一般的深度学习项目,训练时为了加快速度,会使用多GPU分布式训练。但在部署推理时,为了降低成本,往往使用单个GPU机器甚至嵌入式平台(比如 NVIDIA Jetson)进行部署,部署端也要有与训练时相同的深度学习环境,如caffe,TensorFlow等。由于训练的网络模型可能会很大(比如inception,resnet等),参数很多,而且部署端的机器性能存在差异,就会导致推理速度慢,延迟高。这对于那些高实时性的应用场合是致命的,比如自动驾驶要求实时目标检测,目标追踪等。所以为了提高部署推理的速度,出现了很多轻量级神经网络,比如squeezenet,mobilenet,shufflenet等。基本做法都是基于现有的经典模型提出一种新的模型结构,然后用这些改造过的模型重新训练,再重新部署。而tensorRT 则是对训练好的模型进行优化。 tensorRT就只是推理优化器。当你的网络训练完之后,可以将训练模型文件直接丢进tensorRT中,而不再需要依赖深度学习框架(Caffe,TensorFlow等),如下:

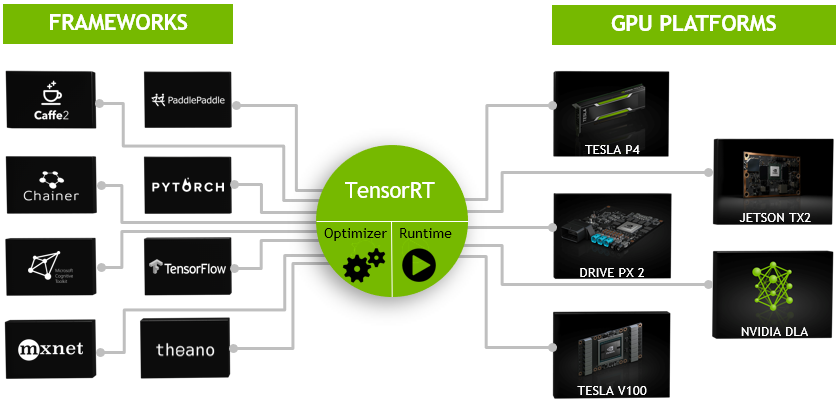
可以认为tensorRT是一个只有前向传播的深度学习框架,这个框架可以将 Caffe,TensorFlow的网络模型解析,然后与tensorRT中对应的层进行一一映射,把其他框架的模型统一全部 转换到tensorRT中,然后在tensorRT中可以针对NVIDIA自家GPU实施优化策略,并进行部署加速。如果想了解更多关于tensorrt的介绍,可参考官网介绍。
一、安装
Installation Guide :: NVIDIA Deep Learning TensorRT Documentation
【精选】TensorRT安装及使用教程-CSDN博客
首先查看电脑是否正常安装cuda以及对应的版本,至于cuda的安装可以查看《ubuntn16.04+cuda9.0+cudnn7.5小白安装教程》,接下来去nvidia官网下载对应的tensorrt安装
包。常见的有两种安装方式:
(1)deb格式文件下载
sudo dpkg -i nv-tensorrt-local-repo-{tag}_1.0-1_amd64.deb
sudo cp /var/nv-tensorrt-local-repo-{tag}/*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get install tensorrt上面的tag号替换成自己下载的版本信息,等install安装结束,输入命令:dpkg -l | grep TensorRT如果显示如下图有关tensorrt的信息,说明tensorrt的c++版本安装成功:

(2)tar下载完成后,进行如下步骤安装
##安装依赖库
pip install pucuda -i https://pypi.douban.com/simple
#在home下新建文件夹,命名为tensorrt_tar,然后将下载的压缩文件拷贝进来解压
tar -xzvf TensorRT-7.0.0.11.Ubuntu-18.04.x86_64-gnu.cuda-10.0.cudnn7.6.tar.gz
#解压得到TensorRT-5.0.2.6的文件夹,将里边的lib绝对路径添加到环境变量中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/lthpc/tensorrt_tar/TensorRT-7.0.0.11/lib
#安装TensorRT
cd TensorRT-7.0.0.11/python
pip install tensorrt-7.0.0.11-cp37-none-linux_x86_64.whl
#安装UFF
cd TensorRT-5.0.2.6/uff
pip install uff-0.6.5-py2.py3-none-any.whl
#安装graphsurgeon
cd TensorRT-5.0.2.6/graphsurgeon
pip install graphsurgeon-0.4.1-py2.py3-none-any.whl当一切正常安装结束,在终端下输入python -c "import tensorrt as trt"不报错即表示安装成功。
需要注意的一点就是,TensorRT与Opset版本之间的匹配关系取决于TensorRT的发行版本。TensorRT的每个版本通常支持一组特定的Opset版本,这些Opset版本与不同的深度学习框架和模型格式相关联。
以下是TensorRT的一些主要版本以及它们通常支持的Opset版本:
-
TensorRT 7.0:
- 支持Opset 9和Opset 10。
-
TensorRT 8.0:
- 支持Opset 11。
请注意,这只是一些示例,实际支持的Opset版本可能因TensorRT的更新和不同发行版本而有所变化。您应该查阅TensorRT的官方文档或相应的发行说明,以获取特定版本的详细信息,包括支持的Opset版本。此外,确保您的模型与您使用的TensorRT版本兼容,以获得最佳性能和准确性。如果您使用的是深度学习框架(如TensorFlow、PyTorch等),还需要确保导出模型时使用了TensorRT支持的Opset版本。
二、tensorrt使用分析
TensorRT使用笔记-CSDN博客
TensorRT整个过程可以分三个步骤,即模型的解析(Parser),Engine优化和执行(Execution)。
》模型的解析(Parser)
目前TensorRT支持两种输入方式:
- 一种是Parser的方式。
Parser是模型解析器,输入一个caffe的模型,或者onnx模型,或者TensorFlow转换成的uff模型,可以解析出其中的网络层及网络层之间的连接关系,然后将其输入到TensorRT中。 - API接口可以添加一个convolution或pooling。将Parser解析出来的模型文件,使用API添加到TensorRT中构建网络。
Parser目前有三个:
- 一个是caffe Parser,这个是最古老的也是支持最完善的;
- 另一个是uff,这个是NV定义的网络模型的一种文件结构,现在TensorFlow可以直接转成uff;
- 另外版本3.5或4.0支持的onnx。
目前API支持两种接口实现方式:
- C++
- Python
补:如果有一个网络层不支持?
这个有可能,TensorRT只支持主流的操作,比如说一个神经网络专家开发了一个新的网络层,TensorRT是不知道是做什么的。这个时候涉及到customer layer的功能,即用户自定义层,构建用户自定义层需要告诉TensorRT该层的连接关系和实现方式,这样TensorRT才能去做。
模型解析后,engine会进行优化,得到优化好的engine可以序列化到内存(buffer)或文件(file),读的时候需要反序列化,将其变成engine以供使用。然后在执行的时候创建context,主要是分配预先的资源,engine加context就可以做推断(Inference)。
TensorRT所做的优化?
第一,也是最重要的,它把一些网络层进行了合并。
第二,取消不需要的层,比如concat这一层。
第三,Kernel可以自动选择最合适的算法。
第四,不同的batch size会做tuning。
第五,对硬件做优化。
总结TensorRT的优点
- TensorRT是一个高性能的深度学习推断(Inference)的优化器和运行的引擎;
- TensorRT支持Plugin,对于不支持的层,用户可以通过Plugin来支持自定义创建;
- TensorRT使用低精度的技术获得相对于FP32二到三倍的加速,用户只需要通过相应的代码来实现。
同时附上几个常用的接口,
Network Definition (高阶用法)
网络定义接口提供方法来指定网络的定义。我们可以指定输入输出的Tensor Name以及增加layer。我们可以通过自定义来扩展TensorRT不支持的层和功能。关于网络定义的API,请查看Network Definition API.
Builder
Builder接口让我们可以从一个网络定义中创建一个优化后的引擎。在这个步骤我们可以选择最大batch,workspace size,精度级别等参数,如果你想了解更多,请查看Builder API.
Engine
引擎接口就允许应用来执行推理了。它支持对引擎输入和输出的绑定进行同步和异步执行、分析、枚举和查询。
It supports synchronous and asynchronous execution, profiling, and
enumeration and querying of the bindings for the engine inputs and
outputs.
此外,引擎接口还允许单个引擎拥有多个执行上下文(execution contexts). 这可以让一个引擎同时对多组数据进行执行推理操作。如想了解更多,请查Execution API.
此外,TensorRT还提供了解析训练模型并创建TensorRT内部支持的模型定义的parser:
- Caffe Parser
This parser can be used to parse a Caffe network created in BVLC Caffe
or NVCaffe 0.16. It also provides the ability to register a plugin
factory for custom layers. For more details on the C++ Caffe Parser,
see NvCaffeParser or the Python Caffe Parser.
- UFF Parser
This parser can be used to parse a network in UFF format. It also
provides the ability to register a plugin factory and pass field
attributes for custom layers. For more details on the C++ UFF Parser,
see NvUffParser or the Python UFF Parser.
- ONNX Parser
This parser can be used to parse an ONNX model. For more details on
the C++ ONNX Parser, see NvONNXParser or the Python ONNX Parser.
Restriction: Since the ONNX format is quickly developing, you may
encounter a version mismatch between the model version and the parser
version. The ONNX Parser shipped with TensorRT 5.1.x supports ONNX IR
(Intermediate Representation) version 0.0.3, opset version 9.
三、tensorrt测试
python:TensorRT学习笔记3 - 运行sampleMNIST-CSDN博客
c++:tensorRT学习笔记 C++version
使用TensorRT进行模型推理加速的工作流(Workflow)可以分为以下几个步骤:
- ① 训练神经网络,得到模型。(以Tensorflow为例,我们得到
xx.pb格式的模型文件) - ② 将模型用TensorRT提供的工具进行parsing(解析)。
- ③ 将parsing后的结构通过TensorRT内部的优化选项(optimization options)对计算图结构进行优化。(包括不限于:1. 算子融合 Layer Funsion: 通过将Conv + BN等层的融合降低数据的吞吐量。 2. 精度校准 Precision Calibration : 当用户为了节省计算资源使用INT8进行推理的时候,需要作精度校准,这个操作TensorRT提供了官方的支持。 3. kernel auto-tuning : 根据计算逻辑,自动选择TensorRT实现的更高效的矩阵乘法,卷积运算等逻辑。)
- ④ 通过上述步骤,得到了一个优化后的推理引擎。我们就可以拿这个引擎进行推理了~
》针对tensorflow模型,先将pb模型转化为uff格式,进入到uff包的安装路径,转化命令如下
python convert_to_uff.py xxx.pb参考链接:
1、https://arleyzhang.github.io/articles/7f4b25ce/
2、使用NVIDIA 免费工具TENSORRT 加速推理实践--YOLOV3目标检测_使用tensorrt 加速yolov3-CSDN博客
3、https://www.cnblogs.com/shouhuxianjian/p/10550262.html
4、TensorRT/YoloV3 - eLinux.org
5、yolov3 with tensorRT on NVIDIA Jetson Nano
6、使用NVIDIA 免费工具TENSORRT 加速推理实践--YOLOV3目标检测_使用tensorrt 加速yolov3-CSDN博客
7、https://blog.csdn.net/weixin_43842032/article/details/85336940(tensorrt 安装和对tensorflow模型做推理,附python3.6解决方案)
8、https://blog.csdn.net/qq_36124767/article/details/68484092(tensorRT学习笔记)
9、https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/parsers/Uff/pyUff.html(TensorRT 5.1.5.0 Python文档)








![[MoeCTF 2023]——Web方向详细Write up、Re、Misc、Crypto部分Writeup](https://img-blog.csdnimg.cn/img_convert/cad28ac1bc173d2d62c40e4312b1d361.png)