高速缓存
什么是高速缓存
高速缓存(Cache)是一种用于存储计算机数据的临时存储设备,用于加速数据访问速度,减少对主存储器(RAM)或磁盘的频繁访问。高速缓存通过将最常用的数据存储在更接近CPU的位置,从而提供更快的数据检索速度,从而提高系统性能。
引入高速缓存的目的
计算机在运行程序时首先将程序从磁盘读取到主存,然后CPU按规则从主存中取出指令、数据并执行指令,但是随着时间的推移,CPU 和内存的访问性能相差越来越大 ,直接从主存(一般用DRAM制成)中读写是很慢的,所以我们引入了cache。
在执行程序前,首先会试图把要用到的指令、数据从主存移到cache中,然后在执行程序时直接访问cache。
高速缓存的分类
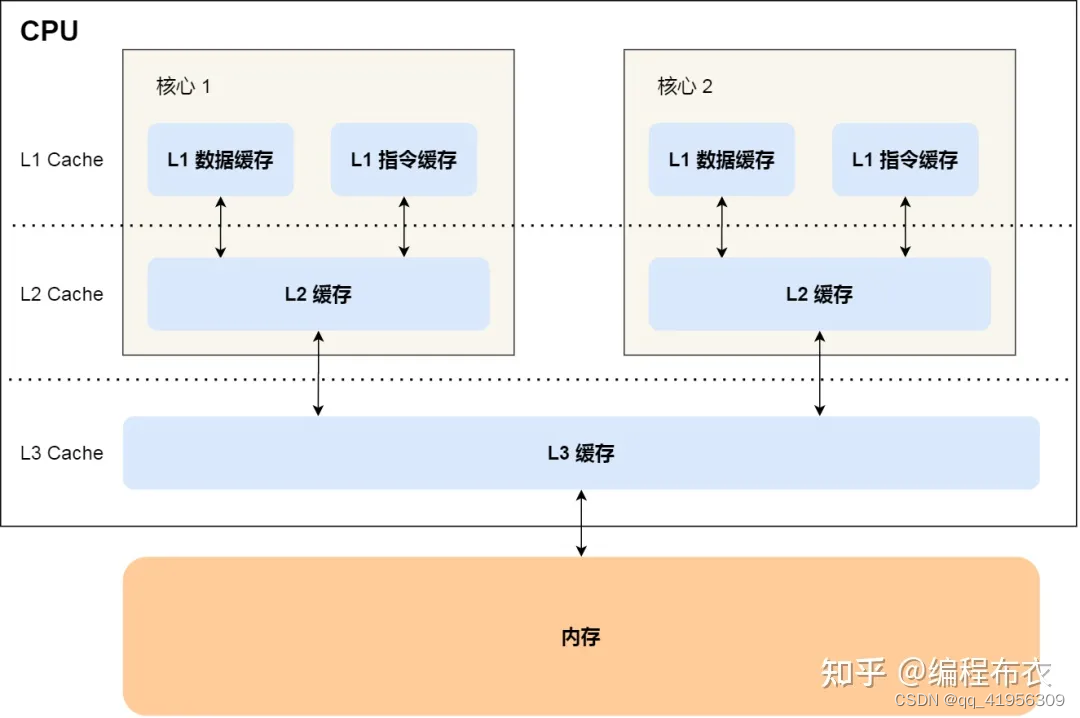
L1 Cache(一级缓存):
位于处理器核心内部。
通常分为数据缓存(D缓存)和指令缓存(I缓存)。
用于存储处理器核心频繁使用的数据和指令。
具有最快的访问速度,但容量较小。
L2 Cache(二级缓存):
通常位于处理器核心之间,多个核心共享。
更大容量的缓存,可存储更多数据和指令。
访问速度比L1 Cache慢一些,但比主存储器快。
L3 Cache(三级缓存):
通常位于多个CPU核心之间,多个处理器共享。
容量更大,可用于共享数据和指令。
访问速度通常比L2 Cache慢,但仍比主存储器快。
主存(Main Memory):
也被称为RAM(随机访问存储器)。
比L3 Cache慢,但仍提供了较高的带宽和存储容量。
通常用于存储程序和数据,是CPU主要的数据来源之一。
引入高速缓存导致了什么问题
引入高速缓存可以显著提高计算机系统的性能和响应速度但同时也可能引发以下一些问题:
一致性问题: 高速缓存引入了一致性问题,即在多个缓存副本之间保持数据的一致性。当一个核心修改了缓存中的数据时,其他核心的缓存需要知道这个更改,以避免数据不一致的情况。一致性协议(如MESI协议)用于解决这个问题,但会引入一定的性能开销。
缓存污染: 当高速缓存大小有限时,可能会出现缓存污染问题。某些数据块可能被频繁地加载到缓存中,而其他重要数据却无法进入缓存,从而导致性能下降。
缓存争用: 多个核心同时尝试访问共享缓存时,可能会导致缓存争用问题。这可能会导致性能下降,因为核心必须等待缓存访问权限。
一致性开销: 维护缓存一致性需要额外的开销,包括缓存一致性协议的开销以及在核心之间传输一致性信息的开销。
缓存失效: 缓存中的数据可能会由于缓存不命中而失效,导致需要从主存储器中重新加载数据。这会引入访问延迟。
复杂性: 高速缓存管理和一致性是复杂的问题,需要复杂的硬件和软件支持。这增加了系统的复杂性和维护难度。
缓存一致性问题
什么是缓存一致性问题
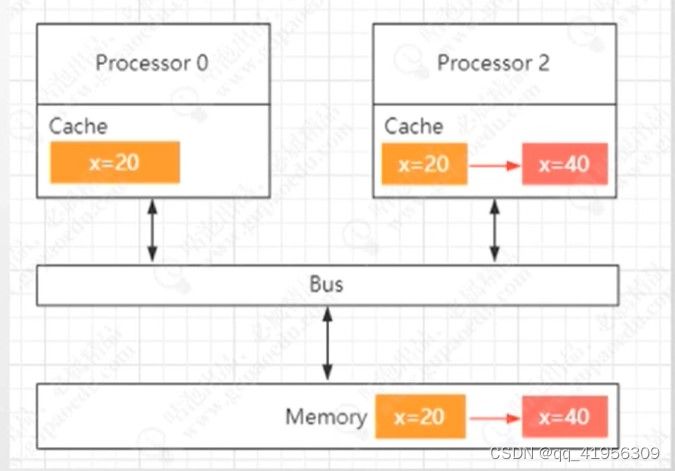
CPU缓存一致性问题是指在多处理器或多核系统中,每个处理器核心具有自己的高速缓存(Cache),而共享相同主内存(Main Memory)的数据可能存在多个缓存中的不一致性。这可能导致在并发多线程或多进程环境中,数据的不一致性和错误结果。
Processor02修改缓存x=20的值改为40 同步到本地缓存行 但是没同步到主内存中 所以Processor0读到的还是X=20是之前的值所以造成了缓存的不一致性
如何解决缓存一致性问题
总线锁
什么是总线
cpu与内存 输出/输入设备传递信息的公共通道 当cpu访问内存进行数据交互时 必须经过总线来传输
什么是总线锁
总线锁是通过系统总线(通常是内存总线)来实现的。当一个核心要写入某个内存地址时,它会向总线发送锁定请求。
总线锁会锁定整个总线,阻止其他核心访问内存,直到请求核心完成写操作。
这可以确保在总线上只有一个核心能够访问内存,从而避免了并发写入导致的数据不一致性。
但是总线锁锁定的是整个总线 期间会阻止其他核心访问内存所以他的消耗特别高
缓存锁
缓存锁是通过处理器核心的高速缓存来实现的。当一个核心要写入某个内存地址时,它会向其他核心发出缓存锁定请求。
如果其他核心已经缓存了相同的内存地址,它会释放该数据的缓存行,让请求核心获得独占访问。
这可以防止多个核心同时修改同一内存地址,从而确保数据一致性。
如果当前cpu访问的数据已经被缓存到其他cpu高速缓存中 那么 cpu不会在总线上声明Lock#信号 而是采用缓存一致性协议来保证多个cpu的缓存一致性
缓存一致性协议
什么是缓存一致性
M(Modify)
表示共享数据只缓存在当前CPU缓存中 并且是被修改状态 缓存的数据和主内存的数据不一致
E(Exclusive)
表示缓存的独占状态 数据只缓存在当前CPU缓存中 并且没有被修改
S(Shared)
表示数据可能被多个CPU缓存 并且各个缓存中的数据和主内存数据一致
I(Invalid)
表示缓存已经失效
缓存一致性遵守的规则
如果一个缓存行处于M状态 则必须监听所有试图获取该缓存行对应的主内存地址的操作 如果监听这类操作的发生 则必须在该操作 之前把缓存行中的数据写回主内存
如果缓存行处于S状态 那么则必须要监听使该缓存行状态设置为Invalid 或者对缓存行执行Exclusive操作的请求 如果存在则必须要把当前缓存行状态设置为Invalid
如果一个缓存行状态为E状态 那么它必须要监听其他试图读取该缓存行对应的主内地址的操作一旦有这种操作该缓存行需要设置成Shared
监听过程由总线嗅探协议完成
有了缓存一致性之后数据读取流程
1.Cpu0发出一条从内存中读取X变量的指令 主内存通过总线返回数据后缓存到CPU0的高速缓存中 将状态设置成E
2.如果此时CPU1发出对变量X的读取指令 那么当CPU0检测到缓存地址冲突就会针对该消息作出响应,将缓存在cpu0的x的值通过ReadResponse消息返回给CPU1 此时X分别存在CPU0和CPU1的高速缓存中所有X的状态为S
3.然后CPU0把X变量的值修改成x=30 把自己的缓存行状态设置成E 接着把修改后的数据写入内存中 此时X的缓存行是共享状态 同时需要发送一个Invalidate消息给其他缓存 Cpu1收到消息后把高速缓存的x置为Invalid状态
指令重排序
什么是指令重排序
指令重排序是一种优化编译器和处理器执行指令的技术,它可以改变指令的执行顺序,以提高程序的性能。然而,指令重排序可能导致多线程编程中出现意外的行为,因此需要在某些情况下加以控制。
指令重排序引发的问题
指令重排序问题的核心是:在多核处理器中,由于编译器和处理器会尽力提高指令的执行效率,导致在不改变程序语义的前提下,重新排列指令的执行顺序。这可能会引发以下问题:
可见性问题:当一个线程对某个共享变量进行写操作,其他线程可能无法立即看到这个写入的结果。这会导致线程间通信问题,例如一个线程修改了共享变量,但其他线程仍然读取了旧的值。
并发性问题:由于指令重排序,可能会导致多线程之间发生意外的交互,从而破坏了预期的执行顺序。
指令重排序阶段
编译器重排序:编译器在生成机器代码时可能会对源代码中的指令进行重新排序,以提高执行效率。这种重排序通常是基于编译器的优化,但需要确保不改变程序的语义。
处理器重排序:处理器在执行指令时,可能会对指令进行重新排序以充分利用处理器内部资源,例如乱序执行。这种重排序是在不改变程序语义的前提下,通过并行执行来提高性能。
内存重排序:处理器与内存之间的数据传输也可能导致重排序。处理器可以对内存访问指令进行重排序,从而影响多线程环境下的可见性。
as-if-serial语义
as-if-serial" 是 Java 内存模型(Java Memory Model,JMM)的一个重要概念。它表示在多线程环境下,程序执行的结果必须与某个顺序一致的串行执行结果一致。
具体来说,“as-if-serial” 原则保证了编译器、处理器和运行时环境不会改变代码中不存在数据竞争的操作的执行顺序。这意味着虽然编译器和处理器可以对指令进行重排序,但不能改变数据竞争操作的执行顺序。
“as-if-serial” 原则的主要目标是确保多线程程序的行为与单线程程序一致。在单线程程序中,所有操作都是串行执行的,因此多线程程序在各个线程中的操作也必须具有某种有序性。
举例来说,考虑以下代码:
int x = 1;
int y = 2;
int result = x + y;
在单线程环境中,这三个操作是按照顺序执行的。在多线程环境中,编译器和处理器可能会对这些操作进行重排序,但不能改变它们的执行顺序。这意味着不会出现如下情况:线程 A 的 x 操作在线程 B 的 y 操作之后执行,从而导致错误的结果。
总之,“as-if-serial” 原则是 Java 内存模型中的一个重要概念,它确保了多线程程序的行为与单线程程序一致。
重排序对多线程的影响
现在让我们来看看,重排序是否会改变多线程程序的执行结果,请看下面的示例代码:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
flag变量是个标记,用来标识变量a是否已经被写入。这里假设有两个线程A和B,A首先执行write方法,随后B线程接着执行reader()方法。线程B在执行操作4的时候,能否看到线程A在操作1对共享变量的写入吗?
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4也没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作1和操作2重排序的时候,可能会产生什么效果?请看下面的
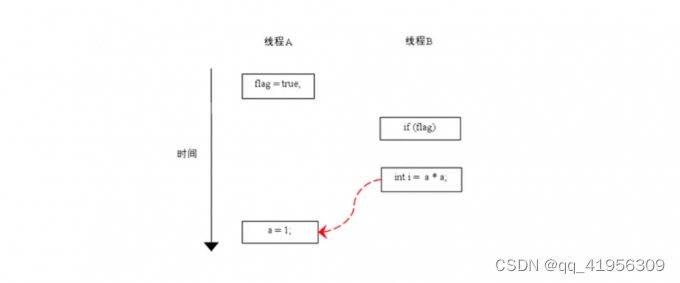
如上图所示,操作1和操作2做了重排序。程序执行的时候,线程A首先写标记变量flag,随后随后线程B读了这个变量。由于条件判断为真,线程B将读取变量a,此时变量a还根本没有被线程A写入,在这里多线程程序的语义被重排序破坏了。
下面再让我们看看,当操作3和操作4重排序的时候会产生什么效果(借助这个重排序,可以顺便说明控制依赖性),下面是操作3和操作4重排序后,程序的执行时序图:
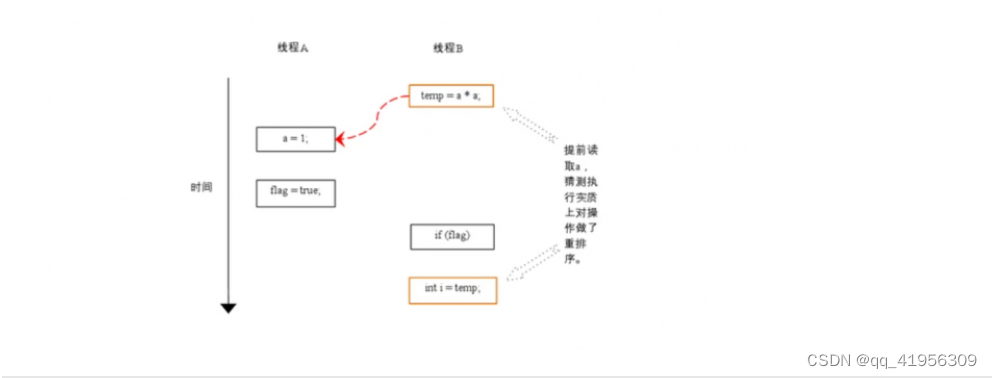
在程序中,操作3和操作4存在控制依赖关系,当代码中存在控制依赖性的时候,会影响程序序列执行的并行度,为此,编译器会采用猜测执行来克服相关性对并行度的影响,以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果保存到一个名为重排序缓冲的硬件缓存中。当接下来的判断条件为真的时候,就把该计算结果写入变量i中。
从图中我们可以看出,猜测执行实质上对操作3和4做了重排序,重排序在这里破坏了多线程程序的语义。
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作进行重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
CPU性能优化之旅
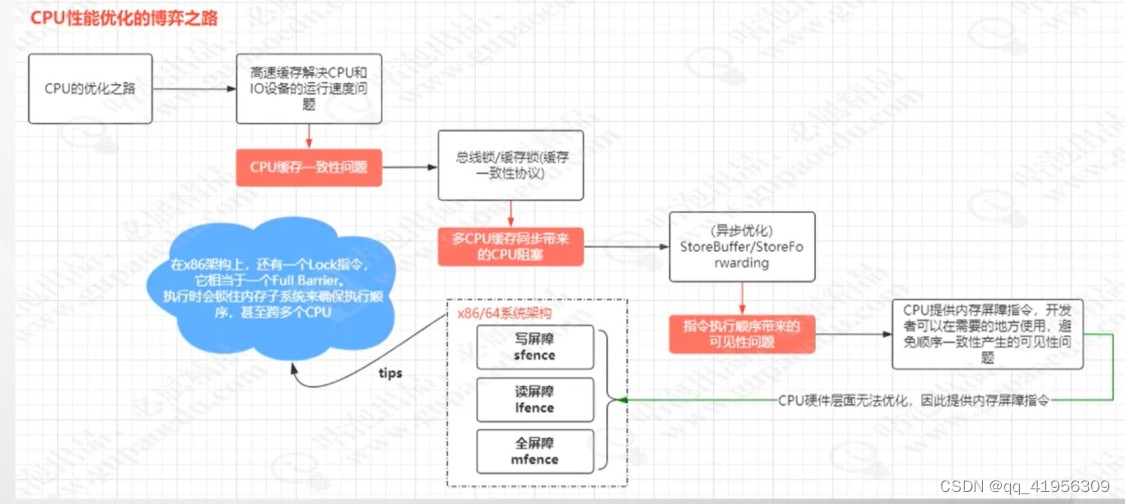
可以参考
https://zhuanlan.zhihu.com/p/125549632?utm_source=ZHShareTargetIDMore&utm_medium=social&utm_oi=1224314960559403008
内存屏障
什么是内存屏障
内存屏障(Memory Barrier),也被称为内存栅栏或内存屏障指令,是计算机系统中的一种重要概念,用于控制和优化多核处理器和多线程编程的内存访问顺序和可见性
内存屏障的作用
内存屏障的主要作用是确保内存操作的顺序和可见性,以防止出现意外的重排序和数据竞争问题。内存屏障通常在多线程环境中用于以下目的:
保证内存可见性:内存屏障可以确保一个线程对共享变量的修改在另一个线程看到之前完全可见。这有助于避免数据竞争和不一致性问题。
防止重排序:现代处理器通常会对指令进行重排序以提高性能。内存屏障可以防止编译器和处理器对指令重排序,确保指令按照预期的顺序执行。
控制内存操作的顺序:内存屏障允许程序员精确地控制内存操作的执行顺序,以满足特定需求,例如保证写操作先于读操作。
内存屏障类型
1.读屏障(ifence)
将Invalidate Queues中的指令立即处理 并且强制读取cpu的缓存行 执行 ifence指令之后的读操作不会被重排序到ifence指令之前这意味着其他cpu 暴露出来的缓存行对当前cpu可见
2.写屏障(sfence)
会把 store Buffers中修改刷新到本地缓存中 使得其他cpu可以看到这些修改 而且在执行sfence指令之后的写操作不会重排序到 sfence指令之前 这意味着sfence指令之前的写操作全局可见
3.读写屏障(mfence)
保证了 mfence指令执行前后的读写操作的顺序 同时要求执行 mfence指令之后的写操作全局可见 之前的写操作全局可见
volatile详解
什么是volatile
volatile 是Java中的一个关键字,用于声明变量,表示该变量是共享的,多个线程可以同时访问避免出现可见性和指令重排序问题
volatile的作用
可见性(Visibility):volatile 修饰的变量在一个线程中被修改后,会立即将最新的值写回主内存,而其他线程在访问该变量时会从主内存中读取最新的值。这确保了所有线程能够看到同一个共享变量的最新值,从而避免了数据不一致的问题。
禁止指令重排序(Preventing Reordering):volatile 修饰的变量会禁止编译器和处理器对其进行指令重排序,确保了操作的顺序不会被改变。这对于一些需要保持顺序的操作非常重要,例如双重检查锁定模式中的初始化操作。
虽然 volatile 具有可见性和禁止指令重排序的特性,但它并不提供原子性。这意味着虽然读取和写入 volatile 变量是原子的,但复合操作(例如递增)仍然可能不是原子的。因此,如果多个线程同时修改 volatile 变量的值,可能会导致竞态条件。
使用场景
控制变量的可见性,确保所有线程都可以看到更新后的值。
用于标记状态标志,例如线程间的信号传递。
简单的读写操作,而不需要复杂的同步控制。
用于实现一些高效的单例模式。
案例
用于实现双重检查锁定的单例模式,以确保线程安全的懒汉式单例。
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
// 私有构造函数
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
volatile怎么解决的可见性问题和指令重排序问题
事实上,我们的JMM模型就是类比CPU多核缓存架构的,它的作用是屏蔽掉了底层不同计算机的区别
JMM不是真实存在的,只是一个抽象的概念。volatile也是借助MESI缓存一致性协议和总线嗅探机制及内存屏障才得以完成
volatile关键字会在JVM层面声明一个C++的volatile 他能防止JIT层面的指令重排序
在对修饰了volatile关键字的字段复制后 JVM会调用 storeload()内存屏障方法该方法声明了lock指令 该指令有两个作用
1.在CPU层面赋值的指令会先存储到StoreBuffers中 所以Lock指令会使得StoreBuffers的数据刷新到缓存行
2.使得其他CPU缓存了该字段的缓存行失效 也就是让存储在Invalidate Queues中的对该字段缓存行失效指令立即生效,当其他线程再去读取该字段的值时会先从内存中或者其他缓存了该字段的缓存行中重新读取从而获得最新的值
参考链接
https://zhuanlan.zhihu.com/p/651732241
https://blog.csdn.net/weixin_46410481/article/details/120395904
https://zhuanlan.zhihu.com/p/125549632?utm_source=ZHShareTargetIDMore&utm_medium=social&utm_oi=1224314960559403008