",
"x_forwarded_for": null,
"bytes_sent": 135,
"response_code": 418,
"path": "/status/418",
"connection_termination_details": null,
"method": "GET",
"protocol": "HTTP/1.1",
"request_id": "e5f57f0a-4894-400e-a3df-e0123c32adf2",
"upstream_transport_failure_reason": null,
"user_agent": "curl/7.80.0-DEV",
# httpbin pod ip
"upstream_host": "172.30.21.184:80",
"response_code_details": "via_upstream",
"upstream_service_time": "6",
"authority": "httpbin:8000",
"requested_server_name": null
}
Envoy流量五元组:
- upstream_local_address, Local address of the upstream connection
- upstream_host, Upstream host URL
- upstream_cluster, Upstream cluster to which the upstream host belongs to
- downstream_local_address, Local address of the downstream connection
- downstream_remote_address, Remote address of the downstream connection
关键字段response_flags,请求的错误标志会被赋值给该字段,常见错误标志有如下几种:
HTTP and TCP相关
- UH: No healthy upstream hosts in upstream cluster in addition to 503 response code.
- UF: Upstream connection failure in addition to 503 response code.
- UO: Upstream overflow (circuit breaking) in addition to 503 response code.
- NR: No route configured for a given request in addition to 404 response code, or no matching filter chain for * a downstream connection.
- URX: The request was rejected because the upstream retry limit (HTTP) or maximum connect attempts (TCP) was reached.
- NC: Upstream cluster not found.
- DT: When a request or connection exceeded max_connection_duration or max_downstream_connection_duration.
TCP相关
- DC: Downstream connection termination.
- LH: Local service failed health check request in addition to 503 response code.
- UT: Upstream request timeout in addition to 504 response code.
- LR: Connection local reset in addition to 503 response code.
- UR: Upstream remote reset in addition to 503 response code.
- UC: Upstream connection termination in addition to 503 response code.
- DI: The request processing was delayed for a period specified via fault injection.
- FI: The request was aborted with a response code specified via fault injection.
- RL: The request was ratelimited locally by the HTTP rate limit filter in addition to 429 response code.
- UAEX: The request was denied by the external authorization service.
- RLSE: The request was rejected because there was an error in rate limit service.
- IH: The request was rejected because it set an invalid value for a strictly-checked header in addition to 400 * response code.
- SI: Stream idle timeout in addition to 408 response code.
- DPE: The downstream request had an HTTP protocol error.
- UPE: The upstream response had an HTTP protocol error.
- UMSDR: The upstream request reached max stream duration.
- OM: Overload Manager terminated the request.
8. istio与skywalking集成
istio与skywalking集成有如下三种方式:
- skywalking与 istio中的Mixer组件进行集成
- skywalking与Envoy 的 access log service 进行相关的系统集成
- 基于 Metrics 与 skywalking集成
8.1 skywalking与 istio中的Mixer组件进行集成
在早期的istio集成中采用该种方案,架构如下所示:
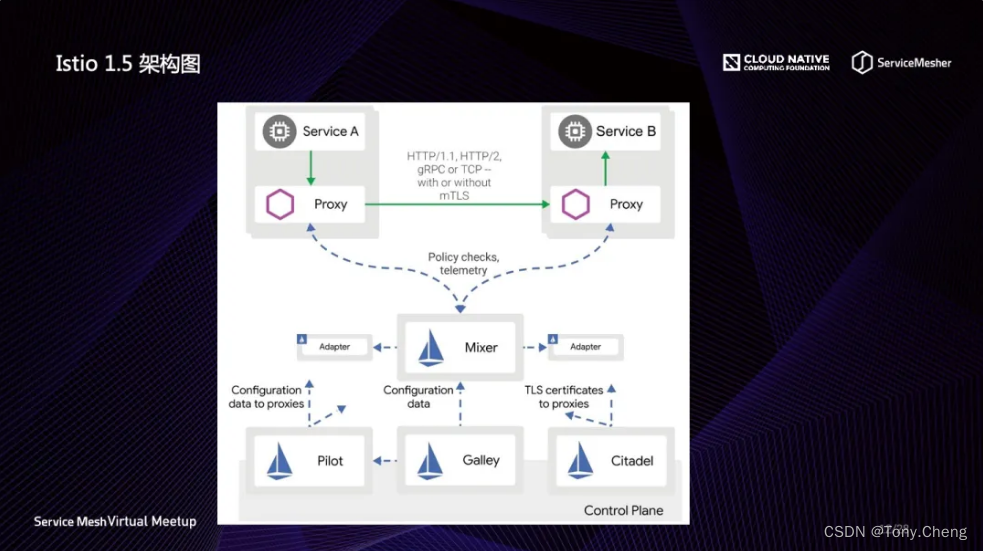
从图上看,所有的监控指标都汇聚到中间的 Mixer 组件,然后由 Mixer 再发送给他左右的 Adapter,通过 Adapter 再将这些指标发送给外围的监控平台,如 SkyWalking 后端分析平台。在监控数据流经 Mixer 的时候,Istio 的元数据会被附加到这些指标中。
8.2 skywalking与Envoy 的 access log service 进行相关的系统集成
与Mixer集成类似,SkyWalking 与 Envoy 的 access log service 进行相关的系统集成,然后根据access log进行数据的解析。
与 Envoy 集成的优势在于可以非常高效的将访问日志发送给 SkyWalking 的接收器,这样延迟最小。但缺点是目前的 access log service 发送数据非常多,会潜在影响 SkyWalking 的处理性能和网络带宽。同时所有的分析模块都依赖于较为底层的访问日志,一些 Istio 的相关特性不能被识别。比如这种模式下只能现实 Envoy 的元数据,Istio 的虚拟服务等概念无法有效的现实。
此方式的具体实现,见 skywalking与Envoy系统集成方案
8.3 基于 Metrics 与 skywalking集成
基于 Telemetry V2 观测体系是通过 Envoy 的 Proxy 直接将监控指标发送给分析平台,此种模式是基于 Metrics 监控而不是基于访问日志,模式如下图所示,这种模式将对外暴露两种 Metrics:
- service level: 这种 Metrics 描述的是服务之间的关系指标,用来生成拓扑图和服务级别的指标;
- proxy level: 这种 Metrics 描述的 Proxy 进程的相关指标,用来生成实例级别的指标.
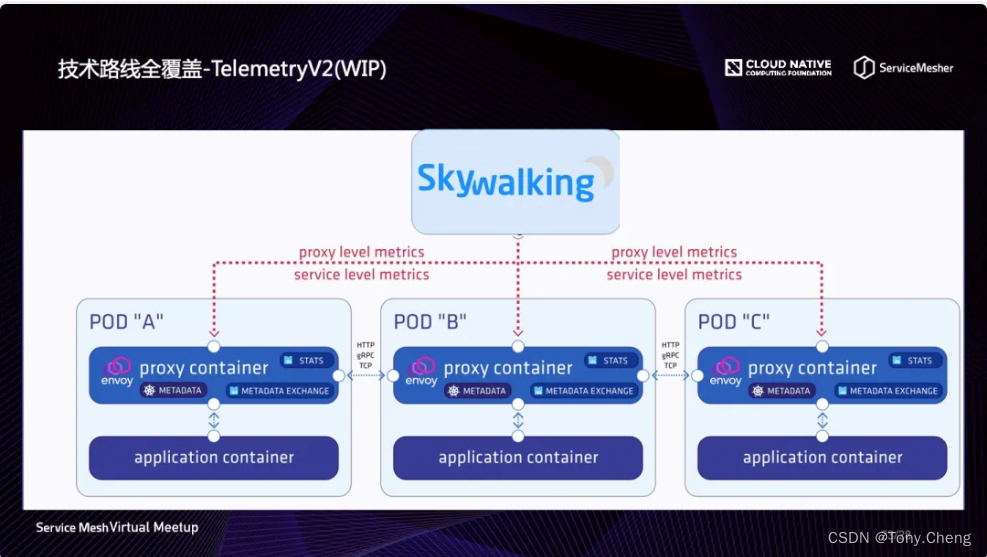
这种模方式的优点是对分析平台友好,网络带宽消耗小。缺点是需要消耗 Envoy 的资源,特别是对内存消耗大。但是相信经过外来多轮优化,可以很好的解决这些问题。
但此种方式还有另外的缺点,即不能生成端点 Endpoint 的监控指标。如果用户希望能包含此种指标,还需要使用基于 ALS 访问日志的模式。
8.4 Tracing 与 Metric 混合支持
在 SkyWalking8.0 之前,如果开启 Service Mesh 模式,那么传统的 Tracing 模式是不能使用的。原因是他们共享了一个分析流水线。如果同时开启会造成计算指标重复的问题。
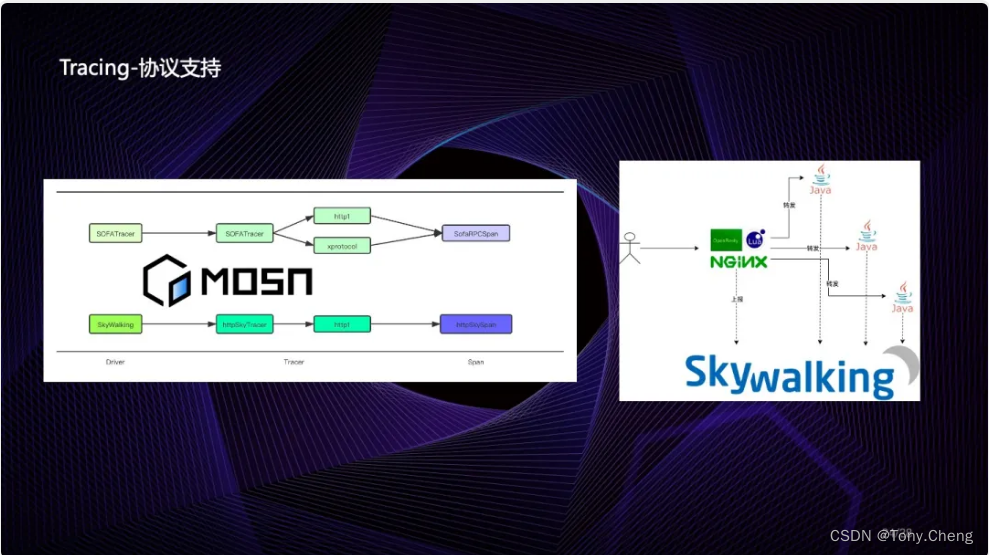
在 SkyWalking8.0 中,引入的 MeterSystem 可以避免此种问题的产生。而且计划将 Tracing 调整为可以配置是否生成监控指标,这样最终将会达到的效果是:指标面板与拓扑图的数据来源于 Envoy 的 Metrics,跟踪数据来源于 Tracing 分析,从而达到支持 Istio 的 Telemetry 在控制面中的所有功能。
9 istio最佳实践
9.1 流量管理最佳实践
- 为服务设置默认路由
- 控制配置在命名空间之间的共享
- 将大型VirtualService和DestinationRule拆分为多个资源
- 避免重新配置服务路由时出现 503 错误


![P1004 [NOIP2000 提高组] 方格取数](https://img-blog.csdnimg.cn/1ffd2fcaa6184223a5998b593d052a19.png)