原文链接:https://arxiv.org/pdf/2308.09616.pdf
1. 引言
目前的环视图图像3D目标检测方法分为基于密集BEV的方法和基于稀疏查询的方法。前者需要较高的计算量,难以扩展到长距离检测。后者全局固定的查询不能适应动态场景,通常会丢失远距离目标。本文引入3D自适应查询以增强灵活性。
基于稀疏查询的长距离检测主要的挑战是召回率低。由于2D检测的召回率高,可以使用高质量的2D检测先验来改进3D提案,从而实现精确定位和全面覆盖。但直接使用来自2D提案的3D查询有两个问题:(1)深度不确定;(2)当距离增加时3D空间中的偏差增大。这会影响训练稳定性,需要去噪方法来优化。此外,训练会倾向对近距离较为密集的物体进行过拟合,而忽略稀疏分布的远距离物体。
本文使用2D提案和相应的深度,通过空间变换得到3D提案,然后用投影位置嵌入和上下文语义来组成3D自适应查询,在解码器中细化。透视图感知的聚合会用在不同尺度和视图的图像上(对远距离物体需要关注高分辨率特征,而近距离物体反之,才能获得高层特征)。此外,还提出距离调制的3D去噪技术(根据GT构建噪声查询,解码器学习从噪声提案中恢复正提案并拒绝负提案),来缓解查询误差传播和收敛慢的问题。同时,查询去噪能减轻距离分布不平衡的问题。
3. 方法
3.1 概述
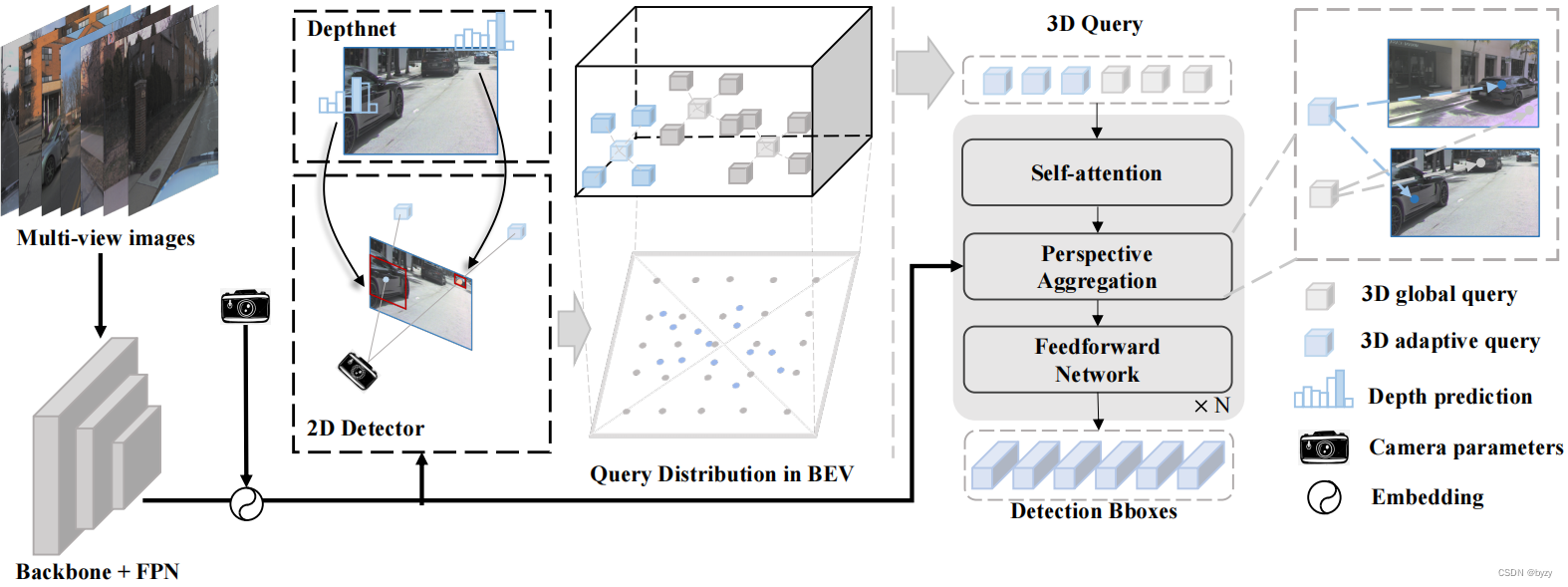
给定环视图像
I
=
{
I
1
,
⋯
.
I
n
}
I=\{I_1,\cdots.I_n\}
I={I1,⋯.In},使用主干和FPN提取多尺度图像特征
F
=
{
F
1
,
⋯
,
F
n
}
F=\{F_1,\cdots,F_n\}
F={F1,⋯,Fn}。使用2D检测器和深度网络获取2D提案和深度,然后筛选出其中可靠性高的并转换到3D空间,得到3D物体查询。
在3D检测器中,将3D自适应查询和3D全局查询输入到Transformer解码层中,进行查询间的自注意力和透视感知的查询-特征聚合。
3.2 自适应查询生成
给定图像特征,输入到2D检测器和轻量级深度估计网络预测2D边界框和离散深度分布,并筛选出分数大于阈值 τ \tau τ的边界框。然后根据深度和相机参数,将边界框的中心投影到3D空间,得到坐标 c 3 d c_{3d} c3d。
然后,按下式编码为3D自适应查询:
Q
p
o
s
=
P
o
s
E
m
b
e
d
(
c
3
d
)
Q_{pos}=PosEmbed(c_{3d})
Qpos=PosEmbed(c3d)
Q
s
e
m
=
S
e
m
E
m
b
e
d
(
z
2
d
,
s
2
d
)
Q_{sem}=SemEmbed(z_{2d},s_{2d})
Qsem=SemEmbed(z2d,s2d)
Q
=
Q
p
o
s
+
Q
s
e
m
Q=Q_{pos}+Q_{sem}
Q=Qpos+Qsem
其中
z
2
d
z_{2d}
z2d为边界框2D中心处的图像特征,
s
2
d
s_{2d}
s2d为边界框的置信度分数。位置编码为正弦变换+MLP,语义编码为MLP。
最后,将3D自适应查询与初始化的全局查询一起输入到Transformer解码层。
3.3 透视感知的聚合
遥远的小物体需要高分辨率特征以精确定位,而近处的大物体需要高级特征。本文提出透视图感知的聚合,从而在不同的尺度和视图上进行高效的特征交互。
本文首先将图像特征 F F F与相机内外参 I , K I,K I,K组合,并使用squeeze-and-excitation块丰富特征。增强的特征 F ′ F' F′使用3D可变形卷积。对每个查询参考点预测 M M M个偏移量,并投影到不同视图和尺度的2D特征图上。
最后根据2D参考点从 F ′ F' F′中采样图像特征,并考虑相对重要性聚合到3D查询中。
3.4 距离调制的3D去噪
具体的方案类似于DN-DETR。
与2D查询不同,不同距离处的3D查询,回归难度往往不同。这一难度差异来自查询密度(近距离物体比远距离物体更容易匹配)与误差传播(2D提案的误差会传播到3D,且随距离的增加而增加)。因此,GT框附近的查询可视为噪声候选对象,而远离GT框的查询视为负样本。通过距离调制的3D去噪,模型会召回潜在的正样本,而拒绝负样本。
本文通过同时添加正负样本,基于GT物体创建噪声查询。为了促进长距离感知学习,根据物体的位置和尺寸添加随机噪声。噪声查询的位置定义如下:
P
~
=
P
G
T
+
α
f
p
(
S
G
T
)
+
(
1
−
α
)
f
n
(
P
G
T
)
\tilde{P}=P_{GT}+\alpha f_p(S_{GT})+(1-\alpha)f_n(P_{GT})
P~=PGT+αfp(SGT)+(1−α)fn(PGT)
其中
α
∈
{
0
,
1
}
\alpha\in\{0,1\}
α∈{0,1}对应正查询和负查询的生成,
P
G
T
P_{GT}
PGT与
S
G
T
S_{GT}
SGT为GT框的位置和尺寸,
f
p
f_p
fp与
f
n
f_n
fn为正负样本编码位置感知的噪声。
对正样本, f p ( S G T ) f_p(S_{GT}) fp(SGT)为3D尺寸的线性函数(带随机变量),这个GT框内的约束用于保证与周围相邻的边界框区分开。对负样本,偏移量与位置相关,有不同的实施方案。此外,对每个GT框会生成多组样本以增强查询多样性,每一组包含一个正样本和 K K K个负样本。
4. 实验
4.3 主要结果
Argoverse 2数据集:本文的方法能超过基于稀疏查询的方法。基于BEV的方法性能较差,这可能是由于深度估计的难度太大。部分模型不能收敛,可能也是缺乏精确的深度估计。总的来说,长距离检测的收敛问题更加严重,本文的3D去噪能起关键作用。
此外,本文的方法能超过激光雷达早期方法CenterPoint等。激光雷达方法的定位误差较小,但环视图方法的朝向估计更准确。
4.4 消融研究 & 分析
自适应查询:在StreamPETR的基础上添加自适应查询,能带来性能提升。可视化表明,从自适应查询得到的预测覆盖了更大的范围。
透视感知的聚合:进一步增加透视感知的聚合,能提高性能。
距离调制的3D去噪:通过惩罚负样本,减少了错误提案的出现;通过考虑物体距离,提高了定位精度。实验表明 f n ( ⋅ ) = log ( ⋅ ) f_n(\cdot)=\log(\cdot) fn(⋅)=log(⋅)时能达到最优效果。
全局查询的作用:全局查询与自适应查询互补,当缺少全局查询时,StreamPETR收敛困难。全局查询增多,可以提高性能。
6. 补充材料
基于BEV的方法SOLO-Fusion在即使有NMS的情况下仍然产生了大量的冗余预测,原因可能是检测头有限的感受野难以处理大的检测范围。
自适应查询的统计数据:使用与自适应查询的平均数量相同的额外全局查询替换自适应查询,会导致性能下降。
Far3D的更多细节:(1)训练的初期,使用真实深度生成3D自适应查询,训练稳定后改用预测查询。(2)本文使用多尺度特征图与查询交互。与手工根据距离选择合适尺度的特征图相比,用网络估计的方法效果相近。