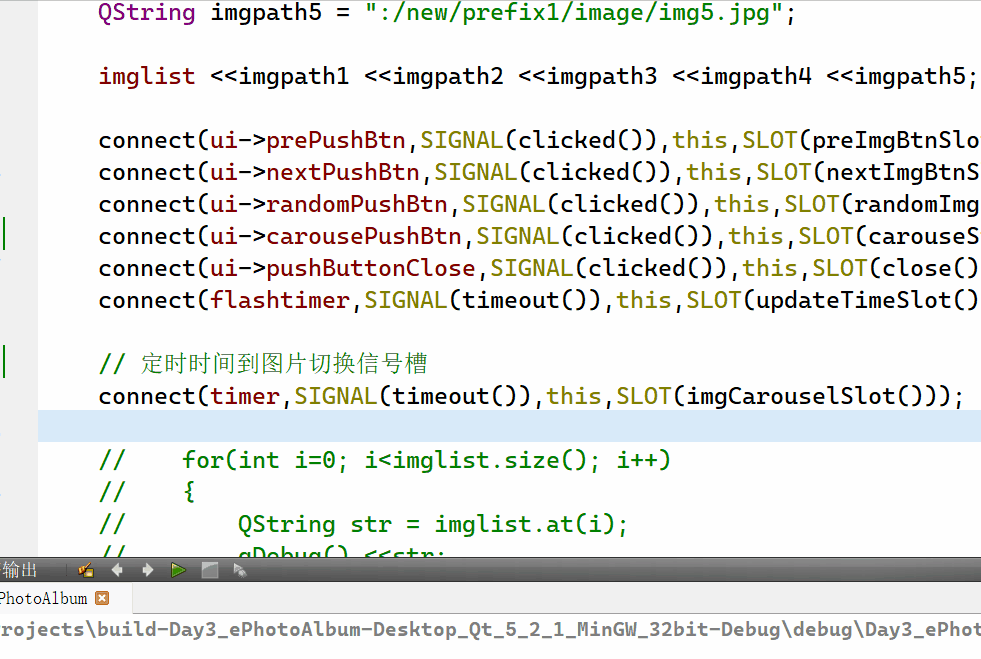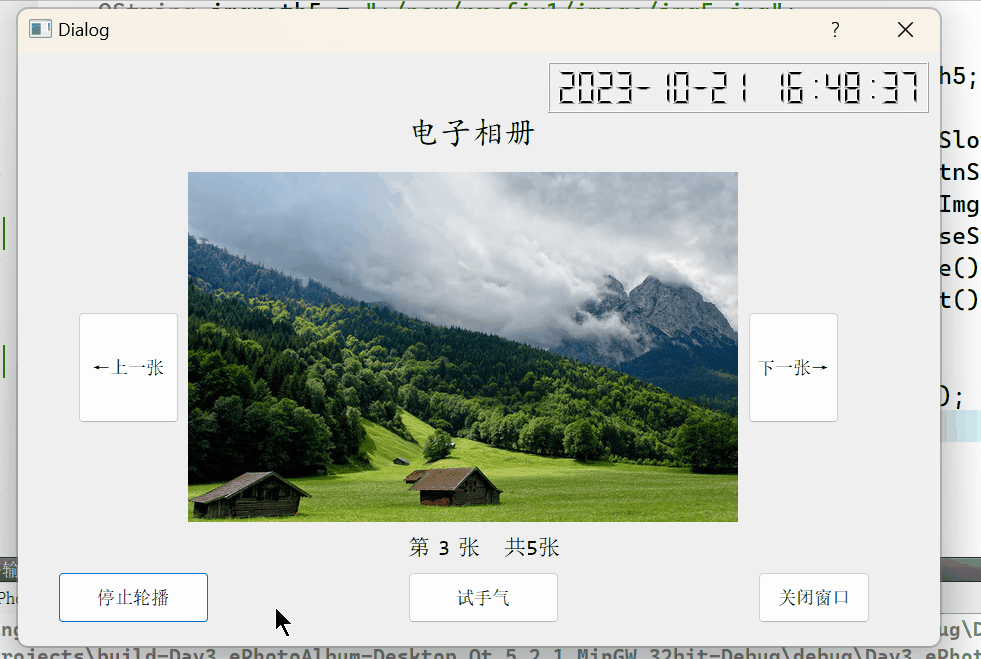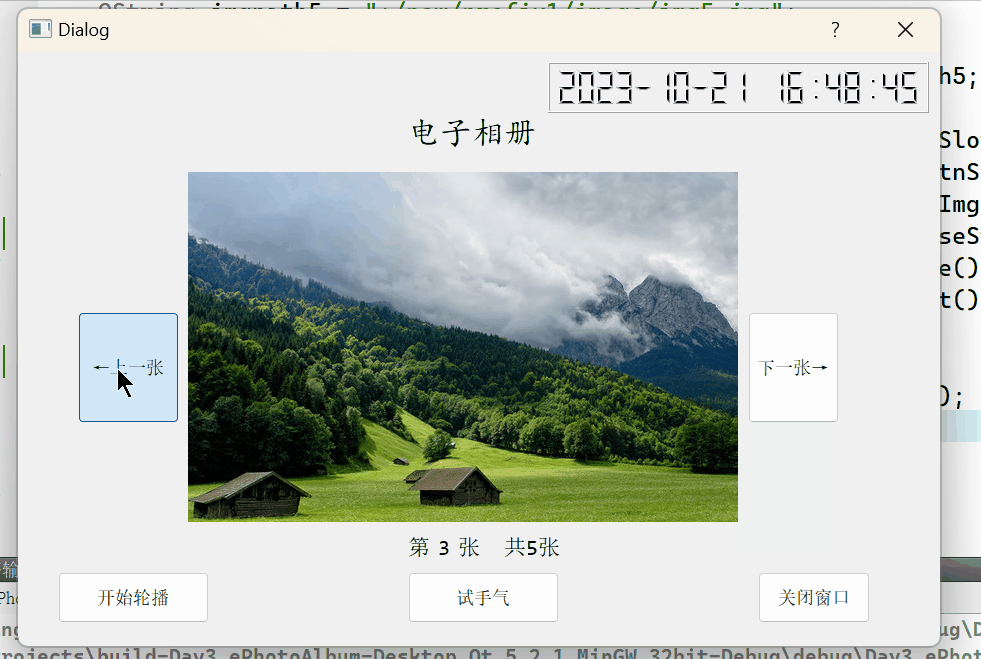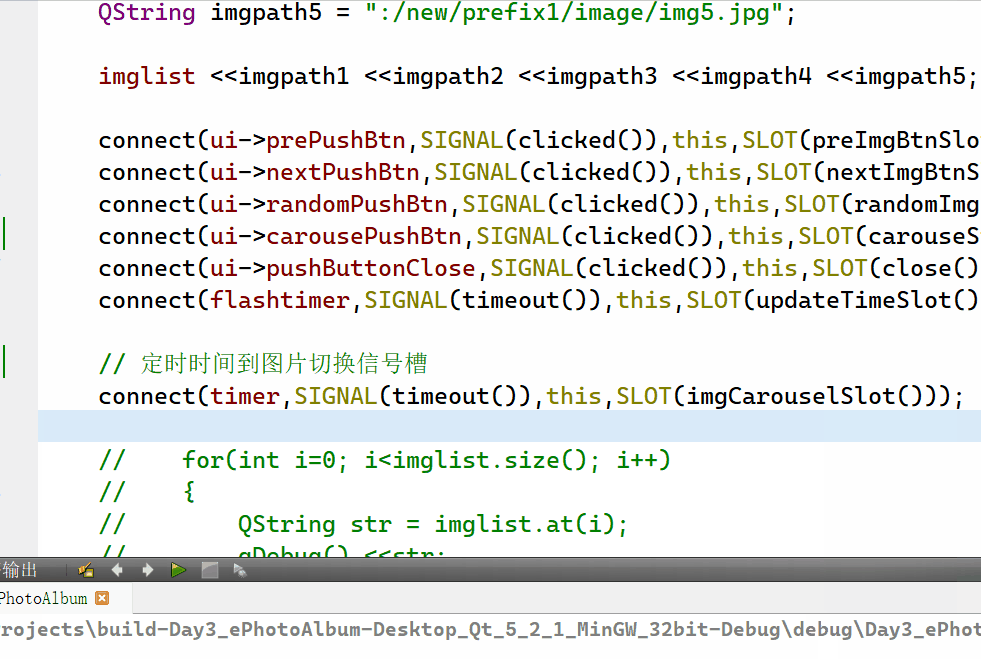
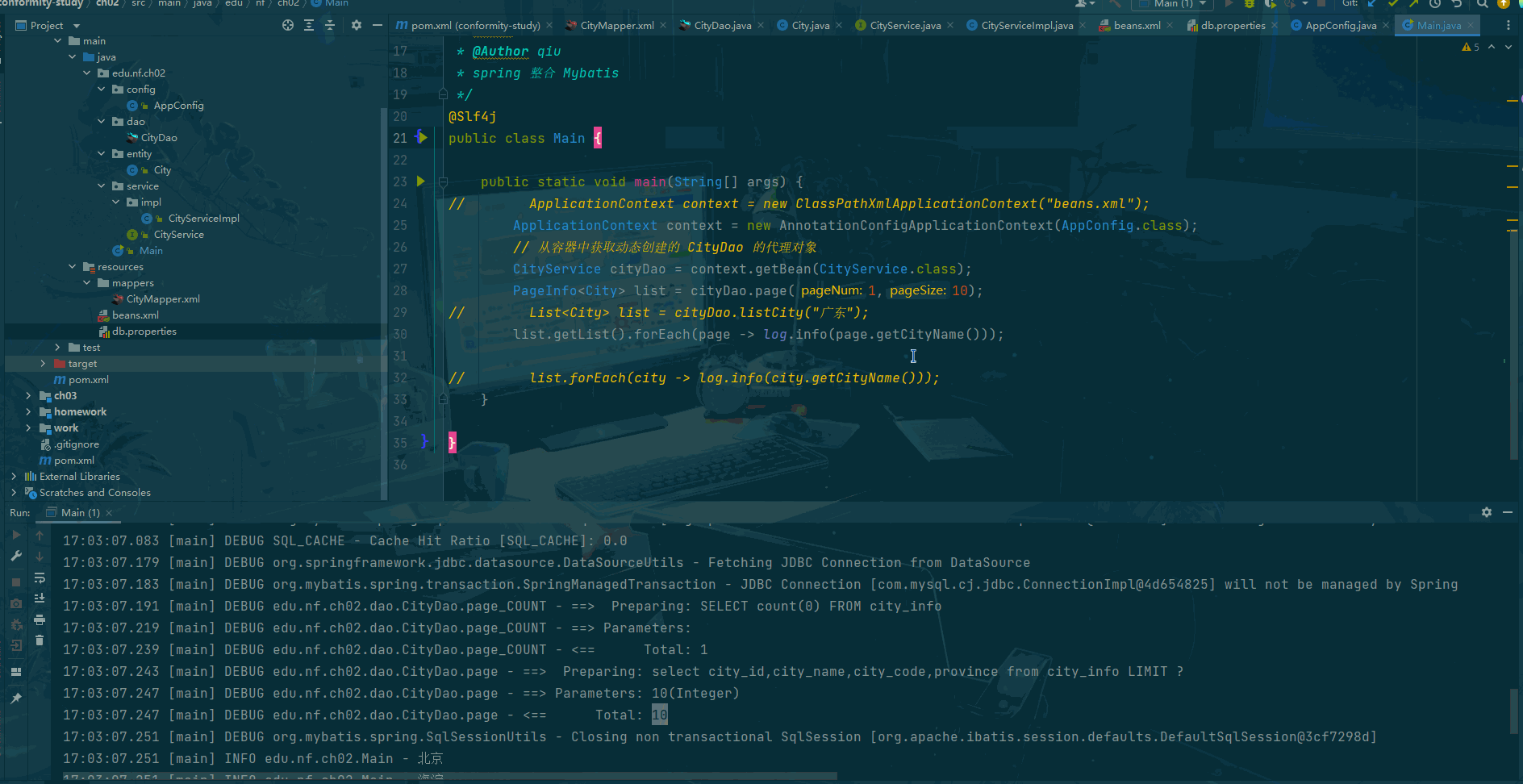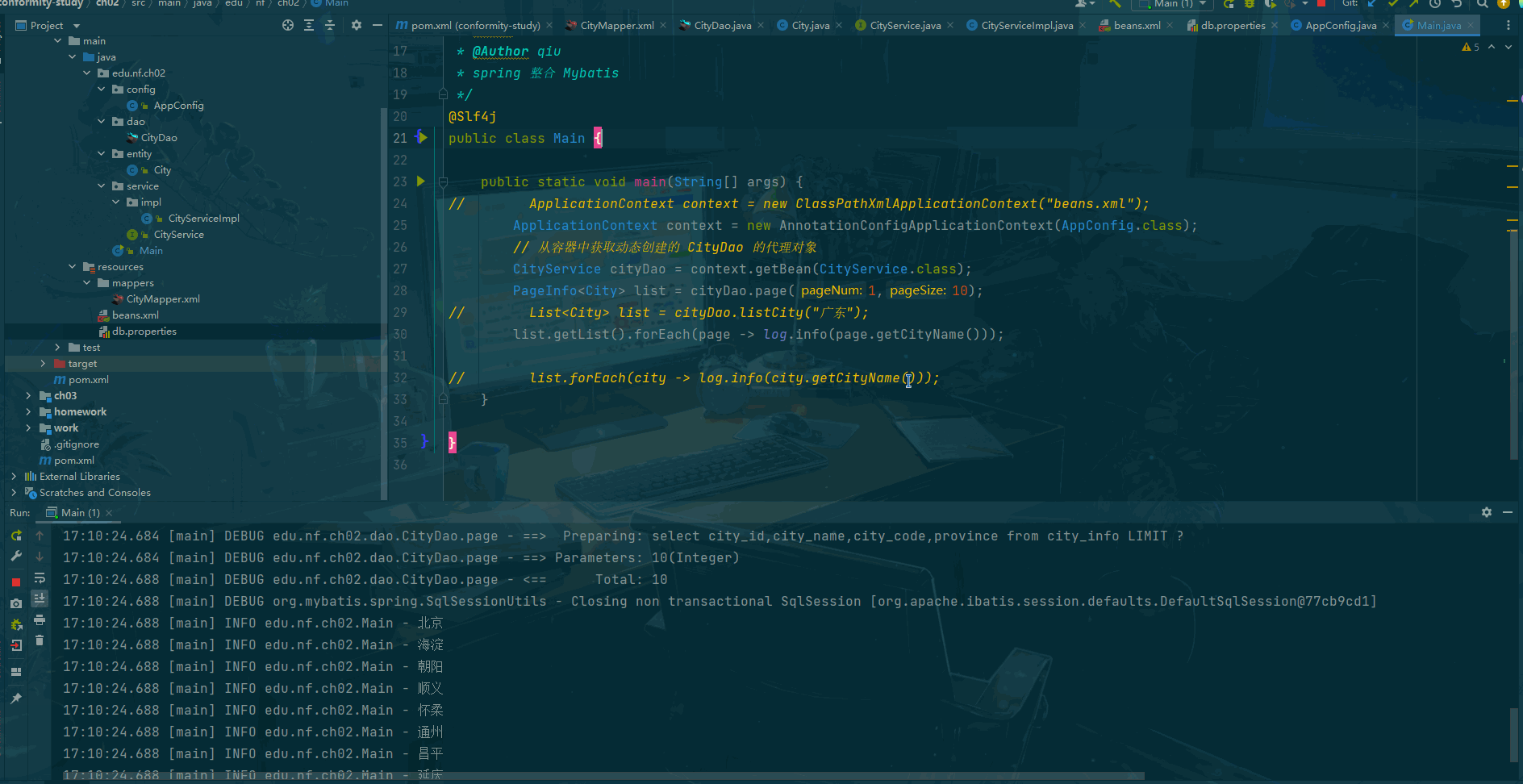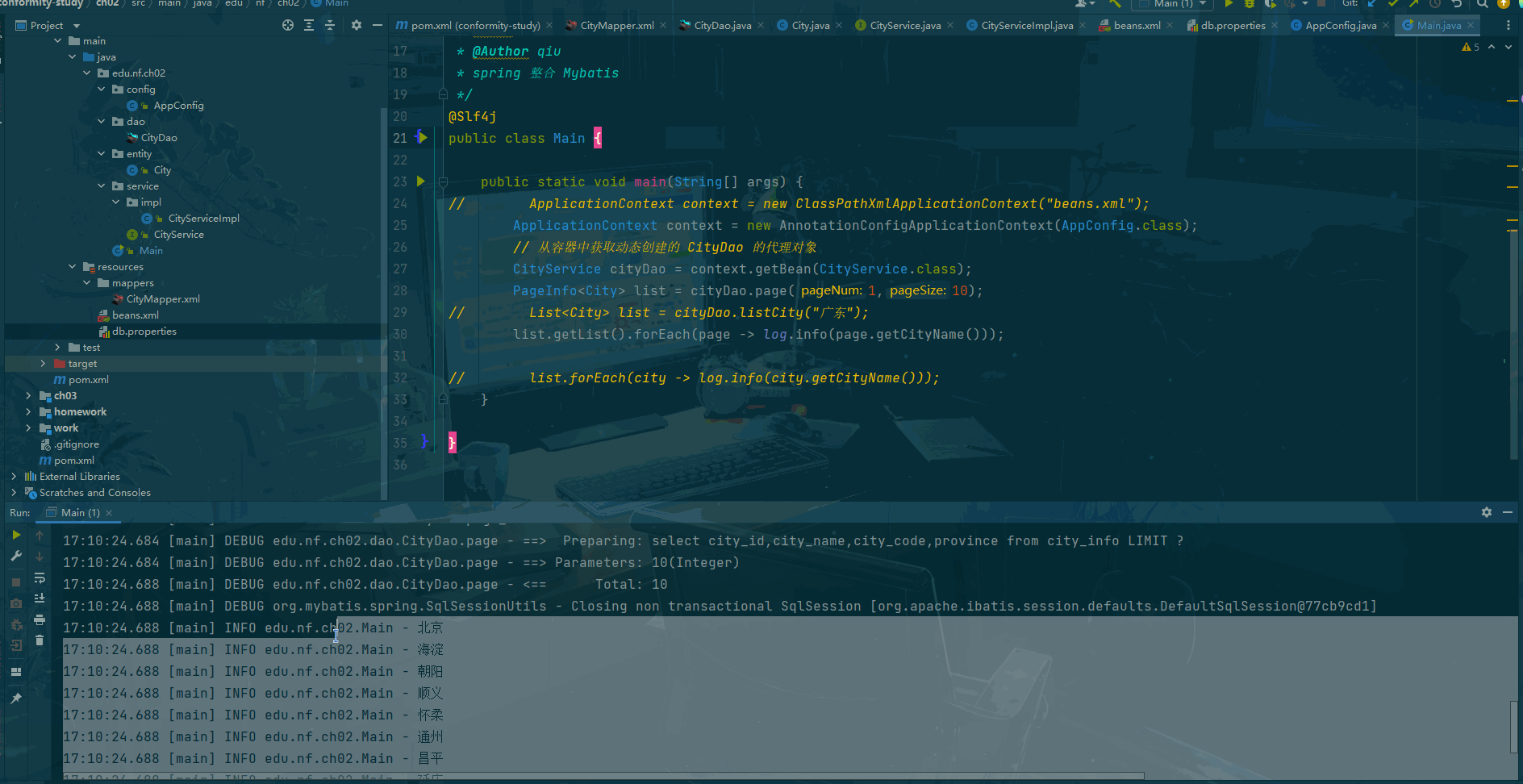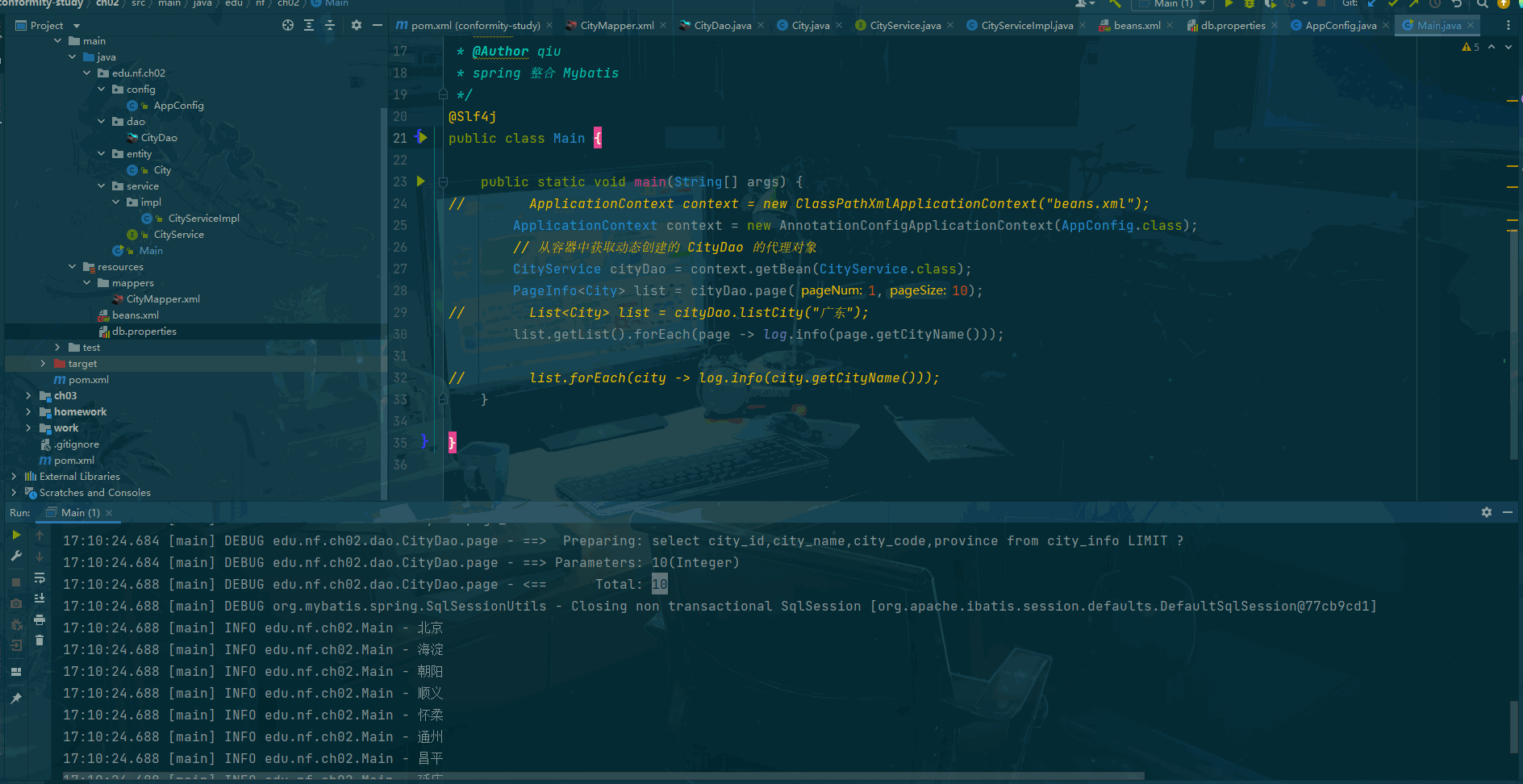
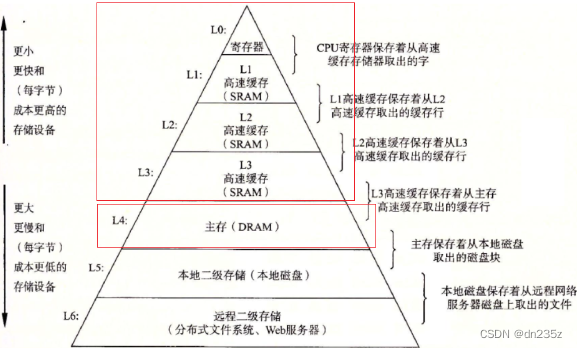
事件计时
CUDA事件是直接在GPU上实现的,因此它们不适用于对同时包含设备代码和主机代码的混合代码计时。
- cudaEventCreate 创建一个事件
- cudaEventRecord 记录一个事件
- cudaEventElapsedTime 计算两个事件之间经历的时间,第一个参数为某个浮点变量的地址,在这个参数中将包含两次事件之间经历的时间,单位是毫秒
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<math.h>
#include <malloc.h>
#include <opencv2/opencv.hpp>
#include <stdlib.h>
#define BLOCK_SIZE 1
//图像卷积 GPU
__global__ void sobel_gpu(unsigned char* in, unsigned char* out, const int Height, const int Width)
{
int x = blockDim.x * blockIdx.x + threadIdx.x;
int y = blockDim.y + blockIdx.y + threadIdx.y;
int index = y * Width + x;
int Gx = 0;
int Gy = 0;
unsigned char x0, x1, x2, x3, x4, x5, x6, x7, x8;
if (x>0 && x<(Width-1) && y>0 && y<(Height-1))
{
x0 = in[(y - 1)*Width + (x - 1)];
x1 = in[(y - 1)*Width + (x)];
x2 = in[(y - 1)*Width + (x + 1)];
x3 = in[(y)*Width + (x - 1)];
x5 = in[(y)*Width + (x + 1)];
x6 = in[(y + 1)*Width + (x - 1)];
x7 = in[(y + 1)*Width + (x)];
x8 = in[(y + 1)*Width + (x + 1)];
Gx = (x0 + 2 * x3 + x6) - (x2 + 2 * x5 + x8);
Gy = (x0 + 2 * x1 + x2) - (x6 + 2 * x7 + x8);
out[index] = (abs(Gx) + abs(Gy)) / 2;
}
}
int main()
{
cv::Mat src;
src = cv::imread("complete004.jpg");
cv::Mat grayImg,gaussImg;
cv::cvtColor(src, grayImg, cv::COLOR_BGR2GRAY);
cv::GaussianBlur(grayImg, gaussImg, cv::Size(3,3), 0, 0, cv::BORDER_DEFAULT);
int height = src.rows;
int width = src.cols;
//输出图像
cv::Mat dst_gpu(height, width, CV_8UC1, cv::Scalar(0));
//GPU存储空间
int memsize = height * width * sizeof(unsigned char);
//输入 输出
unsigned char* in_gpu;
unsigned char* out_gpu;
cudaMalloc((void**)&in_gpu, memsize);
cudaMalloc((void**)&out_gpu, memsize);
cudaEvent_t start, stop_gpu;
cudaEventCreate(&start);//创建事件
cudaEventCreate(&stop_gpu);//创建事件
cudaEventRecord(start);//记录事件
dim3 threadsPreBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 blocksPreGrid((width + threadsPreBlock.x - 1)/threadsPreBlock.x, (height + threadsPreBlock.y - 1)/threadsPreBlock.y);
cudaMemcpy(in_gpu, gaussImg.data, memsize, cudaMemcpyHostToDevice);
sobel_gpu <<<blocksPreGrid, threadsPreBlock>>> (in_gpu, out_gpu, height, width);
cudaEventRecord(stop_gpu);//记录事件
cudaError_t error_code = cudaGetLastError();
if (error_code != cudaSuccess)
{
printf("Error: %s\n", cudaGetErrorString(error_code));
printf("FILE: %s\n", __FILE__);
printf("LINE: %d\n", __LINE__);
printf("Error code: %d\n", error_code);
}
cudaMemcpy(dst_gpu.data, out_gpu, memsize, cudaMemcpyDeviceToHost);
float time_gpu;
cudaEventElapsedTime(&time_gpu, start, stop_gpu);
//事件计时
printf("GPU time: %.3f ms \n", time_gpu);
cudaEventDestroy(start);//销毁事件
cudaEventDestroy(stop_gpu);
cv::imwrite("dst_gpu_save.png", dst_gpu);
//cv::namedWindow("src", cv::WINDOW_NORMAL);
cv::imshow("src", src);
cv::imshow("dst_gpu", dst_gpu);
cv::waitKey();
cudaFree(in_gpu);
cudaFree(out_gpu);
return 0;
}