前言
NIO中缓冲区是数据传输的基础,JDK通过ByteBuffer实现,Netty框架中并未采用JDK原生的ByteBuffer,而是构造了ByteBuf。
Netty中的ByteBuf对ByteBuffer做了大量的优化,比如说内存池,零拷贝,引用计数(不依赖GC)。
JVM内存说明:
在JVM中 内存可分为两大块,一个是堆内存,一个是直接内存。
堆内存:
堆内存是Jvm所管理的内存,相比方法区,栈内存,堆内存是最大的一块。所有的对象实例实例以及数组大多数都要在堆上分配,Java的垃圾收集器是可以在堆上回收垃圾。
直接内存:
JVM使用Native函数在堆外分配内存,之后通过Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。直接内存不会受到Java堆的限制,只受本机内存影响。而DirectByteBuffer内部有使用到Cleaner对象,就是专门用于清理堆外内存。
所以直接内存的清理,需要事件型触发,故Java提出了虚引用的解决方案。虚引用,必须与一个引用队列关联。
虚引用主要用来跟踪对象被垃圾回收的活动。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象之前,把这个虚引用加入到与之关联的引用队列中。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
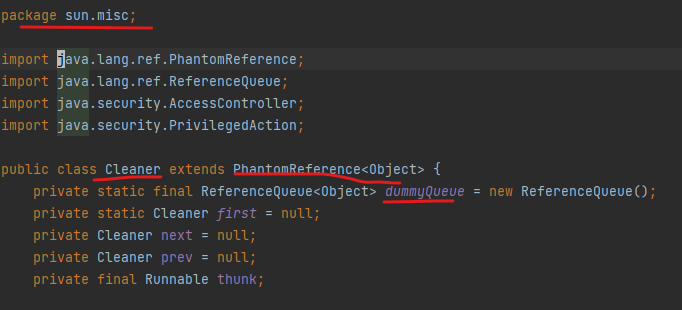
在hotspot的JVM中,有一个叫做cleaner的类,其实就是虚引用典型的应用。可以看到Cleaner是直接简单粗暴的继承了PhantomReference,所以它本质上就是一个虚引用,只不过多了一些便捷的操作。而其在DirectByteBuffer中使用到。
Cleaner通过next和prev构造了一个典型的链表,但它本身是没有任何逻辑的,因为它的清理逻辑都在thunk方法中。其内部依靠unsafe类申请的堆外内存地址引用(仅仅是个地址),有了引用和容量,就能够在回收的时候定位到真正的堆外内存块。
当然他们要如何关联起来,需要依靠其他线程完成,也就是ReferenceHandler。其内部方法tryHandlePending,调用Cleaner的clean方法,进而调用真正的清理方法,释放堆外内存。它会从虚引用注册的队列里,取出新的对象,然后判断是不是Cleaner类型,如果是,就进行一次清理。
**在commons-io包的FileCleaningTracker类中,同样有继承了虚引用的
Tracker类,用来跟踪后续文件的一些清理工作。**这个没存在感的小小虚引用,默默的承担起最后一道防线,是系统正常运行的有效保证。不要小看它,它无处不在。因为你的每一个JVM进程,都跑着一个叫做Reference Handler的线程呢。 虚引用。它存在的唯一目的,就是在回收的时候,能够被感知到,以便进行更深层次的清理。
JDK原生缓冲区ByteBuffer
在NIO中,所有数据都是用缓冲区处理的。读写数据,都是在缓冲区中进行的。缓存区实质是是一个数组,通常使用字节缓冲区——ByteBuffer。
| 属性 | 说明 |
|---|---|
| capacity | 缓冲区的大小,一旦申请将不能改变 |
| position | 位置索引,表示读模式或者写模式数据的位置,读模式和写模式切换的时候position会被重置为0,positon最大可谓capacity-1。 |
| limit | 在写模式下,Buffer的limit表示你最多能往Buffer里写多少数据。读模式下,limit等于buffer的capacity |
| mark | 标记,指一个备忘位置,调用mark()来设定mark=position,调用reset()来设定postion=mark,标记未设定前是未定义的. |
ByteBuffer可以申请两种方式的内存,分别为堆内存和直接内存。
//-------------申请堆内存
ByteBuffer HeapbyteBuffer = ByteBuffer.allocate(1024);
// 其内部如下
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
//-------------申请直接内存
ByteBuffer DirectbyteBuffer = ByteBuffer.allocateDirect(1024);
// 其内部如下 说白了allocateDirect()实际上就是new的一个DirectByteBuffer对象,不过这个new 一个普通对象不一样。这里使用了Native函数来申请内存,在Java中就是调用unsafe对象
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
ByteBuffer的常用方法与使用方式
Bytebuf的读和写是使用get()和put()方法实现的。但是读和写操作都会改变ByteBuffer的position属性,这两个操作是共用的position属性。这样就会带来一个问题,读写操作会导致数据出错啊,数据位置出错。
ByteBuffer提供了flip()方法,读写模式切换,切换的时候会改变position和limit的位置。
// 读操作
public byte get() {
return hb[ix(nextGetIndex())];
}
final int nextGetIndex() {
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}
// 写操作
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x;
return this;
}
final int nextPutIndex() {
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
public final Buffer flip() {
// 1. 设置 limit 为当前位置
limit = position;
// 2. 设置 position 为0
position = 0;
mark = -1;
return this;
}
Netty的ByteBuf
Netty使用的自身的ByteBuf对象来进行数据传输,本质上使用了外观模式对JDK的ByteBuffer进行封装。相较于原生的ByteBuffer,Netty的ByteBuf做了很多优化,零拷贝,内存池加速,读写索引。
对于ByteBuf对象管理,主要分Pooled 和 Unpooled两类。Netty4默认使用池化对象Pooled的方式,可通过参数-Dio.netty.allocator.type=unpooled或pooled进行设置。
Heap指ByteBuf关联的内存JVM堆内分配,分配的内存受GC管理。
Direct Heap,指ByteBuf关联的内存在JVM堆外分配,分配的内存不受GC管理,需要通过系统调用实现申请和释放,底层基于Java NIO的DirectByteBuffer对象。
非池化对象(Unpooled)
Unpooled非池化对象,每次分配时直接调用系统 API 向操作系统申请ByteBuf需要的同样大小内存,用完后通过系统调用进行释放内存。
note: **使用堆外内存的优势在于,Java进行I/O操作时,需要传入数据所在缓冲区起始地址和长度。由于GC的存在,对象在堆中的位置往往会发生移动,导致对象地址变化,系统调用出错。**为避免这种情况,当基于堆内存进行I/O系统调用时,需要将内存拷贝到堆外,而直接基于堆外内存进行I/O操作的话,可以节省该拷贝成本。
池化(Pooled)对象管理
Pooled池化对象,内存分配时基于预分配的一整块大内存,取其中的部分封装成ByteBuf提供使用,用完后回收到内存池中。
优点
- 内存池管理算法是如何实现高效内存分配释放,减少内存碎片
- 高负载下内存池不断申请/释放,如何实现弹性伸缩
- 内存池作为全局数据,在多线程环境下如何减少锁竞争
内存池划分
Netty中将内存池分为五种不同的形态:Arena、ChunkList、Chunk、Page、SubPage。Netty中最大的内存单位PoolArena是连续的内存块,它是由多个PoolChunkList和两个SubPagePools(一个是tinySubPagePool,一个是smallSubPagePool)组成的。
SubPage:大小不固定
Page:默认大小8K。 Page中包含多个SubPage。
Chunk:默认2048个page
ChunkList:Chunk 个数动态变化
**PoolChunkList是一个双向的链表,PoolChunkList负责管理多个PoolChunk的生命周期。PoolChunk中包含多个Page,Page的大小默认是8192字节。**也可以设置系统变量io.netty.allocator.pageSize来改变页的大小。自定义页大小有如下限制:1.必须大于4096字节,2.必须是2的整次数幂。
*PoolChunk的大小是由页的大小和maxOrder算出来的,计算公式是:chunkSize = 2^{maxOrder} * pageSize。 maxOrder的默认值是11,也可以通过io.netty.allocator.maxOrder系统变量设置,只能是0-14的范围,所以chunksize的默认大小为:(2^11)8192=16MB
PoolChunk内部维护了一个平衡二叉树用于根据所需内存大小,去分配适量的空间。
Netty如何分配内存池中的内存?
分配原则(内存池中的内存分配是在PoolArea中进行的)
- 申请小于PageSize(默认8192字节)的内存,会在SubPagePools中进行分配,如果申请内存小于512字节,则会在tingSubPagePools中进行分配,如果大于512小于PageSize字节,则会在smallSubPagePools进行分配。
- 申请大于PageSize的内存,则会在PoolChunkList中进行分配。
- 申请大于ChunkSize的内存,则不会在内存池中申请,在堆外内存中分配。
什么情况下使用内存池?
底层IO处理线程的缓冲区使用堆外直接缓冲区,减少一次IO复制。业务消息的编解码使用堆缓冲区,分配效率更高,而且不涉及到内核缓冲区的复制问题。Netty默认不使用内存池,需要在创建服务端或者客户端的时候进行配置。
//Boss线程池内存池配置.
.option(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT)
//Work线程池内存池配置.
.childOption(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT);
常规业务处理的时候,I/O处理线程使内存池中的直接内存,开启以上配置。而在handler处理业务的时候,使用内存池中的堆内存。
但是需要注意的是,在使用完内存池中的ByteBuf,一定要记得释放,即调用release()。如果handler继承了SimpleChannelInboundHandler,那么它将会自动释放。
Netty内存池的算法设计
原理设计
Netty先向系统申请一整块连续内存,称为chunk,默认大小chunkSize = 16Mb,通过PoolChunk对象包装。为了更细粒度的管理,Netty将chunk进一步拆分为page,默认每个chunk包含2048个page(pageSize = 8Kb)。在同一个chunk中,Netty将page按照不同粒度进行多层分组管理。
- 第1层,分组大小size = 1*pageSize,一共有2048个组
- 第2层,分组大小size = 2*pageSize,一共有1024个组
- 第3层,分组大小size = 4*pageSize,一共有512个组 …
当请求分配内存时,将请求分配的内存数向上取值到最接近的分组大小,在该分组大小的相应层级中从左至右寻找空闲分组,例如请求分配内存对象为1.5 *pageSize,向上取值到分组大小2 * pageSize,在该层分组中找到完全空闲的一组内存进行分配。
当分组大小2 * pageSize的内存分配出去后,为了方便下次内存分配,分组被标记为全部已使用,向上更粗粒度的内存分组被标记为部分已使用。
算法结构
**Netty基于平衡树实现上面提到的不同粒度的多层分组管理。**当需要创建一个给定大小的ByteBuf,算法需要在PoolChunk中大小为chunkSize的内存中,找到第一个能够容纳申请分配内存的位置
为了方便快速查找chunk中能容纳请求内存的位置,算法构建一个基于byte数组(memoryMap)存储的完全平衡树,该平衡树的多个层级深度,按照不同粒度对chunk进行多层分组。

树的最大深度为maxOrder(最大阶,默认值11),通过这棵树,算法在chunk中的查找就可以转换为:**当申请分配大小为chunkSize/2^k的内存,在平衡树高度为k的层级中,从左到右搜索第一个空闲节点。**数组的使用域从index = 1开始,将平衡树按照层次顺序依次存储在数组中,depth = n的第1个节点保存在memoryMap[2^n] 中,第2个节点保存在memoryMap[2^n+1]中,以此类推。
使用情况判断
可以根据memoryMap[id]的值得出节点的使用情况,memoryMap[id]值越大,剩余的可用内存越少。
1)memoryMap[id] = depth_of_id:id节点空闲, 初始状态,depth_of_id的值代表id节点在树中的深度
2)memoryMap[id] = maxOrder + 1:id节点全部已使用,节点内存已完全分配,没有一个子节点空闲
3)depth_of_id < memoryMap[id] < maxOrder + 1:id节点部分已使用,memoryMap[id] 的值 x,代表id的子节点中,第一个空闲节点位于深度x,在深度[depth_of_id, x)的范围内没有任何空闲节点
申请释放内存
当申请分配内存,会首先将请求分配的内存大小归一化(向上取值),通过PoolArena#normalizeCapacity()方法,取最近的2的幂的值,例如8000byte归一化为8192byte( chunkSize/2^11 ),8193byte归一化为16384byte(chunkSize/2^10)。
处理内存申请的算法在PoolChunk#allocateRun方法中,当分配已归一化处理后大小为chunkSize/2^d的内存,即需要在depth = d的层级中找到第一块空闲内存,算法从根节点开始遍历 (根节点depth = 0, id = 1),具体步骤如下:
- 步骤1 判断是否当前节点值memoryMap[id] > d,或depth_of_id > d 如果是,则无法从该chunk分配内存,查找结束
- 步骤2 判断是否节点值memoryMap[id] == d,且depth_of_id <= d 如果是,当前节点是depth = d的空闲内存,查找结束,更新当前节点值为memoryMap[id] = max_order + 1,代表节点已使用,并遍历当前节点的所有祖先节点,更新节点值为各自的左右子节点值的最小值;如果否,执行步骤3
- 步骤3 判断是否当前节点值memoryMap[id] <= d,且depth_of_id <= d 如果是,则空闲节点在当前节点的子节点中,则先判断左子节点memoryMap[2 * id] <=d(判断左子节点是否可分配),如果成立,则当前节点更新为左子节点,否则更新为右子节点,然后重复步骤1, 2
当需要释放内存时,根据申请内存返回的id,将 memoryMap[id]更新为depth_of_id,同时设置id节点的祖先节点值为各自左右节点的最小值
巨型对象内存管理
对于申请分配大小超过chunkSize的巨型对象(huge),Netty采用的是非池化管理策略。
在每次请求分配内存时单独创建特殊的非池化PoolChunk对象进行管理,内部memoryMap为null,当对象内存释放时整个Chunk内存释放,相应内存申请逻辑在PoolArena#allocateHuge()方法中,释放逻辑在PoolArena#destroyChunk()方法中。
小对象内存管理
当请求对象的大小reqCapacity <= 496,归一化计算后方式是向上取最近的16的倍数。规整后的大小(normalizedCapacity)小于pageSize的小对象可分为2类: 微型对象(tiny):规整后为16的整倍数,如16、32、48、…、496,一共31种规格;小型对象(small):规整后为2的幂的,有512、1024、2048、4096,一共4种规格。
这些小对象直接分配一个page会造成浪费,在page中进行平衡树的标记又额外消耗更多空间,因此Netty的实现是:先PoolChunk中申请空闲page,同一个page分为相同大小规格的小内存进行存储。这些page用PoolSubpage对象进行封装,PoolSubpage内部有记录内存规格大小(elemSize)、可用内存数量(numAvail)和各个小内存的使用情况,通过long[]类型的bitmap相应bit值0或1,来记录内存是否已使用
不同大小池化内存对象的分配策略不同
详细内容,请查看:https://juejin.cn/post/6844904034801811469
ByteBuf的优化
1、零拷贝
1)堆外内存,避免 JVM 堆内存到堆外内存的数据拷贝。
Netty 的接收和发送 ByteBuffer 采用 堆外直接内存 (DIRECT BUFFERS) 进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的 堆内存(HEAP BUFFERS) 进行 Socket 读写,JVM 会将 堆内存 Buffer 拷贝一份到 直接内存 中,然后才写入 Socket。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
2)使用 Netty 提供的 CompositeByteBuf 类, 可以将多个ByteBuf 合并为一个逻辑上的 ByteBuf, 避免了各个 ByteBuf 之间的拷贝。
CompositeByteBuf 实际就是个 ByteBuf 的装饰器,它将多个 ByteBuf 组合成一个集合,然后对外提供统一的 ByteBuf 接口,添加 ByteBuf,不需要做内存拷贝。
其内部通过 Unpooled.wrappedBuffer 可以将 byte 数组包装成 ByteBuf 对象,包装过程中不会产生内存拷贝。
同时ByteBuf 支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝。
关于ByteBuffer,Netty提供了两个接口:ByteBuf、ByteBufHolder,并提供了多种实现:
- Heap ByteBuf: 直接在堆内存分配
- Direct ByteBuf:直接在内存区域分配而不是堆内存
- CompositeByteBuf:组合Buffer
3)文件传输,采用Linux的sendfile
通过 FileRegion 包装的FileChannel#tranferTo() 实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题。其中transferTo方法使用的就是sendFile函数。
2、内存池
JVM中的直接内存,在Java种是DirectByteBuffer类,另外这里是映射关系。每次申请直接内存,都先看看是否超限 —— 直接内存的限额默认(可用 -XX:MaxDirectMemorySize 重新设定)。
如果超过限额,就会主动执行System.gc(),这样会带来一个影响,系统会中断100ms。如果没有成功回收直接内存,并且还是超过直接内存的限额,就会抛出OOM——内存溢出。
通常来说,DirectByteBuffer需要熬过了几次young gc之后,会进入老年代。当老年代满了之后,会触发Full GC。因为本身很小,很难占满老年代,那么会使大量堆外内存一直占着不放,无法进行内存回收。或者是依靠申请额度超限时触发的system.gc(),但是它会中断进程100ms,如果在这100ms的之间,系统未完成GC,仍会抛出OOM。
Netty使用了引用计数的方式,主动回收内存。回收的对象包括非池直接内存,和内存池中的内存。
3、读写索引
ByteBuf提供读访问索引(readerIndex)和写访问索引(writerIndex)来控制字节数组。ByteBuf共有三种模式: 堆缓冲区模式(Heap Buffer)、直接缓冲区模式(Direct Buffer)和复合缓冲区模式(Composite Buffer)
当readerIndex > writerIndex时,则抛出IndexOutOfBoundsException。其中ByteBuf容量 = writerIndex,ByteBuf可读容量 = writerIndex - readerIndex。
Netty的ByteBuf同时具有读索引和写索引,但JDK的ByteBuffer只有一个索引,所以JDK需要调用flip()方法在读模式和写模式之间切换。 ByteBuf被读索引和写索引划分成3个区域:可丢弃字节区域,可读字节区域和可写字节区域。
1)堆缓冲区模式(Heap Buffer)
堆缓冲区模式又称为:支撑数组(backing array)。将数据存放在JVM的堆空间,通过将数据存储在数组中实现。适用于业务消息编码场景。
优点:
由于数据存储在Jvm堆中可以快速创建和快速释放,并且提供了数组直接快速访问的方法
缺点:
每次数据与I/O进行传输时,都需要将数据拷贝到直接缓冲区
2)直接缓冲区模式(Direct Buffer)
Direct Buffer属于堆外分配的直接内存,不会占用堆的容量。适用于套接字传输过程,避免了数据从内部缓冲区拷贝到直接缓冲区的过程,性能较好。
优点:
使用Socket传递数据时性能很好,避免了数据从Jvm堆内存拷贝到直接缓冲区的过程。提高了性能
缺点:
相对于堆缓冲区而言,Direct Buffer分配内存空间和释放更为昂贵。对于涉及大量I/O的数据读写,建议使用Direct Buffer。
3)复合缓冲区模式(Composite Buffer)
Composite Buffer是Netty特有的缓冲区。本质上类似于提供一个或多个ByteBuf的组合视图,可以根据需要添加和删除不同类型的ByteBuf。它提供一种访问方式让使用者自由的组合多个ByteBuf,避免了拷贝和分配新的缓冲区。
Composite Buffer不支持访问其支撑数组。因此如果要访问,需要先将内容拷贝到堆内存中,再进行访问
优点:
- 允许用户自定义缓冲区类型扩展
- 通过内置的复合缓冲区类型实现透明的零拷贝
- 容量可按需增长
- 读写这两种模式之间不需要调用类似于JDK的ByteBuffer的flip()方法进行切换
- 读和写使用不同的索引
- 支持方法的链式调用
- 支持引用计数
- 支持池化
详细了解,可查看:https://blog.csdn.net/thinking_fioa/article/details/80795673
其他
1、内存池的内存泄露是如何检测?
**Netty中使用引用计数机制来管理资源,ByteBuf实际上是实现了ReferenceCounted接口,当实例化ByteBuf对象时,引用计数加1。**当应用代码保持一个对象引用时,会调用retain方法将计数增加1,对象使用完毕进行释放,调用release将计数器减1。当引用计数变为0时,对象将释放所有的资源,返回内存池。
Netty内存泄漏检测级别:
禁用(DISABLED) - 完全禁止泄露检测。不推荐。
简单(SIMPLE) - 告诉我们取样的1%的缓冲是否发生了泄露。默认。
高级(ADVANCED) - 告诉我们取样的1%的缓冲发生泄露的地方
偏执(PARANOID) - 跟高级选项类似,但此选项检测所有缓冲,而不仅仅是取样的那1%。此选项在自动测试阶段很有用。如果构建(build)输出包含了LEAK,可认为构建失败
可以使用JVM的-Dio.netty.leakDetectionLevel选项来指定泄漏检测级别。
内存跟踪
**在内存池中分配内存,得到的ByteBuf对象都是经过toLeakAwareBuffer()方法封装的,该方法作用就是对ByteBuf对象进行引用计数。**使用SimpleLeakAwareByteBuf或者AdvancedLeakAwareByteBuf来包装ByteBuf。内存泄露检测是在AbstractByteBuf.leakDetector.track(buf)进行的,该返回对象为DefaultResourceLeak。
**此外该方法只对非池内存中的直接内存和内存池中的内存进行内存泄露检测。如果监控级别低于PARANOID,在一定的采样频率下报告内存泄露。**同时每次需要分配 ByteBuf 时,也会报告内存泄露情况。
DefaultResourceLeak继承了虚引用WeakReference,虚引用完全不影响目标对象的垃圾回收,但是会在目标对象被VM垃圾回收时加入到引用队列。
**正常情况下ResourceLeak对象,会将监控的资源的引用计数为0时被清理掉。但是当资源的引用计数失常,ResourceLeak对象也会被加入到引用队列。**存在着这样一种情况:没有成对调用ByteBuf的retain和relaease方法,导致ByteBuf没有被正常释放,当ResourceLeak(引用队列) 中存在元素时,即表明有内存泄露。
Netty中的 reportLeak()方法来报告内存泄露情况,通过检查引用队列来判断是否有内存泄露,并报告跟踪情况。
2、Handler中的内存处理机制
**Netty中有handler链,消息由当前Handler传到下一个Handler。所以Netty引入了一个规则,谁是最后使用者,谁负责释放。**另外,Netty在Handler链的最末补了一个TailHandler,如果此时消息仍然是ReferenceCounted类型就会被release掉。
每个Handler对消息可能有三种处理方式:
- 对原消息不做处理,调用 ctx.fireChannelRead(msg)把原消息往下传,那不用做什么释放。
- 将原消息转化为新的消息并调用 ctx.fireChannelRead(newMsg)往下传,那必须把原消息release掉。
- 如果已经不再调用ctx.fireChannelRead(msg)传递任何消息,那更要把原消息release掉。
小结:
Netty在不同的内存泄漏检测级别情况下,采样概率是不一样的,在Simple情况下出现了Leak,要设置“-Dio.netty.leakDetectionLevel=advanced”再跑一次代码,找到创建和访问的地方。
**Netty中的内存泄露检测是通过对ByteBuf对象进行装饰,利用虚引用和引用计数来对非池中的直接内存和内存池中内存进行跟踪,判断是否发生内存泄露。**计数器基于 AtomicIntegerFieldUpdater,因为ByteBuf对象很多,如果都把int包一层AtomicInteger花销较大,而AtomicIntegerFieldUpdater只需要一个全局的静态变量。
总结
Netty的内存池,适用于大文件传输设计、也适用于普通业务型的消息。大文件采用堆外内存,业务处理采用池化内存,方便管理,同时还能提升性能。