莱克斯·弗里德曼(Lex Fridman),男,麻省理工学院(MIT)研究科学家兼播客节目主持人,是一位俄罗斯裔美国计算机科学家。2014年,弗里德曼加入谷歌,但在6个月后离开了公司。2015年,他搬到了麻省理工学院的汽车实验室,从事“心理学和大数据分析以了解驾驶员行为”的工作。2019年,弗里德曼发表了一项关于特斯拉自动驾驶仪的研究。在2019年,他离开了实验室,并在航空和航天部门担任了一个无薪职位。截至2023年,他是麻省理工学院信息和决策系统实验室的研究科学家。
弗里德曼于2018年开始播客。它最初名为“人工智能播客”,但在2020年改为“莱克斯弗里德曼播客”。到2023年4月,弗里德曼已经录制了超过350集。弗里德曼播客访谈的对象包括埃隆马斯克、国际象棋大师马格努斯·卡尔森、对冲基金经理雷·达里奥、科技高管杰克·多尔西和马克·扎克伯格等。Lex Fridman的播客内容质量很高,其官网https://lexfridman.com/podcast/上有全部的播客内容和文本。
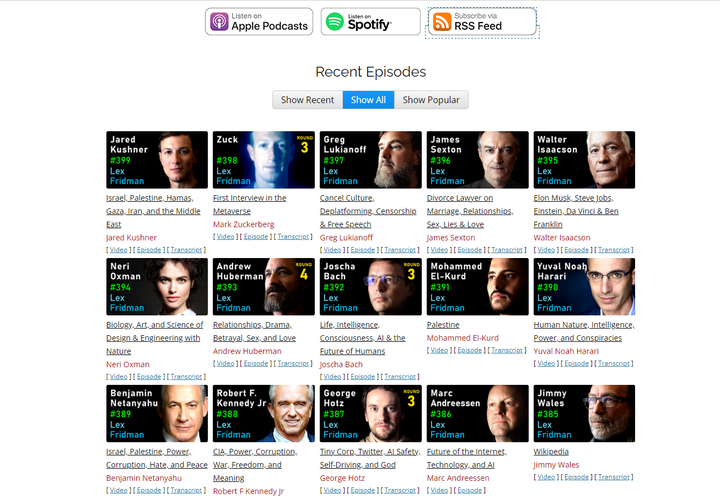
怎么批量下载这些播客音频呢?
首先打开播客的RSS feed https://lexfridman.com/feed/podcast/
寻找到音频的标题:
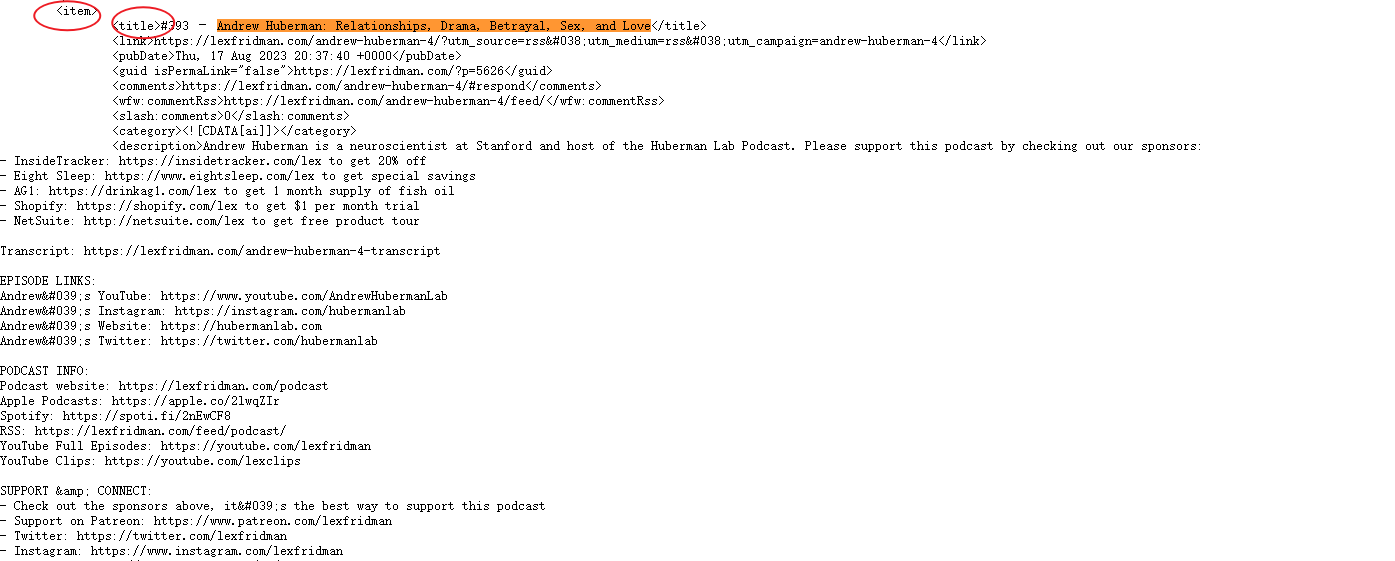
播客的mp3音频:

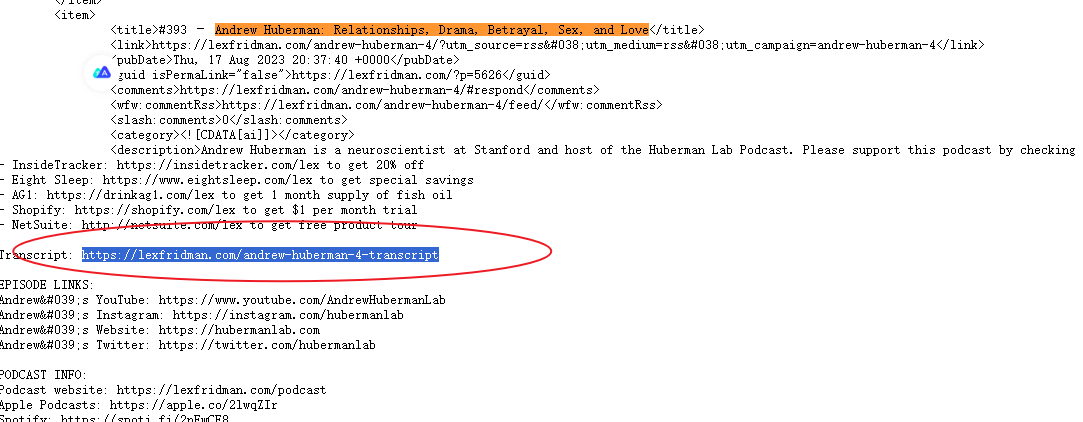
播客的文本:
在ChatGPT中输入提示词如下:
你是一个Python编程专家,要完成一个批量下载网页播客音频的任务,具体步骤如下:
在电脑E盘,创建一个Excel文件:lexfridman.xlsx;
打开播客feed:https://lexfridman.com/feed/podcast/,解析源代码;
定位所有<item>标签;
然后在<item>标签中定位<title>标签,提取其内容,然后去掉“#”符号,将“ : ”符号改成“-”,作为音频文件标题;
然后在<item>标签中定位<enclosure>标签,提取其url属性值,去除其中的“media.blubrry.com/takeituneasy/”,作为音频文件下载地址;
然后在<item>标签中定位内容为“Transcript:”的p标签,提取p标签内a标签的内容作为音频文本下载地址;
将音频文件标题、音频文件下载地址、音频文本下载地址都保存到表格lexfridman.xlsx;
注意:每一步都要输出相关信息;
检查 audio_response.status_code 和 transcript_response.status_code 是否为 200 ;
音频文件标题、音频文件下载地址、音频文本下载地址都要打印输出;
ChatGPT给出的源代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 创建Excel文件
df = pd.DataFrame(columns=['Title', 'Audio URL', 'Transcript URL'])
df.to_excel('E:\\lexfridman.xlsx')
# 获取源代码
response = requests.get('https://lexfridman.com/feed/podcast/')
soup = BeautifulSoup(response.text, 'lxml')
# 解析源代码
items = soup.find_all('item')
for item in items:
# 获取标题
title = item.find('title').text
title = title.replace('#', '').replace(' : ', ' - ')
print(f'Title: {title}')
# 获取音频下载地址
audio_url = item.find('enclosure')['url']
audio_url = audio_url.replace('http://media.blubrry.com/takeituneasy/', '')
print(f'Audio URL: {audio_url}')
# 获取音频文本下载地址
transcript_url = ''
for p in item.find_all('p'):
if 'Transcript:' in p.text:
transcript_url = p.find('a')['href']
print(f'Transcript URL: {transcript_url}')
break
# 保存到表格
new_row = pd.DataFrame({'Title': [title], 'Audio URL': [audio_url], 'Transcript URL': [transcript_url]})
df = pd.concat([df, new_row], ignore_index=True)
# 保存表格
df.to_excel('E:\\lexfridman.xlsx', index=False)
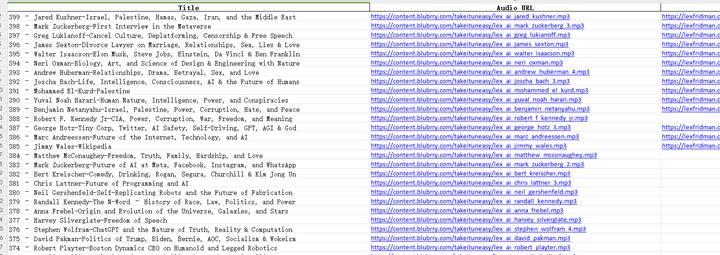
运行程序,所有音频下载地址已经保存到Excel表格中:
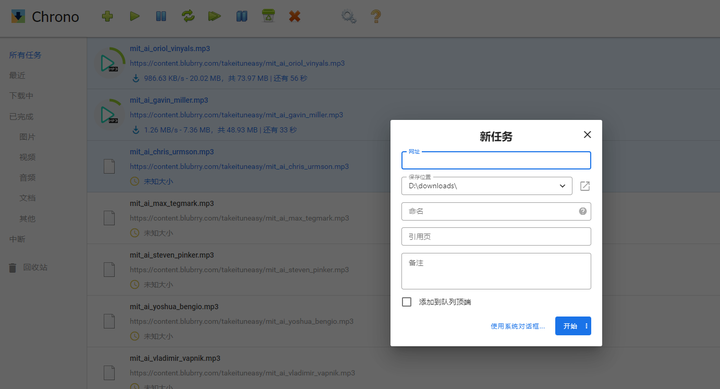
只复制所有音频下载地址,然后打开Chrome浏览器中的Chrono下载器,进行下载:
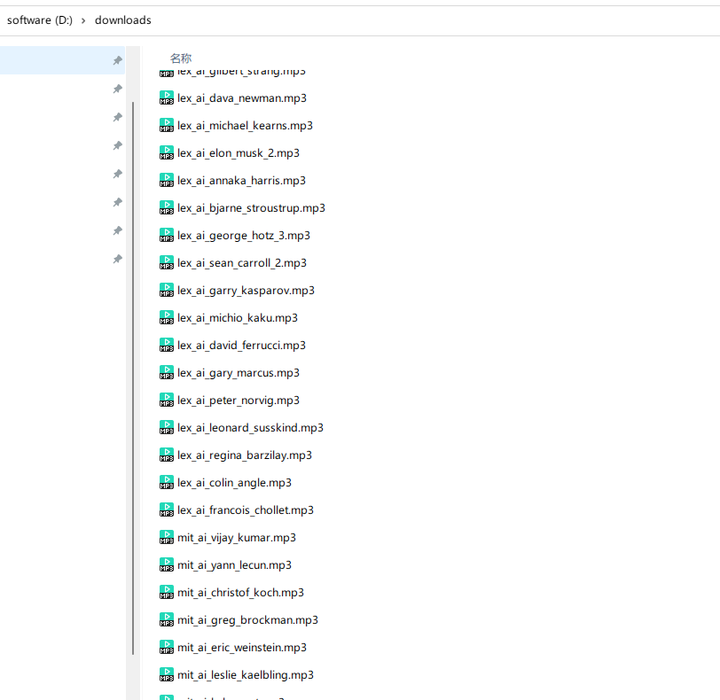
399个播客音频很快就下载完成了: