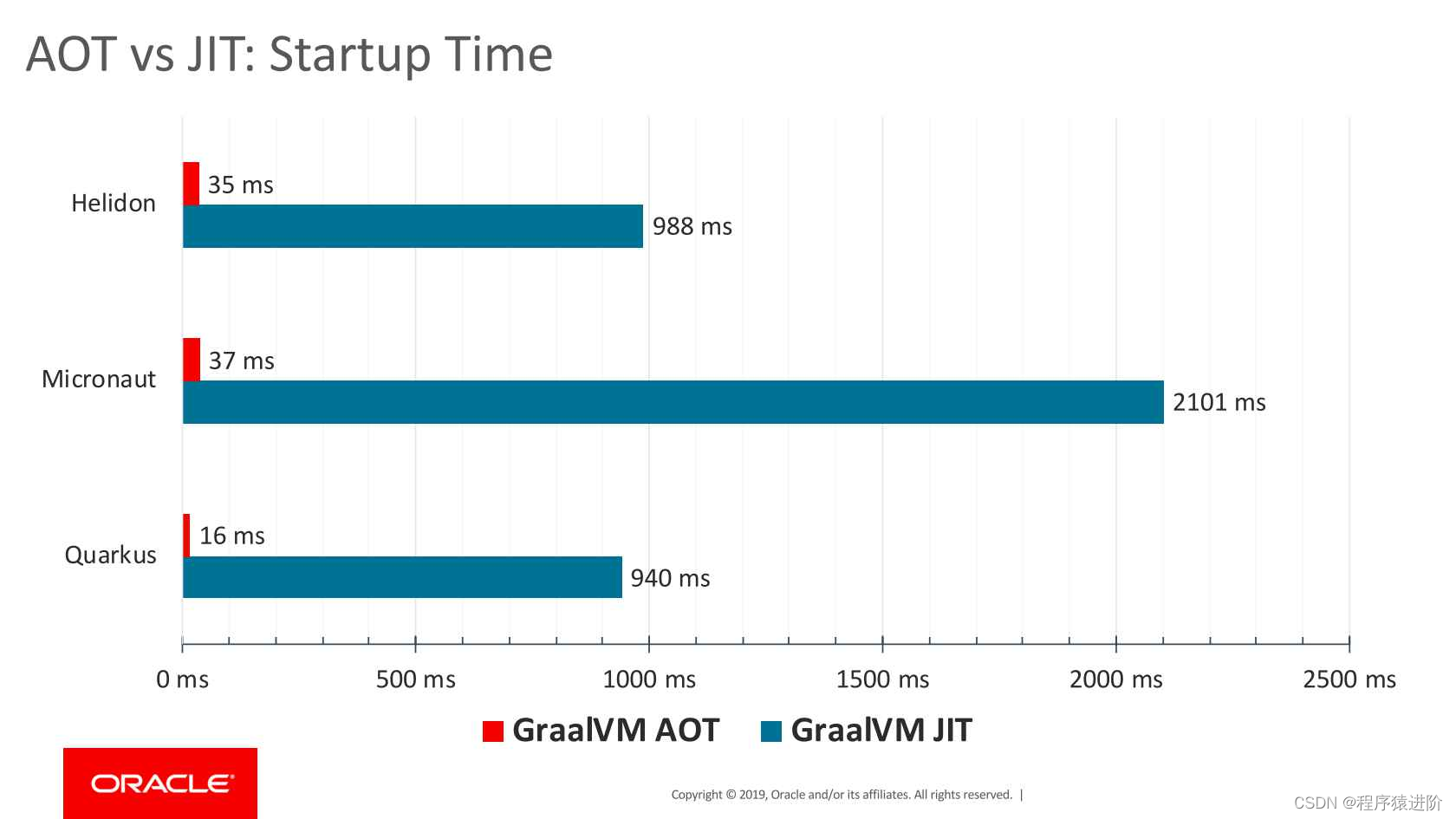
HashMap和HashSet都是存储在哈希桶之中,我们可以先了解一些哈希桶是什么。
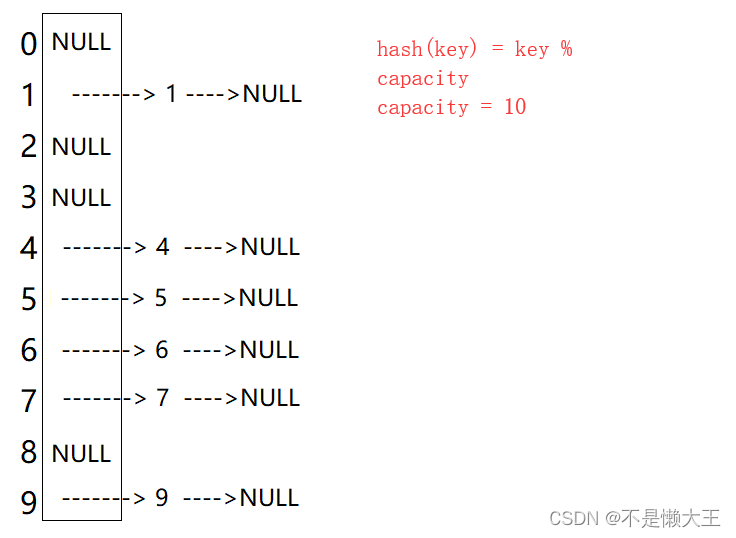
像这样,一个数组数组的每个节点带着一个链表,数据就存放在链表结点当中。哈希桶插入/删除/查找节点的时间复杂度是O(1)
map代表存入一个key值,一个val值。map可多次存储,当第二次插入时,会更新val值。
set代表只存入一个key值,但在实际源码中,set的底层其实也是靠map来实现的。set只能存入数据一次,当第二次插入时,若哈希桶中存在元素则返回false。
下面是代码实现
// key-value 模型
public class HashBucket {
private static class Node {
private int key;
private int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private Node[] array;
private int size; // 当前的数据个数
private static final double LOAD_FACTOR = 0.75;
public int put(int key, int value) {
int index = key % array.length;
// 在链表中查找 key 所在的结点
// 如果找到了,更新
// 所有结点都不是 key,插入一个新的结点
for (Node cur = array[index]; cur != null; cur = cur.next) {
if (key == cur.key) {
int oldValue = cur.value;
cur.value = value;
return oldValue;
}
} N
ode node = new Node(key, value);
node.next = array[index];
array[index] = node;
size++;
if (loadFactor() >= LOAD_FACTOR) {
resize();
} r
eturn -1;
}
private void resize() {
Node[] newArray = new Node[array.length * 2];
for (int i = 0; i < array.length; i++) {
Node next;
for (Node cur = array[i]; cur != null; cur = next) {
next = cur.next;
int index = cur.key % newArray.length;
cur.next = newArray[index];
newArray[index] = cur;
}
} a
rray = newArray;
}
private double loadFactor() {
return size * 1.0 / array.length;
}
public HashBucket() {
array = new Node[8];
size = 0;
}
public int get(int key) {
int index = key % array.length;
Node head = array[index];
for (Node cur = head; cur != null; cur = cur.next) {
if (key == cur.key) {
return cur.value;
}
}
return -1;
}
}