Elasticsearch 中自动生成的文档 ID
当你在未指定 ID 的情况下对文档建立索引时,Elasticsearch 会自动为该文档生成唯一的 ID。 该 ID 是 Base64 编码的 UUID,由多个部分组成,每个部分都有特定的用途。

ID 生成过程针对索引速度和存储效率进行了优化。 负责此过程的代码可以在 GitHub 上的 Elasticsearch 的 TimeBasedUUIDGenerator 类中找到。
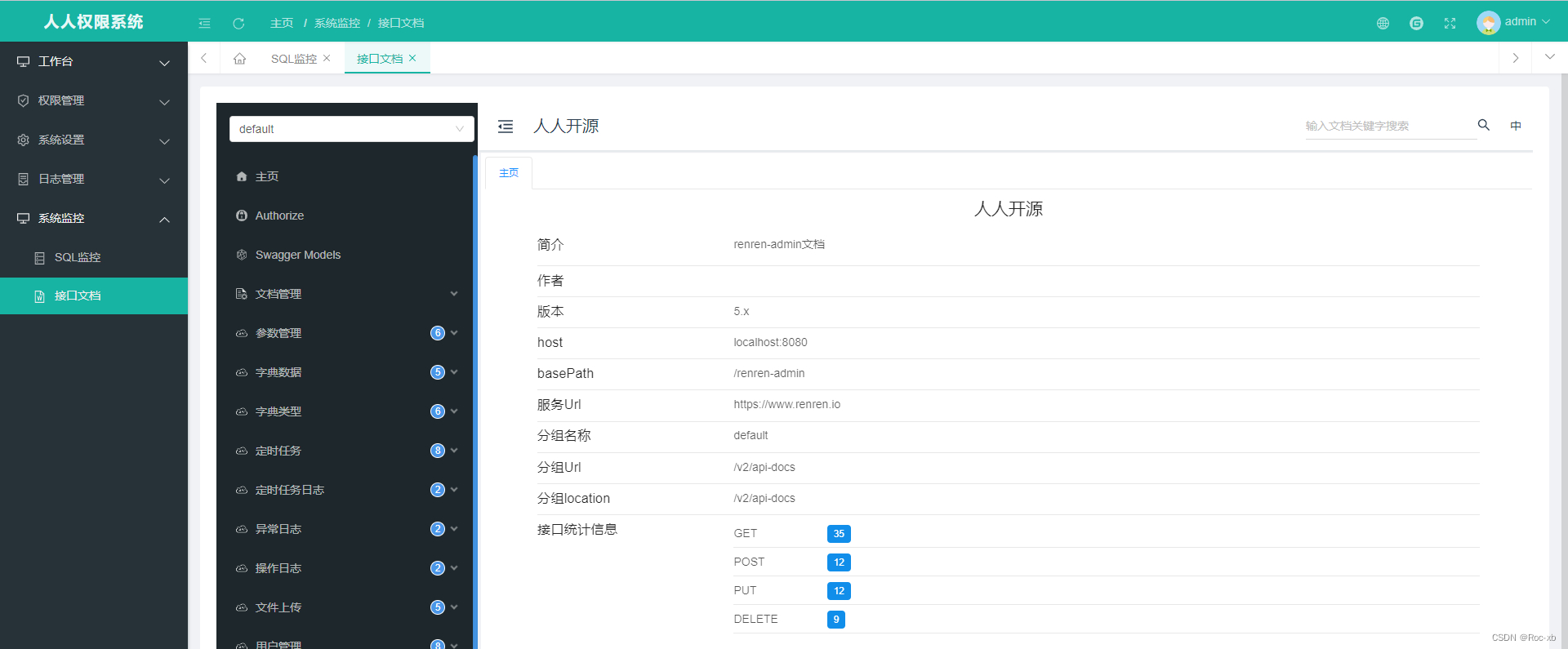
ID 是如何生成的?
ID 的前两个字节源自序列 ID (sequence ID),该 ID 会针对每个索引的文档而递增。 使用序列 ID 的第一和第三字节。 这些字节经常更改,这有助于提高索引速度,因为它使 ID 可以快速排序。
接下来的四个字节来自当前时间戳。 这些字节更改的频率较低,这有助于提高存储效率,因为它可以很好地压缩 ID。 时间戳被移动不同的量来生成这四个字节,这意味着它们以不同的速率变化。
接下来的六个字节是运行 Elasticsearch 的机器的 MAC 地址。 这有助于确保不同机器上 ID 的唯一性。
最后三个字节是时间戳和序列 ID 的剩余字节。 这些字节可能根本没有被压缩。
然后对生成的字节数组进行 Base64 编码以创建最终 ID。 Base64 编码是 URL 安全的,并且不包含填充,这使得 ID 在 URL 中使用安全且存储高效。
碰撞概率
Elasticsearch 为文档生成重复 ID 的概率极低,几乎可以忽略不计。 这是因为 Elasticsearch 使用 UUID(通用唯一标识符)来自动生成 ID。 UUID 是 128 位值,并且被设计为足够随机,因此冲突的概率(即多次生成相同的 UUID)很低。
自动生成的 ID 示例
让我们考虑一个自动生成的 ID 示例:“5PMM3nYBgTGA2v2S6qve”。 此 ID 是 Base64 编码的 UUID。 前两个字节来自序列 ID,接下来的四个字节来自当前时间戳,接下来的六个字节是运行 Elasticsearch 的机器的 MAC 地址,最后三个字节是时间戳的剩余字节和序列 ID。
问答
问:自动生成的 ID 在集群中的所有索引中是否唯一?
答:虽然自动生成的 ID 在索引内是唯一的,但它们在集群中的所有索引中并不是全局唯一的。 如果两个文档在两个不同的索引中具有相同的自动生成 ID,则它们将被视为两个不同的文档。
问:自动生成的 ID 发生冲突的概率是多少?
答:Elasticsearch 为文档生成重复 ID 的概率极低,几乎可以忽略不计。 这是因为 Elasticsearch 使用 UUID 来自动生成 ID,这些 ID 被设计得足够随机,因此冲突的概率极低。
让你了解一下有多低:为了以 50% 的概率发生至少一次碰撞,需要生成的随机版本 4 UUID(这是 Elasticsearch 使用的 UUID 类型)的数量为 2.71 quintillion (2.71 x 1⁰1⁸)。 这个数字是如此之大,即使每秒生成 10 亿个 UUID,生成这么多 UUID 也需要超过 85 年的时间。
问:我们可以不使用自动生成 ID 吗?
答:是可以的。在我们的很多代码中,我们可以这么来生成一个文档:
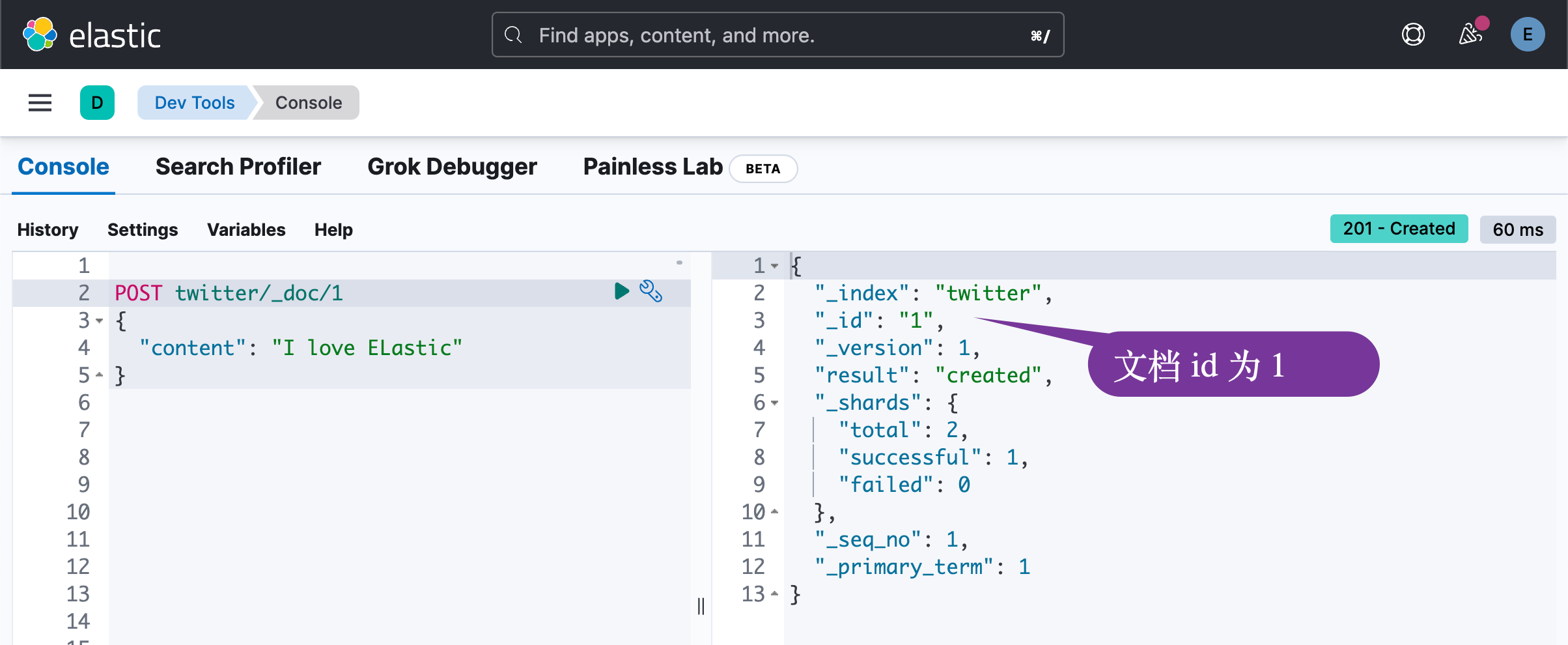
如上所示,我们可以在写入的时候指定文档的 id。这样做的缺点是:在每次写入的时候,Elasticsearch 需要检查当前的文档是否已经存在。如果该 id 的文档不存在,那么就会生成一个新的文档;如果已经存在,那么就会更新当前文档,比如,在上面的例子中,我们再次执行:
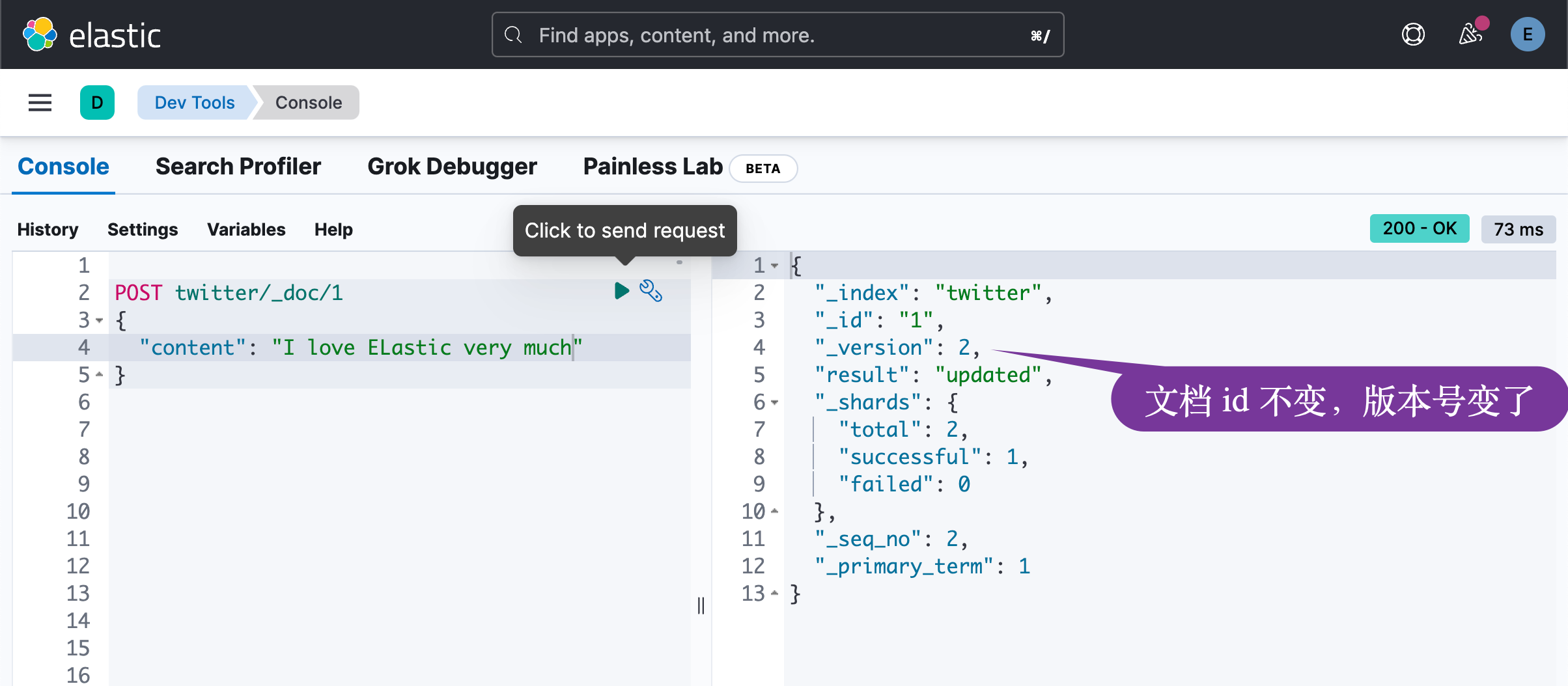
可见,在写入的过程中增加了一个查找文档的过程。显然对于大批量的文档写入来说,这个是非常不利的。
结论
Elasticsearch 的 ID 生成方法是索引速度、存储效率和查找速度之间的权衡。 它针对仅附加工作负载进行了优化,其中文档不断添加到索引中并且很少更新或删除。