简介
核密度估计图(Kernel Density Estimation,KDE)是一种用于估计数据分布的非参数方法,通常用于可视化和理解数据的分布情况。它通过平滑地估计数据的概率密度函数(PDF)来显示数据的分布特征,尤其在连续变量上非常有用。
KDE图通常表现为一条平滑的曲线,描述了数据在特定值附近的密度。这条曲线称为核密度估计。核密度估计是通过将每个数据点视为一个小的概率分布(通常是高斯分布或其他核函数)并将它们叠加而得到的。这样,核密度估计提供了一个对数据分布的连续估计,而不仅仅是一个直方图或散点图。
特点
核密度估计图的主要特点包括:
-
平滑性: KDE图是平滑的,不受特定的数据点的影响。这使得它可以更好地捕捉数据的分布特征。
-
面积为1: KDE图的总面积在整个范围内等于1,因为它是概率密度函数的估计。
-
峰值和谷值: KDE图上的峰值表示数据集中的高密度区域,而谷值表示稀疏区域。
-
帮助比较: 使用KDE图,你可以比较不同数据集的分布,或者比较数据在不同条件下的分布。这对于发现数据之间的差异和相似性非常有用。
KDE图通常用于探索数据的分布,分析数据的形状和特性,以及为其他分析和建模任务提供数据的可视化表示。你可以使用数据可视化工具(如Seaborn或Matplotlib)来创建KDE图以更好地理解数据。
绘制
可以使用Python中的Seaborn库的seaborn.kdeplot()函数来绘制核密度估计图(Kernel Density Estimation,KDE)。核密度估计图是一种用于估计数据分布的非参数方法,通常用于可视化数据的连续分布。以下是绘制核密度估计图的示例代码:
import matplotlib.pyplot as plt
import seaborn as sns
# 防止中文乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import pandas as pd
df = pd.read_csv('data/data.csv').dropna()
# 分离正负样本
positive_samples = df[df['label'] == 0]
negative_samples = df[df['label'] == 1]
# 创建一个4x4的子图布局,每行4个子图
fig, axes = plt.subplots(4, 4, figsize=(32, 32), dpi=100)
fig.subplots_adjust(hspace=0.5)
# 循环遍历每个特征列,绘制核密度估计图
for i, feature in enumerate(df.columns[:-1]): # 不包括标签列
row, col = i // 4, i % 4 # 确定子图的位置
ax = axes[row, col]
# 绘制正负样本的核密度估计图
sns.kdeplot(positive_samples[feature], label='标签0', shade=True, ax=ax)
sns.kdeplot(negative_samples[feature], label='标签1', shade=True, ax=ax)
ax.set_title(feature)
ax.set_xlabel('Value')
ax.set_ylabel('Density')
ax.legend()
# 如果名称太长,可以旋转x轴标签,以免重叠
for ax in axes.flat:
ax.tick_params(axis='x', rotation=45)
# 显示图形
plt.show()
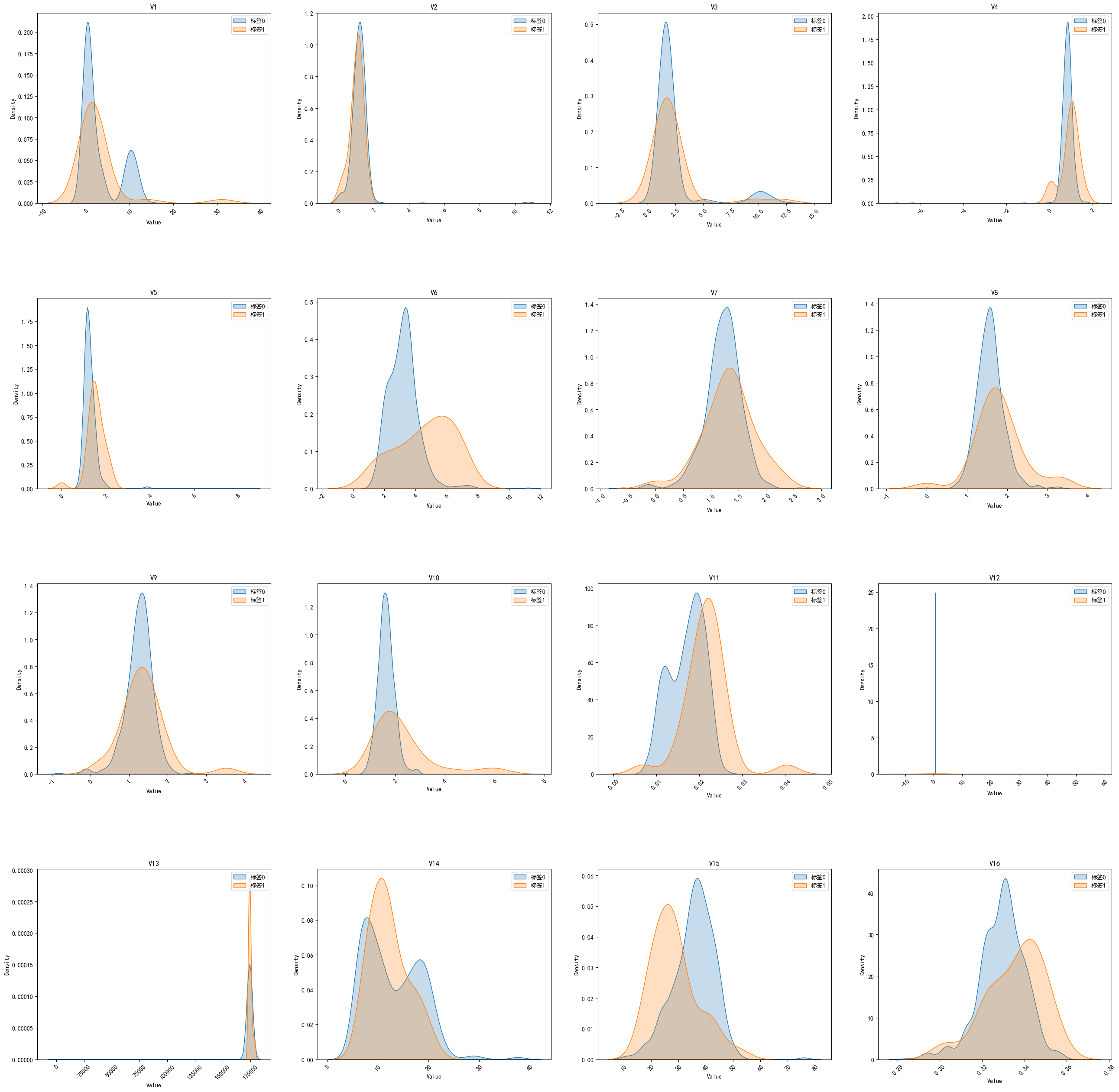
分析
以下是一些可以从核密度估计图中分析的信息:
-
数据分布比较: 通过观察核密度估计图,可以了解每个特征在正样本和负样本中的数据分布情况。这有助于识别数据中是否存在重叠,以及正负样本之间的相似性或差异。
-
峰值和谷值: 核密度估计图上的峰值表示数据中的密集区域,而谷值表示数据中的稀疏区域。可以观察正负样本的峰值和谷值,以确定它们在特征空间中的分布。
-
交叉点: 在核密度估计图中,正负样本的核密度曲线交叉的地方可能是有用的特征。如果两个曲线在某个特征值上交叉,这意味着这个特征可能不太适合区分正负样本。
-
重叠区域: 如果核密度估计图显示正负样本的核密度曲线在某些特征值上有重叠,那么这些特征值可能不太能区分正负样本。
-
明显分离的峰值: 如果核密度估计图显示在某些特征值上正负样本的核密度曲线有明显的分离峰值,那么这些特征值可能对区分正负样本有很好的区分能力。
-
特征之间的比较: 如果绘制了多个特征的核密度估计图,可以比较它们来确定哪些特征对正负样本的区分最为有效。通常情况下,具有更大的分离性和较小的重叠的特征更适合用来区分正负样本。
总之,核密度估计图可以帮助你直观地了解数据的分布情况,以及哪些特征对于区分正负样本是有帮助的。在正负样本不平衡的情况下,分析核密度估计图有助于确定哪些特征可能是有助于构建分类模型的重要特征。
另外,如果使用的是训练集和测试集,对比训练集和验证集的核密度估计图在特征筛选中可以发挥关键作用。这种对比有助于评估特征对模型的性能和泛化能力的影响。以下是一些使用对比核密度估计图来筛选特征的方法以及其用途:
-
检测特征的分布差异: 通过绘制训练集和验证集的核密度估计图,可以比较它们的形状和分布。如果特征在训练集和验证集之间的分布差异很大,这可能表明特征在模型的泛化性能上存在问题。较大的差异可能意味着模型在验证集上的性能会下降。
-
确定稳定性: 稳定性是指特征在不同数据集上的表现是否一致。如果特征在训练集和验证集上的核密度估计图非常相似,那么这些特征可能是稳定的,有助于模型的泛化。
-
特征选择: 通过对比核密度估计图,可以识别那些在验证集上表现稳定且分布差异较小的特征。这些特征可能是有用的,可以用来构建稳健的模型。相反,那些在验证集上表现差异大的特征可能需要谨慎考虑是否保留。
-
减少过拟合风险: 如果特征在训练集上有很好的性能,但在验证集上表现较差,可能表示过拟合。对比核密度估计图有助于确定是哪些特征引起了过拟合问题,从而进行特征筛选或正则化以减少过拟合的风险。