概述
实时/离线
- 实时:Spark是每个3秒或者5秒更新一下处理后的数据,这个是按照时间切分的伪实时。真正的实时是根据事件触发的数据计算,处理精度达到ms级别。
- 离线:数据是落盘后再处理,一般处理的数据是昨天的数据,处理精度是天。
SparkStreaming简介
- 支持的输入源:
Kafka, Flume, HDFS等 - 数据输入后,可以用RDD处理数据
- 结果可以保存在很多地方,比如HDFS,数据库等
SparkStreaming架构
DStream
SparkCore的基本单位RDD
SparkSQL的基本单位是DataFreme, DataSet
Spark Streaming的基本单位是Dstream
每个时间区间内收到的RDD组成的序列就是DStream.因此每个时间段的数据之间是独立的,如果需要汇总,需要指定相应的时间间隔。
架构图
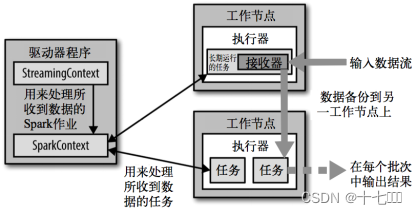
由于接收方和计算方是两个节点,如果接收方和计算方的速度不一致,会存在数据挤压或者计算方空闲等待数据的问题。
DirectAPI : 为了解决该问题,后续新版本增加了Direct, 通过Executor计算方来控制数据的消费速度。
Hello World案例
- 添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.3.1</version>
</dependency>
</dependencies>
- 编写代码,入口为javaStreamingContext, 必须设置时间间隔。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import java.util.ArrayList;
import java.util.HashMap;
public class Test01_HelloWorld {
public static void main(String[] args) throws InterruptedException {
// 创建流环境
JavaStreamingContext javaStreamingContext = new JavaStreamingContext("local[*]", "HelloWorld", Duration.apply(3000));
// 创建配置参数
HashMap<String, Object> map = new HashMap<>();
map.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092,hadoop104:9092");
map.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
map.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
map.put(ConsumerConfig.GROUP_ID_CONFIG,"atguigu");
map.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
// 需要消费的主题
ArrayList<String> strings = new ArrayList<>();
strings.add("topic_db");
JavaInputDStream<ConsumerRecord<String, String>> directStream = KafkaUtils.createDirectStream(javaStreamingContext, LocationStrategies.PreferBrokers(), ConsumerStrategies.<String, String>Subscribe(strings,map));
JavaDStream<String> flatMap = directStream.flatMap(new FlatMapFunction<ConsumerRecord<String, String>, String>() {
@Override
public Iterator<String> call(ConsumerRecord<String, String> consumerRecord) throws Exception {
String[] words = consumerRecord.value().split(" ");
return Arrays.stream(words).iterator();
}
});
flatMap .print();
// 执行流的任务
javaStreamingContext.start();
javaStreamingContext.awaitTermination();//线程阻塞
}
}
window算子窗口操作
由于不同的DStream之间是独立,如果相同统计比DStream时间间隔更大的时间范围内的数据,可以使用窗口操作。
窗口时长:计算内容的时间范围
滑动步长:隔多久触发一次计算
//4 添加窗口 窗口大小12s 滑动步长6s
JavaPairDStream<String, Long> word2oneDStreamBywindow = word2oneDStream.window(Duration.apply(12000L), Duration.apply(6000L));
//5 对加过窗口的数据流进行计算
JavaPairDStream<String, Long> resultDStream = word2oneDStreamBywindow.reduceByKey((v1, v2) -> v1 + v2);

![2023年中国一次性医用内窥镜市场发展现状分析:相关产品进入上市高峰期[图]](https://img-blog.csdnimg.cn/img_convert/a40d660e7ac4a94c882b0d6934510905.png)



![2023年中国养殖渔船产业链、市场规模及发展趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/3af7b2b394fa3a7dfb68ab28140a4bda.png)
![2023年中国车用冲压模具行业特征、竞争现状及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/fb7c918bd1407a4e035be409b9d8d4c9.png)