一,引言
所谓万维网,简单来说就是咱们经常能看见的HTTP,万维网就是基于应用层的HTTP协议出现的。伴随HTTP协议的主要一点就是超文本的概念。
二,超文本的概念
超文本按照非线性结构,将文档中的相关内容的不同部分通过关键字建立其超链接(hypertext) ,阅读的用户可以通过超链接在文档中进行随意的跳转,这些信息还不会受到顺序和空间的限制。渐渐的,不仅文本,图形、视频、影像等媒体都开始作为了链接的对象。
超媒体系统一共分为两种:分布式超媒体系统和集中式超媒体系统。

显而易见,万维网采用的是分布式超媒体系统。那么网络中如此多的资源,难免会有重名的,如何在网络中标识一个唯一的资源呢?
二,URL统一资源定位符
URL(统一资源定位符)为我们标识了网络中唯一的资源。它标识了该服务器上资源的路径名、资源名。URL是文件资源在Internet上范围内的扩展。
URL这个东西比较抽象,其实就是我们俗称的网址。而一般我们使用网址进行访问时其构成如下:
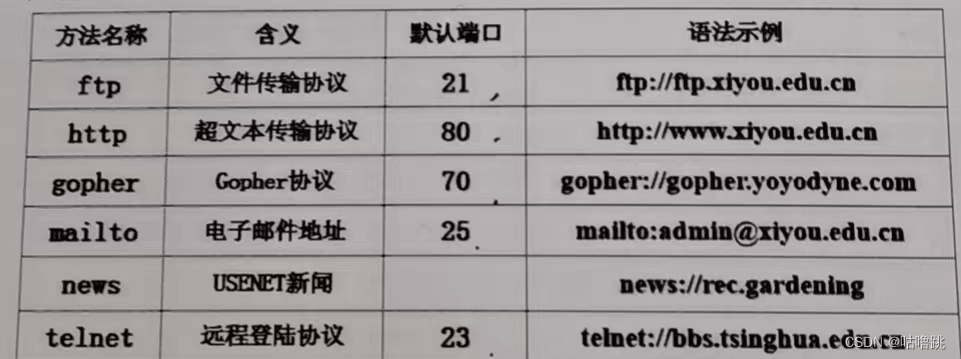
<访问方法>://<用户名>:<密码>@<主机>:<端口>/<URL路径>
当然了,访问方法不同,使用的端口等信息自然也不同
三,HTTP协议
超链接的简写为HTTP,那么他自然需要HTTP协议实现。我们常用的浏览器就是通过HTTP协议与服务器进行通信。
HTTP协议(Hyper Test Transfer Protocol)超文本传输协议,实现了客户和服务器不同系统间的信息交流。HTTP本身是面向事物的无连接协议,但是客户程序和服务器需要通过TCP连接,来完成请求和响应。
HTTP还具备高速缓存的能力,你首次访问一个网站或资源后,下次再访问可以从高速缓存中快速找到。但是大量的高速缓存会影响CPU的使用,因此电脑卡的时候,我们经常让你清一清缓存。
四,万维网工作流程
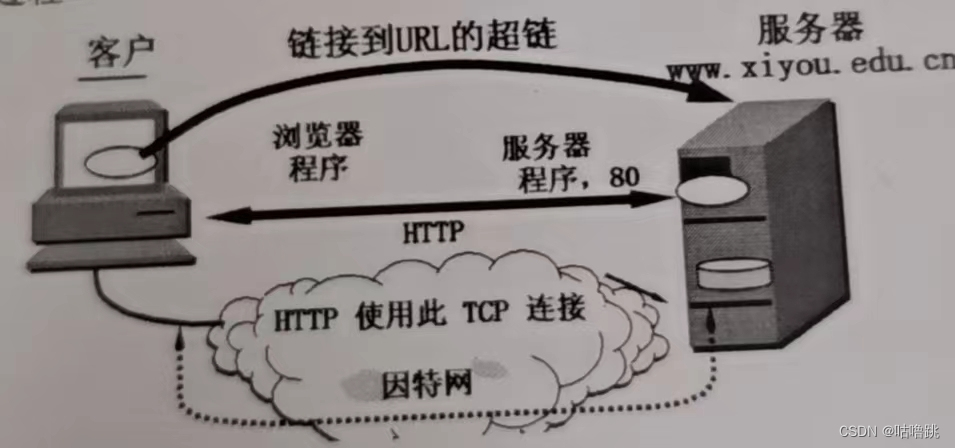
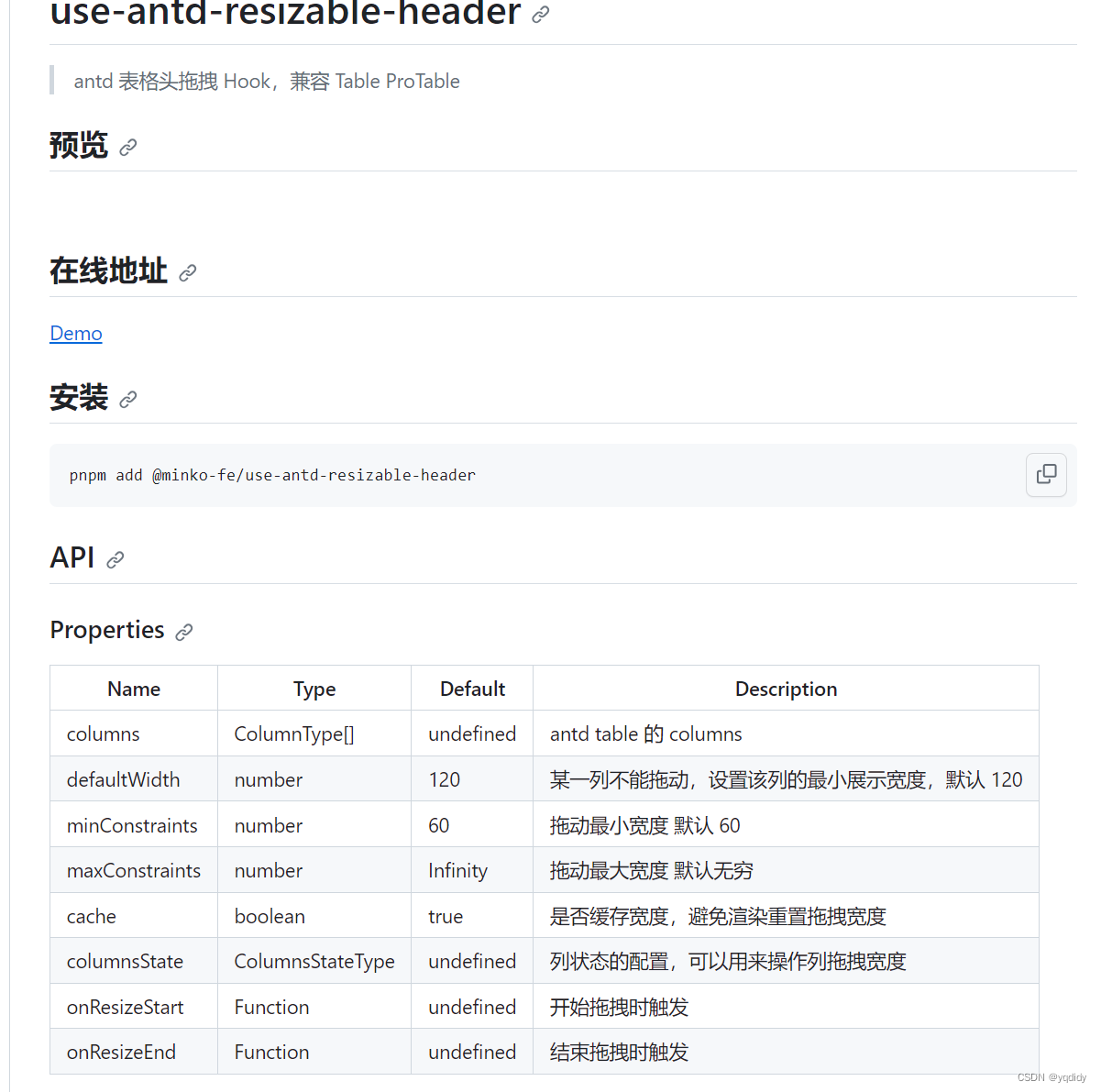
上图是万维网工作流程的示意图
以我们访问百度为例:
我们在地址栏输入地址(http://www.baidu.com),之后浏览器将执行下列操作:
1.浏览器分析超链接指向页面的URL,获得服务器的名字(www.baidu.com)
2.浏览器向DNS请求解析(www.baidu.com)所对应的IP地址
3.DNS解析出目的地址的IP地址后告诉浏览器
4.浏览器使用上述的目的IP地址与www服务器通过80端口建立连接
5.浏览器接收完页面所有数据后断开与服务器的连接
6.浏览器显示index.htm的内容,同时等待用户操作,当用户进行搜索或者点击某些超链接以后,又会回到步骤1重新经历该流程。
HTTP使用持续链接的方式进行工作。持续链接的意思是万维网服务器发送响应后仍然在一段时间内保持这条连接,使得同一个客户(浏览器)和该服务器可以继续在这条连接上传送后续的HTTP请求报文和响应报文。(只要这些文档都在同一个服务器上就可以持续)。
而持续链接又分为两种方式:流水线方式和非流水线方式。
流水线方式:客户收到前一个响应后才能发出下一个请求。
非流水线方式:客户在收到HTTP的响应报文之前就能够接着发送新报文。
上面两点是不是很像之前说过的TCP的两个连接方式——停止等待协议和ARQ。HTTP协议是无连接的,因此需要TCP作为其承载工具,因此它也具备TCP的某些传输特征。
五,HTML
HTML语言(Hyper Text Markup Language)超文本标记语言。是制作Web页面的标准语言,它将可将文本格式化!我们通过浏览器看到的页面背景、特效、字体大小等都是通过HTML语言编程后体现的。通过统一的编程进行逻辑化的设计让我们可以轻松浏览各种各样的网页。文件后带有“.html”或者“htm”的就是HTML文件。
关于HTML,我曾学过一些简单的部分,到时候会分享
六,cookie
cookie不是曲奇,是用来存放用户信息的。每个站点使用cookie来追踪用户。cookie表示在HTTP服务器和客户之间传递的状态信息。使用cookie的网站服务器为用户产生一个唯一的识别码,这个识别码可以追踪用户在网站上的活动。因此,我们浏览网页时常会提醒是否允许cookie,也就是留下在网页中的活动。一般的,我们不推荐在一些未知网站或者个人网站上留有cookie,这是为了预防安全问题。
七,后续
HTTP对于通信而言只是一个协议,但是HTTP引申出来的内容很多,再往后谈论就是程序编程和计算机系统架构的事请了,我学过一些简单的常用的HTML语句和知识,回头给大家分享。至于从Telnet到万维网和HTTP,就到这里吧