🚀🚀 前言 🚀🚀
timm 库实现了最新的几乎所有的具有影响力的视觉模型,它不仅提供了模型的权重,还提供了一个很棒的分布式训练和评估的代码框架,方便后人开发。更难能可贵的是它还在不断地更新迭代新的训练方法,新的视觉模型和优化代码。本章主要介绍如何使用timm替换YOLO系列的主干网络。
🔥🔥 YOLO系列实验实战篇:
📖 YOLOv5/v7/v8改进实验(一)之数据准备篇
📖 YOLOv5/v7/v8改进实验(二)之数据增强篇
📖 YOLOv5/v7/v8改进实验(三)之训练技巧篇
📖 YOLOv5/v7/v8改进实验(五)之使用timm更换YOLOv5模型主干网络Backbone篇
📖 YOLOv5/v7/v8改进实验(七)之使用timm更换YOLOv8模型主干网络Backbone篇
更新中…
目录
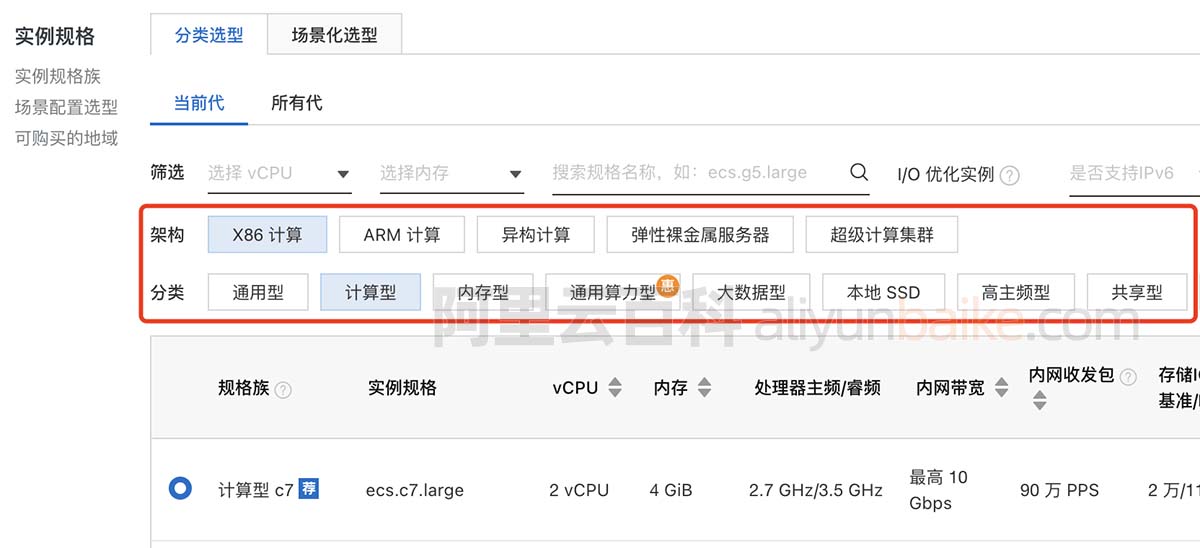
- 一、timm
- 1.1 安装
- 1.2 测试模型库
- 1.3 加载模型
- 二、YOLOv5
- 替换parse_model函数
- 替换BaseModel类中的_forward_once函数
- yolov5s-ghostnet.yaml文件配置
- 模型测试
- 模型训练
一、timm
官方链接:pytorch-image-models
Pytorch Image Models (timm) 整合了常用的models, layers, utilities, optimizers, schedulers, data-loaders / augmentations, and reference training / validation scripts,它的目的是将各种SOTA模型整合在一起,并具有再现ImageNet训练结果的能力。
1.1 安装
timm环境的安装非常简单,pip直接安装即可,版本越高,模型越多。
pip install timm -i https://mirror.baidu.com/pypi/simple
版本更新:
pip install timm --upgrade -i https://mirror.baidu.com/pypi/simple
1.2 测试模型库
安装完成即可查看timm可供我们使用的所有模型。
# timm-0.9.7
import timm
print(timm.list_models())
print(len(timm.list_models())) # 991
# timm-0.6.13
import timm
print(timm.list_models())
print(len(timm.list_models())) # 964
1.3 加载模型
import torch, timm
from thop import clever_format, profile
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dummy_input = torch.randn(1, 3, 640, 640).to(device)
model = timm.create_model('mobileone_s0', pretrained=False, features_only=True)
model.to(device)
model.eval()
print(model.feature_info.channels())
for feature in model(dummy_input):
print(feature.size())
flops, params = profile(model.to(device), (dummy_input,), verbose=False)
params = clever_format(params, "%.3f")
print(f'Total {(flops * 2 / 1E9):.3f} GFLOPS')
print(f'Total {params} params')
PS:其他详细操作可参考官方文档
二、YOLOv5
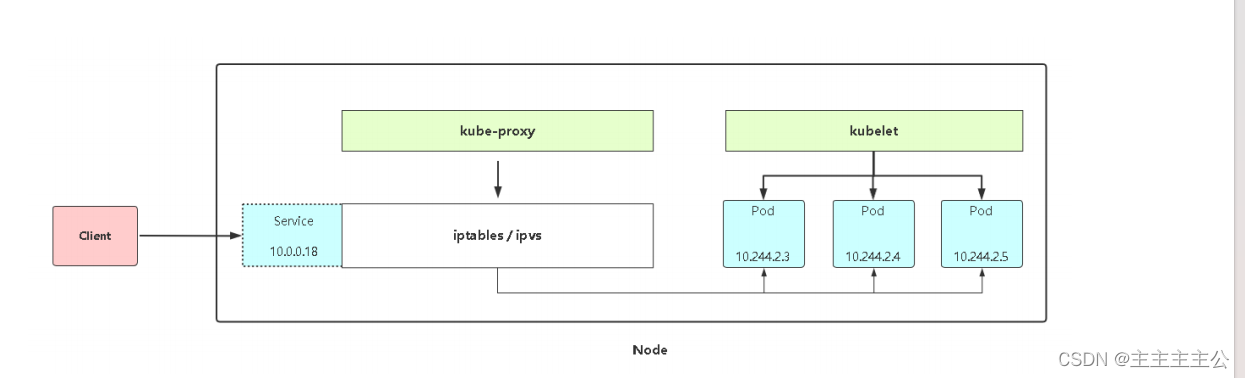
主要修改models/yolo.py文件中的parse_model和_forward_once函数
替换parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
is_backbone = False
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
try:
t = m
m = eval(m) if isinstance(m, str) else m # eval strings
except:
pass
for j, a in enumerate(args):
with contextlib.suppress(NameError):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
args[j] = a
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif isinstance(m, str):
t = m
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
# elif m in {}:
# m = m(*args)
# c2 = m.channel
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
替换BaseModel类中的_forward_once函数
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
y.append(i if i_idx in self.save else None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
yolov5s-ghostnet.yaml文件配置
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, ghostnet_050, []], # 4
[-1, 1, SPPF, [1024, 5]], # 5
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 6
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7
[[-1, 3], 1, Concat, [1]], # cat backbone P4 8
[-1, 3, C3, [512, False]], # 9
[-1, 1, Conv, [256, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11
[[-1, 2], 1, Concat, [1]], # cat backbone P3 12
[-1, 3, C3, [256, False]], # 13 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 14
[[-1, 10], 1, Concat, [1]], # cat head P4 15
[-1, 3, C3, [512, False]], # 16 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 17
[[-1, 5], 1, Concat, [1]], # cat head P5 18
[-1, 3, C3, [1024, False]], # 19 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
模型测试
python models/yolo.py --cfg yolov5s-ghostnet.yaml
模型训练
python train.py --cfg yolov5s-ghostnet.yaml