1 kafka 是啥
Kafka 是一款开源的消息引擎系统,用来实现解耦的异步式数据传递。即系统 A 发消息给到 消息引擎系统,系统 B 通过消息引擎系统读取 A 发送的消息,在大数据场景下,能达到削峰填谷的效果。

2 Kafka 术语

Kafka 中的分区机制指的是将每个主题(Topic)划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中,也就是说如果向一个双分区的主题发送一条消息,这条消息要么在分区 0 中,要么在分区 1 中。Kafka 的分区编号是从 0 开始的,如果 Topic 有 100 个分区,那么它们的分区号就是从 0 到 99。每个分区下可以配置若干个副本,其中只能有 1 个领导者副本和 N-1 个追随者副本。
Kafka 的三层消息架构:
1)主题层,每个主题可以配置 M 个分区,而每个分区又可以配置 N 个副本。
2)分区层,每个分区的 N 个副本中只能有一个充当领导者角色,对外提供服务;其他 N-1 个副本是追随者副本,只是提供数据冗余之用。
3)消息层,分区中包含若干条消息,每条消息的位移从 0 开始,依次递增。最后,客户端程序只能与分区的领导者副本进行交互。
Broker 如何持久化数据?
Kafka 使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只能追加写(Append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机 I/O 操作,改为性能较好的顺序 I/O 写操作,这也是实现 Kafka 高吞吐量特性的一个重要手段。如果不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此 Kafka 必然要定期地删除消息以回收磁盘。怎么删除呢?简单来说就是通过日志段(Log Segment)机制。在 Kafka 底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,Kafka 会自动切分出一个新的日志段,并将老的日志段封存起来。Kafka 在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘空间的目的。
3 生产者
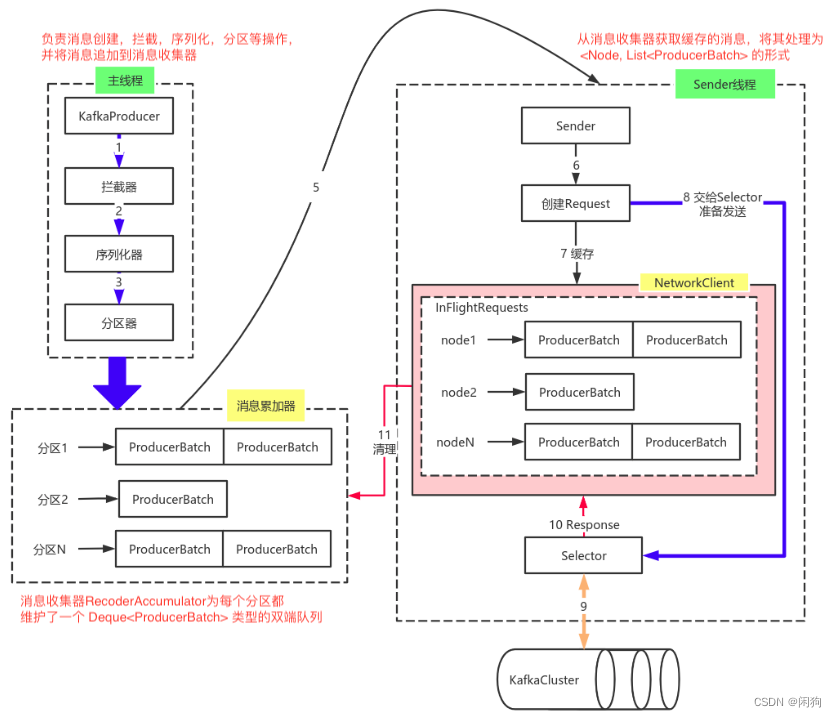
3.1 消息发送

-
Producer创建时,会创建一个Sender线程并设置为守护线程;
-
生产消息时,内部是异步流程。生产的消息先经过拦截器->序列化器->分区器,然后将消息缓存在缓冲区(该缓冲区也是在Producer创建时创建);
-
批次发送的条件为:缓冲区数据大小达到 batch.size 或者 linger.ms 达到上限,哪个先达到就算哪个;
-
批次发送后,发往指定分区,然后落盘到broker;如果生产者配置了 retrires 参数大于 0 并且失败原因允许重试,那么客户端内部会对该消息进行重试;
-
落盘到broker成功,返回生产元数据给生产者;
-
元数据返回有两种方式:一种是通过阻塞直接返回,另一种是通过回调返回。
3.2 原理剖析