图像搜索已成为一种流行且功能强大的能力,使用户能够通过匹配功能或视觉内容来查找相似的图像。随着计算机视觉和深度学习的快速发展,这种能力得到了极大的增强。
本文主要介绍如何基于矢量数据库MYSCALE来实现图像搜索功能。
一、MySCALE简介
MyScale 是一个基于云的数据库,针对 AI 应用程序和解决方案进行了优化,构建在开源 ClickHouse 之上。它有效地管理大量数据,以开发强大的人工智能应用程序。
- 专为 AI 应用程序构建:在单个平台中管理和支持用于 AI 应用程序的结构化和矢量化数据的分析处理。
- 专为性能而构建:先进的 OLAP 数据库架构,以令人难以置信的性能对矢量化数据执行操作。
- 专为通用可访问性而构建:SQL 是 MyScale 所需的唯一编程语言。这使得MyScale与定制API相比更有利,并且适合大型编程社区。
二、实践演示
(一)下载依赖
经过实践python3.7版本可支持后续演示
pip installdatasets clickhouse-connect
pip installrequests transformers torch tqdm(二)构建数据集
这一步主要是将数据转化为向量数据,最终格式为xxx.parquet文件,构建数据集转化数据这一步骤比较耗时且吃机器配置,可以跳过这一步,后续直接下载现成的转化完成的数据集
//下载和处理数据
下载、解压我们需要转化的数据
wget https://unsplash-datasets.s3.amazonaws.com/lite/latest/unsplash-research-dataset-lite-latest.zip
unzip unsplash-research-dataset-lite-latest.zip -d tmp读取下载数据并转化为Pandas dataframes
importnumpy asnp
importpandas aspd
importglob
documents = ['photos', 'conversions']
datasets = {}
fordoc indocuments:
files = glob.glob("tmp/"+ doc + ".tsv*")
subsets = []
forfilename infiles:
df = pd.read_csv(filename, sep='\t', header=0)
subsets.append(df)
datasets[doc] = pd.concat(subsets, axis=0, ignore_index=True)
df_photos = datasets['photos']
df_conversions = datasets['conversions']
定义函数extract_image_features,然后从数据框中选择1000个照片ID,下载对应的图像,调用函数来帮助我们从图像中提取他们的图像嵌入
importtorch
fromtransformers importCLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
defextract_image_features(image):
inputs = processor(images=image, return_tensors="pt")
withtorch.no_grad():
outputs = model.get_image_features(**inputs)
outputs = outputs / outputs.norm(dim=-1, keepdim=True)
returnoutputs.squeeze(0).tolist()
fromPIL importImage
importrequests
fromtqdm.auto importtqdm
# select the first 1000 photo IDs
photo_ids = df_photos['photo_id'][:1000].tolist()
# create a new data frame with only the selected photo IDs
df_photos = df_photos[df_photos['photo_id'].isin(photo_ids)].reset_index(drop=True)
# keep only the columns 'photo_id' and 'photo_image_url' in the data frame
df_photos = df_photos[['photo_id', 'photo_image_url']]
# add a new column 'photo_embed' to the data frame
df_photos['photo_embed'] = None
# download the images and extract their embeddings using the 'extract_image_features' function
fori, row intqdm(df_photos.iterrows(), total=len(df_photos)):
# construct a URL to download an image with a smaller size by modifying the image URL
url = row['photo_image_url'] + "?q=75&fm=jpg&w=200&fit=max"
try:
res = requests.get(url, stream=True).raw
image = Image.open(res)
except:
# remove photo if image download fails
photo_ids.remove(row['photo_id'])
continue
# extract feature embedding
df_photos.at[i, 'photo_embed'] = extract_image_features(image)//创建数据集
声明两个数据框,一个带有嵌入的照片信息,另一个用于转换信息。
df_photos = df_photos[df_photos['photo_id'].isin(photo_ids)].reset_index().rename(columns={'index': 'id'})
df_conversions = df_conversions[df_conversions['photo_id'].isin(photo_ids)].reset_index(drop=True)
df_conversions = df_conversions[['photo_id', 'keyword']].reset_index().rename(columns={'index': 'id'})最后将数据帧转化为parquet文件
importpyarrow aspa
importpyarrow.parquet aspq
importnumpy asnp
# create a Table object from the data and schema
photos_table = pa.Table.from_pandas(df_photos)
conversion_table = pa.Table.from_pandas(df_conversions)
# write the table to a Parquet file
pq.write_table(photos_table, 'photos.parquet')
pq.write_table(conversion_table, 'conversions.parquet')(三)将数据填充到MYSCALE数据库
前面讲到我们可以跳过构建数据集这一步骤,下载已经处理完成的数据集 "https://datasets-server.huggingface.co/splits?dataset=myscale%2Funsplash-examples"
//创建表
在 MyScale 中创建两个表,一个用于照片信息,另一个用于转换信息。
importclickhouse_connect
# initialize client
client = clickhouse_connect.get_client(host='YOUR_CLUSTER_HOST', port=8443, username='YOUR_USERNAME', password='YOUR_CLUSTER_PASSWORD')
# drop table if existed
client.command("DROP TABLE IF EXISTS default.myscale_photos")
client.command("DROP TABLE IF EXISTS default.myscale_conversions")
# create table for photos
client.command("""
CREATE TABLE default.myscale_photos
(
id UInt64,
photo_id String,
photo_image_url String,
photo_embed Array(Float32),
CONSTRAINT vector_len CHECK length(photo_embed) = 512
)
ORDER BY id
""")
# create table for conversions
client.command("""
CREATE TABLE default.myscale_conversions
(
id UInt64,
photo_id String,
keyword String
)
ORDER BY id
""")上传数据
fromdatasets importload_dataset
photos = load_dataset("myscale/unsplash-examples", data_files="photos-all.parquet", split="train")
conversions = load_dataset("myscale/unsplash-examples", data_files="conversions-all.parquet", split="train")
# transform datasets to panda Dataframe
photo_df = photos.to_pandas()
conversion_df = conversions.to_pandas()
# convert photo_embed from np array to list
photo_df['photo_embed'] = photo_df['photo_embed'].apply(lambdax: x.tolist())
# initialize client
client = clickhouse_connect.get_client(host='YOUR_CLUSTER_HOST', port=8443, username='YOUR_USERNAME', password='YOUR_CLUSTER_PASSWORD')
# upload data from datasets
client.insert("default.myscale_photos", photo_df.to_records(index=False).tolist(),
column_names=photo_df.columns.tolist())
client.insert("default.myscale_conversions", conversion_df.to_records(index=False).tolist(),
column_names=conversion_df.columns.tolist())
# check count of inserted data
print(f"photos count: {client.command('SELECT count(*) FROM default.myscale_photos')}")
print(f"conversions count: {client.command('SELECT count(*) FROM default.myscale_conversions')}")
# create vector index with cosine
client.command("""
ALTER TABLE default.myscale_photos
ADD VECTOR INDEX photo_embed_index photo_embed
TYPE MSTG
('metric_type=Cosine')
""")
# check the status of the vector index, make sure vector index is ready with 'Built' status
get_index_status="SELECT status FROM system.vector_indices WHERE name='photo_embed_index'"
print(f"index build status: {client.command(get_index_status)}")基于本地指定的图片查找前K个相似的图像(当前k=10)
fromdatasets importload_dataset
importclickhouse_connect
importrequests
importmatplotlib.pyplot asplt
fromPIL importImage
fromio importBytesIO
importtorch
fromtransformers importCLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained(r'C:\Users\16439\Desktop\clip-vit-base-patch32')
processor = CLIPProcessor.from_pretrained(r"C:\Users\16439\Desktop\clip-vit-base-patch32")
client = clickhouse_connect.get_client(
host='msc-cab0c439.us-east-1.aws.myscale.com',
port=8443,
username='chenzmn',
password='#隐藏'
)
defshow_search(image_embed):
# download image with its url
defdownload(url):
response = requests.get(url)
returnImage.open(BytesIO(response.content))
# define a method to display an online image with a URL
defshow_image(url, title=None):
img = download(url)
fig = plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.show()
# query the database to find the top K similar images to the given image
top_k = 10
results = client.query(f"""
SELECT photo_id, photo_image_url, distance(photo_embed, {image_embed}) as dist
FROM default.myscale_photos
ORDER BY dist
LIMIT {top_k}
""")
# WHERE photo_id != '{target_image_id}'
# download the images and add them to a list
images_url = []
forr inresults.named_results():
# construct a URL to download an image with a smaller size by modifying the image URL
url = r['photo_image_url'] + "?q=75&fm=jpg&w=200&fit=max"
images_url.append(download(url))
# display candidate images
print("Loading candidate images...")
forrow inrange(int(top_k / 5)):
fig, axs = plt.subplots(1, 5, figsize=(20, 4))
fori, img inenumerate(images_url[row * 5:row * 5+ 5]):
axs[i % 5].imshow(img)
plt.show()
defextract_image_features(image):
inputs = processor(images=image, return_tensors="pt")
withtorch.no_grad():
outputs = model.get_image_features(**inputs)
outputs = outputs / outputs.norm(dim=-1, keepdim=True)
returnoutputs.squeeze(0).tolist()
if__name__ == '__main__':
image = Image.open(r'C:\Users\16439\Desktop\OIP-C.jpg')
target_image_embed = extract_image_features(image)
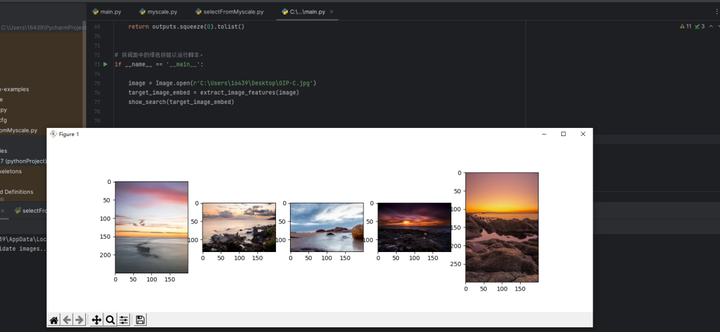
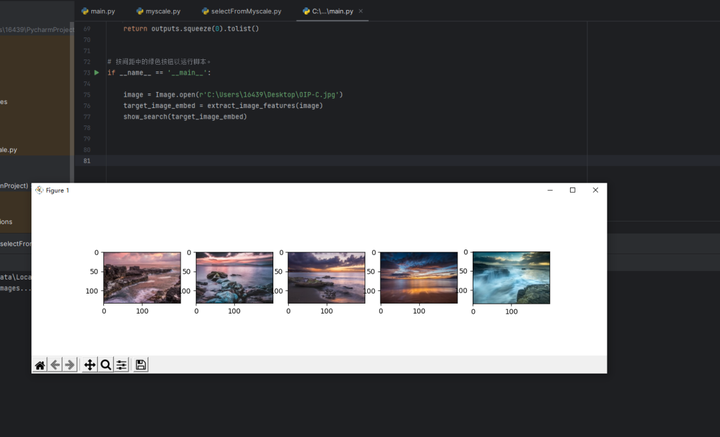
show_search(target_image_embed)我本地的一张图片:

找到的10张最相似的图片:
这就是全部的演示效果了,感兴趣的朋友也可以自己尝试一下。
作者:陈卓敏 | 后端开发工程师
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,了解更多AI相关技术干货。