前序文章请看:
从裸机启动开始运行一个C++程序(十)
从裸机启动开始运行一个C++程序(九)
从裸机启动开始运行一个C++程序(八)
从裸机启动开始运行一个C++程序(七)
从裸机启动开始运行一个C++程序(六)
从裸机启动开始运行一个C++程序(五)
从裸机启动开始运行一个C++程序(四)
从裸机启动开始运行一个C++程序(三)
从裸机启动开始运行一个C++程序(二)
从裸机启动开始运行一个C++程序(一)
Hello, C World!
我们虽然已经成功驱动C语言代码了,但仅仅是通过bochs断点来看看出入栈那也未免太无聊了,咱们肯定是希望能用C语言来写功能的。
我相信很多读者应该跟我一样,第一反应就是写个Hello, World!,但当前我们在内核态上运行程序,这个过程会复杂很多。标准库中的printf函数是要依赖OS所提供的stdout接口的,只有这样程序才能知道要把需要输出的数据送到哪里,OS也才能通过控制台来显式。而现在咱们什么都没,所以只能自己来实现文字输出。
虽然没人给我们提供stdout,但咱们是在内核态呀!是可以直接写显存的呀!咱们直接给显存里写数据,不就可以达到输出字符的功能了吗?
思路有了,接下来我们需要确定细节。之前已经尝试了局部变量,编译器会按照栈空间的方式来处理,也就是取决于进入函数之前ss和esp的值。可现在咱们要操作显存,这是一个固定的内存地址,这如何操作呢?我们来做个实验,看看下面的程序会如何编译:
void Entry() {
unsigned char *p = (unsigned char *)0xb8000; // 尝试定义一个指针
*p = 0x40; // 看看这个值究竟会写到哪里
}
上面我们定义了一个指针,值是0xb8000,那么这样做能否让他真的指向现存呢?咱们用-S参数来把它编译成汇编看看结果(省略无关内容):
_Entry:
push ebp
mov ebp, esp
push eax
mov eax, 753664
mov dword ptr [ebp - 4], eax
mov eax, dword ptr [ebp - 4]
mov byte ptr [eax], 64 ; 重点关注这一行
add esp, 4
pop ebp
ret
可以看到,ebp - 4就是这个变量p的位置,由于是栈寄存器,所以默认取的是ss段,也就是说p的实际地址是ss:ebp-4。我们之前配置好了ss寄存器,所以这里没有问题。
但后面,解指针操作*p = 0x40这一步,我们看到首先从ebp-4的位置读取数据到eax中,然后直接操作eax取址来写数据。但eax是通用寄存器,它的默认段是ds段,也就是说,mov byte [eax], 64其实是mov byte [ds:eax], 64。
因此我们得出结论:指针的值,是ds段对应的偏移地址,而并非实际的物理地址。
了解了这个就好办了,在进入Entry函数之前,我们只要把ds配置成显存段即可,这样进入Entry后,指针的值就是显存段的偏移地址。
[bits 32]
section .text
begin:
mov ax, 00011_00_0b ; 选择3号段,数据段
mov ss, ax
mov eax, 0x1000
mov esp, eax ; 设置初始栈顶
mov ebp, eax ; ebp也记录初始栈顶
; 把ds配成显存段
mov ax, 00010_00_0b
mov ds, ax
; 进入Entry后,指针的偏移地址就是相对0xb8000的
extern Entry
call Entry
hlt
然后我们尝试在Entry()中操作显存:
void Entry() {
unsigned char *p = (unsigned char *)0x0; // 指向显存首地址
*p = 'H';
p[1] = 0x0f; // 黑底白色
p[2] = 'i';
p[3] = 0x0f;
}
咱们构建并运行一下,看看效果:
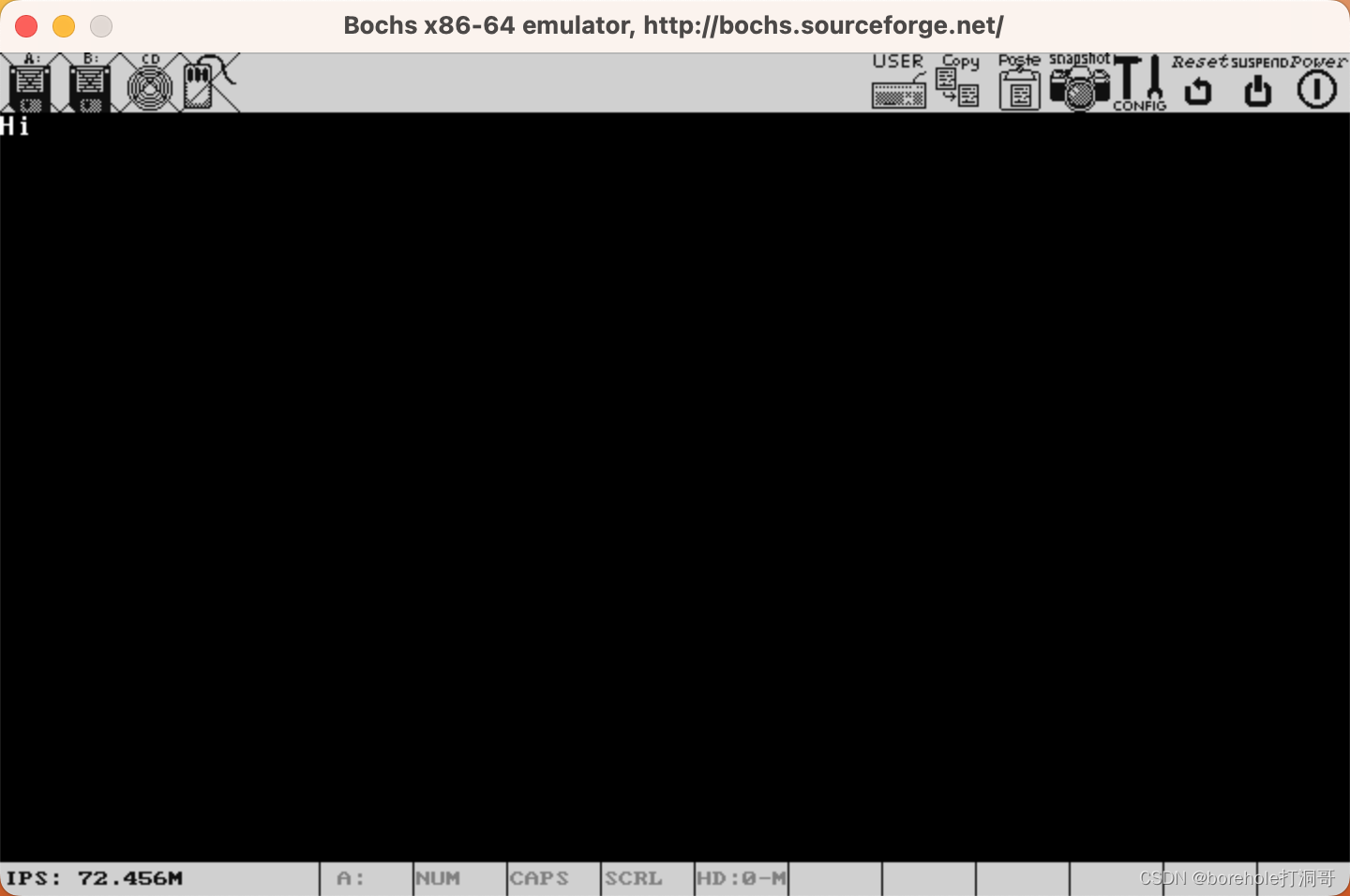
没问题!确实可以这么搞。
不过先别急着去封装putchar,这样做是有个潜在问题的,请看下面示例:
void Entry() {
int a = 5;
int *p = &a;
*p = 10; // 这一步会不会有问题呢?
}
既然我们已经知道,指针的值是相对于ds段的偏移地址了,那我们对局部变量取地址取到的是什么?是ds段的还是ss段的呢?还是,编译成汇编看看结果就很清晰了:
_Entry:
push ebp
mov ebp, esp
sub esp, 8
mov dword ptr [ebp - 4], 5 ; int a = 5;
lea eax, [ebp - 4] ; 注意看这一句
mov dword ptr [ebp - 8], eax
mov eax, dword ptr [ebp - 8]
mov dword ptr [eax], 10 ; 解指针时仍然是用ds:eax
add esp, 8
pop ebp
ret
再次解释一下这里的lea命令,这个就是取地址命令,也就是取[ebp-4]的地址,其实等价于我们理解的mov eax, ebp-4,但是因为没有这个汇编指令,所以必须写成lea eax, [ebp-4]。而因为这里是ebp,所以它匹配的段是ss。
那么这样就出现了一个很严重的问题,我们取地址的时候是取的ss段的偏移地址,但是解指针的时候却是ds段的偏移地址。这显然是要出大问题的呀!
为什么会发生这样的现象?其实很容易理解,因为对于C语言来说,我们通常认为,能走到C语言的过程中开始,就应当使用上层程序语言的思路来进行开发了,而不应该到处还在纠结这些底层实现。所以在C语言的世界观中,「栈段」和「数据段」应该是一起的才对,至少在C的语义层面,不应该区分它。
既然如此,我们直接把ds给成显存段就是一个不合理的操作了,我们应当按照C的标准要求,将ds和ss保持一致才对,这样无论是栈空间还是指针的值,都在同一个段中。
可如果我么把ds也配成数据段的话,写显存的需求要怎么办呢?这个问题,咱们还是要回归到C语言的语义本身上来。如果说你并不理解底层显存这件事的话,让你用C语言输出一个字符,你会首先想到什么?肯定是通过putchar函数来完成。而至于这个函数内部怎么实现的,会把这个数据写到哪里,那应该是OS操心的事。
因此,解决方案也就很清晰了,我们要实现类似于putchar的函数来专门进行输出,而不是直接使用显存的偏移地址。不过putchar还存在光标管理、换行等问题,我们稍后再来实现,现在先简单针对「写显存」这件事。
既然在C语言中没法制定段寄存器,那么在制定段写数据的这件事就只能由汇编来实现了,因此,咱们在工程中新建一个文件asm_func.nas,专门用来实现一些C语言无法直接实现的功能,同样地,它也需要参与Kernel的链接过程。
首先,咱们就先做一个最简单的,实现在显存段的制定地址写一个制定的数据这样一个功能,函数原型是:
void SetVMem(long addr, unsigned char data); // 在显存的addr偏移地址出写入data数据
由于addr是表示偏移地址,在32位环境下,偏移地址应该也是32位数据类型,所以这里写了long。(C语言32位环境下long类型是32位的。)
我们之前已经实现过单个参数传递的调用过程,我们知道在call之前会把参数压栈,过程中再通过ebp+8去找到参数。多个参数则是同样的做法,只不过要进行多次压栈。而对于C语言的函数调用有一个规定,就是按照函数声明的逆序进行压栈。对于上面的函数来说就是会先压栈data,然后压栈addr,然后再call SetVMem这样。
另一个要注意的问题是,虽然data是unsigned char类型,只占一个字节,但由于push操作是匹配指令集位宽的,也就是32位,所以它在栈中实际上也会占4个字节的大小。
这样就明确了,ebp+8就是addr,ebp+12就是data(这里注意,先压栈的在上面,data是先压栈的,所以它在更高地址的位置)。我们就可以来实现SetVMem了,下面是asm_func.nas的内容:
[bits 32]
section .text
global SetVMem ; 告诉链接器下面这个标签是外部可用的
SetVMem:
; 现场记录
push ebp
mov ebp, esp
; 过程中用到的寄存器都要先记录
push ebx
push ecx
push edx
mov bx, es ; 用bx记录原本的es,用于后续恢复现场(这里是因为寄存器还够用,如果不够用的话就还是要压栈)
; 把es配成显存段
mov dx, 00010_00_0b
mov es, dx
; 通过参数找到addr和data
mov edx, [ebp+8] ; addr
mov ecx, [ebp+12] ; data
; 通过es加偏移地址来操作显存
mov [es:edx], cl ; 由于data是1字节的,所以其实只有cl是有效数据
; 现场还原
mov es, bx
pop edx
pop ecx
pop ebx
mov esp, ebp
pop ebp
; 回跳
ret
然后我们也将kernal.nas中的段寄存器重新配置:
[bits 32]
section .text
begin:
mov ax, 00011_00_0b ; 选择3号段,数据段
mov ss, ax
; ds要跟ss一致
mov ds, ax
; es也初始化为数据段(防止后续出问题,先初始化)
mov es, ax
; 初始化栈
mov eax, 0x1000
mov esp, eax ; 设置初始栈顶
mov ebp, eax ; ebp也记录初始栈顶
extern Entry
call Entry
hlt
那么,在entry.c中如何调用呢?自然也是通过函数声明了, 不过这里要按照C语言的方式进行声明,下面是修改后的entry.c:
// 函数声明,实现是用汇编的,链接时会匹配
extern void SetVMem(long addr, unsigned char data);
void Entry() {
SetVMem(0, 'H');
SetVMem(1, 0x0f);
SetVMem(2, 'i');
SetVMem(3, 0x0f);
}
记得要把asm_fun.nas的处理也写在makefile中,不然setVMem函数声明了却没有实现,会链接报错的:
.PHONY: all
all: sys
.PHONY: run
run: bochsrc sys
bochs -qf bochsrc
a.img:
rm -f a.img
bximage -q -func=create -hd=4096M $@
sys: a.img mbr.bin kernel_final.bin
dd if=mbr.bin of=a.img conv=notrunc
dd if=kernel_final.bin of=a.img bs=512 seek=1 conv=notrunc
mbr.bin: mbr.nas
nasm mbr.nas -o mbr.bin
kernel.o: kernel.nas
nasm kernel.nas -f elf -o kernel.o
entry.o: entry.c
x86_64-elf-gcc -c -m32 -march=i386 entry.c -o entry.o
asm_func.o: asm_func.nas
nasm asm_func.nas -f elf -o asm_func.o
kernel_final.out: kernel.o entry.o asm_func.o
x86_64-elf-ld -m elf_i386 kernel.o entry.o asm_func.o -o kernel_final.out
kernel_final.bin: kernel_final.out
x86_64-elf-objcopy -I elf32-i386 -S -R ".eh_frame" -R ".comment" -O binary kernel_final.out kernel_final.bin
.PHONY: clean
clean:
-rm -f .DS_Store
-rm -f *.bin
-rm -f *.img
-rm -f *.o
-rm -f *.out
-rm -f *.gas
下面是运行结果:
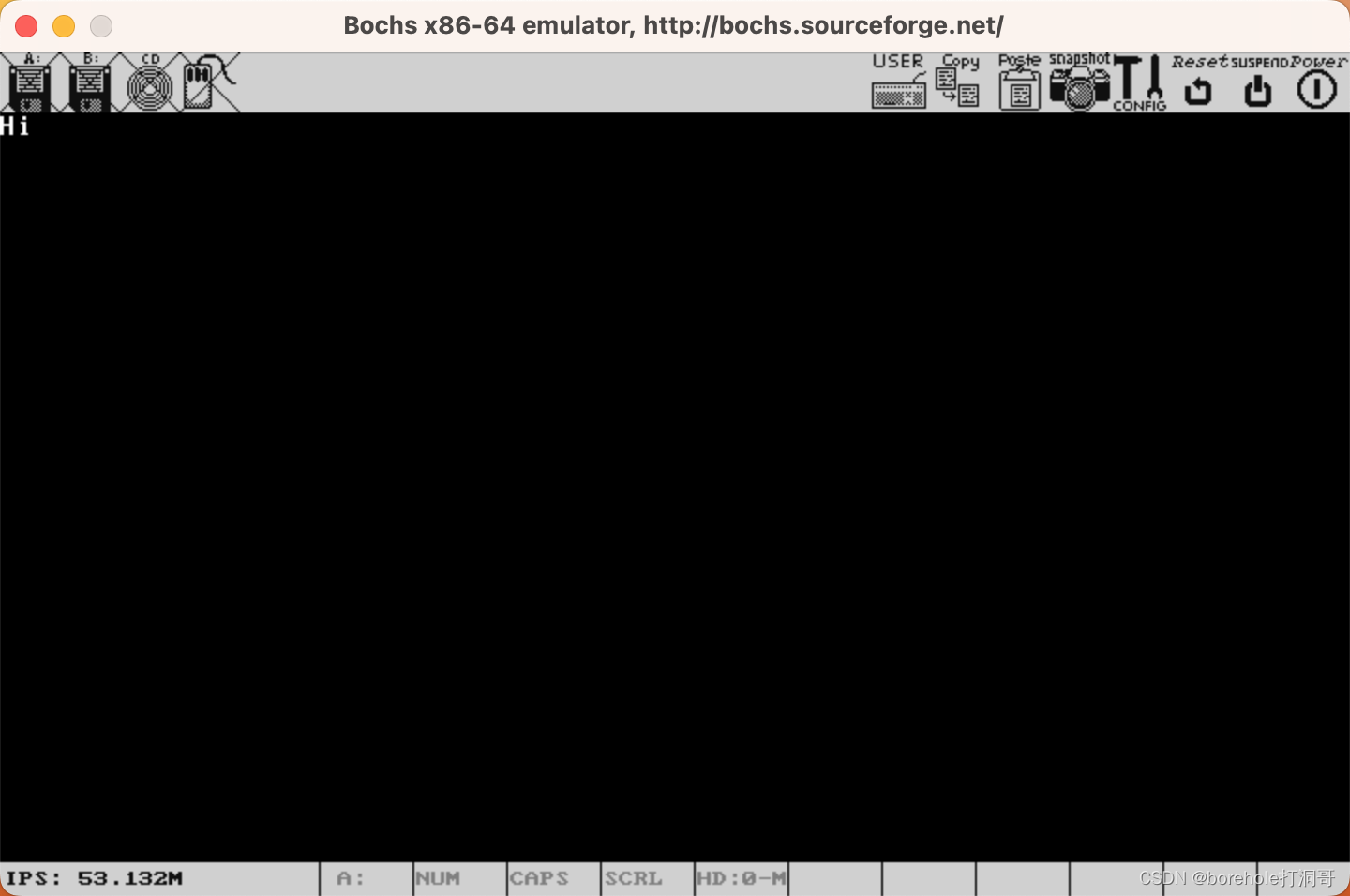
由此,我们实现了C跟汇编的联动,在不去魔改C配置的情况下,用汇编实现局部功能的方式,间接实现了在C中控制显存的功能。
目前的项目工程会我会上传到附件中,作为一个单独目录,读者可以参考。
继续封装一把
现在这种情况,我们调用SetVMem函数来输出着实是有点奇怪了,所以咱们乘胜追击,来封装一个putchar函数。
同样地,我们需要一个全局变量来记录光标信息,不过这次是在C语言上了,难度会低很多:
extern void SetVMem(long addr, unsigned char data);
// 定义光标信息
typedef struct {
long offset; // 暂时只需要一个偏移量
} CursorInfo;
CursorInfo g_cursor_info = {0}; // 全局变量,保存光标信息
// 这里我们按照C标准库中的函数原型来定义
int putchar(int ch) {
if (ch == '\n') { // 处理换行
g_cursor_info.offset += 80 * 2; // 一行是80字符
g_cursor_info.offset -= ((g_cursor_info.offset / 2) % 80) * 2; // 回到行首
} else {
SetVMem(g_cursor_info.offset++, (unsigned char)ch);
SetVMem(g_cursor_info.offset++, 0x0f);
}
return ch;
}
void Entry() {
putchar('H');
putchar('i');
}
看似没有问题,不过如果直接运行的话,你会发现,又触发异常中断了。唉,内核态程序真的好脆弱呀~
原因主要是全局变量的处理上。我们之前已经踩过了栈空间和指针不匹配的坑,现在终于踩到了一个新坑,就是全局变量的坑上。排查问题的思路相同,还是编译成汇编来看,不过因为上面代码稍微有点复杂,我们简化一下,只看全局变量的情况:
int g_value = 5; // 定义全局变量
void Entry() {
g_value = 10;
}
上面这个程序会怎样被编译呢?我们看看结果:
.text
.globl g_value
.data
.align 4
.type g_value, @object
.size g_value, 4
g_value: ; 注意这里,全局变量用的是标签直接表示地址
.long 5
.text
.globl Entry
.type Entry, @function
Entry:
push ebp
mov ebp, esp
mov DWORD PTR g_value, 10 ; 这里也是使用标签来表示地址的。
nop
pop ebp
ret
可以看到,全局变量并不是通过mov指令来存储的,而是随着指令本身,一起加载到了内存中。既然是用标签来表示地址的,按照前面我们编写汇编时的规律,这个标签,将会被翻译为相对于文件的偏移地址。
这是继ss和ds后,出现的第三个偏移地址,相对于文件的偏移地址。注意,当前这个文件是后续要参与链接的,所以事实上它并不是相对于entry.gas的偏移地址,而是相对于kernel_final.bin的位置,请大家一定要明确。既然是当前文件的位置,那自然,它的物理地址取决于实际指令加载的内存位置,而这个内存加载位置确实以cs的段为段基址的。
其实不仅是全局变量,函数指针也会有类似的问题,比如:
void f() {}
void Entry() {
void (*fptr)() = f; // 这里的fptr其实取的是f相对于cs的偏移地址,读者可以自行验证
}
既然如此,我们难道要将ds和ss转换成代码段吗?这显然是不可行的,毕竟代码段只能用来执行,不能用来操作(因为Type字段配置问题)。
虽然我们不应该让ds和ss选择代码段,但我们可以让代码段和数据段的基址相同(大小可以不同)。换言之,由于C语言代码编译后,代码段之间会夹杂很多全局、静态数据在里面,因此,代码段应当作为数据段的一部分,并且他们的首地址相同。当然,数据段可以比代码段长一些。
由此,我们不得不再次回MBR重新配置一下GDT:
; 3号段-数据段(要包含和对其代码段)
; 基址0x8000,大小4MB
mov [es:0x18], word 0x03ff ; Limit=0x400,这是低8位
mov [es:0x1a], word 0x8000 ; Base=0x00008000,这是低16位
mov [es:0x1c], byte 0x0000 ; 这是Base的16~23位
mov [es:0x1d], byte 1_00_1_001_0b ; P=1, DPL=0, S=1, Type=001b, A=0
mov [es:0x1e], byte 1_1_00_0000b ; G=1, D/B=1, AVL=00, Limit的高4位是0000
mov [es:0x1f], byte 0x00 ; 这是Base的高8位
不过这样做马上也能发现一些隐患,比如说数据段的跨度其实包含了显存,而且也包含了GDT的位置。这显然是非常不安全的。
正常的OS肯定不会在MBR中直接加载好所有的配置,MBR只加载一个Boot程序,并进入IA-32模式,然后在这个Boot程序中,再重新读盘,并把真正的Kernel加载到更高地址(至少是大于1MB的部分)去,那么此时再去重新分段就不会出现我们现在这种Kernel只能在前1MB的空间里,于是不得不把段首分在这里的这种情况了。
但目前我们就先这样做吧,把程序跑起来再说。将数据段重新配置后,我们再来尝试一下运行包含了之前entry.c代码的整个工程,看看putchar函数能否如预期那样执行:
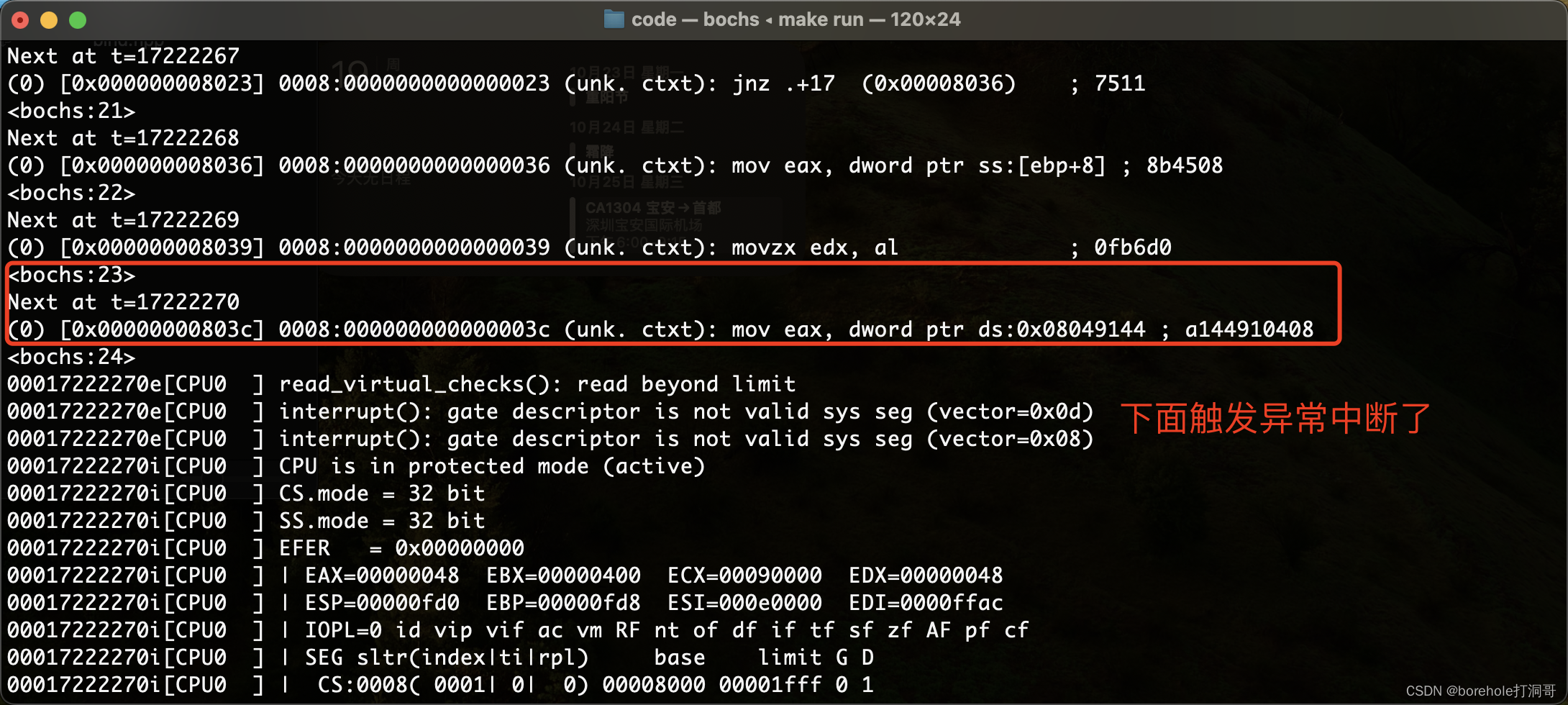
可以看到,在尝试操作全局变量的时候仍然出现了问题,而且这个0x08049144着实是个很奇怪的地址,这是为什么呢?
原因在于,ld在链接时,有一个默认的代码加载偏移地址,这个地址并不是0,所以,相当于代码中所有标签都加上了一个偏移量。
而现在我们需要让他们统一起来,因此要在链接时添加一个参数,指定文件基础偏移量是0,这个参数是-Ttext=0,完整的链接命令如下:
x86_64-elf-ld -m elf_i386 -Ttext=0 kernel.o entry.o asm_func.o -o kernel_final.out
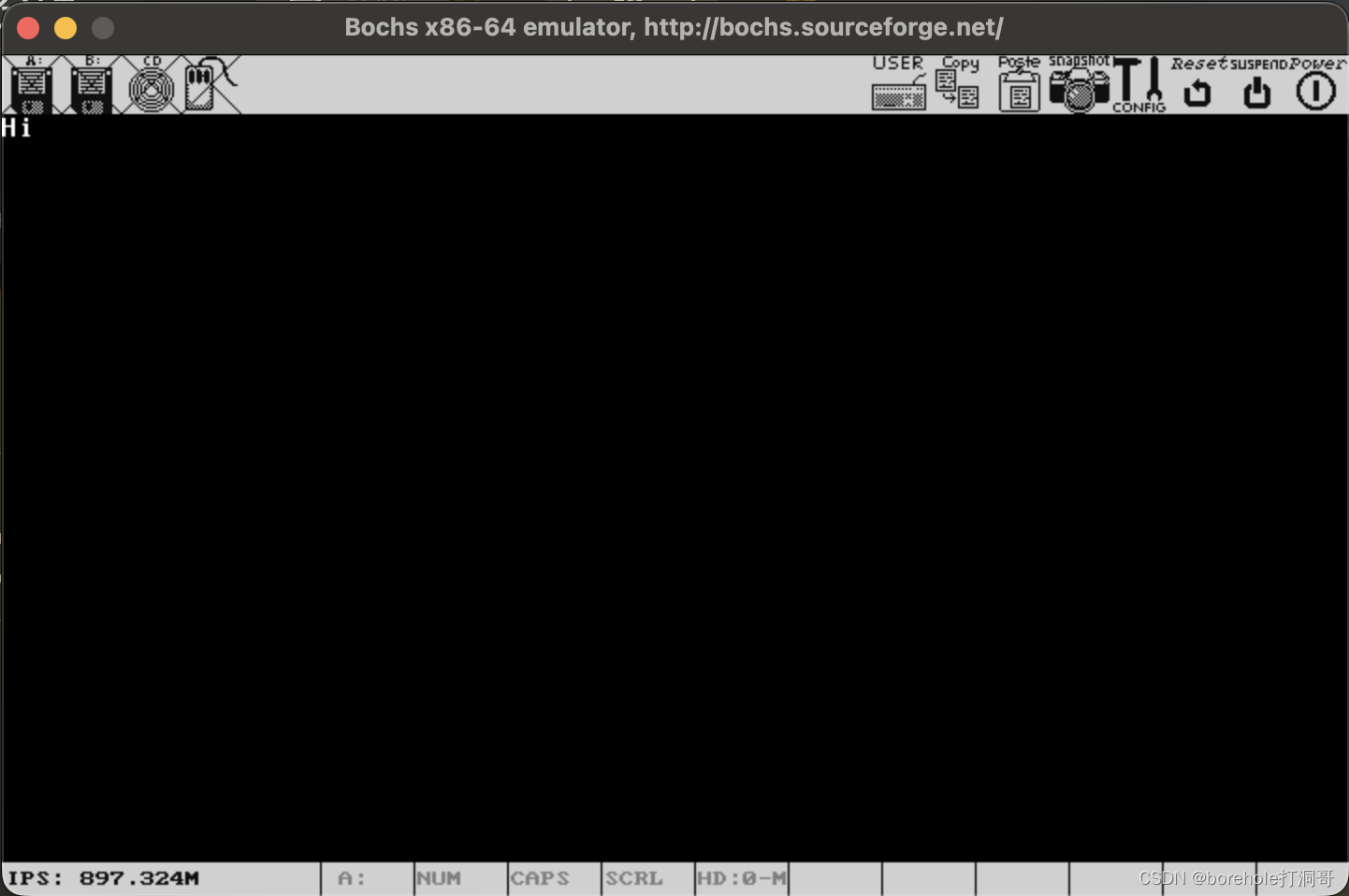
这下再运行,没问题了!
乘胜追击
既然putchar都实现了,我们就再乘胜追击一下,实现一个puts吧,废话不多说,直接上代码:
extern void SetVMem(long addr, unsigned char data);
// 定义光标信息
typedef struct {
long offset; // 暂时只需要一个偏移量
} CursorInfo;
CursorInfo g_cursor_info = {0}; // 全局变量,保存光标信息
int putchar(int ch) {
if (ch == '\n') { // 处理换行
g_cursor_info.offset += 80 * 2; // 一行是80字符
g_cursor_info.offset -= ((g_cursor_info.offset / 2) % 80) * 2; // 回到行首
} else {
SetVMem(g_cursor_info.offset++, (unsigned char)ch);
SetVMem(g_cursor_info.offset++, 0x0f);
}
return ch;
}
int puts(const char *str) {
// 处理C字符串,需要向后找到0结尾,逐一调用putchar
for (const char *p = str; *p != '0'; p++) {
putchar(*p);
}
return 0;
}
void Entry() {
puts("Hello, World!\nThe 2nd line.");
}
运行结果如下:
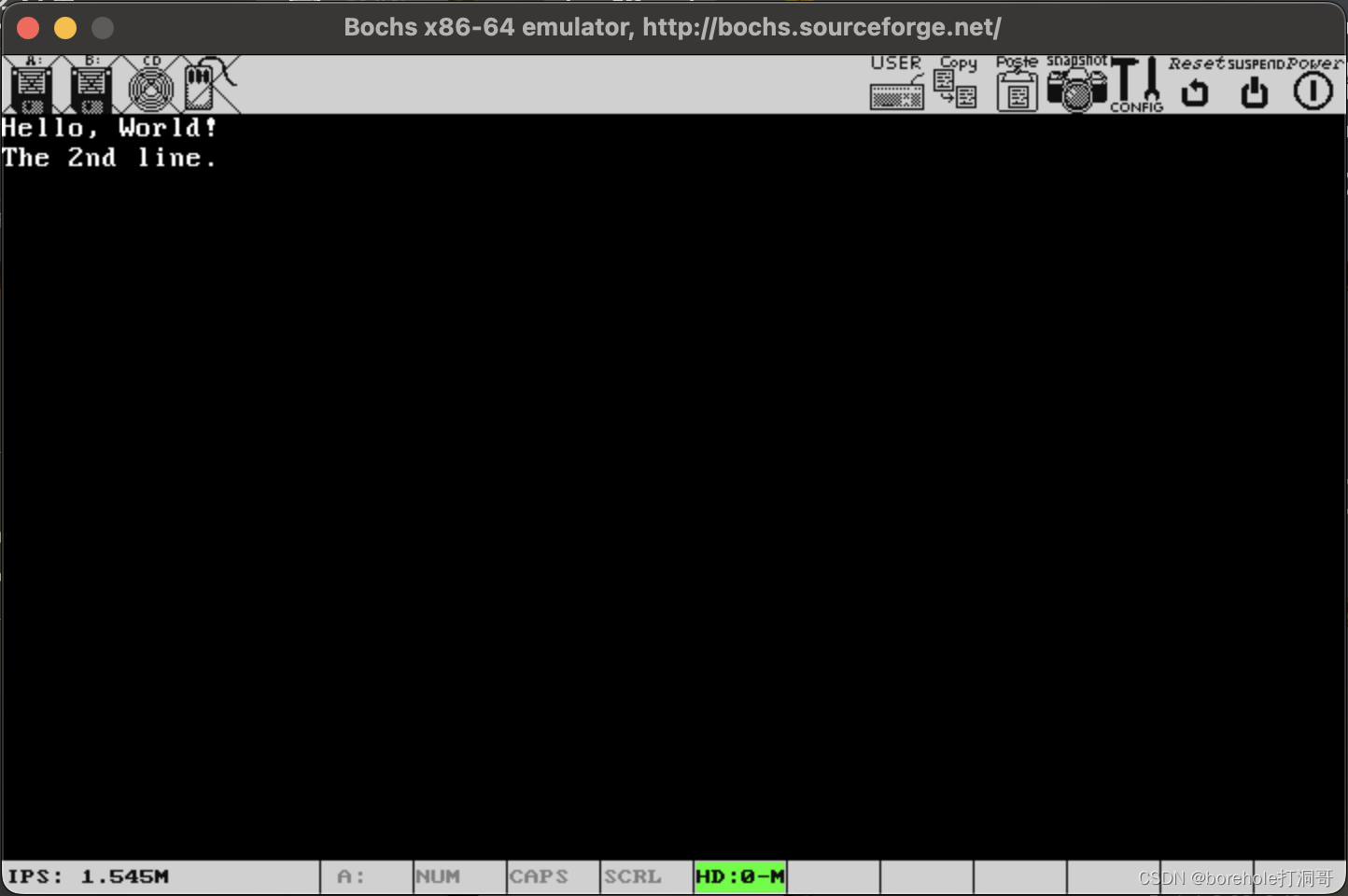
完美!撒花!
小结
本篇我们克服了各种难处,终于用C语言成功输出了Hello, World!,还成功实现了换行。非常不容易!下一篇我们要整理一下当前的工程,并且继续实现一些基础的C能力供后续使用。
本篇的工程代码将会上传至附件,分上下两部分,供读者参考。