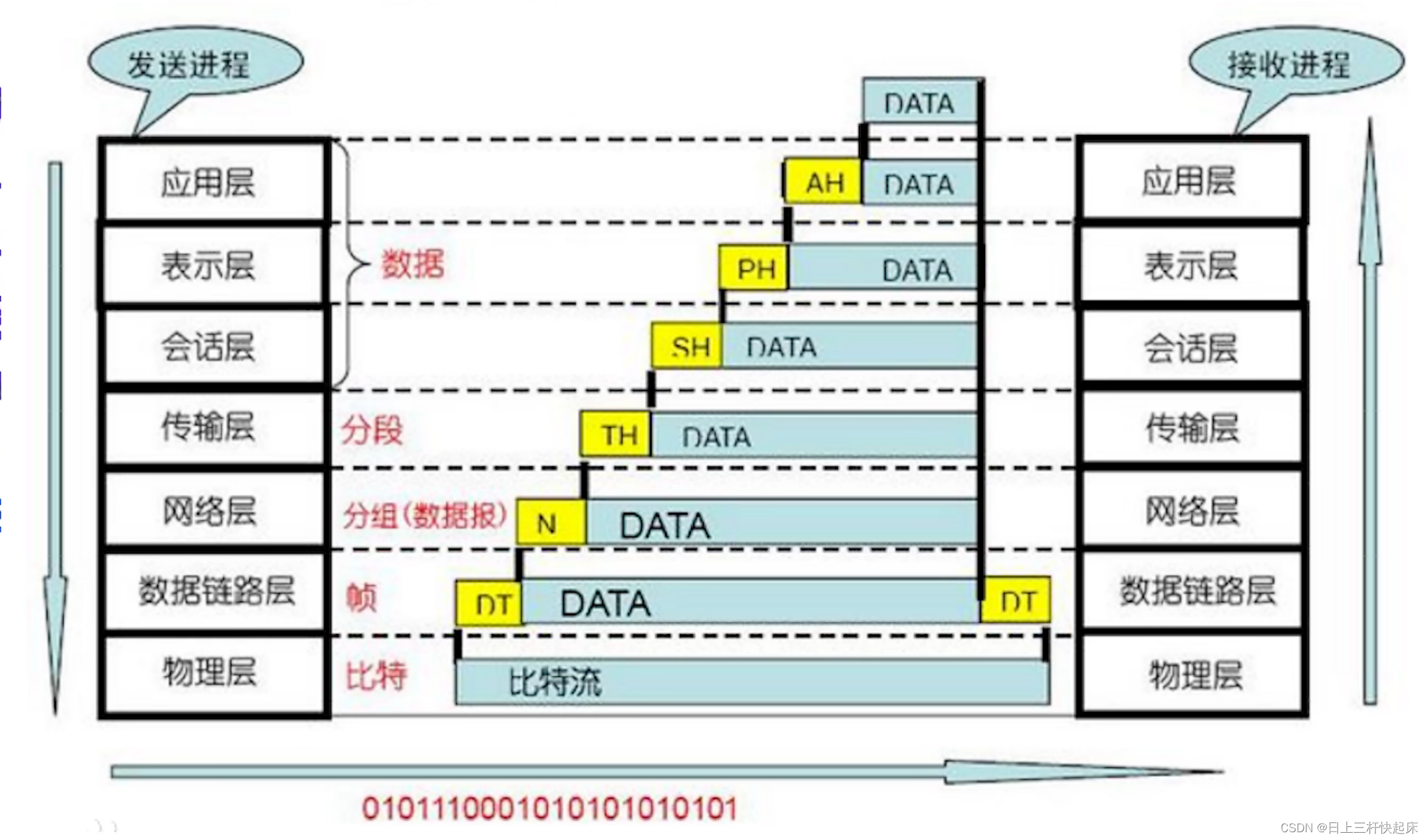
摘要
场景解析是无人驾驶领域的一个关键任务,但是传统的语义分割网络往往只关注于提取更深层次的图像语义信息而忽略了全局信息对图像分割任务的重要性。另外随着图像在深层次卷积网络中的传递,卷积核天然的滤波作用会使得图像的边缘趋于平滑而丢失细节特征。本文基于以上两点考虑设计了融合全局特征的自注意力模块和图像纹理增强模块,使得语义分割网络在在更好的关注全局信息的同时保留了大量的细节信息,使得分割网络的精度得到了明显的提升。
第一章 绪论
1.1 研究背景与意义
随着无人驾驶领域的迅猛发展,以及无人机和卫星的普及,图像的获取变得更加便捷。图像分割技术开始在各个领域大显身手。在无人驾驶领率,车辆需要对摄像头或激光传感器获取的街景图象进行分割处理,将分割结果传递给车辆作为车辆自主决策的重要依据。无人机和高空卫星获取的大量高分辨率图片经过语义分割后能够为自然资源信息的统计以及灾害的检测提供重要的依据。在日常生活中,一键换衣功能为我们网购衣物提供了重要的参考价值。
(1)自动驾驶领域
(2)精准农业
(3)自然灾害监控
(4)医疗领域
(5)网购衣物
1.2 语义分割的发展与现状
从FCN网络开始,语义分割开始向深层神经网络发展。人们希望通过搭建更深的神经网络以提取更加有效的语义信息。但是随着神经网络深度的增加,又出现了梯度消失和梯度爆炸等问题,这使得深层网络的分割结果还不及较浅层的神经网络,为了解决这一问题,不少学者尝试探索正则化的方法优化与激活函数的改进,这一时期出现了层归一化、批次归一化,ReLU、LeakyReLU、ELU等激活函数,但直到Resnet的出现引入了残差结构,这一问题才得以根本性的改善,深度网络也因此开始进入了大模型时代。这一时期学者们的主要研究是探索具有强特征提取能力的主干网络结构,因此涌现了大批优秀的骨干网络架构,例如:Xception、Vgg、GoogleNet等强有力的主干网络。当人们意识到语义分割中上下文信息的重要性后,后期的工作主要集中于如何更加有效的提取网络的上下文信息,在这期间涌现了许都奇思妙想。例如大家熟知的Unet和U2Net的跳跃连结结构,PSPnet的空间金字塔池化模块,DeepLabV3_plus的改进的带有空洞卷积的空间金字塔池化模块。人们尝试通过引入图像目标的多尺度信息来改善语义分割网络的分割结果,在这一段时间,语义分割结构取得了明显的提升。同时该时期也出现了许多种类的注意力模块来更好的提取图像的上下文信息。例如:EcnNet的Context Encoding Module、Danet中引入的Position Attention Module和Channel Attetion Module、APCNet的自适应上下文模块ACM和CCNet的交叉注意力模块,实验证明这也注意力模块的引入确实给语义分割网络带来了明显的性能提升。
随着Transformer在NLP领域的大放异彩,有学者尝试将Transformer引入图像处理领域,首先诞生的VisionTransformer就出现了一鸣惊人的效果,在这之后既有对纯Transfomer结构的探索如SegFormer、SwinTransformer也有将Transformer与传统CNN网络的结合诞生了如SETR、TransUNet等优秀的语义分割网络。但是Transformer结构虽然有很好的模型表达能力,但其对于输入N的平方复杂度却对实验的硬件设备提出了更大的挑战,而且Transformer优秀的特征表达能力需要依赖于庞大的数据集和更多的迭代次数,对于普通学者来说这些训练成本无疑是昂贵的。因此,许多学者的研究工作致力于对Transformer的注意力模块进行改进,提出了线性注意力结构。此外,SegNexT通过引入可变性卷积结构构建的超大语义分割网络架构,在较少的参数数量情况下也取得了不输于Transformer结构的语义分割效果,证明了多尺度信息对于语义分割网络的重要性。
1.3 注意力机制的发展与现状
(1) PSANet
(2)DANet
(3)OCNet
(4)CCNet
(5)SANet
(6)Vision Transformer
(7)Swin Transformer
(8)SegFomer
1.4 课题研究内容
(1)自注意力模块
(2)纹理增强模块
(3)Hambergure解码器模块
1.5 文章组织架构
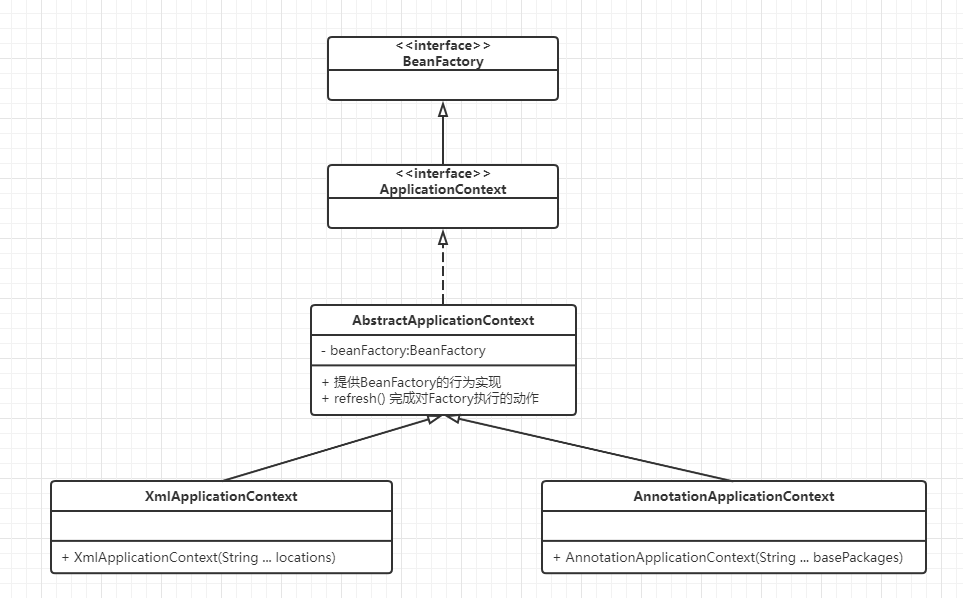
第二章 语义分割基本知识
2.1 语义分割目标
语义分割为给定的图像的每个像素分别进行类别预测,从而提供了包括对象类别、位置和形状信息的全场景描述。
2.2 语义分割评价标准
评价一个语义分割模型的性能大致可以从准确度、帧率和模型复杂度三个方面。准确度的衡量有平均像素准确率(Mean Pixel Accuracy,MPA)和平均交并比(Mean Intersection Union,MIOU)两个方面。MPA是所有目标中判断正确的数量占总数据量百分比的均值,MIOU是将所有图像的标签和网络预测区域的交集与并集之比求均值。相比于MPA,MIOU更具有捕获数据集细节的能力,是主流的准确度评价指标。
(1)准确度
MPA和MIOU的计算都是建立在混淆矩阵的基础上,因此了解混淆矩阵的相关知识是非常有必要的。混淆矩阵是统计分类模型的分类结果,即统计归对类,归错类的样本个数,然后将结果放在一个表里展示出来,这个表就是混淆矩阵。这里以二分类混淆矩阵为例进行介绍,多分类混淆矩阵是以二分类混淆矩阵为基础作为延伸的。
对于二分类问题,将类别1称为正例(Positive),类别2称为反例(Negative),分类器预测正确记作真(True),预测错误记作假(False),由这4个基础元素相互组合,构成混淆矩阵的4个基础元素分别为TP、FP、FN、TN,下面分别解释这4个元素的具体含义:
TP(True Positive):真正例,模型预测为正例,实际为正例。
FP(False Positive):假正例,模型预测为正例,实际是反例。
TN(True Negative):真反例,模型预测为反例,实际为反例。
FN(False Negative):假反例,模型预测为反例,实际为正例。
二分类混淆矩阵示意图如下:
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
混淆矩阵对角元素全是预测正确的,数字值表示各类别预测正确的个数;行的数字求和表示某类别真实值的个数,列的数字求和表示模型预测为该类别的数目。
语义分割的像素准确率PA=(TP+TN)/(TP+TN+FP+FN)
CPA:类别像素准确率,对应精确率。在类别i的预测中,真实属于i类的像素准确率,换言之:模型对类别i的预测值有很多,其中有对有错,预测对的值占预测总值的比例。混淆矩阵计算。
P1 = TP / (TP+FP)
P32 = TN / (TN + FN)
MPA分别计算每个类别被正确分类像素的比例,即CPA,然后累加求平均。
每个类别像素的准确率为Pi,MPA=sum(Pi)/类别数。IOU = TP / (TP + FP + FN)
以二分类的的MIOU为例,MIOU = (IOU正例P+IOU反例n) / 2 = [TP / (TP + FP + FN) + TN / (TN + FN + FP)] / 2
交并比IOU是模型对某一类别预测结果和真实值的交集与并集的比值

在分割任务中,假设类别总数为k,加上背景就是k+1,Pmm是将原数据中目标m的像素判断成目标m的数量,Pmn是将原数据中目标m的像素判断成目标n的数量。
则
MIOU就是对所有类的IOU求平均值,计算公式如下所示
(2)帧率
帧率(Frame Per Second,FPS)指的是语义分割模型在以秒为单位的时间内完成的预测图片的数量,用来衡量分割算法处理数据的耗时程度。其值越大表示算法处理一张图片的时间越短,速度越快。
(3)模型复杂度
语义分割网络模型复杂度的衡量指标主要有以下几个:
1. 参数数量(number of parameters):指模型中需要学习的参数数量。通常情况下,参数数量越多,模型复杂度越高。
2. 浮点操作数(number of floating-point operations):指模型计算中的乘法和加法运算数量。通常情况下,浮点操作数越多,模型复杂度越高。
3. FLOPs(floating-point operations per second):指模型在单位时间内可以进行的浮点运算次数。它综合考虑了模型的参数数量和浮点操作数。
4. 模型输出图像的分辨率(resolution of output image):指模型输出的分割图像的像素数量。通常情况下,输出图像的分辨率越高,模型复杂度越高。
这些指标不是孤立的,通常需要综合考虑。比如在计算 FLOPs 时,需要同时考虑模型的参数数量和浮点操作数。
FPS
2.3 激活函数简介
2.4 损失函数
(1)交叉熵损失函数(CE_Loss : Cross Entropy Loss Function)
交叉熵损失(Cross-Entropy Loss,CE Loss)能够衡量同一个随机变量中的两个不同概率分布的差异程度,当两个概率分布越接近时,交叉熵损失越小,表示模型预测结果越准确
(2)Focal Loss
虽然CE Loss能够衡量同一个随机变量中的两个不同概率分布的差异程度,但无法解决一下两个问题:
- 正负样本分布不平衡的问题(如centernet的分类分支,它只将目标的中心点作为正样本,而把特征图上的其它像素作为负样本,可想而知正负样本的数量差距之大);
- 无法区分难易样本的问题(易分类的样本的分类错误率的损失占了整体损失的绝大部分,并主导梯度)
为了解决以上问题,Focal Loss在CE Loss的基础上改进,引入了:
- 正负样本数量调节因子以解决正负样本数量不平衡的问题;
- 难易样本分类调节因子以聚焦难分类的样本。
(3)GHMC Loss
Focal Loss在CE Loss的基础上改进后,解决了正负样本不平衡以及无法区分难易样本的问题,但也会过分关注难分类的样本(离群点),导致模型学歪。
为了解决这个问题,GHMC(Gradient Harmonizing mechanism-C)定义了梯度模长,该梯度模长正比于分类的难易程度,目的是让模型不要关注那些容易学的样本,也不要关注那些特别难分的样本。
(4)Dice Loss
Dice Loss来自于dice coefficient,是一种用于评估两个样本的相似度的度量函数,取值范围在0到1之间,取值越大表示越相似。Dice Loss是一种区域相关的的Loss。意味着某像素的loss以及梯度值不仅和该点的label以及预测值相关,和其它的label以及预测值也相关。Dice Loss对正负样本严重不平衡的场景有着不错的性能,训练过程中更侧重于对前景区域的挖掘。但训练Loss容易不稳定,尤其是小目标的情况下。另外极端情况会导致梯度饱和的现象,因此有一些改进操作主要是结合CE_Loss等的改进,比如Dice + CE Loss , Dice + Focal loss等。
2.5 优化算法介绍
(1)优化器
梯度下降的基本思想是先设定一个参数η,参数沿着梯度的反方向进行更新。假设需要更新的参数为ω,梯度为ɡ,那么权重的更新策略可以表示为:
梯度下降有三种不同的形式:
- BGD(Batch Gradient Descent):批量梯度下降,每次参数更新使用所有样本
- SGD(Stochastic Gradient Descent):随机梯度下降,每次参数更新仅使用一个样本。
- MBGD(Mini-Batch Gradient Descent):小批量梯度下降,每次参数更新仅使用小部分梯度样本(mini_batch)
这三个优化算法的训练方法是相同的,区别是训练时使用的训练数据量。
Step1:
Step2:求梯度的平均值
Step3:更新权重:
梯度下降算法虽然算法简洁,但对超参数学习率比较敏感,学历率过小会导致模型收敛缓慢,学习率过大这可能导致模型越过极值点。在较为平坦的区域,优化算法会误判,在还未到达极值点时就提前结束迭代,陷入局部极小值。
(2)动量(Momentum)
思想:让参数的更新具有惯性,每一步更新都是由前面梯度的累积υ和当前梯度ɡ组合而成。
公式:
累计梯度更新:
其中α为动量参数,υ为当前梯度,η为学习率。
梯度更新:
通过添加动量参数能够帮助参数在正确的方向上加速前进,也可以帮助模型跳出局部最优解。
3.Adagrad
Adagrad优化算法被称为自适应学习率优化算法。之前我们讲的梯度下降方法是对所有的参数使用相同的,固定的学习率进行优化的,但是不同参数的梯度差异可能很大,使用相同的学习率效果可能不会很好。
Adagrad思想时对于不同的参数设置不同的学习率。具体做法是对于每个参数初始化一个累计平方梯度r=0,然后每次将该参数的梯度平方和累加到这个变量r上:然后,再更新这个参数的时候学习率就变成了:
然后,在更新这个参数的时候,学习率就变成了
权重更新为:
其中,ɡ为梯度,γ为累计平方梯度(初始值为0);η为学习率,σ为小参数,避免分母为0,一般取值为10-10
这样不同的参数由于梯度不同对应的学习率大小也会不同,这也就实现了自适应的学习率。
Adagrad的核心思想就是对于根据参数的梯度自适应的调整学习率大小以使学习率大的参数的学习率减小达到防止震荡的目的,同时对于学习率小的参数也能通过增大学习率使参数更新的数度加快,能够加快收敛速度。
Adam
在Grandient Descent的基础上,做了如下几个方面的改进:
- 梯度方面增加了momentum,使用累计梯度:
- 同RMSProp优化算法一样,对学习率进行优化,使用累计平方梯度:
- 偏差纠正:
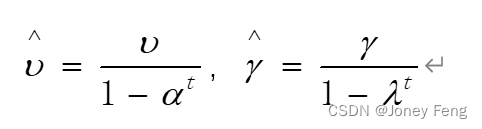
- 权重更新为:
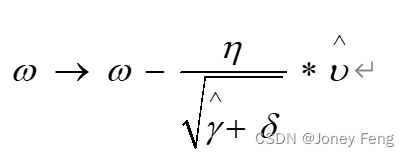
2.6 数据集介绍
(1)PASCAL VOC2012 + SBD
(2)CityScapes