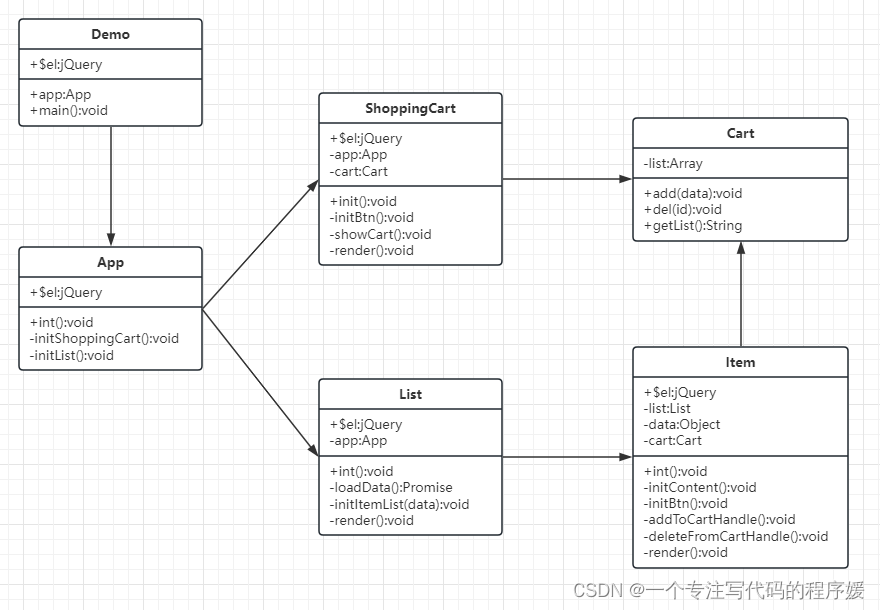
文献copilot:调用文心一言api对论文逐段总结
当我读文献的时候,感觉读得太慢了,看翻译软件翻译的又觉得翻译的不好。于是我就写了个程序辅助我读文献,它可以逐段总结,输出格式是:原文+一句话总结+分段总结,每一段间用分割线分割。下面给大家看看输出结果。


输入
一个.txt文件,这个直接从论文的网页上复制粘贴到记事本里就行。我平常看nature的期刊比较多,nature的绝大多数都可以直接复制,很方便。一个小建议是鼠标通过导航栏,找到reference,然后自下而上选择一直到标题,复制粘贴即可。
大家可以用这个论文练练手:https://www.nature.com/articles/s41587-022-01448-2。
这种方法其实没有那么优雅和便捷,我也想过用爬虫直接爬取,不过一是因为每个期刊网站不一样,不太方便;二是因为爬虫其实会更慢一些。我还想过通过pdf直接转txt或者直接用pdf来进行总结,这个可行,因为像chatdoc就做成功了,而且非常好(不过chatdoc也不能自动化地逐段总结,并且收费,个性化程度不高),但是难度较大,并且我觉得没太大必要,这种方法已经满足我的需求了。
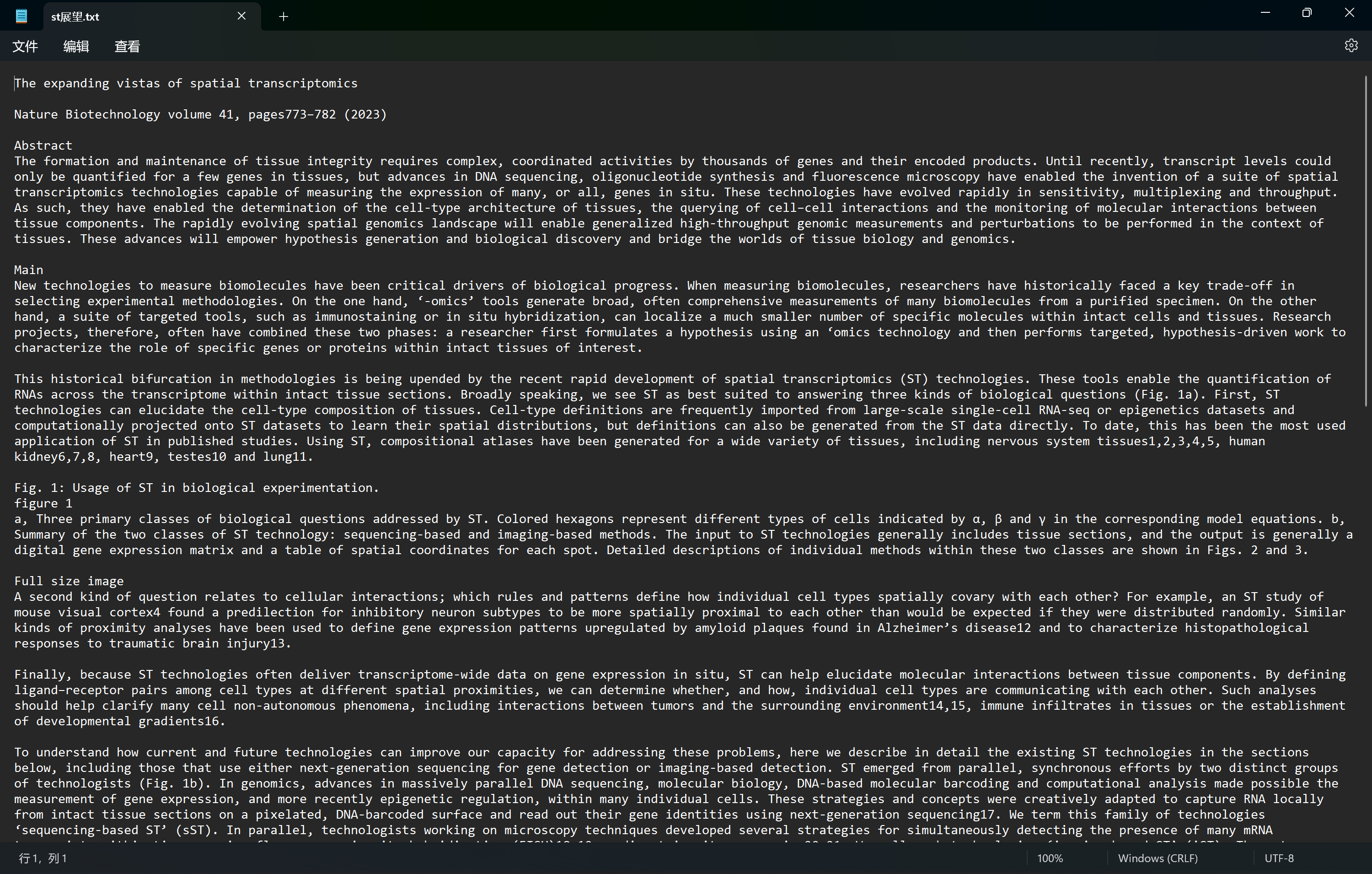
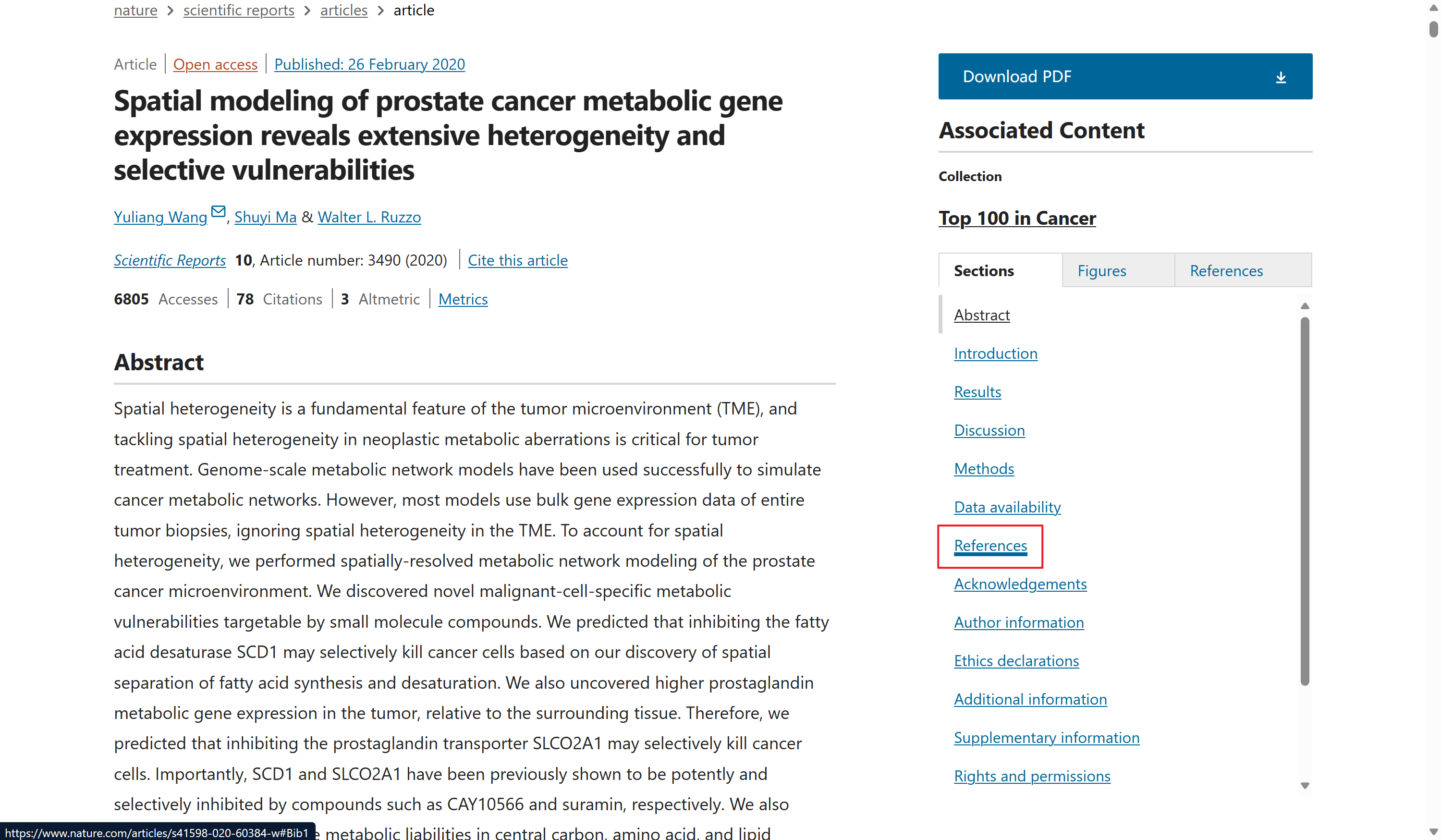
运行方式
首先把输入文件和输出文件的路径确定了:
- filepath:论文.txt所在路径(这个斜杠/,不是这个\)
- outpath:输出路径,可以和filepath一样
大家还需要配置一下文心一言的API_KEY、SECRET_KEY,这个网上教程很多。
import json
import os
import sys
import requests
from tqdm import tqdm
from md_translator import *
# 下面两行是不同的运行方式
filename = sys.argv[1] # 这是用命令行的方式
# 这是在编辑器运行的方式
# filename = "论文名字.txt"
filepath = "D:/"
outpath = "D:/"
# 文心一言的API_KEY、SECRET_KEY
API_KEY = "你的API_KEY"
SECRET_KEY = "你的SECRET_KEY"
编译器内运行
赋值filename为对应的文件名就行,要带后缀。
filename = "论文名字.txt"
然后直接运行即可,会显示一个进度条,结束时会自动打开输出目录。

命令行运行
编译器运行比较麻烦,每次得改文件名,还得点击运行,命令行就方便多了。
直接进到程序的目录,然后改好环境,第二个参数改为文件名即可:
python .\paper_reader.py "论文名字.txt"
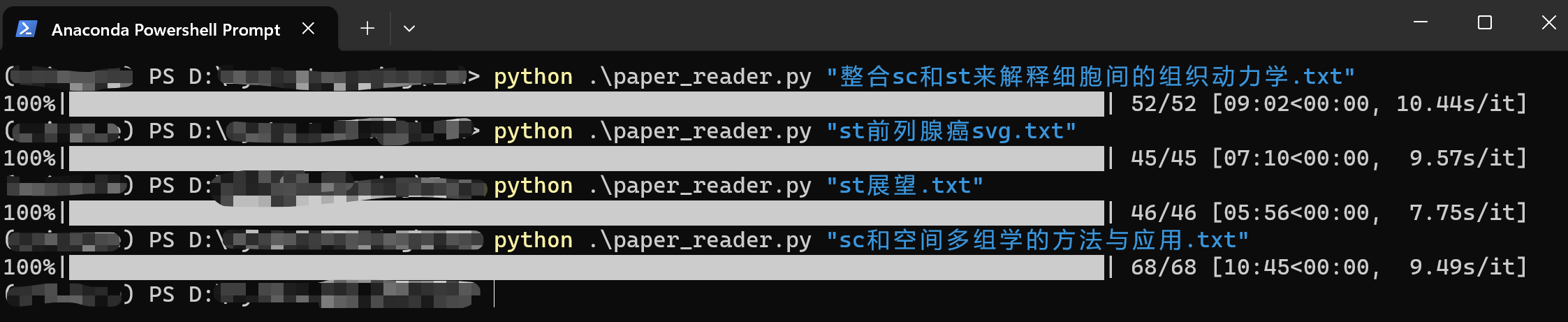
输出结果
会输出一个名为总结-论文名字.md的文件。
第一行大标题,论文名字,接着用分割线来分割每一段,上面是英文,下面是用中文的一句话总结和分段总结。
源代码
paper_reader.py
import json
import os
import sys
import requests
from tqdm import tqdm
from md_translator import *
# 下面两行是不同的运行方式
filename = sys.argv[1] # 这是用命令行的方式
# 这是在编辑器运行的方式
# filename = "论文名字.txt"
filepath = "D:/"
outpath = "D:/"
# 文心一言的API_KEY、SECRET_KEY
API_KEY = "你的API_KEY"
SECRET_KEY = "你的SECRET_KEY"
f = open(outpath + '总结-' + filename.split('.')[0] + '.md', 'w', encoding='utf-8')
old_out = sys.stdout
sys.stdout = f
def ask_Q(question):
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": question
}
]
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response
# print(response.text)
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
# %%
md_origin = md_df(filepath + filename)
# %%
import copy
md_res = copy.deepcopy(md_origin)
for i_zyh in tqdm(range(md_origin.shape[0])):
# for i_zyh in range(1):
try:
if md_origin.loc[i_zyh, 'type'] == 'text':
# Input = '现在你是一个专业翻译家,一个具有生物学背景的生物信息学教授,你的目标是把生物学领域学术论文中的一段翻译成中文。请翻译时不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请注意,提供的段落是markdown格式的,你翻译后需要保留原格式,除了提供给我翻译后的文本,我还需要你分点帮我总结这一段的精要,并且用一句话总结。现在请翻译并总结:' + \
# md_origin.loc[i_zyh, 'content']
Input = '现在你是一个生物学教授,你的目标是把生物学领域学术论文中的一个"自然段(paragraph)"[分点总结],并且用[一句话总结]。请注意,呈现方式为:“一句话总结\n:……;分段总结(用markdown的有序列表格式):1. ……;2. ……;3. ……、……”,现在请总结:' + \
md_origin.loc[i_zyh, 'content']
# Input = '晚上吃什么'
ans = ask_Q(Input)
ans = json.loads(ans.text)
md_res.loc[i_zyh, 'content'] = ans['result']
if i_zyh == 0:
print('# ' + md_origin.loc[i_zyh, 'content'])
else:
print(md_origin.loc[i_zyh, 'content'])
# print("第",i_zyh,"行")
if i_zyh != 0:
print(ans['result'])
# f.write(ans['result'])
print('')
print('------')
else:
# print('------')
print(md_res.loc[i_zyh, 'content'])
print('')
print('------')
# f.write(md_res.loc[i_zyh, 'content'])
except Exception:
print('这一段报错了,不过问题不大')
# 恢复原来的输出流
sys.stdout = old_out
# 关闭文件
f.close()
os.startfile(outpath)
# print('文件输出路径:\n'+outpath + 'out' + filename)
md_translator.py
# 导入所需的库
import pandas as pd
import re
# 定义一个函数,用于读取markdown文件,并按段落分割
def read_markdown(file):
# 打开文件,读取内容
with open(file, 'r', encoding='utf-8') as f:
content = f.read()
# 按换行符分割内容,得到一个列表
lines = content.split('\n')
# 定义一个空列表,用于存储分割后的段落
paragraphs = []
# 定义一个空字符串,用于拼接段落
paragraph = ''
# 遍历每一行
for line in lines:
# 如果是空行,说明段落结束,将拼接好的段落添加到列表中,并清空字符串
if line == '':
if paragraph != '':
paragraphs.append(paragraph)
paragraph = ''
# 如果是代码块的开始或结束标志,也说明段落结束,将拼接好的段落添加到列表中,并清空字符串
elif line.startswith('```'):
if paragraph != '':
paragraphs.append(paragraph)
paragraph = ''
# 将代码块的开始或结束标志也添加到列表中
paragraphs.append(line)
# 如果是图片链接,也说明段落结束,将拼接好的段落添加到列表中,并清空字符串
elif re.match(r'!\[.*\]\(.*\)', line):
if paragraph != '':
paragraphs.append(paragraph)
paragraph = ''
# 将图片链接也添加到列表中
paragraphs.append(line)
# 否则,将当前行拼接到字符串中,并加上换行符
else:
paragraph += line + '\n'
# 如果最后还有未添加的段落,也添加到列表中
if paragraph != '':
paragraphs.append(paragraph)
# 返回分割后的段落列表
return paragraphs
# 定义一个函数,用于识别每个段落的类型(文本、代码、图片)
def identify_type(paragraph):
# 如果是代码块的开始或结束标志,返回'code'
if paragraph.startswith('```'):
return 'code'
# 如果是图片链接,返回'image'
elif re.match(r'!\[.*\]\(.*\)', paragraph):
return 'image'
# 否则,返回'text'
else:
return 'text'
def md_df(filepath):
# 调用read_markdown函数,读取markdown文件,并按段落分割
# paragraphs = read_markdown(filepath + 'data/CellWalkR_Vignette.md')
paragraphs = read_markdown(filepath)
# 创建一个空的dataframe,有两列:'content'和'type'
md_origin = pd.DataFrame(columns=['content', 'type'])
# 遍历每个段落,识别其类型,并添加到dataframe中
for paragraph in paragraphs:
type = identify_type(paragraph)
md_origin = md_origin.append({'content': paragraph, 'type': type}, ignore_index=True)
# 找到第二列等于"code"的行的索引
code_indices = md_origin[md_origin['type'] == 'code'].index.tolist()
# 两个两个地读取索引,并设置这两个索引之间行的第二列为"code"
for i in range(0, len(code_indices), 2):
start_index = code_indices[i]
end_index = code_indices[i + 1] if i + 1 < len(code_indices) else None
# 设置这两个索引之间行的第二列为"code"
md_origin.loc[start_index:end_index - 1, 'type'] = 'code'
# i=0
# codes=[]
# while i < md_origin.shape[0]-2:
# if md_origin.loc[i,'type'] == 'code':
# codes.append(1)
# md_origin.loc[i+1,'type'] = 'code'
# i+=2
# i+=1
# 将DataFrame保存为CSV文件
return md_origin
# md_origin.to_csv('md_df.csv', index=False)

![[云原生1.] Docker容器的简单介绍和基本管理](https://img-blog.csdnimg.cn/f1a8dda389be49a394683fe2d3285c23.png)