一、简介
官网:https://feapder.com/#/
feapder是一款上手简单,功能强大的Python爬虫框架,内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求,但像任何工具一样,它也有其优点和缺点。以下是 feapder 的一些优缺点:
优点:
- 分布式爬取支持:feapder 支持分布式爬取,可以在多台机器上同时运行,提高了爬取效率。
- 多种爬取方式:支持普通请求爬取、Selenium 动态渲染爬取、API 调用、抓包分析等多种爬取方式,适用于不同类型的网站。
- 灵活的配置:可以通过配置文件或代码来定义爬取任务的规则,包括起始 URL、爬取间隔、解析规则等。
- 强大的去重功能:支持多种去重方式,确保数据的唯一性,避免重复爬取。
- 内建的数据存储和输出:支持将爬取的数据存储到文件、数据库(支持 MySQL、MongoDB 等)或其他数据存储介质。
- 动态代理支持:可以集成动态代理,应对需要翻墙或 IP 限制的网站。
- 内建的分布式调度器:提供了一个简单易用的分布式调度器,灵活管理和调度爬取任务。
- 自动化任务管理:提供了完善的任务管理机制,包括监控任务状态、自动重试、任务日志等功能。
- 并发请求支持:可以配置并发数,实现同时发送多个请求,提高爬取效率。
- 支持 JavaScript 渲染:通过集成 Selenium,可以处理动态渲染的页面,支持爬取 JavaScript 渲染的内容。
- 支持断点续爬、监控报警、浏览器渲染等功能。
缺点: - 学习曲线:对于新手来说,可能需要一些时间来学习和理解框架的使用方法和配置。
- 对于小规模任务:如果只需要爬取少量数据或者只需简单的爬取任务,可能会觉得框架功能较为复杂,使用成本较高。
- 依赖:feapder 依赖于 Python 环境,需要安装相关依赖库。
- 可能需要自定义解析规则:对于特定的网站,可能需要编写自定义的解析规则,这需要一定的编程能力。
二、安装
pip install feapder #精简版,不支持浏览器渲染、不支持基于内存去重、不支持入库mongo
pip install "feapder[render]" #浏览器渲染版,不支持基于内存去重、不支持入库mongo
pip install "feapder[all]" #完整版,支持所有功能
三、命令
- 查看支持的命令行:打开命令行窗口,输入feapder
使用:feapder <command> [options] [args] create:创建项目 shell:交互式环境 zip:压缩项目,项目打包 retry:重试 - 查看某个命令行:feapder -h
- 创建项目:feapder create
-h, --help 查看create命令行帮助信息,feapder create -h -p , --project 创建项目,feapder create -p <project_name> -s , --spider 创建爬虫,feapder create -s <spider_name> -i , --item 创建item ,feapder create -i <table_name> 支持模糊匹配 如 feapder create -i %table_name% -t , --table 根据json创建表,feapder create -t <table_name> -init 创建__init__.py,会自动引入当前目录下的所有py文件到__all__中,feapder create -init -j, --json 创建json,feapder create -j -sj, --sort_json 创建有序json,feapder create -sj -c, --cookies 创建cookie --params 解析地址中的参数 --setting 创建全局配置文件feapder create --setting # feapder create -i spider_data --host localhost --db feapder --username feapder --password feapder123 --host mysql 连接地址,常和-i搭配使用,也可直接在setting文件配置mysql配置 --port mysql 端口,常和-i搭配使用,也可直接在setting文件配置mysql配置 --username mysql 用户名,常和-i搭配使用,也可直接在setting文件配置mysql配置 --password mysql 密码,常和-i搭配使用,也可直接在setting文件配置mysql配置 --db mysql 数据库名,常和-i搭配使用,也可直接在setting文件配置mysql配置 - 交互式环境:feapder shell
-h, --help 查看shell命令行帮助信息,feapder shell -h -u , --url 请求指定地址, feapder shell --url http://www.spidertools.cn/ -c, --curl 执行curl,调试响应, feapder shell --curl http://www.spidertools.cn/ - 压缩项目,项目打包:feapder zip
-h, --help 查看shell命令行帮助信息,feapder zip -h -i 忽略文件,逗号分隔,支持正则 -I 忽略文件夹,逗号分隔,支持正则 -o 输出路径,默认为当前目录 - 重试:feapder retry
-h, --help 查看shell命令行帮助信息,feapder retry -h -r , --request 重试失败的request 如 feapder retry --request <redis_key> -i , --item 重试失败的item 如 feapder retry --item <redis_key>
四、内置爬虫模板
- AirSpider:AirSpider是轻量爬虫,学习成本低。面对一些数据量较少,无需断点续爬,无需分布式采集的需求,可采用此爬虫。
- Spider:Spider是基于redis的分布式爬虫,适用于海量数据采集,支持断点续爬、爬虫报警、数据自动入库等功能
- TaskSpider:TaskSpider是任务分布式爬虫,内部封装了取种子任务的逻辑,内置支持从redis或者mysql获取任务,也可通过自定义实现从其他来源获取任务
- BatchSpider:BatchSpider是分布式批次爬虫,对于需要周期性采集的数据,优先考虑使用本爬虫。
五、Item 类型
item为与数据库表的映射,与数据入库的逻辑相关。 在使用此命令前,需在数据库中创建好表,且setting.py中配置好数据库连接地址
Item和UpdateItem区别,UpdateItem可以根据数据库的唯一索引,插入数据时发现数据已存在,则更新数据,而item不会更新
#创建douban表
CREATE TABLE IF NOT EXISTS douban(
id INT AUTO_INCREMENT,
title VARCHAR(255),
rating FLOAT,
quote VARCHAR(255),
intro TEXT,
PRIMARY KEY(id)
)
- Item:feapder create -i douban 选择Item创建
from feapder import Item class DoubanItem(Item): """ This class was generated by feapder command: feapder create -i douban """ __table_name__ = "douban" def __init__(self, *args, **kwargs): super().__init__(**kwargs) # self.id = None self.intro = None self.quote = None self.rating = None self.title = None - Item 支持字典赋值:若item字段过多,不想逐一赋值,可选择支持字典赋值的Item类型创建,feapder create -i douban 选择Item 支持字典赋值
from feapder import Item class DoubanItem(Item): """ This class was generated by feapder command: feapder create -i douban 1 """ __table_name__ = "douban" def __init__(self, *args, **kwargs): super().__init__(**kwargs) # self.id = kwargs.get('id') self.intro = kwargs.get('intro') self.quote = kwargs.get('quote') self.rating = kwargs.get('rating') self.title = kwargs.get('title') - UpdateItem:feapder create -i douban 选择UpdateItem创建
from feapder import UpdateItem class DoubanItem(UpdateItem): """ This class was generated by feapder command: feapder create -i douban """ __table_name__ = "douban" def __init__(self, *args, **kwargs): super().__init__(**kwargs) # self.id = None self.intro = None self.quote = None self.rating = None self.title = None - UpdateItem 支持字典赋值:若item字段过多,不想逐一赋值,可选择支持字典赋值的UpdateItem类型创建,feapder create -i douban 选择UpdateItem 支持字典赋值
from feapder import UpdateItem class DoubanItem(UpdateItem): """ This class was generated by feapder command: feapder create -i douban 1 """ __table_name__ = "douban" def __init__(self, *args, **kwargs): super().__init__(**kwargs) # self.id = kwargs.get('id') self.intro = kwargs.get('intro') self.quote = kwargs.get('quote') self.rating = kwargs.get('rating') self.title = kwargs.get('title')
六、feapder.AirSpider 模块,继承了BaseParser、Thread
- feapder.AirSpider(thread_count):创建AirSpider对象,thread_count开启线程数量
2.feapder.AirSpider.join(timeout):等待所有线程完成。timeout 参数表示最长等待时间(秒),超过该时间将不再等待 - feapder.AirSpider.stop_spider():停止爬虫
- feapder.AirSpider.run():运行爬虫
- feapder.AirSpider.all_thread_is_done():检查所有线程是否已经完成任务,如果完成返回 True,否则返回 False
- feapder.AirSpider.distribute_task():分配任务
- feapder.AirSpider.to_DebugSpider():用于将当前的爬虫实例转换为调试模式下的爬虫实例
七、feapder.Spider 模块,继承了BaseParser、Scheduler
- feapder.Spider(redis_key=redis_key,…, wait_lock=wait_lock,
redis_key:用于任务调度的 Redis 键名。任务队列中的任务将根据此键名进行调度和分发。 thread_count:爬虫的线程数。指定同时运行的线程数量,用于并发地处理任务。 begin_callback:爬虫开始时调用的回调函数。可以指定一个函数,在爬虫开始时执行特定的操作。 end_callback:爬虫结束时调用的回调函数。可以指定一个函数,在爬虫结束时执行特定的操作。 delete_keys:在爬虫结束时要删除的 Redis 键列表。可以传递一个包含要删除的键名的列表,用于清理任务队列中的任务。 keep_alive:指定是否保持爬虫在后台运行。设置为 True 时,爬虫将保持运行状态,不会自动退出。 auto_start_requests:指定是否自动开始爬取任务。设置为 True 时,爬虫会自动开始处理任务队列中的任务。 batch_interval:任务批处理的时间间隔。可以指定一个时间间隔(以秒为单位),用于控制任务的批处理。 wait_lock:指定是否等待锁释放。设置为 True 时,爬虫在获取任务锁时会等待,直到锁被释放才继续执行。 **kwargs:其他自定义参数。可以传递其他自定义参数作为关键字参数,用于配置爬虫的其他行为和属性。 - feapder.Spider.start_monitor_task(*args, **kws):启动监控任务
- feapder.Spider.distribute_task(*args, **kws):用于分发任务
- feapder.Spider.run():用于启动爬虫
- feapder.Spider.to_DebugSpider():用于将当前的爬虫实例转换为调试模式下的爬虫实例
八、feapder.TaskSpider 模块,继承TaskParser、Scheduler
- feapder.TaskSpider(redis_key,…,use_mysql=True,**kwargs,):创建TaskSpider对象
redis_key:用于任务调度的 Redis 键名。任务队列中的任务将根据此键名进行调度和分发。 task_table:任务表的名称或对象。可以是一个字符串,表示任务表的名称,也可以是一个任务表对象,用于操作任务表。 task_table_type:任务表的类型,默认为 "mysql"。可以是 "mysql"、"mongodb" 或其他支持的任务表类型。 task_keys:任务键列表。指定任务表中的键名列表,用于唯一标识任务。 task_state:任务状态字段名,默认为 "state"。任务表中的该字段用于标识任务的状态。 min_task_count:最小任务数。指定任务表中的最小任务数量,当任务数量低于此值时,会触发任务补充。 check_task_interval:检查任务的时间间隔(秒)。指定任务补充的检查间隔,用于定期检查任务数量并进行补充。 task_limit:任务限制数。指定每次从任务表中获取的任务数量上限。 related_redis_key:关联的 Redis 键名。指定一个关联的 Redis 键名,用于在任务补充时进行关联任务的获取。 related_batch_record:关联任务的批处理记录。指定一个关联任务的批处理记录对象,用于在任务补充时进行关联任务的获取。 task_condition:任务查询条件。指定一个查询条件,用于筛选任务表中的任务。 task_order_by:任务排序方式。指定一个排序方式,用于对任务表中的任务进行排序。 thread_count:爬虫的线程数。指定同时运行的线程数量,用于并发地处理任务。 begin_callback:爬虫开始时调用的回调函数。可以指定一个函数,在爬虫开始时执行特定的操作。 end_callback:爬虫结束时调用的回调函数。可以指定一个函数,在爬虫结束时执行特定的操作。 delete_keys:在爬虫结束时要删除的 Redis 键列表。可以传递一个包含要删除的键名的列表,用于清理任务队列中的任务。 keep_alive:指定是否保持爬虫在后台运行。设置为 True 时,爬虫将保持运行状态,不会自动退出。 batch_interval:任务批处理的时间间隔。可以指定一个时间间隔(以秒为单位),用于控制任务的批处理。 use_mysql:是否使用 MySQL 数据库,默认为 True。设置为 False 时,将不会使用 MySQL 数据库进行任务操作。 **kwargs:其他自定义参数。可以传递其他自定义参数作为关键字参数,用于配置爬虫的其他行为和属性。 - feapder.TaskSpider.add_parser(parser, **kwargs):将参数解析器添加到 TaskSpider 中。可以通过调用 add_parser 方法将自定义的参数解析器添加到 TaskSpider 中,以便解析命令行参数。
- feapder.TaskSpider.start_monitor_task():启动任务监控。调用此方法会启动一个线程,用于监控任务的状态和数量,并进行任务的自动补充和分发。
- feapder.TaskSpider.get_task(todo_task_count):从任务表中获取任务。可以指定要获取的任务数量 todo_task_count,返回获取到的任务列表。
- feapder.TaskSpider.distribute_task(tasks):分发任务。将传入的任务列表 tasks 分发到任务队列中,供爬虫线程处理。
- feapder.TaskSpider.get_task_from_redis():从 Redis 中获取任务。从任务队列中获取一个任务,并返回任务的内容。
- feapder.TaskSpider.get_todo_task_from_mysql():从 MySQL 中获取待处理的任务数量。返回任务表中状态为待处理的任务数量。
- feapder.TaskSpider.get_doing_task_from_mysql():从 MySQL 中获取正在处理的任务数量。返回任务表中状态为正在处理的任务数量。
- feapder.TaskSpider.get_lose_task_count():获取丢失的任务数量。返回任务表中状态为丢失的任务数量。
- feapder.TaskSpider.reset_lose_task_from_mysql():重置丢失的任务。将任务表中状态为丢失的任务重新设置为待处理状态。
- feapder.TaskSpider.related_spider_is_done():关联的爬虫是否已完成。判断关联的爬虫是否已经完成任务。
- feapder.TaskSpider.task_is_done():任务是否已完成。判断任务是否已经完成。
- feapder.TaskSpider.run():运行 TaskSpider。启动 TaskSpider 的运行,开始处理任务。
- feapder.TaskSpider.to_DebugTaskSpider(*args, **kwargs):将 TaskSpider 转换为 DebugTaskSpider。返回一个 DebugTaskSpider 对象,用于调试任务的处理流程
九、feapder.BatchSpider 模块,继承BatchParser、Scheduler
- feapder.BatchSpider( task_table,…,auto_start_next_batch=True,**kwargs,):创建BatchSpider对象
task_table:任务表的名称或对象。可以是一个字符串,表示任务表的名称,也可以是一个任务表对象,用于操作任务表。 batch_record_table:批处理记录表的名称或对象。可以是一个字符串,表示批处理记录表的名称,也可以是一个批处理记录表对象,用于操作批处理记录表。 batch_name:批处理的名称。指定批处理的名称,用于在批处理记录表中标识批处理的记录。 batch_interval:批处理的时间间隔(秒)。指定批处理的时间间隔,用于控制批处理的频率。 task_keys:任务键列表。指定任务表中的键名列表,用于唯一标识任务。 task_state:任务状态字段名,默认为 "state"。任务表中的该字段用于标识任务的状态。 min_task_count:最小任务数。指定任务表中的最小任务数量,当任务数量低于此值时,会触发任务补充。 check_task_interval:检查任务的时间间隔(秒)。指定任务补充的检查间隔,用于定期检查任务数量并进行补充。 task_limit:任务限制数。指定每次从任务表中获取的任务数量上限。 related_redis_key:关联的 Redis 键名。指定一个关联的 Redis 键名,用于在任务补充时进行关联任务的获取。 related_batch_record:关联任务的批处理记录。指定一个关联任务的批处理记录对象,用于在任务补充时进行关联任务的获取。 task_condition:任务查询条件。指定一个查询条件,用于筛选任务表中的任务。 task_order_by:任务排序方式。指定一个排序方式,用于对任务表中的任务进行排序。 redis_key:用于任务调度的 Redis 键名。任务队列中的任务将根据此键名进行调度和分发。 thread_count:爬虫的线程数。指定同时运行的线程数量,用于并发地处理任务。 begin_callback:爬虫开始时调用的回调函数。可以指定一个函数,在爬虫开始时执行特定的操作。 end_callback:爬虫结束时调用的回调函数。可以指定一个函数,在爬虫结束时执行特定的操作。 delete_keys:在爬虫结束时要删除的 Redis 键列表。可以传递一个包含要删除的键名的列表,用于清理任务队列中的任务。 keep_alive:指定是否保持爬虫在后台运行。设置为 True 时,爬虫将保持运行状态,不会自动退出。 auto_start_next_batch:是否自动启动下一批处理。设置为 True 时,当当前批处理完成后,会自动启动下一批处理。 **kwargs:其他自定义参数。可以传递其他自定义参数作为关键字参数,用于配置爬虫的其他行为和属性。 - feapder.BatchSpider.init_batch_property():初始化批处理属性。在批处理开始时调用,用于初始化批处理的属性,包括批处理记录、任务状态等。
- feapder.BatchSpider.add_parser(parser, **kwargs):将参数解析器添加到 BatchSpider 中。可以通过调用 add_parser 方法将自定义的参数解析器添加到 BatchSpider 中,以便解析命令行参数。
- feapder.BatchSpider.start_monitor_task():启动任务监控。调用此方法会启动一个线程,用于监控任务的状态和数量,并进行任务的自动补充和分发。
- feapder.BatchSpider.create_batch_record_table():创建批处理记录表。根据配置的批处理记录表名称和字段,在数据库中创建对应的批处理记录表。
- feapder.BatchSpider.distribute_task(tasks):分发任务。将传入的任务列表 tasks 分发到任务队列中,供爬虫线程处理。
- feapder.BatchSpider.update_task_done_count():更新任务完成数量。在任务完成后调用,更新批处理记录表中的任务完成数量。
- feapder.BatchSpider.update_is_done():更新批处理状态为完成。在批处理完成后调用,更新批处理记录表中的状态为完成。
- feapder.BatchSpider.get_todo_task_from_mysql():从 MySQL 中获取待处理的任务数量。返回任务表中状态为待处理的任务数量。
- feapder.BatchSpider.get_doing_task_from_mysql():从 MySQL 中获取正在处理的任务数量。返回任务表中状态为正在处理的任务数量。
- feapder.BatchSpider.get_lose_task_count():获取丢失的任务数量。返回任务表中状态为丢失的任务数量。
- feapder.BatchSpider.reset_lose_task_from_mysql():重置丢失的任务。将任务表中状态为丢失的任务重新设置为待处理状态。
- feapder.BatchSpider.get_deal_speed(total_count, done_count, last_batch_date):获取处理速度。根据总任务数、已完成任务数和上一批处理的时间,计算并返回任务处理的速度。
- feapder.BatchSpider.init_task():初始化任务。在批处理开始时调用,用于初始化任务表中的任务状态和批处理记录表中的任务数量。
- feapder.BatchSpider.check_batch(is_first_check=False):检查批处理。根据配置的批处理时间间隔和任务数量限制,检查是否需要进行批处理的触发。
- feapder.BatchSpider.related_spider_is_done():关联的爬虫是否已完成。判断关联的爬虫是否已经完成任务。
- feapder.BatchSpider.record_batch():记录批处理。将批处理的相关信息记录到批处理记录表中。
- feapder.BatchSpider.task_is_done():任务是否已完成。判断任务是否已经完成。
- feapder.BatchSpider.run():运行 BatchSpider。启动 BatchSpider 的运行,开始处理任务。
- feapder.BatchSpider.to_DebugBatchSpider(*args, **kwargs):将 BatchSpider 转换为 DebugBatchSpider。返回一个 DebugBatchSpider 对象,用于调试批处理的处理流程。
十、feapder.core 框架核心模块
1.基础解析器:from feapder.core.base_parser import BaseParser,用于解析任务或批处理的参数和配置
- BaseParser.name:解析器的名称
- BaseParser.close():用于关闭解析器,可以在其中进行一些清理工作
- BaseParser.start_requests():生成初始的请求,可以在这里通过 yield 语句返回起始请求
- BaseParser.parse(request, response):默认的页面解析方法,可以在这里定义解析逻辑。
- BaseParser.end_callback():程序结束的回调
- BaseParser.download_midware(request):下载中间件,可以在这里实现一些自定义的下载逻辑
- BaseParser.exception_request(request, response, e):请求或者parser里解析出异常的request
- BaseParser.failed_request(request, response, e):超过最大重试次数的request
- BaseParser.start_callback():程序开始的回调
- BaseParser.validate(request, response):用于验证解析器的有效性,若函数内抛出异常,则重试请求若返回True 或 None,则进入解析函数若返回False,则抛弃当前请求
- 基础任务解析器:from feapder.core.base_parser import TaskParser,用于解析单个任务的参数和配置,继承BaseParser
- TaskParser(task_table, task_state, mysqldb=None):创建基础任务解析器对象
task_table:任务表的名称或配置。可以是一个字符串,表示任务表的名称,也可以是一个字典,包含任务表的配置信息。 task_state:任务状态的配置。一个字典,包含任务状态的配置信息,用于定义任务的不同状态,如待处理、正在处理、已完成等。 mysqldb:MySQL 数据库连接对象。可选参数,用于指定连接到的 MySQL 数据库。 - TaskParser.add_task(): 用于添加一个任务到任务表中,每次启动start_monitor 都会调用,且在init_task之前调用
- TaskParser.start_requests(task): 用于开始处理指定的任务。
- TaskParser.update_task_state(task_id, state=1, **kwargs): 更新任务表中任务状态,做完每个任务时代码逻辑中要主动调用
- TaskParser.update_task_batch(task_id, state=1, **kwargs): 批量更新任务 多处调用,更新的字段必须一致
- 基础批处理解析器:from feapder.core.base_parser import BatchParser,用于解析批处理任务的参数和配置,继承TaskParser
- BatchParser(task_table, batch_record_table, task_state, date_format, mysqldb=None):创建基础批处理解析器对象
task_table:任务表的名称或配置。可以是一个字符串,表示任务表的名称,也可以是一个字典,包含任务表的配置信息。 batch_record_table:批处理记录表的名称或配置。可以是一个字符串,表示批处理记录表的名称,也可以是一个字典,包含批处理记录表的配置信息。 task_state:任务状态的配置。一个字典,包含任务状态的配置信息,用于定义任务的不同状态,如待处理、正在处理、已完成等。 date_format:日期格式的配置。一个字符串,表示日期的格式,用于解析和格式化日期。 mysqldb:MySQL 数据库连接对象。可选参数,用于指定连接到的 MySQL 数据库。 - BatchParser.batch_date:用于表示批处理日期。它指定了批处理任务的日期,用于在批处理记录表中进行日期筛选和操作
- 解析器控制模块:from feapder.core.parser_control import ParserControl,用于控制解析器的执行流程和任务调度
- parserControl = ParserControl(collector, redis_key, request_buffer, item_buffer):创建ParserControl对象
collector:用于收集数据的对象或组件。 redis_key:用于标识任务状态的 Redis 键名。 request_buffer:请求缓冲区,用于存储待处理的请求。 item_buffer:数据项缓冲区,用于存储待收集的数据项。 - parserControl.DOWNLOAD_TOTAL:下载总数。
- parserControl.DOWNLOAD_EXCEPTION:下载异常数。
- parserControl.DOWNLOAD_SUCCESS:下载成功数。
- parserControl.is_show_tip:是否示提示。
- parserControl.PAESERS_EXCEPTION:解析器异常数。
- parserControl.add_parser(parser):添加解析器。
- parserControl.stop():停止解析器。
- parserControl.run():运行解析器。
- parserControl.deal_request(request):处理请求。
- parserControl.get_task_status_count():获取任务状态计数。
- parserControl.is_not_task():检查是否没有任务。
- AirSpider爬虫解析器控制模块,继承ParserControl:from feapder.core.parser_control import AirSpiderParserControl
- airSpiderParserControl = AirSpiderParserControl(memory_db, request_buffer, item_buffer):创建AirSpiderParserControl对象
- airSpiderParserControl.is_show_tip:是否显示提示。
- airSpiderParserControl.deal_request(request):处理请求。
- airSpiderParserControl.run():运行解析器。
- 收集数据模块:from feapder.core.collector import Collector,用于收集和处理爬取的数据
- collector = Collector(redis_key):创建收集器对象
redis_key:用于标识任务状态的 Redis 键名。 - collector.run():运行收集器。
- collector.stop():停止收集器。
- collector.is_collector_task():检查是否有收集任务。
- collector.get_request():获取一个请求对象。
- collector.get_requests_count():获取请求对象的数量。
- 调度管理:from feapder.core.scheduler import Scheduler,用于管理和调度爬虫任务的执行
- scheduler = Scheduler(redis_key,…, **kwargs):创建调度器对象
redis_key:用于标识任务状态的 Redis 键名。 thread_count:调度器使用的线程数。 begin_callback:在开始调度时调用的回调函数。 end_callback:在结束调度时调用的回调函数。 delete_keys:在结束调度时删除的 Redis 键。 keep_alive:调度器是否保持活动状态。 auto_start_requests:是否自动开始请求。 batch_interval:批量处理请求的间隔时间。 wait_lock:等待锁的时间。 task_table:任务表的名称。 **kwargs:其他参数。 - wait_lock:等待锁的时间。
- check_task_status():检查任务状态。
- run():运行调度器。
- wait_lock:等待锁的时间。
- add_parser():添加解析器。
- join():等待所有线程完成。
- all_thread_is_done():检查是否所有线程都完成了。
- check_task_status:检查任务状态。
- delete_tables():删除表。
- have_alive_spider():检查是否有活跃的爬虫。
- heartbeat():心跳。
- heartbeat_start():启动心跳。
- heartbeat_stop():停止心跳。
- init_metrics():初始化指标。
- is_reach_next_spider_time():检查是否到达启动下一个爬虫的时间。
- record_end_time():记录结束时间。
- reset_task():重置任务。
- send_msg():发送消息。
- spider_begin():爬虫开始。
- spider_end():爬虫结束。
- stop_spider():停止爬虫。
十一、feapder.setting:配置模块
- setting.py文件,可通过命令 feapder create --setting 创建
# -*- coding: utf-8 -*- """爬虫配置文件""" # import os # import sys # # # MYSQL # MYSQL_IP = "localhost" # MYSQL_PORT = 3306 # MYSQL_DB = "" # MYSQL_USER_NAME = "" # MYSQL_USER_PASS = "" # # # MONGODB # MONGO_IP = "localhost" # MONGO_PORT = 27017 # MONGO_DB = "" # MONGO_USER_NAME = "" # MONGO_USER_PASS = "" # # # REDIS # # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"] # REDISDB_IP_PORTS = "localhost:6379" # REDISDB_USER_PASS = "" # REDISDB_DB = 0 # # 适用于redis哨兵模式 # REDISDB_SERVICE_NAME = "" # # # 数据入库的pipeline,可自定义,默认MysqlPipeline # ITEM_PIPELINES = [ # "feapder.pipelines.mysql_pipeline.MysqlPipeline", # # "feapder.pipelines.mongo_pipeline.MongoPipeline", # # "feapder.pipelines.console_pipeline.ConsolePipeline", # ] # EXPORT_DATA_MAX_FAILED_TIMES = 10 # 导出数据时最大的失败次数,包括保存和更新,超过这个次数报警 # EXPORT_DATA_MAX_RETRY_TIMES = 10 # 导出数据时最大的重试次数,包括保存和更新,超过这个次数则放弃重试 # # # 爬虫相关 # # COLLECTOR # COLLECTOR_TASK_COUNT = 32 # 每次获取任务数量,追求速度推荐32 # # # SPIDER # SPIDER_THREAD_COUNT = 1 # 爬虫并发数,追求速度推荐32 # # 下载时间间隔 单位秒。 支持随机 如 SPIDER_SLEEP_TIME = [2, 5] 则间隔为 2~5秒之间的随机数,包含2和5 # SPIDER_SLEEP_TIME = 0 # SPIDER_MAX_RETRY_TIMES = 10 # 每个请求最大重试次数 # KEEP_ALIVE = False # 爬虫是否常驻 # 下载 # DOWNLOADER = "feapder.network.downloader.RequestsDownloader" # SESSION_DOWNLOADER = "feapder.network.downloader.RequestsSessionDownloader" # RENDER_DOWNLOADER = "feapder.network.downloader.SeleniumDownloader" # # RENDER_DOWNLOADER="feapder.network.downloader.PlaywrightDownloader", # MAKE_ABSOLUTE_LINKS = True # 自动转成绝对连接 # # 浏览器渲染 # WEBDRIVER = dict( # pool_size=1, # 浏览器的数量 # load_images=True, # 是否加载图片 # user_agent=None, # 字符串 或 无参函数,返回值为user_agent # proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址 # headless=False, # 是否为无头浏览器 # driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX # timeout=30, # 请求超时时间 # window_size=(1024, 800), # 窗口大小 # executable_path=None, # 浏览器路径,默认为默认路径 # render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码 # custom_argument=[ # "--ignore-certificate-errors", # "--disable-blink-features=AutomationControlled", # ], # 自定义浏览器渲染参数 # xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型 # auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox # download_path=None, # 下载文件的路径 # use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征 # ) # # PLAYWRIGHT = dict( # user_agent=None, # 字符串 或 无参函数,返回值为user_agent # proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址 # headless=False, # 是否为无头浏览器 # driver_type="chromium", # chromium、firefox、webkit # timeout=30, # 请求超时时间 # window_size=(1024, 800), # 窗口大小 # executable_path=None, # 浏览器路径,默认为默认路径 # download_path=None, # 下载文件的路径 # render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码 # wait_until="networkidle", # 等待页面加载完成的事件,可选值:"commit", "domcontentloaded", "load", "networkidle" # use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征 # page_on_event_callback=None, # page.on() 事件的回调 如 page_on_event_callback={"dialog": lambda dialog: dialog.accept()} # storage_state_path=None, # 保存浏览器状态的路径 # url_regexes=None, # 拦截接口,支持正则,数组类型 # save_all=False, # 是否保存所有拦截的接口, 配合url_regexes使用,为False时只保存最后一次拦截的接口 # ) # # # 爬虫启动时,重新抓取失败的requests # RETRY_FAILED_REQUESTS = False # # 保存失败的request # SAVE_FAILED_REQUEST = True # # request防丢机制。(指定的REQUEST_LOST_TIMEOUT时间内request还没做完,会重新下发 重做) # REQUEST_LOST_TIMEOUT = 600 # 10分钟 # # request网络请求超时时间 # REQUEST_TIMEOUT = 22 # 等待服务器响应的超时时间,浮点数,或(connect timeout, read timeout)元组 # # item在内存队列中最大缓存数量 # ITEM_MAX_CACHED_COUNT = 5000 # # item每批入库的最大数量 # ITEM_UPLOAD_BATCH_MAX_SIZE = 1000 # # item入库时间间隔 # ITEM_UPLOAD_INTERVAL = 1 # # 内存任务队列最大缓存的任务数,默认不限制;仅对AirSpider有效。 # TASK_MAX_CACHED_SIZE = 0 # # # 下载缓存 利用redis缓存,但由于内存大小限制,所以建议仅供开发调试代码时使用,防止每次debug都需要网络请求 # RESPONSE_CACHED_ENABLE = False # 是否启用下载缓存 成本高的数据或容易变需求的数据,建议设置为True # RESPONSE_CACHED_EXPIRE_TIME = 3600 # 缓存时间 秒 # RESPONSE_CACHED_USED = False # 是否使用缓存 补采数据时可设置为True # # # 设置代理 # PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n # PROXY_ENABLE = True # # # 随机headers # RANDOM_HEADERS = True # # UserAgent类型 支持 'chrome', 'opera', 'firefox', 'internetexplorer', 'safari','mobile' 若不指定则随机类型 # USER_AGENT_TYPE = "chrome" # # 默认使用的浏览器头 # DEFAULT_USERAGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36" # # requests 使用session # USE_SESSION = False # # # 去重 # ITEM_FILTER_ENABLE = False # item 去重 # REQUEST_FILTER_ENABLE = False # request 去重 # ITEM_FILTER_SETTING = dict( # filter_type=1 # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4 # ) # REQUEST_FILTER_SETTING = dict( # filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4 # expire_time=2592000, # 过期时间1个月 # ) # # # 报警 支持钉钉、飞书、企业微信、邮件 # # 钉钉报警 # DINGDING_WARNING_URL = "" # 钉钉机器人api # DINGDING_WARNING_PHONE = "" # 报警人 支持列表,可指定多个 # DINGDING_WARNING_ALL = False # 是否提示所有人, 默认为False # # 飞书报警 # # https://open.feishu.cn/document/ukTMukTMukTM/ucTM5YjL3ETO24yNxkjN#e1cdee9f # FEISHU_WARNING_URL = "" # 飞书机器人api # FEISHU_WARNING_USER = None # 报警人 {"open_id":"ou_xxxxx", "name":"xxxx"} 或 [{"open_id":"ou_xxxxx", "name":"xxxx"}] # FEISHU_WARNING_ALL = False # 是否提示所有人, 默认为False # # 邮件报警 # EMAIL_SENDER = "" # 发件人 # EMAIL_PASSWORD = "" # 授权码 # EMAIL_RECEIVER = "" # 收件人 支持列表,可指定多个 # EMAIL_SMTPSERVER = "smtp.163.com" # 邮件服务器 默认为163邮箱 # # 企业微信报警 # WECHAT_WARNING_URL = "" # 企业微信机器人api # WECHAT_WARNING_PHONE = "" # 报警人 将会在群内@此人, 支持列表,可指定多人 # WECHAT_WARNING_ALL = False # 是否提示所有人, 默认为False # # 时间间隔 # WARNING_INTERVAL = 3600 # 相同报警的报警时间间隔,防止刷屏; 0表示不去重 # WARNING_LEVEL = "DEBUG" # 报警级别, DEBUG / INFO / ERROR # WARNING_FAILED_COUNT = 1000 # 任务失败数 超过WARNING_FAILED_COUNT则报警 # # LOG_NAME = os.path.basename(os.getcwd()) # LOG_PATH = "log/%s.log" % LOG_NAME # log存储路径 # LOG_LEVEL = "DEBUG" # LOG_COLOR = True # 是否带有颜色 # LOG_IS_WRITE_TO_CONSOLE = True # 是否打印到控制台 # LOG_IS_WRITE_TO_FILE = False # 是否写文件 # LOG_MODE = "w" # 写文件的模式 # LOG_MAX_BYTES = 10 * 1024 * 1024 # 每个日志文件的最大字节数 # LOG_BACKUP_COUNT = 20 # 日志文件保留数量 # LOG_ENCODING = "utf8" # 日志文件编码 # OTHERS_LOG_LEVAL = "ERROR" # 第三方库的log等级 # # # 切换工作路径为当前项目路径 # project_path = os.path.abspath(os.path.dirname(__file__)) # os.chdir(project_path) # 切换工作路经 # sys.path.insert(0, project_path) # print("当前工作路径为 " + os.getcwd()) - 导入配置:import feapder.setting as setting 或 from feapder import setting
十二、feapder.network,处理网络请求和响应的模块
- from feapder.network.request import Request 或 from feapder import Request:用于表示一个 HTTP 请求。可以设置请求的 URL、请求方法、请求头、请求体等信息
- request = Request(url,…,**kwargs)
url: 待抓取url retry_times: 当前重试次数 priority: 优先级 越小越优先 默认300 parser_name: 回调函数所在的类名 默认为当前类 callback: 回调函数 可以是函数 也可是函数名(如想跨类回调时,parser_name指定那个类名,callback指定那个类想回调的方法名即可) filter_repeat: 是否需要去重 (True/False) 当setting中的REQUEST_FILTER_ENABLE设置为True时该参数生效 默认True auto_request: 是否需要自动请求下载网页 默认是。设置为False时返回的response为空,需要自己去请求网页 request_sync: 是否同步请求下载网页,默认异步。如果该请求url过期时间快,可设置为True,相当于yield的reqeust会立即响应,而不是去排队 use_session: 是否使用session方式 random_user_agent: 是否随机User-Agent (True/False) 当setting中的RANDOM_HEADERS设置为True时该参数生效 默认True download_midware: 下载中间件。默认为parser中的download_midware is_abandoned: 当发生异常时是否放弃重试 True/False. 默认False render: 是否用浏览器渲染 render_time: 渲染时长,即打开网页等待指定时间后再获取源码 make_absolute_links: 是否转成绝对连接,默认是 **kwargs: 其他值: 如 Request(item=item) 则item可直接用 request.item 取出 method:请求方式,可以是 POST 或 GET。 params:请求参数,通常是一个字典,包含了发送到服务器的额外参数。 data:请求的主体内容,通常用于 POST 请求。 json:请求的主体内容,以 JSON 字符串形式传递。 headers:请求头,包含了一些额外的信息,如 User-Agent、Content-Type 等。 cookies:用于发送请求的 cookies,可以是一个字典或者 CookieJar 对象。 files:上传文件时使用的参数。 auth:用于 HTTP 基本认证。 timeout:等待服务器响应的超时时间,可以是一个浮点数,也可以是一个元组,表示连接超时和读取超时。 allow_redirects:是否允许跟踪 POST/PUT/DELETE 方法的重定向。 proxies:代理设置,以字典形式传递,如 {"http": "http://xxx", "https": "https://xxx"}。 verify:是否验证 SSL 证书。 stream:如果为 False,将会立即下载响应内容。 cert:SSL 证书的路径。 - request.requests_kwargs:请求的一些额外参数。
- request.url:请求的URL。
- request.headers:请求头。
- request.parser_name:解析器的名称。
- request.downloader:下载器。
- request.auto_request:是否自动发送请求。
- request.download_midware:下载中间件。
- request.to_dict:将请求对象转换成字典。
- request.priority:请求的优先级。
- request.callback:回调函数。
- request.method:请求方法(GET、POST等)。
- request.cache_db:缓存数据库。
- request.cached_expire_time:缓存过期时间。
- request.cached_redis_key:缓存的 Redis 键。
- request.callback_name:回调函数的名称。
- request.custom_proxies:自定义代理。
- request.custom_ua:自定义 User-Agent。
- request.filter_repeat:是否进行去重。
- request.fingerprint:指纹。
- request.is_abandoned:是否被废弃。
- request.make_absolute_links:是否创建绝对链接。
- request.proxies_pool:代理池。
- request.random_user_agent:随机 User-Agent。
- request.render:是否进行渲染。
- request.render_downloader:渲染下载器。
- request.render_time:渲染时间。
- request.request_sync:请求同步。
- request.retry_times:重试次数。
- request.session_downloader:会话下载器。
- request.use_session:是否使用会话。
- request.user_agent_pool:User-Agent 池。
- request.from_dict(request_dict):从字典中创建一个请求对象。
- request.get_cookies():获取请求的 cookies。
- request.get_headers():获取请求的 headers。
- request.get_params():获取请求的参数。
- request.get_proxies():获取请求的代理。
- request.get_proxy():获取单个代理。
- request.get_response():获取响应。
- request.get_response_from_cached():从缓存中获取响应。
- request.get_user_agent():获取 User-Agent。
- request.make_requests_kwargs():生成请求参数。
- request.save_cached(response, expire_time):将响应缓存。
- request.del_proxy():删除代理。
- request.del_response_cached():从缓存中删除响应。
- request.copy():复制请求对象。
- from feapder.network.response import Response 或 from feapder import Response:用于表示一个 HTTP 响应。包含响应的状态码、响应头、响应体等信息
- response = Response(response, make_absolute_links)
response:代表接收到的 HTTP 响应。 make_absolute_links:一个布尔值,用于指定是否将相对链接转换为绝对链接。 - response.make_absolute_links:将相对链接转换为绝对链接。
- response.url:响应的URL。
- response.request:关联的请求对象。
- response.to_dict:将响应对象转换成字典。
- response.selector:用于解析的选择器。
- response.browser:浏览器对象。
- response.text:响应的文本内容。
- response.json:将响应解析为 JSON。
- response.headers:响应头信息。
- response.encoding:响应的编码方式。
- response.cookies:响应的 cookies。
- response.driver:浏览器驱动。
- response.content:响应的内容。
- response.next:返回下一个请求对象。
- response.apparent_encoding:响应的编码方式(自动检测)。
- response.code:响应的状态码。
- response.elapsed:响应时间。
- response.encoding_errors:编码错误。
- response.history:响应的重定向历史。
- response.is_html:判断响应是否为 HTML。
- response.is_permanent_redirect:是否为永久重定向。
- response.is_redirect:是否为重定向。
- response.links:响应中的链接。
- response.ok:响应是否成功。
- response.raw:原始响应。
- response.reason:响应的原因。
- response.status_code:响应的状态码。
- response.xpath(query, **kwargs):使用 XPath 进行解析。
- response.css(query):使用 CSS 选择器进行解析。
- response.extract():提取响应内容。
- response.re(regex, replace_entities):使用正则表达式进行提取。
- response.re_first(regex, default, replace_entities):提取第一个匹配的内容。
- from_dict(response_dict):从字典创建一个响应对象。
- response.close():关闭响应对象。
- response.open():打开响应对象。
- response.bs4(features):使用 BeautifulSoup 进行解析。
- response.close_browser(request):关闭浏览器。
- response.from_text(text,url,cookies,headerse, encoding,):从文本创建响应对象。
- response.iter_content(chunk_size, decode_unicode):迭代响应内容。
- response.iter_lines(chunk_size, decode_unicode, delimiter):迭代响应内容的行。
- response.raise_for_status():检查响应的状态,并在非成功响应时引发异常
- from feapder.network.item import Item 或 from feapder import Item
- item = Item(**kwargs):创建item对象,继承ItemMetaclass,**kwargs item的字典对象
''' ItemMetaclass:使Item继承一些默认属性 __name__:类的名称,默认为 None。 __table_name__:类对应的表的名称,默认为 None。 __name_underline__:类名的下划线版本,默认为 None。 __update_key__:用于更新记录的关键字,默认为 None。 __unique_key__:用于唯一标识记录的关键字,默认为 None。 ''' class ItemMetaclass(type): def __new__(cls, name, bases, attrs): attrs.setdefault("__name__", None) attrs.setdefault("__table_name__", None) attrs.setdefault("__name_underline__", None) attrs.setdefault("__update_key__", None) attrs.setdefault("__unique_key__", None) return type.__new__(cls, name, bases, attrs) - item.item_name: 这可能是用于表示一个项目(item)的名称。
- item.unique_key: 这可能是一个用于唯一标识一个项目的关键字。
- item.to_ict: 这可能是一个方法,用于将项目转换为一个字典。
- item.name_underline: 这可能是表示项目名称的下划线版本。
- item.table_name: 这可能是用于表示项目对应的表格名称。
- item.fingerprint: 这个属性可能与项目的指纹(fingerprint)有关。
- item.to_UpdateItem(): 这可能是一个方法,用于将项目转换为一个更新项。
- item.update(*args, **kwargs): 这可能是一个用于更新项目的方法,接受位置参数和关键字参数。
- item.pre_to_db(): 这可能是一个用于将项目预处理为数据库中的格式的方法。
- item.to_sql(auto_update=False, update_columns=()): 这可能是一个用于将项目转换为 SQL 语句的方法,可能有一个名为 auto_update 的参数和一个名为 update_columns 的参数。
- item.update_strict(*args, **kwargs): 这可能是一个用于严格更新项目的方法,接受位置参数和关键字参数。
- from feapder.network.item import UpdateItem 或 from feapder import UpdateItem,继承item
- item = UpdateItem(**kwargs):创建item对象,继承ItemMetaclass,**kwargs item的字典对象
- item.update_key(keys):更新__update_key__值
- from feapder.network.user_agent import get as get_ua
- get(ua_type):获取ua
ua_type: ua类型 chrome opera firefox internetexplorer safari mobile
- from feapder.network.proxy_pool import BaseProxyPool:基础代理池,会在文章后面另起标题配置代理
- BaseProxyPool.get_proxy(): 用于获取一个代理IP。
- BaseProxyPool.del_proxy(): 用于删除一个代理IP。
- BaseProxyPool.tag_proxy(): 用于给一个代理IP打上标签或者标记。
- from feapder.network.proxy_pool import ProxyPool:代理池,继承BaseProxyPool
- proxyPool = ProxyPool(proxy_api=None, **kwargs):创建代理池对象,会在文章后面另起标题配置代理
proxy_api 是一个用于获取代理IP的API接口,如果不提供的话,可能会使用默认的代理获取方式。 **kwargs 则是用于传递其他可能需要的参数。 - proxyPool.proxy_api: 用于获取代理IP的API接口。
- proxyPool.proxy_queue: 用于存储代理IP。
- proxyPool.pull_proxies: 用于从代理API中获取代理IP并将其放入队列中。
- proxyPool.del_proxy(proxy): 用于从队列中删除指定的代理IP。
- proxyPool.get_proxy(): 用于从队列中获取一个代理IP。
- proxyPool.format_proxy(proxy): 用于格式化代理IP的表示方式。
- from feapder.network.user_pool import GuestUserPool, GuestUser:游客用户池,用于从不需要登录的页面获取cookie
- guestUserPool = GuestUserPool(redis_key,page_url=None,min_users=1,must_contained_keys=(),keep_alive=False, **kwargs):创建游客用户池对象
redis_key: user存放在redis中的key前缀 page_url: 生产user的url min_users: 最小user数 must_contained_keys: cookie中必须包含的key,用于校验cookie是否正确 keep_alive: 是否保持常驻,以便user不足时立即补充 kwargs: WebDriver的一些参数 load_images: 是否加载图片 user_agent: 字符串 或 无参函数,返回值为user_agent proxy: xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址 headless: 是否启用无头模式 driver_type: CHROME,EDGE 或 PHANTOMJS,FIREFOX timeout: 请求超时时间 window_size: # 窗口大小 executable_path: 浏览器路径,默认为默认路径 - guestUserPool.login():用于登录获取用户代理。在调用该方法后,用户代理池会向指定的页面 URL 发送请求,获取用户代理列表并存储到 Redis 中。
- guestUserPool.add_user():用于手动添加一个用户代理到用户代理池中。你可以通过调用该方法来添加自定义的用户代理。
- guestUserPool.get_user(user):用于从用户代理池中获取一个用户代理对象。你可以将其用于发送请求。
- guestUserPool.run():用于启动用户代理池,它会自动定时登录获取用户代理。
- guestUserPool.del_user(user_id):用于删除指定 user_id 的用户代理。
- guestUser = GuestUser(user_agent=None, proxies=None, cookies=None, **kwargs):创建用户代理信息对象
user_agent:用户代理字符串,用于模拟浏览器发送请求。 proxies:代理信息,可以是一个代理字典,例如 {"http": "http://proxy.example.com:8080", "https": "https://proxy.example.com:8080"}。 cookies:Cookie 信息,可以是一个 Cookie 字符串,例如 "cookie1=value1; cookie2=value2" **kwargs:自定义属性 - guestUser.user_agent:用户代理字符串,用于模拟浏览器发送请求。
- guestUser.user_id:用户代理的唯一标识符,用于在用户代理池中识别和管理用户代理。
- guestUser.cookies:Cookie 信息,可以是一个 Cookie 字符串,例如 “cookie1=value1; cookie2=value2”。
- guestUser.proxies:代理信息,可以是一个代理字典,例如 {“http”: “http://proxy.example.com:8080”, “https”: “https://proxy.example.com:8080”}。
- guestUser.to_dict():将 GuestUser 对象转换为字典形式,方便序列化和存储。
- guestUser.from_dict(data):从字典中恢复 GuestUser 对象的属性。
- from feapder.network.user_pool import NormalUserPool, NormalUser:普通用户池,管理大量账号的信息,从需要登录的页面获取cookie
- normalUserPool = NormalUserPool(redis_key,…,keep_alive=False,):创建用户池对象
redis_key: 项目名 table_userbase: 用户表名 login_state_key: 登录状态列名 lock_state_key: 封锁状态列名 username_key: 登陆名列名 password_key: 密码列名 login_retry_times: 登陆失败重试次数 keep_alive: 是否保持常驻,以便user不足时立即补充 - normalUserPool.add_user(user):用于手动添加一个用户代理到用户代理池中。你可以通过调用该方法来添加自定义的用户代理。
- normalUserPool.del_user(user_id):用于删除指定 user_id 的用户代理。
- normalUserPool.get_user(block=True):用于从用户代理池中获取一个用户代理对象。如果 block 参数为 True,并且用户代理池为空,该方法会等待直到有可用的用户代理为止。
- normalUserPool.run():用于启动用户代理池,它会自动定时从数据库中获取用户代理。
- normalUserPool.login(user):用于登录获取用户代理。它接受一个 NormalUser 对象作为参数。
- normalUserPool.handel_exception(e):用于处理异常情况,例如在发送请求时发生错误。
- normalUserPool.handle_login_failed_user(user):用于处理登录失败的用户代理。
- normalUserPool.tag_user_locked(user_id):用于标记指定 user_id 的用户代理为锁定状态。
- normalUser = NormalUser(username, password, **kwargs):创建用户代理信息对象,继承GuestUser
- normalUser.user_id:用户代理的id
- normalUser.username:用户名
- normalUser.password:用户密码
- from feapder.network.user_pool import GoldUserPool, GoldUser, GoldUserStatus:昂贵的用户池,用于账号单价较高,需要限制使用频率、使用时间的场景
- goldUserPool = GoldUserPool(redis_key,users,keep_alive=False):创建用户池对象
redis_key: user存放在redis中的key前缀 users: 账号信息 keep_alive: 是否保持常驻,以便user不足时立即补充 - goldUserPool.users:包含用户代理字符串的列表,用于模拟不同类型的高级用户。
- goldUserPool.add_user(user):用于手动添加一个高级用户代理到用户代理池中。你可以通过调用该方法来添加自定义的高级用户代理。
- goldUserPool.del_user(user_id):用于删除指定 user_id 的高级用户代理。
- goldUserPool.get_user(block=True, username=None, used_for_spider_name=None, not_limit_use_interval=False):用于从用户代理池中获取一个高级用户代理对象。如果 block 参数为 True,并且用户代理池为空,该方法会等待直到有可用的高级用户代理为止。
- goldUserPool.run(username):用于启动用户代理池,它会自动定时从数据库中获取高级用户代理。
- goldUserPool.login(user):用于登录获取高级用户代理。它接受一个 GoldUser 对象作为参数。
- goldUserPool.delay_use(user_id, delay_seconds):用于延迟使用指定 user_id 的高级用户代理,以避免频繁请求。
- goldUserPool.get_user_by_id(user_id):用于通过 user_id 获取指定的高级用户代理。
- goldUserPool.record_exception_user(user_id):用于记录发生异常的高级用户代理。
- goldUserPool.record_success_user(user_id):用于记录成功使用的高级用户代理。
- goldUserPool.record_user_status(user_id, status):用于记录高级用户代理的状态,如是否可用、是否锁定等。
- goldUser = GoldUser(max_use_times,use_interval=0,work_time=(7, 23),login_interval=30 * 60,exclusive_time=None,**kwargs,):创建用户代理信息对象,继承NormalUser
max_use_times:@param use_interval: 使用时间间隔。 支持元组 指定间隔的时间范围 如(5,10)即5到10秒;或直接传整数 work_time: 工作时间,默认 7点到23点 login_interval: 登录时间间隔 防止频繁登录 导致账号被封 exclusive_time: 独占时长 - goldUser.redisdb:与用户代理相关的 Redis 数据库。
- goldUser.redis_key:用户代理存储在 Redis 中的键名。
- goldUser.use_interval:两次使用之间的最小间隔时间(以秒为单位)。
- goldUser.use_times:已经使用的次数。
- goldUser.cookies:Cookie 信息。
- goldUser.work_time:工作时间段,表示在哪些时间段内可以使用该高级用户代理。
- goldUser.login_interval:两次登录之间的最小间隔时间(以秒为单位)。
- goldUser.max_use_times:高级用户代理的最大使用次数。
- goldUser.exclusive_time:高级用户代理的独占时间(以秒为单位)
- goldUser.to_dict():将 GoldUser 对象转换为字典形式。
- goldUser.from_dict(data):从字典中恢复 GoldUser 对象的属性。
- goldUser.update(ohter):更新 GoldUser 对象的属性。
- goldUser.get_last_use_time():获取上次使用的时间。
- goldUser.get_login_time():获取上次登录的时间。
- goldUser.get_used_for_spider_name():获取用于爬虫的名称。
- goldUser.is_at_work_time():判断当前时间是否在工作时间段内。
- goldUser.is_overwork():判断是否超过最大工作次数。
- goldUser.is_time_to_login():判断是否到了登录的时间。
- goldUser.is_time_to_use():判断是否到了使用的时间。
- goldUser.next_login_time():获取下次登录的时间。
- goldUser.reset_use_times():重置使用次数。
- goldUser.set_cookies(cookies):设置 Cookie 信息。
- goldUser.set_delay_use(seconds):设置延迟使用的时间。
- goldUser.set_login_time(login_time):设置登录时间。
- goldUser.set_used_for_spider_name(name):设置用于爬虫的名称。
- goldUser.sycn_to_redis():将用户代理信息同步到 Redis 中。
- goldUserStatus = GoldUserStatus():用户代理的状态
- goldUserStatus.USED:表示用户代理已经被使用过,也可直接通过GoldUserStatu获取该属性。
- goldUserStatus.SUCCESS:表示某个操作(比如登录)成功,也可直接通过GoldUserStatu获取该属性。
- goldUserStatus.OVERDUE:表示用户代理已经过期,不再可用,也可直接通过GoldUserStatu获取该属性。
- goldUserStatus.SLEEP:表示用户代理处于休眠状态,也可直接通过GoldUserStatu获取该属性。
- goldUserStatus.EXCEPTION:表示发生了异常情况,也可直接通过GoldUserStatu获取该属性。
- goldUserStatus.LOGIN_SUCCESS:表示登录操作成功,也可直接通过GoldUserStatu获取该属性。
- goldUserStatus.LOGIN_FAILED:表示登录操作失败,也可直接通过GoldUserStatu获取该属性。
十三、feapder.db 数据库模块
- from feapder.db.mysqldb import MysqlDB:mysql数据库
- mysql = MysqlDB(ip, port, db, user_name, user_pass, **kwargs):连接mysql
- mysql.connect_pool:连接池对象,用于管理数据库连接。
- mysql.execute(sql):执行 SQL 。
- mysql.update(sql):执行 SQL 更新操作。
- mysql.add(sql, exception_callfunc=None):执行 SQL 插入操作。
- mysql.find(sql, limit=None, to_json=False, conver_col=False):执行查询操作。
- mysql.get_connection():获取数据库连接。
- mysql.delete(sql):执行删除操作。
- mysql.add_batch(sql, datas):批量插入数据。
- mysql.add_batch_smart(table, datas, **kwargs):智能批量插入数据。
- mysql.add_smart(table, data, **kwargs):智能插入数据。
- mysql.close_connection(conn, cursor):关闭数据库连接。
- mysql.from_url(url, **kwargs):从URL获取数据库连接信息。
- mysql.size_of_connect_pool():连接池大小。
- mysql.size_of_connections():连接数。
- mysql.unescape_string(value):反转义字符串。
- mysql.update_smart(table, data, condition):智能更新数据。
- from feapder.db.mysqldb import auto_retry:mysql自动重试数据库操作,是个装饰器
- from feapder.db.redisdb import RedisDB:redis数据库
- redisDB = RedisDB(ip_ports,db,user_pass,url,decode_responses,service_name,max_connections,**kwargs):连接redis数据库
- redisDB.from_url(url):从 URL 获取连接信息。
- redisDB.get_redis_obj():获取 Redis 连接对象。
- redisDB.clear(table):清除指定表的数据。
- redisDB.srem(table, values):从集合中移除一个或多个元素。
- redisDB.sadd(table, values):向集合中添加一个或多个元素。
- redisDB.zrem(table, values):从有序集合中移除一个或多个元素。
- redisDB.lrange(table, start, end):获取列表指定范围内的元素。
- redisDB.lpush(table, values):将一个或多个值插入到列表头部。
- redisDB.hdel(table, *keys):删除哈希表中的一个或多个指定字段。
- redisDB.hset(table, key, value):设置哈希表中指定字段的值。
- redisDB.bitcount(table):计算给定字符串中,被设置为 1 的比特位的数量。
- redisDB.current_status(show_key, filter_key_by_used_memory):获取当前状态。
- redisDB.exists_key(key):检查指定的键是否存在。
- redisDB.get_connect():获取连接。
- redisDB.get_expire(key):获取键的过期时间。
- redisDB.getbit(table, offsets):获取位图中指定偏移量的值。
- redisDB.getkeys(regex):获取匹配指定模式的所有键。
- redisDB.hexists(table, key):检查哈希表中是否存在指定的字段。
- redisDB.hget(table, key, is_pop):获取哈希表中指定字段的值。
- redisDB.hget_count(table):获取哈希表的字段数量。
- redisDB.hgetall(table):获取哈希表中的所有字段和值。
- redisDB.hincrby(table, key, increment):为哈希表中的字段加上指定增量。
- redisDB.hkeys(table):获取哈希表中的所有字段。
- redisDB.hset_batch(table, datas):批量设置哈希表中的字段值
- redisDB.lget_count(table):获取列表的长度。
- redisDB.lpop(table, count):移除并返回列表的第一个元素。
- redisDB.lrem(table, value, num):移除列表元素。
- redisDB.rpoplpush(from_table, to_table):移除列表的最后一个元素,并将该元素添加到另一个列表。
- redisDB.sdelete(table):删除集合。
- redisDB.set_expire(key, seconds):设置键的过期时间。
- redisDB.setbit(table, offsets, values):对字符串的指定偏移量设置位值。
- redisDB.sget(table, count, is_pop):获取集合中的元素。
- redisDB.sget_count(table):获取集合的元素数量。
- redisDB.sismember(table, key):检查集合中是否存在指定的元素。
- redisDB.str_incrby(table, value):将存储的数字值增一。
- redisDB.strget(table):获取字符串值。
- redisDB.strlen(table):获取字符串的长度。
- redisDB.strset(table, value, **kwargs):设置字符串的值。
- redisDB.zadd(table, values, prioritys):将一个或多个成员及其分数添加到有序集合中。
- redisDB.zexists(table, values):检查有序集合中是否存在指定的成员。
- redisDB.zget(table, count, is_pop):获取有序集合中的成员。
- redisDB.zget_count(table, priority_min, priority_max):获取指定分数范围内的成员数量。
- redisDB.zincrby(table, amount, value):有序集合中对指定成员的分数进行增量操作。
- redisDB.zrangebyscore(table, priority_min, priority_max, count, is_pop):通过分数返回有序集合指定区间内的成员。
- redisDB.zrangebyscore_increase_score(table, priority_min, priority_max, increase_score, count):通过分数返回有序集合指定区间内的成员,并增加分数。
- redisDB.zrangebyscore_set_score(table, priority_min, priority_max, score, count):通过分数返回有序集合指定区间内的成员,并设置分数。
- redisDB.zremrangebyscore(table, priority_min, priority_max):根据分数移除有序集合中的成员
- from feapder.db.redisdb import Encoder:redis对数据进行编码或序列化的工具
- from feapder.db.memorydb import MemoryDB:memory基于内存的队列
- memoryDB = MemoryDB():创建对象
- memoryDB.priority_queue:优先级队列
- memoryDB.get():获取数据
- memoryDB.add(item, ignore_max_size):添加数据
- memoryDB.empty():检查是否为空
- from feapder.db.mongodb import MongoDB:mongoDB数据库
- mongoDB = MongoDB(ip,port,db,user_name,user_pass,urle,**kwargs):连接数据库
ip:MongoDB 服务器的 IP 地址。 port:MongoDB 服务器的端口号。 db:要连接的数据库名称。 user_name:数据库用户的用户名。 user_pass:数据库用户的密码。 urle:数据库的连接 URL。 **kwargs:其他参数。 - mongoDB.db:MongoDB 数据库对象。
- mongoDB.client:MongoDB 客户端对象。
- mongoDB.add(coll_name,data,replace,update_columns,update_columns_value,insert_ignore):向指定集合中插入数据。
- mongoDB.update(coll_name, data, condition, upsert):更新集合中的数据。
- mongoDB.find(coll_name, condition, limit, **kwargs):在集合中查询数据。
- mongoDB.delete(coll_name, condition):在集合中删除数据。
- mongoDB.from_url(url, **kwargs):从 URL 获取数据库连接信息。
- mongoDB.add_batch(coll_name, datas, replace, update_columns, update_columns_value, condition_fields):批量插入数据。
- mongoDB.get_database(database):获取指定名称的数据库。
- mongoDB.get_collection(coll_name, **kwargs):获取指定名称的集合。
- mongoDB.count(coll_name, condition, limit, **kwargs):统计集合中符合条件的文档数量。
- mongoDB.create_index(coll_name, keys, unique):在集合中创建索引。
- mongoDB.drop_collection(coll_name):删除指定名称的集合。
- mongoDB.get_index(coll_name):获取集合的索引信息。
- mongoDB.get_index_key(coll_name, index_name):获取指定索引的键。
- mongoDB.run_command(command):在数据库上运行命令。
十四、feapder.utils 工具模块
1.from feapder.utils.log import get_logger:获取log
- get_logger(name=None,path=None,log_level=None,is_write_to_console=None,is_write_to_file=None,color=None,mode=None,max_bytes=None,backup_count=None,encoding=None):返回logging对象
name: log名 path: log文件存储路径 如 D://xxx.log@param log_level: log等级 CRITICAL/ERROR/WARNING/INFO/DEBUG@param is_write_to_console: 是否输出到控制台 is_write_to_file: 是否写入到文件 默认否 color:是否有颜色 mode:写文件模式 max_bytes: 每个日志文件的最大字节数 backup_count:日志文件保留数量 encoding:日志文件编码
- from feapder.utils.log import log:logging对象
- import feapder.utils.tools as tools:工具模块
- tools.send_msg(msg, level=“DEBUG”, message_prefix=“”): 发送消息,可指定消息级别和前缀。
- tools.get_ip(domain): 获取指定域名的IP地址。
- tools.retry(retry_times=3, interval=0): 重试函数,可指定重试次数和间隔时间。
- tools.get_md5(*args): 计算给定参数的MD5哈希值。
- tools.mkdir(path): 创建目录。
- tools.get_json(json_str): 将JSON字符串解析为Python对象。
- tools.add_zero(n): 给数字添加前导零。
- tools.aio_wrap(loop=None, executor=None): 异步包装器函数。
- tools.canonicalize_url(url): 规范化URL。
- tools.compile_js(js_func): 编译JavaScript函数。
- tools.cookies2str(cookies): 将Cookie对象转换为字符串。
- tools.cookiesjar2str(cookies): 将CookieJar对象转换为字符串。
- tools.cut_string(text, length): 截取指定长度的字符串。
- tools.date_to_timestamp(date, time_format=“%Y-%m-%d %H:%M:%S”): 将日期字符串转换为时间戳。
- tools.del_file(path, ignore=()): 删除文件。
- tools.del_html_js_css(content): 删除HTML内容中的JavaScript和CSS。
- tools.del_html_tag(content, save_line_break=True, save_p=False, save_img=False): 删除HTML内容中的标签。
- tools.del_redundant_blank_character(text): 删除字符串中多余的空白字符。
- tools.delay_time(sleep_time=60): 延迟指定时间。
- tools.dingding_warning(message, message_prefix=None, rate_limit=None, url=None, user_phone=None, secret=None): 发送钉钉警告消息。
- tools.download_file(url, file_path, *, call_func=None, proxies=None, data=None): 下载文件。
- tools.dumps_json(data, indent=4, sort_keys=False): 将Python对象转换为JSON字符串。
- tools.dumps_obj(obj): 将对象转换为字符串。
- tools.email_warning(message, title, message_prefix=None, email_sender=None, email_password=None, email_receiver=None, email_smtpserver=None, rate_limit=None): 发送电子邮件警告消息。
- tools.ensure_float(n): 确保值为浮点数。
- tools.ensure_int(n): 确保值为整数。
- tools.escape(str): 转义字符串中的特殊字符。
- tools.exec_js(js_code): 执行JavaScript代码。
- tools.feishu_warning(message, message_prefix=None, rate_limit=None, url=None, user=None): 发送飞书警告消息。
- tools.fit_url(urls, identis): 匹配URL。
- tools.flatten(x): 扁平化列表。
- tools.format_json_key(json_data): 格式化JSON键。
- tools.format_date(date, old_format=“”, new_format=“%Y-%m-%d %H:%M:%S”): 格式化日期字符串。
- tools.format_seconds(seconds): 格式化秒数。
- tools.format_sql_value(value): 格式化SQL值。
- tools.format_time(release_time, date_format=“%Y-%m-%d %H:%M:%S”): 格式化时间。
- tools.func_timeout(timeout): 函数超时装饰器。
- tools.reach_freq_limit(rate_limit, *key): 判断是否达到频率限制。
- tools.get_all_keys(datas, depth=None, current_depth=0): 获取所有键。
- tools.get_all_params(url): 获取URL中的所有参数。
- tools.get_base64(data): 获取数据的Base64编码。
- tools.get_before_date(current_date, days, current_date_format=“%Y-%m-%d %H:%M:%S”, return_date_format=“%Y-%m-%d %H:%M:%S”): 获取前几天的日期。
- tools.get_between_date(begin_date, end_date=None, date_format=“%Y-%m-%d”, **time_interval): 获取两个日期之间的日期列表。
- tools.get_between_months(begin_date, end_date=None): 获取两个日期之间的月份列表。
- tools.get_cache_path(filename, root_dir=None, local=False): 获取缓存文件路径。
- tools.get_chinese_word(content): 获取字符串中的中文字符。
- tools.get_conf_value(config_file, section, key): 获取配置文件中的值。
- tools.get_cookies(response): 从响应中获取Cookie。
- tools.get_cookies_from_selenium_cookie(cookies): 从Selenium的Cookie对象中获取Cookie字符串。
- tools.get_cookies_from_str(cookie_str): 从字符串中获取Cookie。
- tools.get_cookies_jar(cookies): 将Cookie字符串转换为CookieJar对象。
- tools.get_current_date(date_format=“%Y-%m-%d %H:%M:%S”): 获取当前日期。
- tools.get_current_timestamp(): 获取当前时间戳。
- tools.get_date_number(year=None, month=None, day=None): 获取日期的数字表示。
- tools.get_days_of_month(year, month): 获取指定年份和月份的天数。
- tools.get_domain(url): 获取URL的域名。
- tools.get_english_words(content): 获取字符串中的英文单词。
- tools.get_file_list(path, ignore=[]): 获取指定目录下的文件列表。
- tools.get_file_path(file_path): 获取文件的路径。
- tools.get_file_type(file_name): 获取文件的类型。
- tools.get_firstday_month(month_offset=0): 获取指定月份的第一天。
- tools.get_firstday_of_month(date): 获取指定日期所在月份的第一天。
- tools.get_form_data(form): 获取表单数据。
- tools.get_full_url(root_url, sub_url): 获取完整的URL。
- tools.get_hash(text): 获取文本的哈希值。
- tools.get_html_by_requests(url, headers=None, code=“utf-8”, data=None, proxies={}, with_response=False): 使用Requests库获取HTML内容。
- tools.get_index_url(url): 获取URL的索引URL。
- tools.get_info(html, regexs, allow_repeat=True, fetch_one=False, split=None): 从HTML中提取信息。
- tools.get_json_by_requests(url, params=None, headers=None, data=None, proxies={}, with_response=False, cookies=None): 使用Requests库获取JSON数据。
- tools.get_json_value(json_object, key): 从JSON对象中获取指定键的值。
- tools.get_last_month(month_offset=0): 获取上个月的月份
- tools.get_lastday_month(month_offset=0): 获取指定月份的最后一天。
- tools.get_lastday_of_month(date): 获取指定日期所在月份的最后一天。
- tools.get_localhost_ip(): 获取本机的IP地址。
- tools.get_method(obj, name): 获取对象中的方法。
- tools.get_month(month_offset=0): 获取指定月份的月份。
- tools.get_oss_file_list(oss_handler, prefix, date_range_min, date_range_max=None): 获取指定OSS存储桶中指定前缀和日期范围内的文件列表。
- tools.get_param(url, key): 获取URL中指定参数的值。
- tools.get_random_email(length=None, email_types=None, special_characters=“”): 获取随机的电子邮件地址。
- tools.get_random_password(length=8, special_characters=“”): 获取随机密码。
- tools.get_random_string(length=1): 获取指定长度的随机字符串。
- tools.get_redisdb(): 获取Redis数据库连接对象。
- tools.get_sha1(*args): 计算给定参数的SHA1哈希值。
- tools.get_table_row_data(table): 获取表格中的行数据。
- tools.get_text(soup, *args): 从BeautifulSoup对象中获取文本。
- tools.get_today_of_day(day_offset=0): 获取指定偏移天数的日期。
- tools.get_url_md5(url): 计算URL的MD5哈希值。
- tools.get_urls(html, stop_urls=(“javascript”, “+”, “.css”, “.js”, “.rar”, “.xls”, “.exe”, “.apk”, “.doc”, “.jpg”, “.png”, “.flv”, “.mp4”)): 从HTML中获取URL列表。
- tools.get_uuid(key1=“”, key2=“”): 生成UUID。
- tools.get_year_month_and_days(month_offset=0): 获取指定月份及其包含的天数。
- tools.iflatten(x): 迭代扁平化列表。
- tools.import_cls(cls_info): 动态导入类。
- tools.ip_to_num(ip): 将IP地址转换为数字表示。
- tools.is_html(url): 判断URL是否为HTML页面。
- tools.is_exist(file_path): 判断文件是否存在。
- tools.is_have_chinese(content): 判断字符串中是否包含中文字符。
- tools.is_have_english(content): 判断字符串中是否包含英文字符。
- tools.is_valid_proxy(proxy, check_url=None): 检查代理是否有效。
- tools.is_valid_url(url): 检查URL是否有效。
- tools.jsonp2json(jsonp): 将JSONP转换为JSON。
- tools.key2hump(key): 将下划线命名转换为驼峰命名。
- tools.key2underline(key, strict=True): 将驼峰命名转换为下划线命名。
- tools.linkedsee_warning(message, rate_limit=3600, message_prefix=None, token=None): 发送LinkedSee警告消息。
- tools.make_batch_sql(table, datas, auto_update=False, update_columns=(), update_columns_value=()): 生成批量插入或更新SQL语句。
- tools.mkdir(path): 创建目录。
- tools.memoizemethod_noargs(method): 无参数的方法缓存装饰器。
- tools.make_item(cls, data): 根据类定义和数据生成实例对象。
- tools.make_insert_sql(table, data, auto_update=False, update_columns=(), insert_ignore=False): 生成插入SQL语句。
- tools.make_update_sql(table, data, condition): 生成更新SQL语句。
- tools.list2str(datas): 将列表转换为字符串。
- tools.linksee_warning(message, rate_limit=3600, message_prefix=None, token=None): 发送LinkedSee警告消息。
- tools.loads_obj(obj_str): 将字符串转换为对象。
- tools.log_function_time(func): 记录函数执行时间的装饰器。
- tools.parse_url_params(url): 解析URL中的参数。
- tools.print_pretty(object): 打印对象的漂亮格式。
- tools.print_cookie2json(cookie_str_or_list): 打印Cookie字符串或列表的JSON格式。
- tools.print_params2json(url): 打印URL参数的JSON格式。
- tools.quick_to_json(text): 快速将文本转换为JSON对象。
- tools.quote_url(url, encoding=“utf-8”): 对URL进行编码。
- tools.quote_chinese_word(text, encoding=“utf-8”): 对中文字符进行编码。
- tools.escape(str): 转义字符串中的特殊字符。
- tools.exec_js(js_code): 执行JavaScript代码。
- tools.email_warning(message, title, message_prefix=None, email_sender=None, email_password=None, email_receiver=None, email_smtpserver=None, rate_limit=None): 发送电子邮件警告消息。
- tools.ensure_int(n): 确保值为整数。
- tools.re_def_supper_class(obj, supper_class): 重新定义对象的父类。
- tools.reach_freq_limit(rate_limit, *key): 判断是否达到频率限制。
- tools.read_file(filename, readlines=False, encoding=“utf-8”): 读取文件内容。
- tools.rename_file(old_name, new_name): 重命名文件。
- tools.retry_asyncio(retry_times=3, interval=0): 异步重试函数。
- tools.rows2json(rows, keys=None): 将数据库查询结果转换为JSON格式。
- tools.replace_str(source_str, regex, replace_str=“”): 使用正则表达式替换字符串。
- tools.run_safe_model(module_name): 安全运行模块。
- tools.write_file(filename, content, mode=“w”, encoding=“utf-8”): 写入文件内容。
- tools.wechat_warning(message, message_prefix=None, rate_limit=None, url=None, user_phone=None, all_users=None): 发送微信警告消息。
- tools.urlencode(params): 对URL参数进行编码。
- tools.urldecode(url): 对URL进行解码。
- tools.unquote_url(url, encoding=“utf-8”): 对URL进行解码。
- tools.unescape(str): 反转义字符串中的特殊字符。
- tools.transform_lower_num(data_str): 将字符串中的大写数字转换为小写数字。
- tools.to_date(date_str, date_format=“%Y-%m-%d %H:%M:%S”): 将日期字符串转换为日期对象。
- tools.to_chinese(unicode_str): 将Unicode字符串转换为中文字符串。
- tools.timestamp_to_date(timestamp, time_format=“%Y-%m-%d %H:%M:%S”): 将时间戳转换为日期字符串。
- tools.table_json(table, save_one_blank=True): 函数用于将表格数据转换为JSON格式,并保存到文件中
- tools.switch_workspace(project_path): 函数用于切换工作目录到指定的项目路径
- from feapder.utils.email_sender import EmailSender:发送邮件,可在setting.py中配置
- senderEmail = EmailSender(username, password, smtpserver=“smtp.163.com”):创建发送邮件对象
- senderEmail.send(receivers,title,content,content_type,filepath):发送邮件
- senderEmail.login():登录
- senderEmail.quit():退出
- from feapder.utils.custom_argparse import ArgumentParser 或 from feapder import ArgumentParser:解析命令行参数并生成帮助信息,继承argparse.ArgumentParser,官方文档:https://docs.python.org/3/library/argparse.html#adding-arguments
- parser = ArgumentParser(prog=None,usage=None,description=None,epilog=None,parents=[],formatter_class=HelpFormatter,prefix_chars=‘-’,fromfile_prefix_chars=None,argument_default=None, conflict_handler=‘error’,add_help=True,allow_abbrev=True,exit_on_error=True):创建解析器对象
查看运行命令 python main.py --helpprog -- 程序的名称(默认为:os.path.basename(sys.argv[0])) usage -- 使用说明消息(默认从参数自动生成) description -- 程序功能的描述 epilog -- 在参数描述之后的文本 parents -- 将其参数复制到此程序中的解析器 formatter_class -- 用于打印帮助信息的 HelpFormatter 类 prefix_chars -- 可选参数前缀字符 fromfile_prefix_chars -- 前缀文件的字符,包含额外的参数 argument_default -- 所有参数的默认值 conflict_handler -- 表示如何处理冲突的字符串 add_help -- 添加一个 -h/-help 选项 allow_abbrev -- 允许对长选项进行无歧义的缩写 exit_on_error -- 确定当发生错误时 ArgumentParser 是否退出并显示错误信息 - parser.start(args=None, namespace=None):用于启动解析器的某些功能或流程。
- parser.add_argument(*args, **kwargs):用于向解析器添加一个命令行参数,*args 通常用于指定参数的名字,**kwargs 用于指定参数的属性和默认值
name or flags: 参数的名称或者选项(可以是一个字符串或一个字符串列表),例如 '--input' 或 '-i'。 action: 参数的动作。通常可以是 store(默认)、store_const、store_true、store_false、append、append_const、count 等。 choices: 允许的参数值的列表。 const: 用于 store_const 和 append_const 动作的常量值。 default: 参数的默认值,如果用户没有提供此参数。 dest: 参数被解析后的存储属性的名称。 help: 参数的帮助信息。 metavar:参数的备用显示名称,如帮助中所示 nargs: 参数的个数,可以是一个具体的数字,也可以是 '+' 表示一个或多个,'*' 表示零个或多个。 required: 是否要求必须提供此参数。 type: 参数的类型,例如 int、float、str 等。 - parser.add_mutually_exclusive_group(**kwargs):创建一个互斥的参数组,其中只能选择一个参数。
- parser.parse_args(args=None, namespace=None):解析命令行参数并返回一个包含参数值的命名空间(Namespace)对象。
- parser.run(args, values=None):用于运行解析器的某些功能或流程。
可打印:parser.functions 查看有哪些args可打印:parser.functions 查看有哪些args args:通过add_argument添加的命令行参数 values:通过add_argument添加的命令行中function的参数 - parser.error(message):用于显示错误消息并终止程序执行。
- parser.add_argument_group(*args, **kwargs):用于创建一个参数组,可以将相关的参数分组显示在帮助信息中。
- parser.add_subparsers(**kwargs):创建一个子命令解析器,用于处理不同的子命令。
- parser.convert_arg_line_to_args(arg_line):将一个参数字符串转换为参数列表。
- parser.exit(status=0, message=None):用于退出程序,并可选地显示一条消息。
- parser.format_help():生成并返回帮助信息的字符串。
- parser.format_usage():生成并返回用法信息的字符串。
- parser.parse_intermixed_args(args=None, namespace=None):解析混合的位置参数和可选参数。
- parser.parse_known_args(args=None, namespace=None):解析命令行参数,返回已知参数和未知参数的 Namespace 对象。
- parser.print_help(file=None):将帮助信息打印到指定文件或标准输出。
- parser.print_usage(file=None):将用法信息打印到指定文件或标准输出。
- parser.parse_known_intermixed_args(args=None, namespace=None):解析混合的位置参数和可选参数,返回已知参数和未知参数的 Namespace 对象
- import feapder.utils.perfect_dict as perfect_dict:处理字典数据
- perfect_dict.ensure_value(value):确保值存在,如果值为 None 则返回一个空字典。
- perfect_dict.PerfectDict.get():从字典中获取指定键的值,支持多级键访问
- from feapder.utils import metrics:用于度量或评估某些任务的性能或指标
- metrics.init(influxdb_host=None,influxdb_port=None,influxdb_udp_port=None,influxdb_database=None,influxdb_user=None,influxdb_password=None,influxdb_measurement=None,retention_policy=None,retention_policy_duration=“180d”,emit_interval=60, batch_size=100, debug=False, use_udp=False,timeout=22,ssl=False, retention_policy_replication: str = “1”,set_retention_policy_default=True, **kwargs):打点监控初始化
influxdb_host: InfluxDB 主机的地址。 influxdb_port: InfluxDB 使用的端口。 influxdb_udp_port: InfluxDB 使用的 UDP 端口。 influxdb_database: InfluxDB 数据库的名称。 influxdb_user: InfluxDB 连接所使用的用户名。 influxdb_password: InfluxDB 连接所使用的密码 influxdb_measurement: 存储的表,也可以在打点的时候指定 retention_policy: 保留策略 retention_policy_duration: 保留策略过期时间 emit_interval: 打点最大间隔 batch_size: 打点的批次大小 debug: 是否开启调试 use_udp: 是否使用udp协议打点 timeout: 与influxdb建立连接时的超时时间 ssl: 是否使用https协议 retention_policy_replication: 保留策略的副本数, 确保数据的可靠性和高可用性。如果一个节点发生故障,其他节点可以继续提供服务,从而避免数据丢失和服务不可用的情况 set_retention_policy_default: 是否设置为默认的保留策略,当retention_policy初次创建时有效 **kwargs: 可传递MetricsEmitter类的参数 - metrics.emit_any(tags,fields, classify= “”, measurement= None, timestamp=None):原生的打点,不进行额外的处理
tags: influxdb的tag的字段和值 fields: influxdb的field的字段和值 classify: 点的类别 measurement: 存储的表 timestamp: 点的时间搓,默认为当前时间 - metrics.emit_counter(key,count = 1,classify= “”, tags=None, measurement=None, timestamp= None):聚合打点,即会将一段时间内的点求和,然后打一个点数和
key: 与点绑定的key值 count: 点数 classify: 点的类别 tags: influxdb的tag的字段和值 measurement: 存储的表 timestamp: 点的时间搓,默认为当前时间 - metrics.emit_timer(key= None,duration= 0, classify= “”,tags= None,measurement= None,timestamp=None):时间打点,用于监控程序的运行时长等,每个duration一个点,不会被覆盖
key: 与点绑定的key值 duration: 时长 classify: 点的类别 tags: influxdb的tag的字段和值 measurement: 存储的表 timestamp: 点的时间搓,默认为当前时间 - metrics.emit_store(key= None,value= 0, classify= “”,tags= None,measurement= None,timestamp=None):直接打点,不进行额外的处理
key: 与点绑定的key值 value: 点的值 classify: 点的类别 tags: influxdb的tag的字段和值 measurement: 存储的表 timestamp: 点的时间搓,默认为当前时间 - metrics.flush():强刷点到influxdb
- metrics.close():关闭
- from feapder.utils.metrics import MetricsEmitter
- metricsEmitter = MetricsEmitter(influxdb,batch_size=10, max_timer_seq=0,emit_interval=10,retention_policy=None, ratio=1.0, debug=False,add_hostname=False, max_points=10240,default_tags=None,):创建打点对象
influxdb: influxdb instance batch_size: 打点的批次大小 max_timer_seq: 每个时间间隔内最多收集多少个 timer 类型点, 0 表示不限制 emit_interval: 最多等待多长时间必须打点 retention_policy: 对应的 retention policy ratio: store 和 timer 类型采样率,比如 0.1 表示只有 10% 的点会留下 debug: 是否打印调试日志 add_hostname: 是否添加 hostname 作为 tag max_points: 本地 buffer 最多累计多少个点 - metricsEmitter.make_point(measurement, tags, fields, timestamp=None):创建一个度量指标点(measurement point)
measurement: 存储的表 fields:一个字典,包含了度量的字段和其对应的值。字段通常包含了实际的测量值 tags: influxdb的tag的字段和值 timestamp: 点的时间搓,默认为当前时间 - metricsEmitter.get_timer_point(measurement,key = None,duration = 0,tags= None,timestamp=None,):获取一个计时器(timer)度量指标点
measurement: 存储的表 key: 与点绑定的key值 duration: 时长 tags: influxdb的tag的字段和值 timestamp: 点的时间搓,默认为当前时间 - metricsEmitter.get_store_point(measurement,key = None,value= 0,tags = None,timestamp=None,):获取一个存储(store)度量指标点
measurement: 存储的表 key: 与点绑定的key值 value: 点的值 tags: influxdb的tag的字段和值 timestamp: 点的时间搓,默认为当前时间 - metricsEmitter.get_counter_point(measurement,key = None,count= 1,tags = None,timestamp=None,):获取一个计数器(counter)度量指标点
measurement: 存储的表 key: 与点绑定的key值 count: 点数 tags: influxdb的tag的字段和值 timestamp: 点的时间搓,默认为当前时间 - metricsEmitter.emit_any(*args, **kwargs):原生的打点,不进行额外的处理,方法内部实现make_point+emit
- metricsEmitter.emit_counter(*args, **kwargs)):聚合打点,即会将一段时间内的点求和,然后打一个点数和,方法内部实现get_counter_point+emit
- metricsEmitter.emit_store(*args, **kwargs):直接打点,不进行额外的处理,方法内部实现get_store_point+emit
- metricsEmitter.emit_timer(*args, **kwargs):时间打点,用于监控程序的运行时长等,每个duration一个点,不会被覆盖,方法内部实现get_timer_point+emit
- metricsEmitter.emit(point=None, force=False):发送度量指标点到 InfluxDB
- metricsEmitter.define_tagkv(tagk, tagvs):定义标签键值对
- metricsEmitter.close():关闭
- metricsEmitter.flush():刷新缓冲区,将度量指标发送到 InfluxDB
- from feapder.utils.webdriver import WebDriver:内置的自动化测试工具,继承了selenium的WebDriver
- webDriver = WebDriver(xhr_url_regexes, **kwargs):创建WebDriver对象
xhr_url_regexes:用于配置 WebDriver 的一些正则表达式,以匹配 XMLHttpRequest(XHR)请求的URL。这样可以在需要的情况下进行特定URL的处理或过滤。 **kwargs:用于传递额外的配置项给 WebDriver 对象 - webDriver.driver:获取当前 WebDriver 实例的底层驱动程序。
- webDriver.cookies:获取当前页面的 cookies 信息。
- webDriver.user_agent:获取当前 WebDriver 的用户代理信息。
- webDriver.url:获取当前页面的 URL。
- webDriver.CHROME:代表 Chrome 浏览器标识。
- webDriver.domain:获取当前页面的域名信息。
- webDriver.EDGE:代表 Edge 浏览器标识。
- webDriver.FIREFOX:代表 Firefox 浏览器标识。
- webDriver.PHANTOMJS:代表 PhantomJS 浏览器标识。
- webDriver.chrome_driver():用于创建 Chrome 浏览器驱动的方法。
- webDriver.get_driver():获取当前的 WebDriver 对象。
- webDriver.edge_driver():用于创建 Edge 浏览器驱动的方法。
- webDriver.filter_kwargs():用于过滤关键字参数的方法。
- webDriver.firefox_driver():用于创建 Firefox 浏览器驱动的方法。
- webDriver.phantomjs_driver():用于创建 PhantomJS 浏览器驱动的方法。
- webDriver.xhr_data():用于处理 XMLHttpRequest(XHR)请求,获取请求的数据。
- webDriver.xhr_json():用于处理 XMLHttpRequest(XHR)请求,获取 JSON 数据。
- webDriver.xhr_response():用于处理 XMLHttpRequest(XHR)请求,获取请求的响应。
- webDriver.xhr_text():用于处理 XMLHttpRequest(XHR)请求,获取文本数据。
十五、feapder.commands 执行命令行模块
- import feapder.commands.retry as retry:重试相关的功能
- retry.retry_failed_items(redis_key):可能用于重试处理失败的数据项(items)。
- retry.retry_failed_requests(redis_key):可能用于重试处理失败的请求(requests)。
- retry.parse_args():可能用于解析命令行参数,以获取相应的配置信息。
- import feapder.commands.zip as zip:文件压缩相关的功能
- zip.parse_args(): 用于解析命令行参数,以获取相应的配置信息。
- zip.zip(dir_path, zip_name, ignore_dirs=None, ignore_files=None): 用于将指定目录下的文件进行压缩打包。参数包括待压缩的目录路径、压缩文件的名称、要忽略的目录列表以及要忽略的文件列表。
- zip.is_ignore_file(ignore_files, filename): 用于判断某个文件是否在忽略列表中。参数包括要忽略的文件列表和要判断的文件名。
- import feapder.commands.shell as shell:命令行交互相关的功能
- shell.parse_args(): 用于解析命令行参数,以获取相应的配置信息。
- shell.request(**kwargs): 可能用于发送 HTTP 请求,并返回响应。参数可能包括了用于配置请求的各种参数,如 URL、请求方式、请求头等。
- shell.fetch_curl(): 可能用于获取用于复制粘贴的 cURL 命令,用于模拟请求。
- shell.parse_curl(curl_str): 可能用于解析 cURL 命令,从中提取出请求的各种参数,以便进行相应的操作。
- shell.usage(): 可能用于显示命令行操作的使用说明。
十六、feapder.pipelines 管道模块
- basePipeline = BasePipeline():创建管道
- basePipeline.save_items(table, items):保存数据
- basePipeline.update_items(table, items, update_keys):更新数据, 与UpdateItem配合使用
- basePipeline.close():关闭
十七、代理
- 在项目中创建代理包:proxy
- 创建代理文件proxy>kuaidaili.py,这里以快代理为例:
import requests class Kuaidaili(): request_url = { # 获取代理ip前面 'getIpSignature': 'https://auth.kdlapi.com/api/get_secret_token', # 获取代理ip 'getIp': 'https://dps.kdlapi.com/api/getdps?secret_id=oy2q5xu76k4s8olx59et&num=1&signature={}' } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36' } ip_use = '购买代理的用户名' ip_password = '购买代理的密码' def __init__(self): '''创建request会话对象''' self.request_session = requests.Session() self.request_session.headers.update(self.headers) # 获取代理ip签名 @classmethod def get_ip_url(cls): par = { 'secret_id': 'oy2q5xu76k4s8olx59et', 'secret_key': '5xg6gvouc0vszfw0kxs1a8vrw1r6ity7' } response = requests.post(cls.request_url['getIpSignature'],data=par) response_data = response.json() return cls.request_url['getIp'].format(response_data['data']['secret_token']) @classmethod def get_all_ip(cls): url = cls.get_ip_url() response = requests.get(url) return f'http://{cls.ip_use}:{cls.ip_password}@{response.text}' @classmethod def get_ip(cls): url = cls.get_ip_url() response = requests.get(url) return f'{cls.ip_use}:{cls.ip_password}@{response.text}' if __name__ == '__main__': kuaidaili = Kuaidaili() - 直接给请求指定代理,爬虫文件
import feapder from proxy.kuaidaili import Kuaidaili class AirSpiderDouban(feapder.AirSpider): def __init__(self, thread_count=None): super().__init__(thread_count) self.request_url = 'https://movie.douban.com/top250' # ip代理 self.kuaidaili = Kuaidaili() proxy_ip = self.kuaidaili.get_all_ip() self.proxies = { 'http': proxy_ip, 'https': proxy_ip } print(f'当前代理{self.proxies}') def start_requests(self): yield feapder.Request("https://www.baidu.com") def download_midware(self, request): # 这里使用代理使用即可 request.proxies = self.proxies return request def parse(self, request, response): print(response) def exception_request(self, request, response, e): prox_err = [ConnectTimeout,ProxyError] if type(e) in prox_err: request.del_proxy() - 配置文件setting.py中配置代理,在快代理中需要先设置白名单,设置白名单后ip可以免密码使用,如不想设置白名单可自定义代理池
PROXY_EXTRACT_API = None # 代理提取API ,返回的代理分割符为\r\n PROXY_ENABLE = True PROXY_MAX_FAILED_TIMES = 5 # 代理最大失败次数,超过则不使用,自动删除 - 自定义代理池
- 创建proxy>proxypool.py代理池文件
from feapder.network.proxy_pool import BaseProxyPool from proxy import kuaidaili from queue import Queue import feapder.utils.tools as tools from feapder.utils import metrics class MyProxyPool(BaseProxyPool): def __init__(self): self.kuaidaili = kuaidaili.Kuaidaili() self.proxy_queue = Queue() def format_proxy(self, proxy): return {"http": proxy, "https": proxy} def get_proxy(self): try: if self.proxy_queue.empty(): proxy_ip = self.kuaidaili.get_ip() self.proxy_queue.put_nowait(proxy_ip) proxy = self.proxy_queue.get_nowait() self.proxy_queue.put_nowait(proxy) metrics.emit_counter("used_times", 1, classify="proxy") return self.format_proxy(proxy) except Exception as e: tools.send_msg("获取代理失败", level="error") raise Exception("获取代理失败", e) def del_proxy(self, proxy): """ @summary: 删除代理 --------- @param proxy: ip:port """ if proxy in self.proxy_queue.queue: self.proxy_queue.queue.remove(proxy) metrics.emit_counter("invalid", 1, classify="proxy") self.get_proxy() - 修改setting.py文件
PROXY_EXTRACT_API = True # 代理提取API ,返回的代理分割符为\r\n PROXY_ENABLE = True PROXY_MAX_FAILED_TIMES = 5 # 代理最大失败次数,超过则不使用,自动删除 PROXY_POOL = "proxy.proxypool.MyProxyPool" # 代理池 - 爬虫文件
import feapder class AirSpiderDouban(feapder.AirSpider): def start_requests(self): yield feapder.Request("https://www.baidu.com") def parse(self, request, response): print(response) def exception_request(self, request, response): prox_err = [ConnectTimeout,ProxyError] if type(e) in prox_err: request.del_proxy()
十八、去重
- 修改setting.py配置文件
# # REDIS # # ip:port 多个可写为列表或者逗号隔开 如 ip1:port1,ip2:port2 或 ["ip1:port1", "ip2:port2"] REDISDB_IP_PORTS = "localhost:6379" REDISDB_USER_PASS = "" REDISDB_DB = 0 # 连接redis时携带的其他参数,如ssl=True REDISDB_KWARGS = dict() # 适用于redis哨兵模式 REDISDB_SERVICE_NAME = "" # # 去重 ITEM_FILTER_ENABLE = True # item 去重 # REQUEST_FILTER_ENABLE = False # request 去重 ITEM_FILTER_SETTING = dict( filter_type=1, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、轻量去重(LiteFilter)= 4 name="douban" ) # REQUEST_FILTER_SETTING = dict( # filter_type=3, # 永久去重(BloomFilter) = 1 、内存去重(MemoryFilter) = 2、 临时去重(ExpireFilter)= 3、 轻量去重(LiteFilter)= 4 # expire_time=2592000, # 过期时间1个月 # ) - Dedup参数:用于配置REQUEST_FILTER_SETTING、ITEM_FILTER_SETTING
- filter_type:去重类型,支持BloomFilter、MemoryFilter、ExpireFilter三种
- redis_url:不是必须传递的,若项目中存在setting.py文件,且已配置redis连接方式,则可以不传递redis_url
- name: 过滤器名称 该名称会默认以dedup作为前缀 dedup:expire_set:[name]或dedup:bloomfilter:[name]。 默认ExpireFilter name=过期时间,BloomFilter name=dedup:bloomfilter:bloomfilter
- absolute_name:过滤器绝对名称 不会加dedup前缀
- expire_time:ExpireFilter的过期时间 单位为秒,其他两种过滤器不用指定
- error_rate:BloomFilter/MemoryFilter的误判率 默认为0.00001
- to_md5:去重前是否将数据转为MD5,默认是
- 修改item文件,增加__unique_key__
from feapder import Item class DoubanItem(Item): """ This class was generated by feapder command: feapder create -i douban """ __table_name__ = "douban" __unique_key__ = ["title","quote","rating","title"] # 指定去重的key为 title、quote,最后的指纹为title与quote值联合计算的md5 def __init__(self, *args, **kwargs): super().__init__(**kwargs) # self.id = None self.intro = None self.quote = None self.rating = None self.title = None
十九、邮件报警
- 需要根据官网文档邮件报警配置163邮箱,https://feapder.com/#/source_code/%E6%8A%A5%E8%AD%A6%E5%8F%8A%E7%9B%91%E6%8E%A7
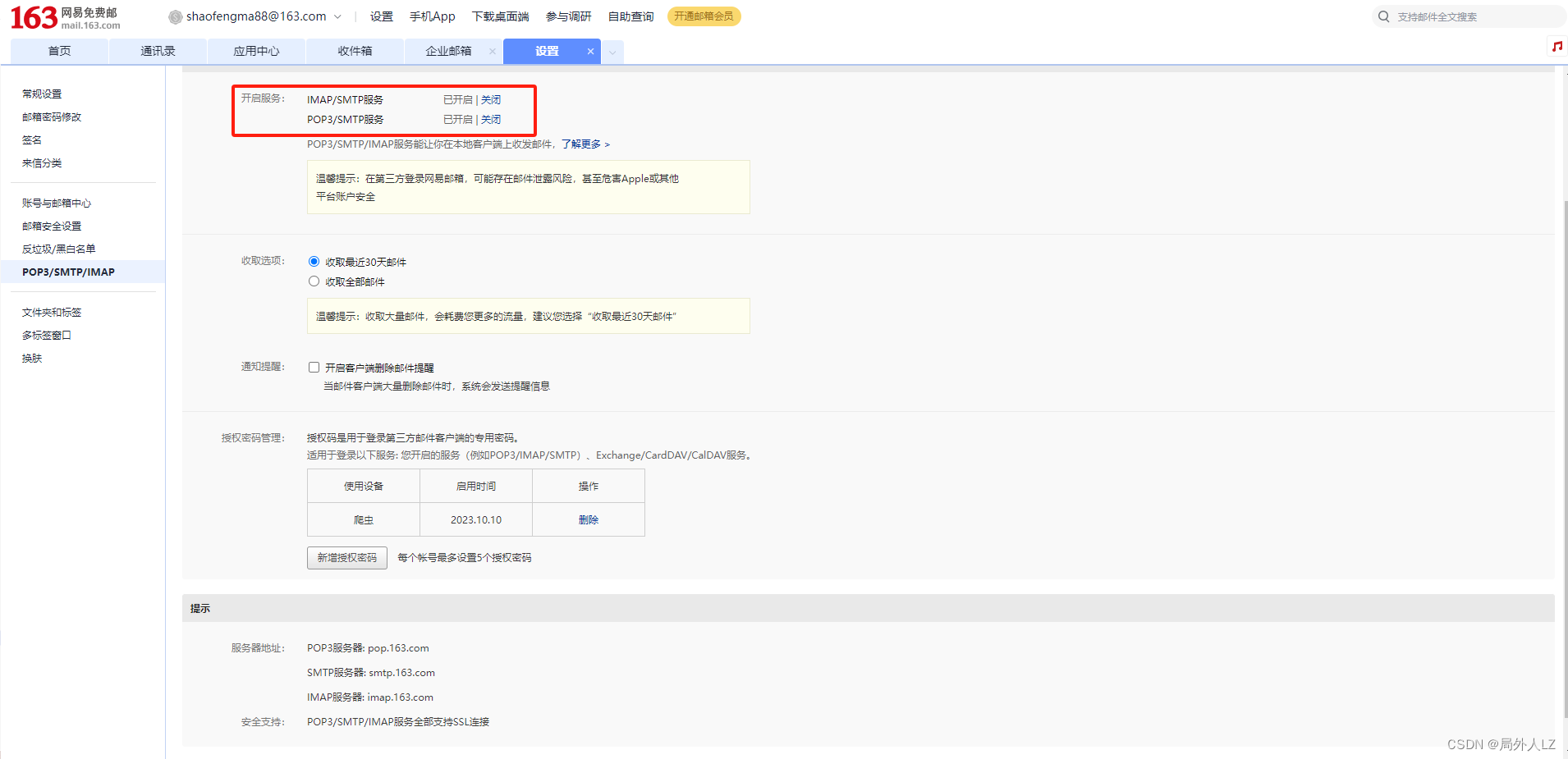
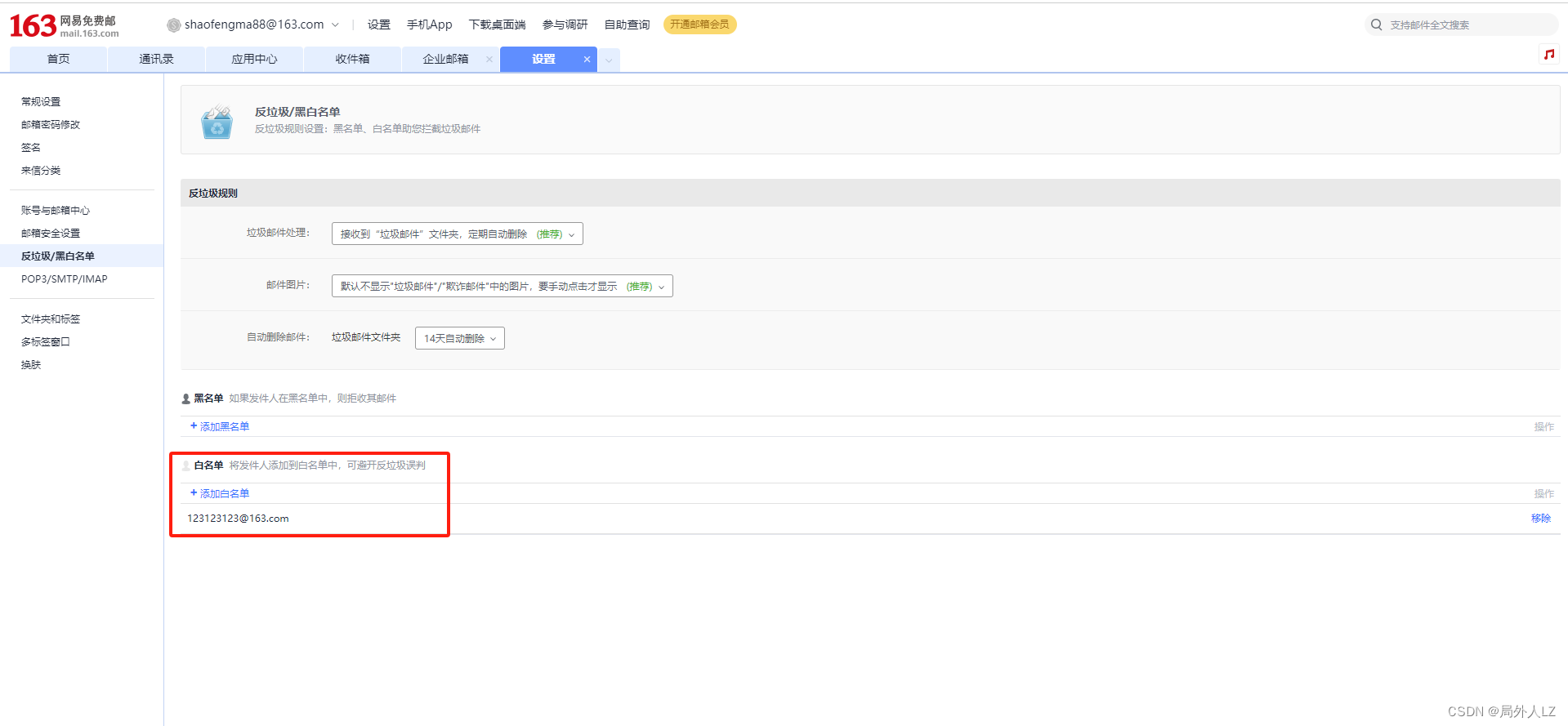
- 修改setting.py配置
EMAIL_SENDER = "123123123@163.com" # 发件人 EMAIL_PASSWORD = "EYNXMBWJKMLZFTKQ" # 授权码 EMAIL_RECEIVER = ["123123123@163.com"] # 收件人 支持列表,可指定多个 EMAIL_SMTPSERVER = "smtp.163.com" # 邮件服务器 默认为163邮箱 - 修改爬虫文件
import feapder
from feapder.network.user_agent import get as get_ua
from requests.exceptions import ConnectTimeout,ProxyError
from feapder.utils.email_sender import EmailSender
import feapder.setting as setting
class AirSpiderDouban(feapder.AirSpider):
def __init__(self, thread_count=None):
super().__init__(thread_count)
self.request_url = 'https://www.baidu.com'
def start_requests(self):
yield feapder.Request(self.request_url)
def parse(self, request, response):
pass
def end_callback(self):
with EmailSender(setting.EMAIL_SENDER,setting.EMAIL_PASSWORD) as email_sender:
email_sender.send(setting.EMAIL_RECEIVER, title='python',content="爬虫结束")
if __name__ == "__main__":
AirSpiderDouban(thread_count=5).start()
二十、自定义管道
- 创建pipeline包
- 创建pipeline>mysql_pipeline.py文件
from feapder.pipelines import BasePipeline class MysqlPipeline(BasePipeline): def save_items(self, table, items): print("自定义pipeline, 保存数据 >>>>", table, items) return True def update_items(self, table, items, update_keys): print("自定义pipeline, 更新数据 >>>>", table, items, update_keys) return True - 修改setting.py文件
ITEM_PIPELINES = [ "pipeline.mysql_pipeline.MysqlPipeline", ]





![[AutoSAR系列] 1.2 AutoSar 综述](https://img-blog.csdnimg.cn/9a589257b6484714b1f558beef12ce70.png)